Transformers库Question Answering任务样例
Transformers库Question Answering任务样例
transformer库问答任务的样例,可以直接在colab运行,我这些做学习笔记来大致翻译一下。可以在这里找到Hugging Face提供的各种样例。这里是colab的地址,需要翻。
文章目录
- Transformers库Question Answering任务样例
- 前言
- 一、在QA任务中的BERT微调
-
- 加载数据集
- 数据预处理
-
- 长文本处理
- 微调模型
- 评估模型
-
- 首先加载保存的模型
- 评估
- 总结
前言
这是我自己的学习笔记,我也是刚开始学习,会有不少错误,谨慎参考!
学习可以在colab,怎么连接GPU可以看前面的博客。
一、在QA任务中的BERT微调
在笔记中,会微调一个 Transformers库中的一个QA任务(抽取式问答),学习加载抽取式类型的数据集和用TrainerAPI微调。
注:答案是原文中抽取的一个子段落,不是新生成的回答
在笔记中的代码可以用来运行任何格式和SQuAD相同的问答任务(版本1或2),使用来自Model Hub的特定检查点(model checkpoint)的模型,只要token classification和fast tokenizer(检查这个表)相同。如果您决定使用不同的数据集,可能只需要做一些小小的调整。根据您的模型和您使用的GPU,您可能需要调整batch_size以避免内存不足的错误。设置好这三个参数,笔记本的其余部分就可以顺利运行了:
# 使用1或2版本 如果您正在使用另一个数据集,它会指示是否允许不可能的答案
squad_v2 = False
model_checkpoint = "distilbert-base-uncased" # https://huggingface.co/distilbert-base-uncased
batch_size = 16
加载数据集
使用 Datasets库下载数据,获得需要的评估矩阵(对比我们的基准模型)。可以用函数load_dataset和load_metric实现.
from datasets import load_dataset, load_metric
这里使用SQUAD dataset数据集,这篇笔记可以适用于任何这个数据集提供的问答任务。如果用自己数据集的JSON或者csv文件(查看Datasets documentation学习怎么加载),那就要考虑调整"列"的名字。
datasets = load_dataset("squad_v2" if squad_v2 else "squad")
这个数据集,datasets是一个DatasetDict对象,它包含训练,验证和测试集的键。
打印出来看就是:
DatasetDict({
train: Dataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 87599
})
validation: Dataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 10570
})
})
可以看到,在训练,验证与测试集的问题都有context,question和answers列。
具体打印一个样例:
datasets["train"][0]
--------------------------------------------------------------------
输出: {'answers': {'answer_start': [515], 'text': ['Saint Bernadette Soubirous']},
'context': 'Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.',
'id': '5733be284776f41900661182',
'question': 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?',
'title': 'University_of_Notre_Dame'}
我们可以看到,答案是通过在全文的开始位置(这里是第515个字符处),和答案内容来表示的,全文指的是 context
为了了解数据,下面这个函数展示了一些随机挑选的数据(自动解码)
from datasets import ClassLabel, Sequence
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset." # 挑选的数据不要超过总共有的数据
picks = [] # 建立列表
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1) # 随机选择一条数据
while pick in picks: # 如果选择到一个在列表中的,重新选一个
pick = random.randint(0, len(dataset)-1)
picks.append(pick) # 总共凑足num_examples个
df = pd.DataFrame(dataset[picks]) # 对着num_examples数据建立df
# display(HTML(df.to_html())) 不太明白后面这段函数的作用
for column, typ in dataset.features.items(): # 共有id,title,context,question,answer,answer_start
if isinstance(typ, ClassLabel): # 例对id列,
df[column] = df[column].transform(lambda i: typ.names[i])
elif isinstance(typ, Sequence) and isinstance(typ.feature, ClassLabel):
df[column] = df[column].transform(lambda x: [typ.feature.names[i] for i in x])
display(HTML(df.to_html()))
打印结果
show_random_elements(datasets["train"])

数据预处理
在输入数据到自己的模型前,需要对模型进行预处理。这里使用 Transformers的Tokenizer完成,它将输入(例如名字)对输入进行标记(tokenize)(要处理 字符转换为相应的ids),并将其转换为模型需要的格式,也包括生成其它模型要求的输入.
为了做的这些,使用tokenizer的AutoTokenizer.from_pretrained方法,能确保:
- 获得tokenizer,它包含我们想要的模型架构
- 下载当我们用到预训练模型特定的检查点的词汇表
该词汇表将被缓存,因此在下次运行单元格时不会再次下载。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint) # 使用distilbert-base-uncased的tokenizer
下面这个断言将确保我们的tokenizer是来自fast tokenizers(Rust支持的)来自 Tokenizers 库。这个fast tokenizers是对于任何模型都可用的,并且,我们将需要它们具有的一些特殊特性来进行预处理。
import transformers
assert isinstance(tokenizer, transformers.PreTrainedTokenizerFast)
您可以在big table of models中检查哪种类型的模型有可用的fast tokenizer,哪种没有。
直接使用tokenzier在下面的两个句子中
y = tokenizer("What is your name?", "My name is Sylvain.")
-----------------------------------------------------------------
输出: {'input_ids': [101, 2054, 2003, 2115, 2171, 1029, 102, 2026, 2171, 2003, 25353, 22144, 2378, 1012, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
tokenizer.decode(y["input_ids"]) # 解码后
--------------------------------------------------------------------
输出: '[CLS] what is your name? [SEP] my name is sylvain. [SEP]'
依据我们选择的模型,将在上述单元格返回的字典中看到不同的键。它们对于我们在这里所做什么事情并不重要(只要知道是稍后实例化的模型所需要),如果你感兴趣的话,你可以在本教程中学习更多关于它们的知识。
长文本处理
现在一个特殊的事情是处理在QA中的长文档。对于特别长的句子,通常在其它任务是选择截断(truncate),但是截断在QA中可能删掉答案。为了处理这个问题,对长例子进行给定一个特殊的输入特征,使每个长度都小于模型的最大长度(或作为超参数设置的长度)。此外,为了避免问题的答案分割,我们允许超参数doc_stride 控制我们生成的特性之间有一些重叠:
max_length = 384 # The maximum length of a feature (question and context) 问题和文本的长度
doc_stride = 128 # The authorized overlap between two part of the context when splitting it is needed.
