预训练在Sparse retrieval的应用
Sparse retrieval models主要通过获得更好的文本表示来提升检索效果,比如传统term-based方法中的bag-of-words (BoW)表示或者"latent word"空间的表示。通过这种方式,查询和文档可以通过sparse embeddings表示,即只有少部分维度非0。这种稀疏表示得到了广泛的关注,因为它可以构建倒排索引用于高效的检索。
随着PTMs的发展,预训练模型被广泛用于提升sparse retrieval模型的容量。我们将这些预训练模型分成四类,包括term re-weighting, document expansion, expansion + re-weighting和sparse representation learning。
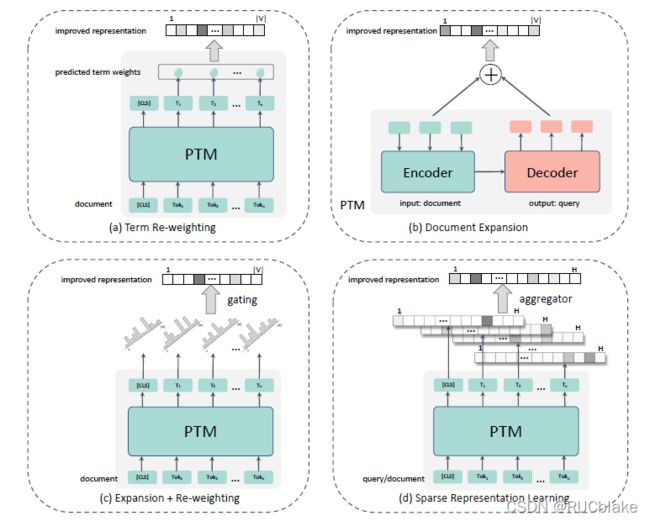
1. Term Re-weighting
1.1 DeepCT
【Introduction】
在搜索引擎的第一阶段检索过程中,传统的方法通常使用布尔模型,概率模型或者是向量空间的BOW模型,这些模型会基于倒排索引捕捉一些信息。在这些第一阶段检索模型中,一个比较重要的问题是如何衡量查询和文档中的term weight。通常使用query term frequency (tf)来表达context-specific的权重,用inverse document frequency (idf)来表达全局的权重。这些基于frequency的方法取得了一定的成功,但是这种方法比较简单粗暴,没有对于文本语义的理解。当遇到比较短的文档时,term frequency分布比较均匀时,信息量会十分有限,不具备区分度。为了确定某个term是否是一段话所表达的核心含义,不仅仅要看它的词频,更要考虑整段文本的语义,才能判断这个term究竟有多么重要。
随着contextualized word representation技术的广泛应用(ELMo, BERT),文本语义理解建模能力有显著提升。每个term最终可以得到一个包含整个文本语义以及句法的表示。本文就展示了如何通过这个contextualized word representation来提升第一阶段检索模型。本文提出Deep Contextualized Term Weighting framework (DeepCT),通过有监督的方式训练一个BERT-based模型来学习term的contextualized representation,并且得到一个将representation映射到term weights的函数。DeepCT在不同的语境下,可以给同一个词生成不同的term weights。这样在一些频率均匀分布的文本(短文档或者长query)中,可以帮助生成更有代表性的term weights。
DeepCT有两个应用场景。其一是识别文档中的重要term用于passage retrieval,在passage长度的文档内使用term-frequency的方式得到的词权重分布较为均匀,文章设计了DeepCT-Index用于离线计算terms的权重并构建索引。训练过程使用DeepCT来预测passage中的每个词是否会出现在相关的查询中,训练完成后的模型用于文档集的所有文档上,整个过程与查询无关。经过DeepCT-Index计算得到的词权重被存入倒排索引中供第一阶段检索模型使用。另一个场景用于识别长query中代表性的term。对于一些包含很多term或者概念的查询,需要判断哪些是最核心的。本文提出DeepCT-Query,通过query-doc pair的相关性标注训练一个DeepCT,通过预测query中每个词在文档中被提及的概率,来生成词权重。这些query词权重可以用于一些诸如BM25和query likelihood的检索模型。实验表明了DeepCT可以生成查询和文档内词的高质量表示,最核心的贡献在于,DeepCT帮助搜索引擎更多地根据词意来确定词的重要度,而非频率。
