在cuda中使用tensor core计算GEMM(上)
从CUDA9.0开始就已经支持代码中调用tensor core进行计算,tensor core是NVIDIA的volta架构中新处理单元,分布于各个流处理器(SM)中,其在物理层支持如下形式的运算:

其中矩阵乘法中的A,B数据类型必须为FP16,而累加矩阵C和最终输出数据类型可以为FP16也可以为FP32。
要在自己的kernel中使用tensor core必须包含头文件mma.h,相关变量和结构位于叫做wmma(Warp Matrix Multiply Accumulate) 的namespace中。需要注意的是虽然tensor core物理基本结构为4*4*4的单元,但一般用的时候直接进行16*16大小的矩阵乘法(事实上官方的例子中也提到了WMMA的操作维度目前只支持16*16)。
下面以官方的例子进行说明:
- 定义和初始化
单次16*16矩阵的乘法和累加称为wmma操作,首先定义wmma在各个方向上的维度(实际上就是单次计算的小矩阵(tile)的size),这里输入的M,N,K,分别为矩阵A的行数,矩阵B的列数,以及A的列数也就是B的行数,注意这里A,B的size不局限于16*16,因为16*16只是单次wmma可运算的矩阵大小,而通过多个warp(SM中的基本执行代码单元,包含32个thread)和循环实现更大size的矩阵运算。
// The only dimensions currently supported by WMMA
const int WMMA_M = 16;
const int WMMA_N = 16;
const int WMMA_K = 16;
__global__ void wmma_example(half *a, half *b, float *c,
int M, int N, int K,
float alpha, float beta)
{
// Leading dimensions. Packed with no transpositions.
int lda = M;
int ldb = K;
int ldc = M;
// Tile using a 2D grid
int warpM = (blockIdx.x * blockDim.x + threadIdx.x) / warpSize;
int warpN = (blockIdx.y * blockDim.y + threadIdx.y);
- 声明fragment变量
// Declare the fragments
wmma::fragment a_frag;
wmma::fragment b_frag;
wmma::fragment acc_frag;
wmma::fragment c_frag; fragement变量用于对应一次wmma操作中的小矩阵块,声明时所填的参数表明了该fragment在计算中的用途和角色(用于乘法的matrix_a和matrix_b,附加项和输出矩阵则定义为accumulator),以及三个参数用于表示数据的维度形状,如果是matrix_a或matrix_b还必须说明数据在内存中的存储形式是按行还是按列以方便GPU在读取数据时。
- 循环计算一系列tile的乘积
计算之前需要加载数据,用到的也是wmma命名空间下得api,前两个参数为fragment变量和其实地址,最后一个参数为leading dimension,表示数据在按行存储时矩阵的总行数或是按列存储时的总列数,这样知道了输入矩阵的存储方式和leading dimension在加载数据时GPU才知道如何在不连续的数据中取出我们需要的tile。
// Loop over the K-dimension
for (int i = 0; i < K; i += WMMA_K) {
int aRow = warpM * WMMA_M;
int aCol = i;
int bRow = i;
int bCol = warpN * WMMA_N;
// Bounds checking
if (aRow < M && aCol < K && bRow < K && bCol < N) {
// Load the inputs
wmma::load_matrix_sync(a_frag, a + aRow + aCol * lda, lda);
wmma::load_matrix_sync(b_frag, b + bRow + bCol * ldb, ldb);
// Perform the matrix multiplication
wmma::mma_sync(acc_frag, a_frag, b_frag, acc_frag);
}
}首先利用warp的ID来决定这个warp所计算的tile,然后将加载计算所需的数据,之前定义了leading dimensions就是为了这里让GPU知道该如何从不连续的数据中得到计算所需要的。为了方便理解单次循环中的计算,简单画了个示意图:
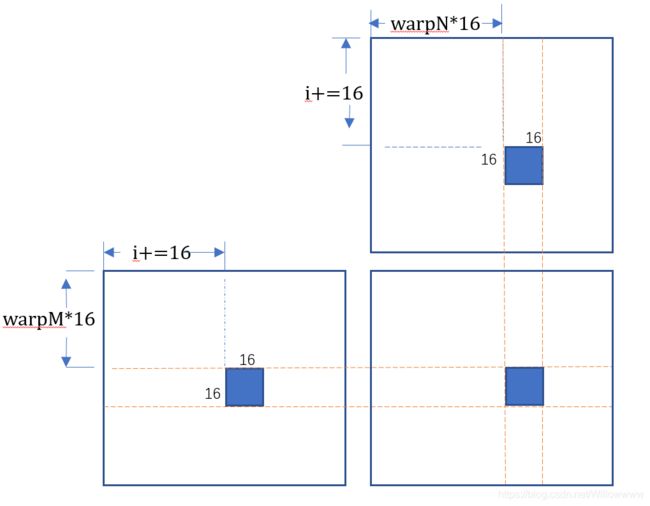
可以看出一次循环中一个warp完成了a和b中一个tile的乘法计算,而每次循环的结果都累加在acc_fag上,最后acc_frag中的结果也就是结果矩阵c中该warp对应的tile。至于为什么大的矩阵运算可以划成tile并将tile看成元素一样运算是线性代数的基本定理,这里不再赘述。
- scale和附加矩阵
之前提到了tensor core不仅可以一次进行一个tile 的乘法,还可以在乘法结果上加上一个附加项,官方blog中同时也提到,在进行加法计算之前,乘法输出和附加矩阵都可以先进行scale也就是乘上一个系数。
// Load in current value of c, scale by beta, and add to result scaled by alpha
int cRow = warpM * WMMA_M;
int cCol = warpN * WMMA_N;
if (cRow < M && cCol < N) {
wmma::load_matrix_sync(c_frag, c + cRow + cCol * ldc, ldc, wmma::mem_col_major);
for(int i=0; i < c_frag.num_elements; i++) {
c_frag.x[i] = alpha * acc_frag.x[i] + beta * c_frag.x[i];
}这里num_elements和x[]都是fragment类的成员变量,方便用户对fragment的数据进行逐一单独访问。
//num_elements和x[]在fragment类中的定义
enum fragment::num_elements;
T fragment::x[num_elements]; - 最后保存计算结果
// Store the output
wmma::store_matrix_sync(c + cRow + cCol * ldc, c_frag, ldc, wmma::mem_col_major);
}
}官方blog指出保存的地址可以为GPU上任意可见地址(及shared memory和global memory)。