# 需要分割上下文时,上下文的两个部分之间的授权重叠。
这里演示。首先,选择一个超长文本
for i, example in enumerate(datasets["train"]):
if len(tokenizer(example["question"], example["context"])["input_ids"]) > 384: # 存在"input_ids"和"attention——mask" 两个key值
break
example = datasets["train"][i]
打印下
tokenizer(example["question"], example["context"])
--------------------------------------------------------------------
{'input_ids': [101, 2129, 2116, 5222, 2515, 1996, 10289, 8214, 2273, 1005, 1055, 3455, 2136, 2031, 1029, 102, 1996, 2273, 1005, 1055, 3455, 2136, 2038, 2058, 1015, 1010, 5174, 5222, 1010, 2028, 1997, 2069, 2260, 2816, 2040, 2031, 2584, 2008, 2928, 1010, 1998, 2031, 2596, 1999, 2654, 5803, 8504, 1012, 2280, 2447, 5899, 12385, 4324, 1996, 2501, 2005, 2087, 2685, 3195, 1999, 1037, 2309, 2208, 1997, 1996, 2977, 2007, 6079, 1012, 2348, 1996, 2136, 2038, 2196, 2180, 1996, 5803, 2977, 1010, 2027, 2020, 2315, 2011, 1996, 16254, 2015, 5188, 3192, 2004, 2120, 3966, 3807, 1012, 1996, 2136, 2038, 23339, 1037, 2193, 1997, 6314, 2015, 1997, 2193, 2028, 4396, 2780, 1010, 1996, 2087, 3862, 1997, 2029, 2001, 4566, 12389, 1005, 1055, 2501, 6070, 1011, 2208, 3045, 9039, 1999, 3326, 1012, 1996, 2136, 2038, 7854, 2019, 3176, 2809, 2193, 1011, 2028, 2780, 1010, 1998, 2216, 3157, 5222, 4635, 2117, 1010, 2000, 12389, 1005, 1055, 2184, 1010, 2035, 1011, 2051, 1999, 5222, 2114, 1996, 2327, 2136, 1012, 1996, 2136, 3248, 1999, 4397, 10601, 26429, 10531, 1006, 2306, 1996, 9493, 1052, 1012, 11830, 2415, 1007, 1010, 2029, 11882, 2005, 1996, 2927, 1997, 1996, 2268, 1516, 2230, 2161, 1012, 1996, 2136, 2003, 8868, 2011, 3505, 7987, 3240, 1010, 2040, 1010, 2004, 1997, 1996, 2297, 1516, 2321, 2161, 1010, 2010, 16249, 2012, 10289, 8214, 1010, 2038, 4719, 1037, 29327, 1011, 13913, 2501, 1012, 1999, 2268, 2027, 2020, 4778, 2000, 1996, 9152, 2102, 1010, 2073, 2027, 3935, 2000, 1996, 8565, 2021, 2020, 7854, 2011, 9502, 2110, 2040, 2253, 2006, 1998, 3786, 23950, 1999, 1996, 2528, 1012, 1996, 2230, 1516, 2340, 2136, 5531, 2049, 3180, 2161, 4396, 2193, 2698, 1999, 1996, 2406, 1010, 2007, 1037, 2501, 1997, 2423, 1516, 1019, 1010, 7987, 3240, 1005, 1055, 3587, 3442, 2322, 1011, 2663, 2161, 1010, 1998, 1037, 2117, 1011, 2173, 3926, 1999, 1996, 2502, 2264, 1012, 2076, 1996, 2297, 1011, 2321, 2161, 1010, 1996, 2136, 2253, 3590, 1011, 1020, 1998, 2180, 1996, 16222, 3034, 2977, 1010, 2101, 10787, 2000, 1996, 7069, 1022, 1010, 2073, 1996, 3554, 3493, 2439, 2006, 1037, 4771, 12610, 2121, 1011, 3786, 2121, 2114, 2059, 15188, 5612, 1012, 2419, 2011, 6452, 4433, 11214, 15333, 6862, 3946, 1998, 6986, 9530, 2532, 18533, 2239, 1010, 1996, 3554, 3493, 3786, 1996, 9523, 2120, 3410, 3804, 2630, 13664, 3807, 2076, 1996, 2161, 1012, 1996, 3590, 5222, 2020, 1996, 2087, 2011, 1996, 3554, 3493, 2136, 2144, 5316, 1011, 5641, 1012, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
在没有任何截断的情况下,我们得到输入id的长度如下:
len(tokenizer(example["question"], example["context"])["input_ids"])
--------------------------------------------------------------------
输出: 396
在下面这种截断方法会失去部分信息(这失去的信息有可能是答案)
len(tokenizer(example["question"], example["context"], max_length=max_length, truncation="only_second")["input_ids"])
--------------------------------------------------------------------
输出: 384
注意:我们从不想去截断问题,仅截断文本,截断关键字选择only_second。现在,用tokenizer自动返回特定最大长度的特征映射列表,对于重叠部分使用return_overflowing_tokens=True 并传递 stride=doc_stride
tokenized_example = tokenizer(
example["question"],
example["context"],
max_length=max_length,
truncation="only_second",
return_overflowing_tokens=True,
stride=doc_stride
)
打印结果
tokenized_example
--------------------------------------------------------------------
{'input_ids': [[101, 2129, 2116, 5222, 2515, 1996, 10289, 8214, 2273, 1005, 1055, 3455, 2136, 2031, 1029, 102, 1996, 2273, 1005, 1055, 3455, 2136, 2038, 2058, 1015, 1010, 5174, 5222, 1010, 2028, 1997, 2069, 2260, 2816, 2040, 2031, 2584, 2008, 2928, 1010, 1998, 2031, 2596, 1999, 2654, 5803, 8504, 1012, 2280, 2447, 5899, 12385, 4324, 1996, 2501, 2005, 2087, 2685, 3195, 1999, 1037, 2309, 2208, 1997, 1996, 2977, 2007, 6079, 1012, 2348, 1996, 2136, 2038, 2196, 2180, 1996, 5803, 2977, 1010, 2027, 2020, 2315, 2011, 1996, 16254, 2015, 5188, 3192, 2004, 2120, 3966, 3807, 1012, 1996, 2136, 2038, 23339, 1037, 2193, 1997, 6314, 2015, 1997, 2193, 2028, 4396, 2780, 1010, 1996, 2087, 3862, 1997, 2029, 2001, 4566, 12389, 1005, 1055, 2501, 6070, 1011, 2208, 3045, 9039, 1999, 3326, 1012, 1996, 2136, 2038, 7854, 2019, 3176, 2809, 2193, 1011, 2028, 2780, 1010, 1998, 2216, 3157, 5222, 4635, 2117, 1010, 2000, 12389, 1005, 1055, 2184, 1010, 2035, 1011, 2051, 1999, 5222, 2114, 1996, 2327, 2136, 1012, 1996, 2136, 3248, 1999, 4397, 10601, 26429, 10531, 1006, 2306, 1996, 9493, 1052, 1012, 11830, 2415, 1007, 1010, 2029, 11882, 2005, 1996, 2927, 1997, 1996, 2268, 1516, 2230, 2161, 1012, 1996, 2136, 2003, 8868, 2011, 3505, 7987, 3240, 1010, 2040, 1010, 2004, 1997, 1996, 2297, 1516, 2321, 2161, 1010, 2010, 16249, 2012, 10289, 8214, 1010, 2038, 4719, 