【Model Structure】
DeepCT的模型包括generating contextualized word embedding和predicting term weights两个组件。其中生成词表示的部分使用的就是BERT,预测词权重就是一个简单的线性层,将词的表示通过线性映射加偏置得到一个权重分数。训练过程相当于在每个词上都是一个回归任务,将预测的权重分数与groud-truth权重分数计算MSE损失函数。BERT使用训练好的参数来初始化,之后使用上述训练任务做fine-tune。DeepCT是一个学习词权重的通用框架,根据不同的任务可以设置不同的ground-true词权重计算方式,从而训练不同的目标。下面介绍的DeepCT-Index和DeepCT-Query就是两个不同的应用场景。
DeepCT-Index用于计算document中词权重,Target term weights (即训练DeepCT用的ground truth)的计算方式为:
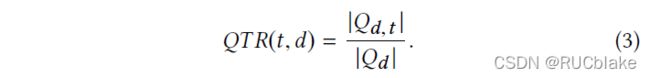
分母是与文档d相关的query集合大小,分子是集合中包含词t的子集大小。QTR(query term recall)的取值范围为[0,1],该值越大,说明词t在用户进行检索行为时最能代表该文档,最有可能与查询词匹配成功。训练完成之后,可以用训练好的模型来构建索引,文中采用的方式是将DeepIndex预测的词频放大100倍四舍五入得到一个整数,替代之前用词频表示的词权重。
DeepCT-Query模型用于给query词预测权重,Target term weights的计算方式为:

分母是与查询相关的文档集大小,分子是D_q中包含词t的子集大小。TR(term recall)表示查询词的重要程度,TR越高,说明该词更可能出现在相关文档中。训练阶段同样使用相关的q-d pair,预测的时候只需要query不需要文档。
1.2 HDCT
原理同DeepCT一致,差别在于要获取document-level term weight,因此需要将passage-level的contextualized term weights组合获取document-level的词权重。另外,fine-tune BERT需要词权重标注,文中提出了三种自动计算目标词权重的策略。
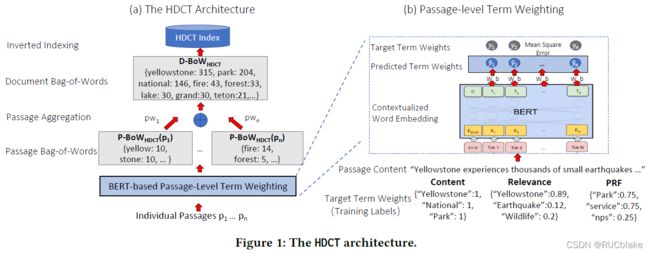
首先对于给定的文档,将其分成若干长度为300左右的passage。随后对每个passage,采用和DeepCT一样的结构,得到预测的target term weights。随后同样将预测得到的term weights放大到类似tf一样的整数词频,但与DeepCT所不同之处在于,HDCT放大的时候在将term weights乘以100取整数之前先取了一个算术平方根,这么做的原因在于term weights是处于[0,1]的小数,开根号之后可以将极端小的分数扩大几个量级,防止最终被几个高分的词主导。此外还有两个细节设置:1)BERT的tokenizer会将词分成若干个piece,最后取第一个piece的表示代表这个词;2)如果同一个词在passage中出现多次,取分数最高的。根据分数可以给每个passage生成一个bag-of-words向量,里面的权重值是这个词对于passage的代表价值,有可能出现频率低但分数高,或者出现频率高但是分数低,这也是HDCT与基于词频的BOW向量的主要区别。
