神经网络欠拟合与过拟合方法
Overfitting
how to detect
1、train/evalute /test splitting
batchsz = 128
(x, y), (x_test, y_test) = datasets.mnist.load_data()
print('datasets:', x.shape, y.shape, x.min(), x.max())
idx = tf.range(60000)
idx = tf.random.shuffle(idx)
x_train, y_train = tf.gather(x, idx[:50000]), tf.gather(y, idx[:50000])
x_val, y_val = tf.gather(x, idx[-10000:]) , tf.gather(y, idx[-10000:])
print(x_train.shape, y_train.shape, x_val.shape, y_val.shape)
db_train = tf.data.Dataset.from_tensor_slices((x_train,y_train))
db_train = db_train.map(preprocess).shuffle(50000).batch(batchsz)
db_val = tf.data.Dataset.from_tensor_slices((x_val,y_val))
db_val = db_val.map(preprocess).shuffle(10000).batch(batchsz)
2、k_fold cross-validation
Reduce Overfitting
More data
3、constrain model complexity
shallow
奥卡姆剃刀原理
regularization
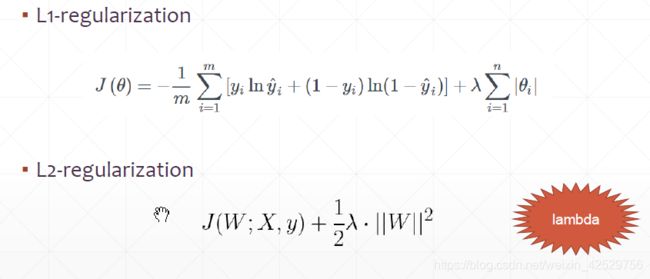
手动添加
for step, (x,y) in enumerate(db):
with tf.GradientTape() as tape:
# [b, 28, 28] => [b, 784]
x = tf.reshape(x, (-1, 28*28))
# [b, 784] => [b, 10]
out = network(x)
# [b] => [b, 10]
y_onehot = tf.one_hot(y, depth=10)
# [b]
loss = tf.reduce_mean(tf.losses.categorical_crossentropy(y_onehot, out, from_logits=True))
loss_regularization = []
for p in network.trainable_variables:
loss_regularization.append(tf.nn.l2_loss(p))
loss_regularization = tf.reduce_sum(tf.stack(loss_regularization))
loss = loss + 0.0001 * loss_regularization
grads = tape.gradient(loss, network.trainable_variables)
optimizer.apply_gradients(zip(grads, network.trainable_variables))
if step % 100 == 0:
print(step, 'loss:', float(loss), 'loss_regularization:', float(loss_regularization))
自动添加
keras.models.Sequential([
keras.layers.Dense(16,kernel_regularizer=keras.regularizers.l2(0.0001)
,activation=tf.nn.relu,input_shape=())
])
tricks
-
momentum
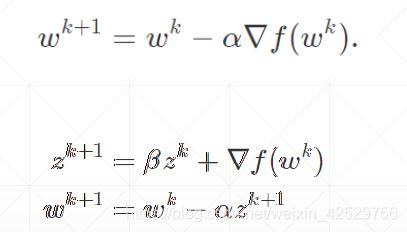
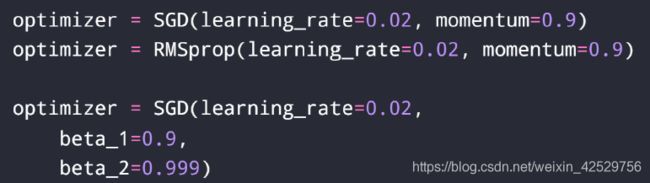
-
learning rate decay
4、dropout
network = Sequential([layers.Dense(256, activation='relu'),
layers.Dropout(0.5), # 0.5 rate to drop
layers.Dense(128, activation='relu'),
layers.Dropout(0.5), # 0.5 rate to drop
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(10)])
network.build(input_shape=(None, 28*28))
network.summary()
5、early stopping
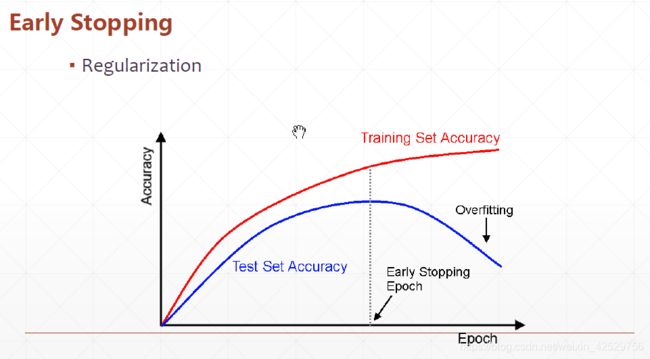
- validation set to select patameters
- Monitor validation performance
- stop at the highest val perf