1037, 29327, 1011, 13913, 2501, 1012, 1999, 2268, 2027, 2020, 4778, 2000, 1996, 9152, 2102, 1010, 2073, 2027, 3935, 2000, 1996, 8565, 2021, 2020, 7854, 2011, 9502, 2110, 2040, 2253, 2006, 1998, 3786, 23950, 1999, 1996, 2528, 1012, 1996, 2230, 1516, 2340, 2136, 5531, 2049, 3180, 2161, 4396, 2193, 2698, 1999, 1996, 2406, 1010, 2007, 1037, 2501, 1997, 2423, 1516, 1019, 1010, 7987, 3240, 1005, 1055, 3587, 3442, 2322, 1011, 2663, 2161, 1010, 1998, 1037, 2117, 1011, 2173, 3926, 1999, 1996, 2502, 2264, 1012, 2076, 1996, 2297, 1011, 2321, 2161, 1010, 1996, 2136, 2253, 3590, 1011, 1020, 1998, 2180, 1996, 16222, 3034, 2977, 1010, 2101, 10787, 2000, 1996, 7069, 1022, 1010, 2073, 1996, 3554, 3493, 2439, 2006, 1037, 4771, 12610, 2121, 1011, 3786, 2121, 2114, 2059, 15188, 5612, 1012, 2419, 2011, 6452, 4433, 11214, 15333, 6862, 3946, 1998, 6986, 9530, 2532, 18533, 2239, 1010, 1996, 3554, 3493, 3786, 1996, 9523, 2120, 3410, 3804, 2630, 13664, 3807, 2076, 1996, 2161, 1012, 1996, 3590, 5222, 2020, 102], [101, 2129, 2116, 5222, 2515, 1996, 10289, 8214, 2273, 1005, 1055, 3455, 2136, 2031, 1029, 102, 2528, 1012, 1996, 2230, 1516, 2340, 2136, 5531, 2049, 3180, 2161, 4396, 2193, 2698, 1999, 1996, 2406, 1010, 2007, 1037, 2501, 1997, 2423, 1516, 1019, 1010, 7987, 3240, 1005, 1055, 3587, 3442, 2322, 1011, 2663, 2161, 1010, 1998, 1037, 2117, 1011, 2173, 3926, 1999, 1996, 2502, 2264, 1012, 2076, 1996, 2297, 1011, 2321, 2161, 1010, 1996, 2136, 2253, 3590, 1011, 1020, 1998, 2180, 1996, 16222, 3034, 2977, 1010, 2101, 10787, 2000, 1996, 7069, 1022, 1010, 2073, 1996, 3554, 3493, 2439, 2006, 1037, 4771, 12610, 2121, 1011, 3786, 2121, 2114, 2059, 15188, 5612, 1012, 2419, 2011, 6452, 4433, 11214, 15333, 6862, 3946, 1998, 6986, 9530, 2532, 18533, 2239, 1010, 1996, 3554, 3493, 3786, 1996, 9523, 2120, 3410, 3804, 2630, 13664, 3807, 2076, 1996, 2161, 1012, 1996, 3590, 5222, 2020, 1996, 2087, 2011, 1996, 3554, 3493, 2136, 2144, 5316, 1011, 5641, 1012, 102]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], 'overflow_to_sample_mapping': [0, 0]}
现在,在输出的input_id列表不是一个,而是几个:
[len(x) for x in tokenized_example["input_ids"]]
--------------------------------------------------------------------
[384, 157]
如果将它们解码,就会看到它们是重叠的
for x in tokenized_example["input_ids"][:2]:
print(tokenizer.decode(x))
--------------------------------------------------------------------
[CLS] how many wins does the notre dame men's basketball team have? [SEP] the men's basketball team has over 1, 600 wins, one of only 12 schools who have reached that mark, and have appeared in 28 ncaa tournaments. former player austin carr holds the record for most points scored in a single game of the tournament with 61. although the team has never won the ncaa tournament, they were named by the helms athletic foundation as national champions twice. the team has orchestrated a number of upsets of number one ranked teams, the most notable of which was ending ucla's record 88 - game winning streak in 1974. the team has beaten an additional eight number - one teams, and those nine wins rank second, to ucla's 10, all - time in wins against the top team. the team plays in newly renovated purcell pavilion ( within the edmund p. joyce center ), which reopened for the beginning of the 2009 – 2010 season. the team is coached by mike brey, who, as of the 2014 – 15 season, his fifteenth at notre dame, has achieved a 332 - 165 record. in 2009 they were invited to the nit, where they advanced to the semifinals but were beaten by penn state who went on and beat baylor in the championship. the 2010 – 11 team concluded its regular season ranked number seven in the country, with a record of 25 – 5, brey's fifth straight 20 - win season, and a second - place finish in the big east. during the 2014 - 15 season, the team went 32 - 6 and won the acc conference tournament, later advancing to the elite 8, where the fighting irish lost on a missed buzzer - beater against then undefeated kentucky. led by nba draft picks jerian grant and pat connaughton, the fighting irish beat the eventual national champion duke blue devils twice during the season. the 32 wins were [SEP]
[CLS] how many wins does the notre dame men's basketball team have? [SEP] championship. the 2010 – 11 team concluded its regular season ranked number seven in the country, with a record of 25 – 5, brey's fifth straight 20 - win season, and a second - place finish in the big east. during the 2014 - 15 season, the team went 32 - 6 and won the acc conference tournament, later advancing to the elite 8, where the fighting irish lost on a missed buzzer - beater against then undefeated kentucky. led by nba draft picks jerian grant and pat connaughton, the fighting irish beat the eventual national champion duke blue devils twice during the season. the 32 wins were the most by the fighting irish team since 1908 - 09. [SEP]
现在,这将给我们一些工作来正确处理答案:我们需要找到这些特征中的哪个是真正的答案,以及这些特征的具体位置。我们后面使用的模型需要答案的开始和结束位置,因此需要对一些tokens 映射到原始的上下文的位置。用offset_mapping参数返回。