为了获得document-level的词权重,HDCT将passage-level词权重做加权和:
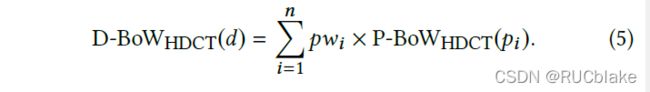
其中pw_i是第i个段落的重要性。文中使用两种方式求pw_i。第一种方式是令所有段落的权重一致,均为1。另一种方式是取1/i,即随着段落数增加而衰减,这是基于现实中往往前几个段落更能够吸引读者的注意力。随后便将document-level bag-of-words representation存入倒排索引中。
下面考虑如何获取标注数据,即ground truth词权重如何获取,人工标注的方式显然是不现实的,文中设计了三种方式来判断词在document retrieval过程的重要度分数:1)当只有文档可用时,可采用一个content-based的标注方式;2)当有大量query-document相关标注的数据时,可采用一个relevance-based的标注方式;3)当可以收集到大量查询,但是与文档的相关度不便获取(出于保护隐私的考虑)时,可考虑采用pseudo-relevance based的标注方式。
Content-based的标注方式中,使用一些特定的文本域(比如文档标题,内链文本),将该文本域下所有的实例构成一个集合(文档标题下只有一个实例,内链文本有多个实例),利用这个集合可以生成弱监督标注:

分子是集合内包括词t的实例个数,分母是集合实例总数。因此当使用文档标题作为指定文本域,最后得到的是0-1标注,若使用内链文本,则得到的标注是位于[0,1]区间内的一个实数。使用content-based的标注方式存在一个问题,即得到的标注是文档级别的,同一个词在不同passage内出现时所使用的标注都是一样的。这种global labels的效果在实验部分会有讨论。
Relevance-based的标注方式使用的前提是有大量query-document相关分数数据。给定一个文档的段落集合,以及与之相关的查询集合,可采用如下方式获取relevance-based标注:

其中分子是相关查询中包含词t的查询个数,分母是所有相关查询的个数。与content-based标注方式一样,这种标注方式也属于global labels,即与具体段落无关的标注。当真实的相关性标注不可用时,可使用一个已有的检索系统,如BM25,对每个查询检索回top K文档,这些文档作为与该查询pseudo-relevant的文档,随后通过与Relevance-based标注计算方式一样的公式,获取pseudo-relevance based的标注。
2. Document Expansion
2.1 DocTTTTTquery (Following Doc2query)
一种提升检索效果的方式就是对文档进行扩充。参考QA系统中,如果能够根据文档来生成该文档可以回答的问题,然后将这个问题添加到文档末尾,会一定程度解决vocabulary mismatch问题,进而提升检索效果,整个Doc2query流程如下图所示:
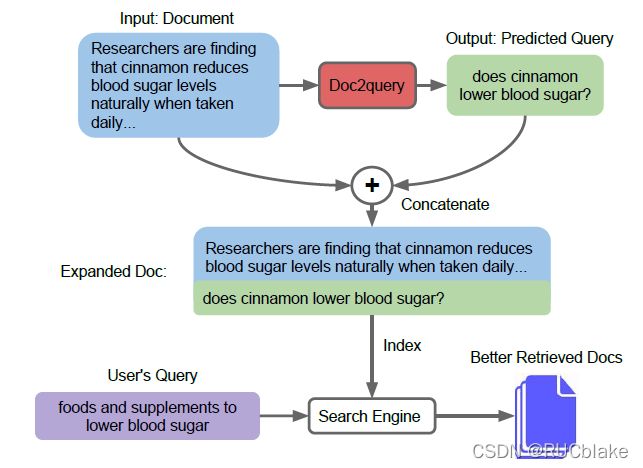
Doc2query使用seq2seq的Transformer模型,使用文档作为输入,输出生成查询。文档和查询在输入之前都使用BPE切分,文档被阶段至400,查询被截断至100。模型训练完成之后,使用top-k随机采样的方式生成10个查询加到文档后面。
DocTTTTTquery相比于Doc2query,将transformer换成了T5,在查询时延上几乎没有增加,但是效果却大大提升。
2.2 UED
