数据以及空值数据处理方法
第四节 数据七十二变
1、对于简单的数据删除空值数据(NaN)——对于简单的数据进行过滤,如果对于负责的
DataFrame对象进行使用则会存在空值数据过滤不干净
import pandas as pd——导入模块
li=[2,NaN,4,6,NaN,4]——数据集
se=pd.Series(data=li)——生成Series对象
se.notnull()——对是否是空值数据进行判断(返回值是bool值)
print(se[se.notnull()])——返回过滤之后的数据
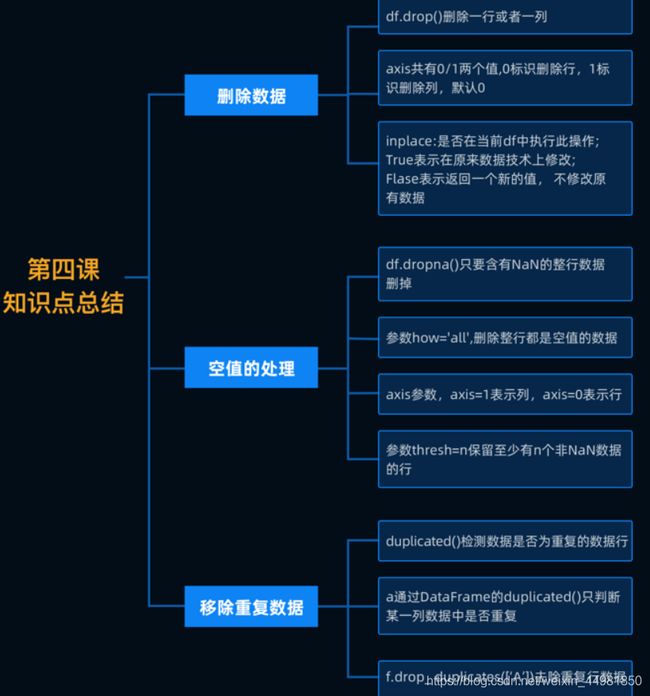
2、删除空值数据(NaN)的行和列
使用dropna函数:
df1=df.dropna()
dropna()是删除空值数据的方法,默认将只要含有NaN的整行数据删掉,如果想要删除整行都是空值的数据
需要添加how='all'参数。
如果想要对列做删除操作,需要添加axis参数,axis=1表示列,axis=0表示行。
我们也可以使用thresh参数筛选想要删除的数据,thresh=n保留至少有n个非NaN数据的行。
3、删除数据
使用函数drop(labels=None,axis=0, index=None, columns=None, inplace=False)
labels :就是要删除的行列的名字,用列表给定。
axis:axis=1表示列,axis=0表示行
index: 直接指定要删除的行。
columns: 直接指定要删除的列。
inplace=False:默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe。
inplace=True:则会直接在原数据上进行删除操作,删除后无法返回。
///
DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False)
总结:最后总结出删除数据可以使用两种方式:
(1)使用labels参数和axis参数结合来删除数据
(2)使用index或者是columns来删除参数,而且index和columns可以同时使用,但是同时使用时
删除的不是某一个单元格,而是所在行和所在列都会删除
4、空值的处理(NaN表示空值)
对于空值我们可以将整条数据删除,也可以使用fillna()方法对空值进行填充
df.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
注意:method参数不能与value参数同时出现。
填充方法有以下三种:
(1)使用常数填充
df.fillna(常数)
(2)使用列的平均数填充
df.fillna(df.mean())
(3)使用前面前面一个值进行填充
df.fillna(method="ffill",axis=0)
5、重复数据的处理
重复数据的存在有时不仅会降低分析的准确度,也会降低分析的效率。所以我们在整理数据的
时候应该将重复的数据删除掉
判断是否是重复数据:
利用duplicated()函数返回的是一个值为Bool类型的Series,如果当前行所有列的数据与前面
的数据是重复的就返回True;反之,则返回False
print(df.duplicated())
删除重复数据
可以使用drop_duplicates()将重复的数据行进行删除
df.drop_duplicates()
也可以对列数据进行判断,然后把重复的数据删除
df.drop_duplicates([列名],inplace=False)
总结