tokenized_example = tokenizer(
example["question"],
example["context"],
max_length=max_length,
truncation="only_second",
return_overflowing_tokens=True, # 长文本处理
return_offsets_mapping=True, # 返回offset-mapping参数
stride=doc_stride
)
print(tokenized_example["offset_mapping"][0][:100])
--------------------------------------------------------------------
[(0, 0), (0, 3), (4, 8), (9, 13), (14, 18), (19, 22), (23, 28), (29, 33), (34, 37), (37, 38)]
这里返回的是字符的开始位置和结束位置,(0, 0)是特殊字符([SEP], [CLS]等)。
tokenized_example[0]
--------------------------------------------------------------------
Encoding(num_tokens=384, attributes=[ids, type_ids, tokens, offsets, attention_mask, special_tokens_mask, overflowing])
对每个输入的索引,给出相关原始文本开始和结束字符。第一个字符是([CLS])是(0, 0),不对应任何question/answer开始和结束位置,然后,第二个字符是0到3
first_token_id = tokenized_example["input_ids"][0][1] # 第一个单词
offsets = tokenized_example["offset_mapping"][0][1]
print(tokenizer.convert_ids_to_tokens([first_token_id])[0], example["question"][offsets[0]:offsets[1]])
# 字符串的第offsets[0]到offsets[1]中的字符
--------------------------------------------------------------------
输出:how How
因此,我们可以使用这个映射来查找给定特征中答案的开始和结束标记的位置。我们不得不去区分相关问题和相关文本的重叠部分,利用tokenized_example的sequence_ids方法。
sequence_ids = tokenized_example.sequence_ids()
print(sequence_ids)
--------------------------------------------------------------------
[None, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, None, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, None]
它返回None证明是特殊字符,0和1取决于它是第一个句子(问题)还是第二个句子(文本)。现在有了所有这些,我们可以在我们的输入特性(或者如果答案不在这个特性中)中找到答案的第一个和最后一个标记:
example
--------------------------------------------------------------------
{'answers': {'answer_start': [30], 'text': ['over 1,600']},
'context': "The men's basketball team has over 1,600 wins, one of only 12 schools who have reached that mark, and have appeared in 28 NCAA tournaments. Former player Austin Carr holds the record for most points scored in a single game of the tournament with 61. Although the team has never won the NCAA Tournament, they were named by the Helms Athletic Foundation as national champions twice. The team has orchestrated a number of upsets of number one ranked teams, the most notable of which was ending UCLA's record 88-game winning streak in 1974. The team has beaten an additional eight number-one teams, and those nine wins rank second, to UCLA's 10, all-time in wins against the top team. The team plays in newly renovated Purcell Pavilion (within the Edmund P. Joyce Center), which reopened for the beginning of the 2009–2010 season. The team is coached by Mike Brey, who, as of the 2014–15 season, his fifteenth at Notre Dame, has achieved a 332-165 record. In 2009 they were invited to the NIT, where they advanced to the semifinals but were beaten by Penn State who went on and beat Baylor in the championship. The 2010–11 team concluded its regular season ranked number seven in the country, with a record of 25–5, Brey's fifth straight 20-win season, and a second-place finish in the Big East. During the 2014-15 season, the team went 32-6 and won the ACC conference tournament, later advancing to the Elite 8, where the Fighting Irish lost on a missed buzzer-beater against then undefeated Kentucky. Led by NBA draft picks Jerian Grant and Pat Connaughton, the Fighting Irish beat the eventual national champion Duke Blue Devils twice during the season. The 32 wins were the most by the Fighting Irish team since 1908-09.",
'id': '5733caf74776f4190066124c',
'question': "How many wins does the Notre Dame men's basketball team have?",
'title': 'University_of_Notre_Dame'}
下面是用来找到答案的开始和结束位置
answers = example["answers"]
start_char = answers["answer_start"][0]
end_char = start_char + len(answers["text"][0]) # 获得答案的开始和结束位置 用的字符长度 char
# Start token index of the current span in the text. 文本中当前span的起始标记索引。
token_start_index = 0
while sequence_ids[token_start_index] != 1:
token_start_index += 1 # 找到文本的开始位置 单词
# End token index of the current span in the text.
token_end_index = len(tokenized_example["input_ids"][0]) - 1
while sequence_ids[token_end_index] != 1:
token_end_index -= 1 # 找到结束位置,排除特殊字符
# Detect if the answer is out of the span (in which case this feature is labeled with the CLS index). 检测答案是否超出范围(在这种情况下,该特性被标记为CLS索引)
offsets = tokenized_example["offset_mapping"][0] # 将第一个截断的,(也就是重叠的)加入
if (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char): # 当答案在offsets中,
# Move the token_start_index and token_end_index to the two ends of the answer.
# Note: we could go after the last offset if the answer is the last word (edge case).
while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char: # 答案在offsets中时候,从第一个单词处开始找答案
token_start_index += 1
start_position = token_start_index - 1 # 确定开始位置
while offsets[token_end_index][1] >= end_char: # 从最后一个单词处找答案
token_end_index -= 1
end_position = token_end_index + 1 # 确定结束位置
print(start_position, end_position) # 答案范围
else:
print("The answer is not in this feature.")