预训练模型在IR领域上取得了显著的效果,一方面可以直接作用与ranking过程,另一方面可以用于passage expansion用于第一阶段检索,本文考虑到ranking和passage expansion之间有内在关联,即目标一致,都需要对于文档整体语义的理解,因而考虑联合训练这两个任务。文章提出了Unified Encoder-Decoder networks (UED)。总体包括两个部分:1)用于passage expansion的decoder generator 2)用于re-ranking的encoder。训练过程采用两阶段训练方式,第一个阶段首先使用BERT的自编码训练目标训练encoder,GPT的自回归训练目标来训练decoder。第二个阶段联合训练passage ranking任务和query generation任务。
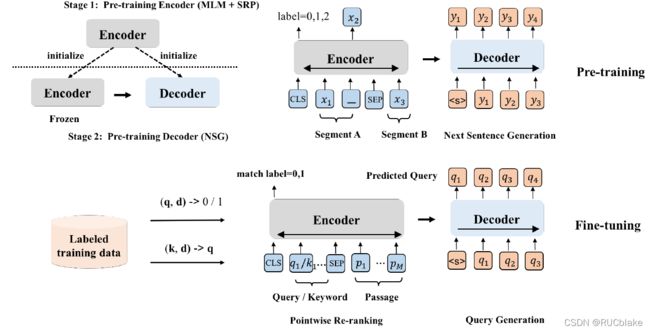 具体地,在第一阶段预训练中,encoder的做预训练的时候除了使用MLM任务以外,为了理解句子之间复杂的关系,还参考StructBERT加入sentence relation prediction (SRP)任务,预测两个部分是next sentence relation, previous sentence relation或者是no relation三种关系。decoder预训练的任务比较简单,即从大规模无标注的语料上选取某个片段中所有句子作为encoder的输入,下一个句子作为生成的目标。
具体地,在第一阶段预训练中,encoder的做预训练的时候除了使用MLM任务以外,为了理解句子之间复杂的关系,还参考StructBERT加入sentence relation prediction (SRP)任务,预测两个部分是next sentence relation, previous sentence relation或者是no relation三种关系。decoder预训练的任务比较简单,即从大规模无标注的语料上选取某个片段中所有句子作为encoder的输入,下一个句子作为生成的目标。
第一阶段预训练完成之后,要对UED的两个组件做fine-tune来分别用于query generation和re-ranking任务。对于query generation任务,利用训练集标注好的query-passage pair,以passage作为输入来生成query。但考虑到passage很长,生成的query有可能失去关键信息,因此在encoder输入不仅仅使用passage内容,还是用PAKE算法抽取出部分关键词加在前面,来指引query的生成。因此encoder的输入实际上为"[CLS]k[SEP]d[SEP]",k为抽取的key words。与Doc2query类似,训练完成之后使用模型生成top-k个query加载passage后面。对re-ranking任务的fine-tune则是比较常规的方式,即将query和doc拼接在一起输入到encoder中,利用CLS位置的表示来预测相关分数,最终采用交叉熵损失来训练encoder部分参数。为了联合训练这两个任务,在每个mini-batch生成时,都以等概率的选择其中一个任务去做,即每一次参数更新都仅使用ranking loss或者generation loss其中的一个。两个阶段的训练过程皆如图所示。
3. Term re-weighting + Document expansion
上述的term re-weighting在基于已有的BOW sparse representation (如tf-idf, BM25)基础上改进,融入语义信息,从而学习到词的重要度而非频率。Document expansion旨在根据文档语义生成潜在对应的查询或问题,即缩小document和query语义上的gap,通过添加新词的方式实现。从最终结果上来看,前者相当于将原有sparse表示中非零的部分学习得更好,后者相当于挖掘sparse中为零的部分哪些应该具有一定权重。那么是否可以设计一个模型,可以同时完成上述目标,即能更好地学习权重,同时又可以结合语义信息,挖掘更多的相关词,这就是本部分方法要解决的。