--------------------------------------------------------------------
23 26
我们可以再次验证它确实是理论答案:
print(tokenizer.decode(tokenized_example["input_ids"][0][start_position: end_position+1]))
print(answers["text"][0])
--------------------------------------------------------------------
输出:
over 1, 600
over 1,600
对于这篇笔记本工作在任何模型上,我们需要考虑模型期望左边填充的特殊情况(在这种情况下,我们切换问题和上下文的顺序):左补0的情况
pad_on_right = tokenizer.padding_side == "right"
将所有处理放到一个函数中,我们将应用到我们的训练集。在不能回答(在长文本时,答案在另外一段中),对开始和结束位置设置cls索引。如果allow_impossible_answers标志为False,我们也可以简单地从训练集中丢弃这些示例。因为预处理已经足够复杂了,所以我们在这一部分保持简单。
def prepare_train_features(examples):
# Tokenize our examples with truncation and padding, but keep the overflows using a stride. This results
# in one example possible giving several features when a context is long, each of those features having a
# context that overlaps a bit the context of the previous feature.
# 用填充/截断进行tokenize,但是会保留一大部分的重叠
# 这就产生了一个例子,当一个上下文很长时,可能会给出几个特性,每个特性都有一个与前一个特性的上下文有一些重叠的上下文。
tokenized_examples = tokenizer(
examples["question" if pad_on_right else "context"],
examples["context" if pad_on_right else "question"],
truncation="only_second" if pad_on_right else "only_first",
max_length=max_length,
stride=doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
# 因为一个文本过长,会有一个features, 所以,需要一个映射从feature到相对应的例子。主要是应对重叠部分
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# offset mappings 将为我们提供一个从token到原始上下文中字符位置的映射。这将帮助我们计算start_positions和end_positions。
offset_mapping = tokenized_examples.pop("offset_mapping")
# Let's label those examples! 加上开始和结束位置标签
tokenized_examples["start_positions"] = []
tokenized_examples["end_positions"] = []
for i, offsets in enumerate(offset_mapping):
# 我们将用[CLS]的索引来标记不可能的答案。
input_ids = tokenized_examples["input_ids"][i] # 输入位置的索引
cls_index = input_ids.index(tokenizer.cls_token_id) # cls的索引 101
# 获取与该示例对应的序列(以了解上下文和问题)。
sequence_ids = tokenized_examples.sequence_ids(i) # 0代表问题,1代表答案,None代表特殊标记
# One example can give several spans, this is the index of the example containing this span of text.
# 一个示例可以给出几个span,这是包含该span文本的示例的索引。
sample_index = sample_mapping[i] # 第i个offset_mapping
answers = examples["answers"][sample_index] # 答案的
# 没有答案时,答案为cls_index 即[CLS]
if len(answers["answer_start"]) == 0:
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
# 答案开始/结束字符文本中的索引
start_char = answers["answer_start"][0]
end_char = start_char + len(answers["text"][0])
# 文本中当前span的起始标记索引。
token_start_index = 0
while sequence_ids[token_start_index] != (1 if pad_on_right else 0):
token_start_index += 1 # 找到第一个sequence_ids为1的地方
# 文本中当前span的结束标记索引。
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != (1 if pad_on_right else 0):
token_end_index -= 1
# 检测答案是否超出范围(在这种情况下,该特征被标记为CLS索引)
if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):
# 无答案
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
# 锁定答案
while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
token_start_index += 1
tokenized_examples["start_positions"].append(token_start_index - 1)
while offsets[token_end_index][1] >= end_char:
token_end_index -= 1
tokenized_examples["end_positions"].append(token_end_index + 1)
return tokenized_examples
这个函数可以使用一个或多个示例。
在多个例子中,标记器将为每个键返回一个列表:
features = prepare_train_features(datasets['train'][:5])
print(len(features["input_ids"]))
--------------------------------------------------------------------
5
在我们的数据集中,为了应用这个函数到所有的句子(或句子对),使用dataset对象的map方法。这将对数据集中所有分片的所有元素应用该函数,因此我们的训练、验证和测试数据将在一个命令中预处理。由于预处理更改了样例的数量,所以在应用它时需要删除旧的列。
tokenized_datasets = datasets.map(prepare_train_features, batched=True, remove_columns=datasets["train"].column_names)
tokenized_datasets.items()
--------------------------------------------------------------------
dict_items([('train', Dataset({
features: ['attention_mask', 'end_positions', 'input_ids', 'start_positions'],
num_rows: 88524
})), ('validation', Dataset({
features: ['attention_mask', 'end_positions', 'input_ids', 'start_positions'],
num_rows: 10784
}))])
更好的话,结果由Datasets库自动缓存,以避免在下次运行notebook时在这一步上花费时间。Datasets库通常足够智能,可以检测到传递给map的函数何时发生了更改(因此要求不使用缓存数据)。例如,它将正确地检测您是否更改了第一个单元格中的任务并重新运行notebook。Datasets警告您,当它使用缓存文件时,您可以在调用中传递load_from_cache_file=False来map,以不使用缓存文件,并强制再次应用预处理。