3.1 SparTerm
为了实现上述的目的,SparTerm考虑直接根据输入文本在整个vocabulary空间上学习一个sparse表示。学习到的这个表示同时具有sparsity和flexibility,也就是说既保留了sparse retrieval模型的优势(对extract matching友好,效率高),也提升语义匹配能力(缓解vocabulary mismatch,并不是只有在passage中出现的词才有权重)。为了实现这两点,模型包括两个主要的组件:Importance Predictor和Gating Controller,整个模型如下图所示:
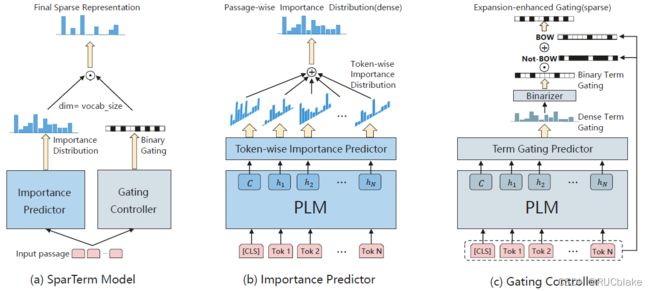
其中Importance Predictor要在整个vocabulary空间上计算每个词的权重。计算方式为,先通过BERT-based的预训练模型处理输入的passage文本,得到每个词最终的输出向量h_i。随后在每个词上都通过下面公式的操作得到一个全词表上的重要度分布:
![]()
其中E是词向量矩阵,Transform函数表示GELU激活函数和一个layer normalization层。得到的I_i的含义是整个词表上与passage中第i个词相关度的概率分布,即与第i个词越相关,对应位置的值越大。随后将每个位置上词的概率分布加到一起就得到了Importance Predictor最终输出的词表上的重要度分布I:

Gating Controller的主要功能是选择"激活"哪些词,最后返回的是一个binary的向量,向量的每个位置是0/1表示该词是否被"激活"。上述的Importance Predictor理论上在每个词上都有一定的分布,但要满足最后获取表示的稀疏性,则需要只"激活"部分的词权重。文中提出了两种Gating Controller:1)Literal-only Gating。只考虑在passage中出现的词,这些词的位置设置为1,其他的词的位置设置为0。这种方式相当于放弃了发掘新的相关词,即只有term re-weighting的效果,没有document expansion的效果。2)Expansion-enhanced Gating。相比于第一种controller,这种方式既考虑passage原有的词,也考虑增加新的词。具体做法是先使用和Importance Predictor一样的结构,通过公式(2)和(3)获取一个词表上的概率分布G,这个概率分布与上述Importance Predictor输出的词重要度分布含义不同,G表示的是哪些词更可能被激活。随后对G中的每个数值做Binary处理(比如以0.5为阈值,大于0.5为1否则为0)。随后需要将在passage中出现过的词的位置也置为1,得到最终的Gating分布,将它和Importance分布相乘就得到了最终的sparse表示。
模型在训练的时候无法端到端地训练,因为需要先有一个可靠的Gating Controller,否则很难收敛。所以首先训练Gating Controller,由于BERT预训练过程的MLM任务输出的概率分布可以较为准确地识别出输入词本身以及语义上相近的词,所以直接使用BERT的参数来初始化。下面在Fine-tune的时候只需要考虑expansion词就可以了。Fine-tune过程中的监督信号来源于已有的passage-query pair数据,即将对应的query中的词视作目标词,组成词集合t。用T表示依据集合t获取的one-hot向量,即在t中出现的词对应为值为1,其余位置为0。通过以下交叉熵损失来优化:
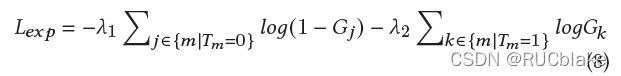
其中lambda_1和lambda_2都是可调的超参数,G表示的是做binary操作之前的dense gating probability。通过这个fine-tune过程,可以使得Gating Controller生成的Gating distribution在passage中原词以及相关query的expansion词上更可能为1。
Fine-tune完成Gating Controller之后就可以端到端地联合训练整个模型,以最后ranking的监督信号来同时训练Importance Predictor和Gating Controller,其中Importance Predictor部分的损失函数如下:
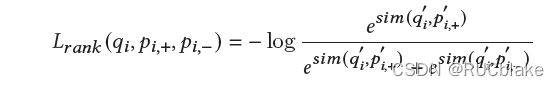
这是一个pairwise的negative log likelihood损失函数,目标在于使得相关的passage最后得到的sparse表示与query的sparse表示相比于不相关的passage更接近。相比于DeepCT中的词权重学习方式,这里直接使用ranking监督信号来训练模型。这么做的目的是希望在整个词表上所有词都参与到学习过程中,从而可以生成稍微smooth一些但仍然具有区分度的重要度分布。最后将rank的loss和controller的loss加到一起,联合训练两个组件。
3.2 SPLADE
SparTerm存在以下两个缺陷:1)训练过程复杂,无法直接端到端训练,需要先训练Gating Controller,再联合训练,无法直接使用最好的Gating Controller参数用于ranking;2)两种Gating Controller经实验证实效果差别不大,说明expansion词效果不明显。据此,SPLADE提出了一些小但是却不可缺少的改动来大幅提升SparTerm的效果。
改动包括以下三点:1)在获取Importance分布时,为了防止部分词的权重占据主导地位,使用一个log-saturation函数,原公式是取RELU直接相加,改成取RELU之后加一取log再相加:
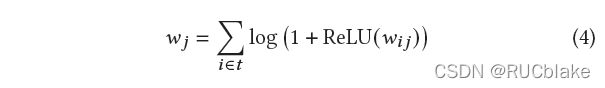
2)原来用于rank任务的损失函数只包括正负例,这里加入了in-batch的随机负例,损失函数如下
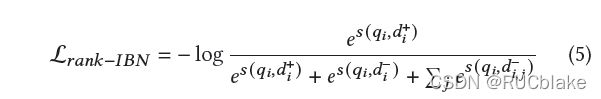
3)保持representation的sparse特性的方式做了改变。SparTerm是使用Gating Controller解决的,这种方式不利于端到端的训练,这里改成使用正则化的方式。SNRM中使用的L0正则无法解决构建索引存在的不平衡问题,即高频词的post list会很长,为了获取balanced的post list,这里使用的是FLOPS正则,公式如下:
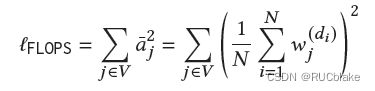
通过FLOPS正则(相比于L0加了一个平方,从而求梯度的时候有区分度),可以更多地打压一些在一个batch内出现权重均值较高的词,这些词的权重更多地降下去有利于索引的平衡。
最终的损失函数如下:
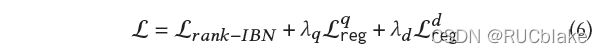
相比于SparTerm去掉了Gating Controller的训练损失,加入了正则化项。分开对查询和文档做正则化是希望查询的sparsity更高一些,有助于快速检索。
3.3 DeepImpact