请注意,我们通过batch = True将文本分批编码在一起。这是为了充分利用我们前面加载的快速标记器的优势,它将使用多线程并发地处理批处理中的文本。
微调模型
现在,我们的数据已经为训练做好了准备,我们可以下载预训练的模型并对其进行微调。我们使用AutoModelForQuestionAnswering类。与tokenizer加载一样,from_pretraining方法将为我们下载并缓存模型:
from transformers import AutoModelForQuestionAnswering, TrainingArguments, Trainer
model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint)
警告告诉我们丢弃了一些权重(vocab_transform和vocab_layer_norm层),并随机初始化了一些其他的层(pre_classifier和classifier层)。这种情况是绝对正常的,因为在掩码 语言模型对象是使用预训练模型会去除头,代之以一个没有预训练权重的新的头,所以库警告我们在使用推理任务时,我们应该fine-tune这个模型,这正是我们要做的。
要实例化一个Trainer,我们还需要定义三个东西。最重要的是TrainingArguments,包含特定训练的所有属性。它需要一个文件夹名,用于保存模型的检查点,所有其他参数都是可选的:
args = TrainingArguments(
f"test-squad",
evaluation_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=3,
weight_decay=0.01,
)
在这里,我们设置了要在每个epoch结束时完成的评估,调整学习率,使用在笔记本顶部定义的batch_size,并为训练定制epoch的数量,以及权重衰减。
然后我们需要一个数据整理器(data collator),将我们处理过的例子批处理在一起,这里默认的将会工作:
from transformers import default_data_collator
data_collator = default_data_collator
我们将在下一节评估我们的模型和计算指标(这是一个很长的操作,所以我们将只计算训练期间的评估损失)。
然后我们只需要将所有这些和我们的数据集一起传递给Trainer:
trainer = Trainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)
我们现在可以通过调用train方法来微调我们的模型:
trainer.train()
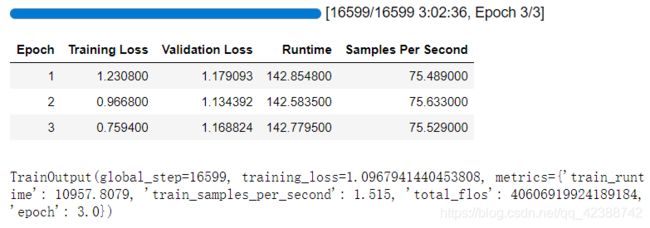
这里可以看到,总共运行了3: 02: 36小时,总共训练步数16599,训练loss=1.0968。
metrics={‘train_runtime’: 10957.8079, ‘train_samples_per_second’: 1.515, ‘total_flos’: 40606919924189184, ‘epoch’: 3.0},
total_flos:训练以来,模型进行浮点操作总次数
train_samples_per_second:每秒训练样本数
在训练中会生成很多检查点,会占据colab很多内存
因为这个训练时间是非常长的,可以保存这个模型以防下次使用。
trainer.save_model("test-squad-trained")
下面这个是我自己写的,将训练过的模型保存下载。
import os
from google.colab import files
def traverse_dir(data_dir):
file_name_list = os.listdir(data_dir)
for file_name in file_name_list:
files.download('{}/{}'.format(data_dir, file_name)) # 多层文件夹需要修改这里
traverse_dir("/content/test-squad-trained") # 模型文件路径
评估模型
评估我们的模型将需要更多的工作,我们需要模型的预测答案,映射回文本的部分。模型本身会预测的答案的逻辑开始位置的结束位置:如果我们从验证集datalaoder中获取一批数据,下面是我们模型给出的输出:
首先加载保存的模型
在transformer提供的cloab在,可以直接运行Evaluation部分的代码,但是由于训练时间过长,这里我写了从drive重新加载模型加载模型的代码,如果不能运行,可以再做修改,自己跑fine-tune直接跑官方代码就可以了。
# 挂载云盘
import os
from google.colab import drive
drive.mount('/content/drive')
# 点击生成链接,登陆。复制
# 云盘中模型路径
mymodel_path = "/content/drive/MyDrive/Colab Notebooks/test-squad-trained"
# 重新运行时加载库,模型,参数等
from transformers import default_data_collator
from transformers import AutoModelForQuestionAnswering, TrainingArguments, Trainer, AutoTokenizer
data_collator = default_data_collator
model = AutoModelForQuestionAnswering.from_pretrained(mymodel_path)
tokenizer = AutoTokenizer.from_pretrained(mymodel_path)
args = TrainingArguments(
f"test-squad",
evaluation_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=3,
weight_decay=0.01,
)
trainer = Trainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)
评估
import torch
for batch in trainer.get_eval_dataloader():
break
# print(batch['input_ids'].shape) # torch.Size([16, 384])
batch = {k: v.to(trainer.args.device) for k, v in batch.items()} # 使用GPU
with torch.no_grad(): # 不更新参数
output = trainer.model(**batch)
output.keys()
返回每个batch中对应句子的attention_mask,end_positions,input_ids,start_positions。
output是测试输出的结果,返回的关键字有loss,start_logits,end_logits,损失率,开始和结束点的评分。
模型的输出(output)是一个类似dict的对象,它包含loss(因为我们提供了标签)、开始和结束的logits。我们不需要损失来做预测,让我们看看logits:
output.start_logits.shape, output.end_logits.shape
--------------------------------------------------------------------------------
输出:(torch.Size([16, 384]), torch.Size([16, 384]))
对于每个feature和每个token,我们都有一个logit值。对于每个feature,最明显的预测方法是将起始logits最大值的索引作为起始位置,将结束logits最大值的索引作为结束位置。
output.start_logits.argmax(dim=-1), output.end_logits.argmax(dim=-1)
--------------------------------------------------------------------------------
输出:(tensor([ 46, 57, 78, 43, 118, 107, 72, 35, 107, 34, 73, 41, 80, 86, 156, 35], device='cuda:0'),
tensor([ 47, 58, 81, 44, 118, 110, 75, 37, 110, 36, 76, 42, 83, 94,
158, 35], device='cuda:0'))
这在很多情况下都很有效,但如果这个预测给了我们一些不可能出现的东西:例如,开始位置可能大于结束位置,或者指向问题中的一段文本,而不是答案。在这种情况下,我们可能想看看第二好的预测,看看它是否给出了一个可能的答案,然后选择它。
然而,选择第二个最佳答案并不像选择一个最佳答案那么简单:
它是起始logits中的第二个最佳索引与结束logis中的最佳索引吗?
或者是起始logits中最好的索引和结束logits中第二好的索引?
如果次优答案也不可能,那么第三优答案就更棘手了。
为了对我们的答案进行分类,我们将使用通过添加起始logit和结束logit获得的分数。我们不会尝试对所有可能的答案进行排序,并限制使用一个称为n_best_size的超参数。我们将在起始logit和结束logit中挑选最好的索引,并收集它预测的所有答案。在检查每一个是否有效后,我们将根据他们的分数排序,并保留最好的一个。以下是我们如何在批量的第一个特性中做到这一点:
n_best_size = 20
import numpy as np
start_logits = output.start_logits[0].cpu().numpy()
end_logits = output.end_logits[0].cpu().numpy() # 获得例句中每个单词的得分列表
# 收集最好的开始/结束logit索引:
start_indexes = np.argsort(start_logits)[-1 : -n_best_size - 1 : -1].tolist()
# 获得分数最大的20个,从大到小排序
end_indexes = np.argsort(end_logits)[-1 : -n_best_size - 1 : -1].tolist()
valid_answers = []
for start_index in start_indexes:
for end_index in end_indexes:
if start_index <= end_index: # We need to refine that test to check the answer is inside the context
# 我们需要细化这个测试,以检查答案是否在上下文中
valid_answers.append(
{
"score": start_logits[start_index] + end_logits[end_index],
"text": "" # We need to find a way to get back the original substring corresponding to the answer in the context
# 我们需要找到一种方法来取回与上下文中的答案对应的原始子字符串
}
)
评估的分数:
[{'score': 17.235836, 'text': ''}, {'score': 14.314373, 'text': ''}, {'score': 11.095074, 'text': ''}, {'score': 9.345072, 'text': ''}, ........]
然后我们可以根据他们的分数对valid_answers排序,只保留最好的一个。剩下的唯一问题是如何检查给定的span是否在上下文中(而不是问题),以及如何取回其中的文本。为了做到这一点,我们需要在验证集的features中添加两件事:
- 生成该特性的示例的ID(因为每个示例都可以生成多个特性,如前所述);
- 偏移量映射,它将为我们提供一个从token索引到context中字符位置的映射。
这就是为什么我们将使用以下函数重新处理验证集,与prepare_train_features略有不同。
def prepare_validation_features(examples):
# 用截断和填充来标记我们的例子,但是使用步来保持溢出。
# 当一个上下文很长时,可能会给出几个特性,每个特性都有一个与前一个特性的上下文有一些重叠的上下文。
tokenized_examples = tokenizer(
examples["question" if pad_on_right else "context"],
examples["context" if pad_on_right else "question"],
truncation="only_second" if pad_on_right else "only_first",
max_length=max_length,
stride=doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
# 一个很长的上下文,它可能会给我们提供几个特性,所以我们需要从特性到它对应的示例的映射。这个关键字给了我们答案。
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# 我们保留这个特性的example_id,并存储偏移量映射。
tokenized_examples["example_id"] = []
for i in range(len(tokenized_examples["input_ids"])):
# 获取与该示例对应的序列(以了解上下文和问题)。
sequence_ids = tokenized_examples.sequence_ids(i)
context_index = 1 if pad_on_right else 0
# 一个示例可以给出几个span,这是包含该span文本的示例的索引。
sample_index = sample_mapping[i]
tokenized_examples["example_id"].append(examples["id"][sample_index])
# 将不属于上下文的offset_mapping设置为None,这样就很容易确定一个标记位置是否是上下文的一部分。
tokenized_examples["offset_mapping"][i] = [
(o if sequence_ids[k] == context_index else None)
for k, o in enumerate(tokenized_examples["offset_mapping"][i])
]
return tokenized_examples
和之前一样,我们可以很容易地将该函数应用到验证集:
可以比较和训练集的代码
validation_features = datasets["validation"].map(
prepare_validation_features,
batched=True,
remove_columns=datasets["validation"].column_names
)
--------------------------------------------------------------------------------
比较:
tokenized_datasets = datasets.map(
prepare_train_features,
batched=True,
remove_columns=datasets["train"].column_names)
查看验证特征
Dataset({
features: ['attention_mask', 'example_id', 'input_ids', 'offset_mapping'],
num_rows: 10784
})
现在我们可以通过使用训练器来获取所有Trainer.predict预测方法:
raw_predictions = trainer.predict(validation_features)
Trainer隐藏了模型不使用的列(这里的example_id和offset_mapping是我们后处理需要的),所以我们把它们设置回来:
validation_features.set_format(
type=validation_features.format["type"],
columns=list(validation_features.features.keys()))
我们现在可以完善之前的测试:因为当偏移映射对应问题的一部分时,我们在偏移映射中设置None,所以很容易检查答案是否完全在上下文中。我们还从我们的考虑中排除了非常长的答案(使用我们可以调优的超参数)
max_answer_length = 30
start_logits = output.start_logits[0].cpu().numpy()
end_logits = output.end_logits[0].cpu().numpy()
offset_mapping = validation_features[0]["offset_mapping"]
# 来自第一个示例的第一个特性。对于更一般的情况,我们需要将example_id匹配到示例索引
context = datasets["validation"][0]["context"] # 第一个例子
# 收集最好的开始/结束logit索引:
start_indexes = np.argsort(start_logits)[-1 : -n_best_size - 1 : -1].tolist()
end_indexes = np.argsort(end_logits)[-1 : -n_best_size - 1 : -1].tolist()
valid_answers = []
for start_index in start_indexes:
for end_index in end_indexes:
# 不要考虑超出范围的答案,因为索引是超出范围的,或者对应于不在上下文中的部分input_id。
if (
start_index >= len(offset_mapping)
or end_index >= len(offset_mapping)
or offset_mapping[start_index] is None
or offset_mapping[end_index] is None
):
continue
# 不要考虑长度小于0或> max_answer_length的答案。
if end_index < start_index or end_index - start_index + 1 > max_answer_length:
continue
if start_index <= end_index: # 我们需要完善这个测试,以检查答案是否在上下文中
start_char = offset_mapping[start_index][0]
end_char = offset_mapping[end_index][1]
valid_answers.append(
{
"score": start_logits[start_index] + end_logits[end_index],
"text": context[start_char: end_char]
}
)
valid_answers = sorted(valid_answers, key=lambda x: x["score"], reverse=True)[:n_best_size]
valid_answers
对于第一个样例的输出时:
[{'score': 17.235836, 'text': 'Denver Broncos'},
{'score': 14.314373,
'text': 'Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers'},
{'score': 12.904865, 'text': 'Broncos'},
{'score': 11.367662,
'text': 'The American Football Conference (AFC) champion Denver Broncos'},
{'score': 11.095074, 'text': 'Denver'},
{'score': 10.982615, 'text': 'Carolina Panthers'},
{'score': 10.526375,
'text': 'American Football Conference (AFC) champion Denver Broncos'},
{'score': 9.983402,
'text': 'Broncos defeated the National Football Conference (NFC) champion Carolina Panthers'},
.