SparTerm实验结果相比于DocTTTTTQuery在MRR@10上仅仅从0.277提升到0.279。Deep-Impact希望采用更简单有效的方式,即再DeepCT基础上修改。DeepCT的一个缺点是学习目标是每个term彼此独立的target term weight,忽略了passage内term共现的信息(term weight权重学习过程彼此独立),DocTTTTTQuery在完成expansion之后的后续过程还需要依赖BM25的分数。因此,DeepImpact希望在学习每个term权重的时候综合考虑passage里所有的权重,同时可以直接得到相关度分数。
文章做了一个实验,来探寻DocTTTTTQuery在做passage expansion过程中,rewrite词和新词(Inject)词哪个影响更大,实验结果如下图所示:
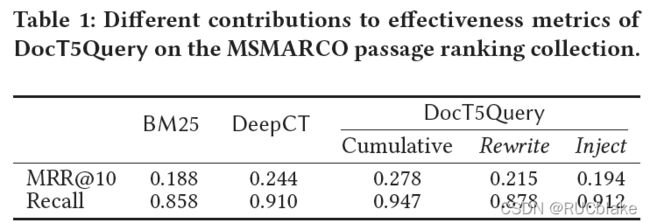
结果发现扩充Rewrite词在MRR@10上有更多提升,扩充新词在recall上有更多提升,同时使用两种词在所有指标上均有提升。另外,使用rewrite词的DocTTTTTQuery在原理上也是term re-weight但是效果却比DeepCT差,说明DocTTTTTQuery在学习词权重的时候不是最优的选择。
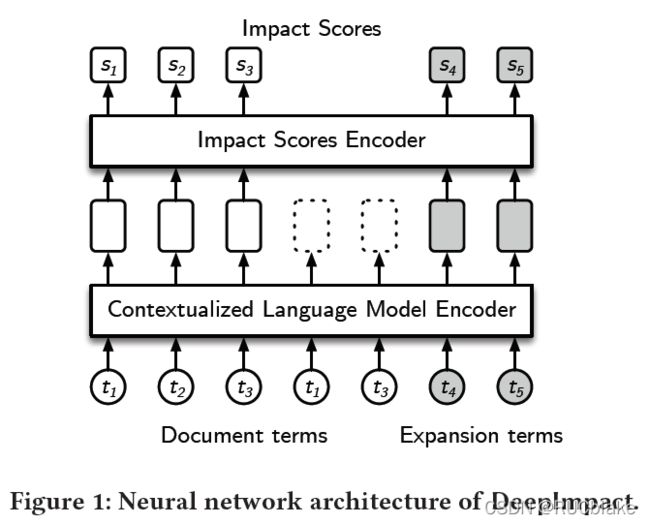
下面介绍DeepImpact的模型结构。首先利用DocTTTTTQuery生成一些查询,获取一些injected expansion terms。将这些词与原passage利用[SEP]分隔开,输入到encoder中,最后输出每个词的embedding。对于重复的词,使用第一次出现位置的embedding,输入到Impact Scores encoder中。这个Impact Scores Encoder包括一个两层的MLP以RELU作为激活函数,最后输出的分数作为该term的impact分数。随后计算query和doc分数的时候使用它们公共词Impact分数的和作为相关分数。训练的时候利用pairwise softmax cross-entropy loss来直接训练模型。
本质上,DeepImpact相比于DeepCT有两个主要区别,一个是使用DocTTTTTQuery先做一次passage expansion,随后计算每个词的权重时以q-d pair相关性直接作为监督信号来训练,而不是以每个term的target term weight分别训练。
4.Sparse Representation Learning
不同于提升在symbolic space的文档表示,稀疏表示学习的方法注重在隐空间内学习查询和文档的稀疏表示,在隐空间内每个维度表示一个词并利用这些隐空间的稀疏表示来建立倒排索引。
4.1 UHD-BERT
Dense representation的好处是能够建模语义进而解决多义词与同义词的关系,这是普通sparse representation难以解决的。然而dense representation也存在一些缺点,比如难以根据它来构建倒排索引,可解释性不强,无法直接在此基础上使用已有的term-based的方法。本文考虑如何在保留sparse representation优势的基础上,引入dense representation的优势。为了获取根据dense representation获取sparse representation,文中使用的是winner-take-all算法(WTA),WTA是一个线性层,只保留Top-K个值并将其他位置的值设置为0。这种控制稀疏性的好处是可以设置指定的稀疏度K。
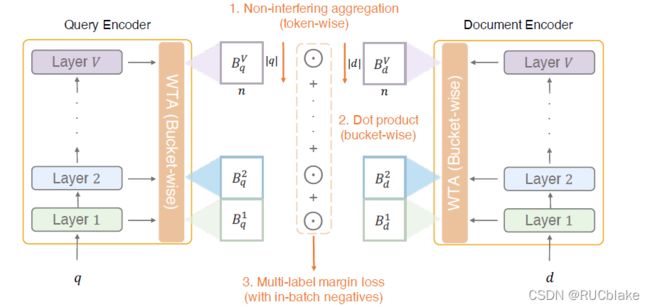
总体的模型结构如上图所示,query和document各有一个结构一致共享参数的encoder,每一层输出的各个token的dense representation,随后在每一层使用WTA生成每个token的sparse representation,随后使用non-interfering aggregation获取每个bucket的表示(即该层的整体表示,每个bucket表示query或者document的某个aspect)。随后将每对bucket表示两两计算点积,最终通过margin loss计算损失。
具体地,Encoder即使用BERT,在每一层上都会给每个token输出一个表示,将这个表示通过一个线性层之后,只保留前k个最大的值,其余位置置为0。随后在每一层上,将每个token的表示通过max pooling聚合成一个整体的bucket表示,所谓non-interfering aggregation意思是每个token的表示都是sparse representation,因此做max-pooling的时候彼此影响不大,不想dense representation做max-pooling会损失大量信息。得到每个bucket表示之后,将query和document每层对应的表示作点积,再将所有点积相加即得到相关度分数。训练的时候将相关的文档作为正例集合,标注不相关的文档(hard-negative)和in-batch随机文档作为负例集合,两两计算margin loss,最后将每个pair的loss加在一起得到最终的loss。
直观上看,相比于SparTerm,主要的区别在于稀疏度控制方法(Gating Controller vs. WTA),以及使用了多层BERT输出结果来表示多个aspects。
4.2 BPR
这篇文章也是针对dense representation做retrieval过程的不足做出的改进。由于dense vector在存储上会具有很大的压力(所有维度的数值都要存),本文提出Binary Passage Retriever (BPR) 将learning-to-hash技术引入到Dense Passage Retriever (DPR)中,从而可以使用压缩的二进制编码来替代连续向量。BPR使用多任务联合训练策略:1)根据二进制码的汉明距离生成候选的passage;2)基于dense vector的passage reranking任务。BPR在不降精度的条件下将存储开销从65G降到了2GB。
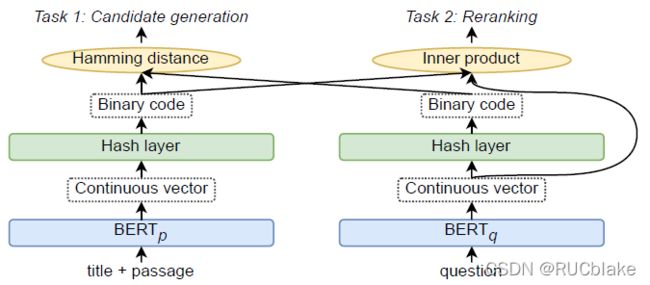
模型结构如图所示,在经过BERT得到输出向量之后,通过一个Hash layer获得二进制向量,这个Hash layer层很简单,即符号函数sign,对向量的每个维度,如果大于0则置为1,否则置为-1。但考虑到符号函数在0处不可导,因此使用一个scaled tanh函数来近似:

其中的beta是scaling参数,当beta趋向正无穷时,该函数逼近符号函数。beta的计算方式为sqrt(0.1 * step + 1),即初始时稍微平缓一些,训练到最后,约接近二进制编码。
训练的时候为了保证模型的效果,分成两个阶段,第一阶段利用生成的二进制编码通过汉明距离计算获得1000个候选,随后第二阶段对这1000个候选做re-rank。第一阶段的损失函数为:
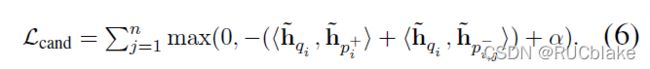
这里看起来是使用内积作为损失函数,但实际上对于二进制编码来说,内积和汉明距离在优化过程中是可以互换的。第二阶段的损失函数和DPR一致:
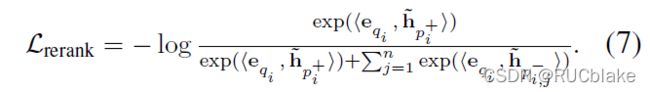
两个任务的Loss直接相加来联合训练。