.
.
我们可以比较一下真实的答案:
datasets["validation"][0]["answers"]
--------------------------------------------------------------------------------
{'answer_start': [177, 177, 177],
'text': ['Denver Broncos', 'Denver Broncos', 'Denver Broncos']}
我们的模型选择了最可能的答案 !
正如我们在上面的代码中提到的,这对于第一个特性来说很容易,因为我们知道它来自第一个示例。对于其他特性,我们将需要示例与其对应特性之间的映射。
此外,由于一个示例可以提供多个特性,我们将需要收集给定示例生成的所有特性中的所有答案,然后选择最好的一个。
下面的代码构建了一个从示例索引到相应特征索引的映射:
import collections
examples = datasets["validation"]
features = validation_features
example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
# 获得id : index 例子的id号,和对应的索引
features_per_example = collections.defaultdict(list) # 定义列表字典
for i, feature in enumerate(features):
features_per_example[example_id_to_index[feature["example_id"]]].append(i)
# 找到id对应的索引,
这段确实不会翻译
我们差不多准备好做后处理函数。最后一点需要处理的是无答案(squad_v2 = True)。上面的代码只保存在上下文中的答案,我们还需要获取无答案的分数(CLS索引对应的开始和结束索引)。
当一个例子有几个特征时(长答案),当所有特征都给无答案打高分时,我们必须预测无答案(一个特征能够预测出无答案,仅仅因为答案不在它可以访问的上下文中),这就是为什么一个样例的无答案的分数是该样例在生成的每个特征的无答案分数的最低值
然后,当无答案的得分大于最佳非无答案的得分(阈值)时,我们预测无答案。所有这些结合在一起,给了我们这个后处理功能:
from tqdm.auto import tqdm
def postprocess_qa_predictions(examples, features, raw_predictions, n_best_size = 20, max_answer_length = 30):
all_start_logits, all_end_logits = raw_predictions
# Build a map example to its corresponding features.
# 构建一个对应功能的映射示例。
example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
features_per_example = collections.defaultdict(list)
for i, feature in enumerate(features):
features_per_example[example_id_to_index[feature["example_id"]]].append(i)
# 我们要填的字典。
predictions = collections.OrderedDict()
# Logging.
# 后处理
print(f"Post-processing {len(examples)} example predictions split into {len(features)} features.")
# 让我们循环所有的例子!
for example_index, example in enumerate(tqdm(examples)):
# 这些是与当前示例相关联的特性的索引。
feature_indices = features_per_example[example_index]
min_null_score = None # Only used if squad_v2 is True.
valid_answers = []
context = example["context"]
# 循环遍历与当前示例相关的所有特性。
for feature_index in feature_indices:
# We grab the predictions of the model for this feature.
start_logits = all_start_logits[feature_index]
end_logits = all_end_logits[feature_index]
# This is what will allow us to map some the positions in our logits to span of texts in the original
# context.
offset_mapping = features[feature_index]["offset_mapping"]
# Update minimum null prediction.
cls_index = features[feature_index]["input_ids"].index(tokenizer.cls_token_id)
feature_null_score = start_logits[cls_index] + end_logits[cls_index]
if min_null_score is None or min_null_score < feature_null_score:
min_null_score = feature_null_score
# Go through all possibilities for the `n_best_size` greater start and end logits.
start_indexes = np.argsort(start_logits)[-1 : -n_best_size - 1 : -1].tolist()
end_indexes = np.argsort(end_logits)[-1 : -n_best_size - 1 : -1].tolist()
for start_index in start_indexes:
for end_index in end_indexes:
# Don't consider out-of-scope answers, either because the indices are out of bounds or correspond
# to part of the input_ids that are not in the context.
if (
start_index >= len(offset_mapping)
or end_index >= len(offset_mapping)
or offset_mapping[start_index] is None
or offset_mapping[end_index] is None
):
continue
# Don't consider answers with a length that is either < 0 or > max_answer_length.
if end_index < start_index or end_index - start_index + 1 > max_answer_length:
continue
start_char = offset_mapping[start_index][0]
end_char = offset_mapping[end_index][1]
valid_answers.append(
{
"score": start_logits[start_index] + end_logits[end_index],
"text": context[start_char: end_char]
}
)
if len(valid_answers) > 0:
best_answer = sorted(valid_answers, key=lambda x: x["score"], reverse=True)[0]
else:
# In the very rare edge case we have not a single non-null prediction, we create a fake prediction to avoid
# failure.
# 在非常罕见的边缘情况下,我们没有一个非空预测,我们创建一个假预测来避免失败。
best_answer = {"text": "", "score": 0.0}
# Let's pick our final answer: the best one or the null answer (only for squad_v2)
if not squad_v2:
predictions[example["id"]] = best_answer["text"]
else:
answer = best_answer["text"] if best_answer["score"] > min_null_score else ""
predictions[example["id"]] = answer
return predictions
我们可以将后处理函数应用于我们的原始预测:
final_predictions = postprocess_qa_predictions(datasets["validation"], validation_features, raw_predictions.predictions)
--------------------------------------------------------------------------------
Post-processing 10570 example predictions split into 10784 features.
然后我们可以从datasets库加载metric。
metric = load_metric("squad_v2" if squad_v2 else "squad")
然后我们可以调用compute。我们只需要格式化一些预测和标签,因为它需要一个字典列表,而不是一个大字典。在squad_v2中,我们还必须设置no_answer_probability参数(我们在这里将其设置为0.0,因为我们已经将选择的答案设置为空)。
if squad_v2:
formatted_predictions = [{"id": k, "prediction_text": v, "no_answer_probability": 0.0} for k, v in predictions.items()]
else:
formatted_predictions = [{"id": k, "prediction_text": v} for k, v in final_predictions.items()]
references = [{"id": ex["id"], "answers": ex["answers"]} for ex in datasets["validation"]]
metric.compute(predictions=formatted_predictions, references=references)
--------------------------------------------------------------------------------
输出:{'exact_match': 76.6887417218543, 'f1': 85.10296520714778}
后面就是一些上传模型的教程
总结
效果还是不太好的。这是自己的一个学习笔记,如果有帮到你的话,可以三联支持一下