如何训练YOLOv5神经网络(本地+云端)
1. 本地上训练YOLOv5
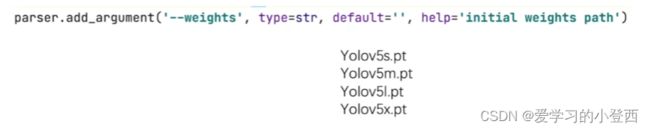
# 指定好训练好的模型的路径,然后用这个训练好的模型来初始化我们网络当中的参数,一般训练时都是一开始来进行训练,即default为空
# default='' Yolov5s.pt Yolov5m.pt Yolov5l.pt Yolov5x.pt
parser.add_argument('--weights', type=str, default='', help='initial weights path')
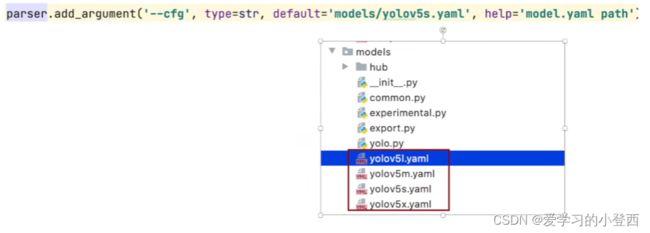
# config 设置的介绍,存储在help=''中
# 模型结构采用 YOLOv5s,初始化参数采用程序当中很简单的初始化,不用训练好的模型初始化
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
# 指定训练数据集 yaml文件夹中附带下载说明
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')

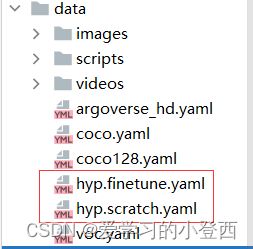
# 超参数 对模型进行微调
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# 指定好训练好的模型的路径,然后用这个训练好的模型来初始化我们网络当中的参数,一般训练时都是一开始来进行训练,即default为空
# default='' Yolov5s.pt Yolov5m.pt Yolov5l.pt Yolov5x.pt
parser.add_argument('--weights', type=str, default='', help='initial weights path')
# config 设置的介绍,存储在help=''中
# 模型结构采用 YOLOv5s,初始化参数采用程序当中很简单的初始化,不用训练好的模型初始化
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='model.yaml path')
# 指定训练数据集
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')
# 超参数 对模型进行微调
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
# 训练轮数,默认300
parser.add_argument('--epochs', type=int, default=300)
# 将多少个数据打包成一个batch送到网络当中
parser.add_argument('--batch-size', type=int, default=3, help='total batch size for all GPUs')
# 分别设置训练集和测试集的大小,当cfg为5s时,img_size最好都设置为640
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
# rectangle,矩阵的训练方式,减少不必要的信息,加快模型速度(推理过程)
parser.add_argument('--rect', action='store_true', help='rectangular training')
# 是否在之前训练完的一个模型中进行训练,默认False,如果要的话default='模型路径' 例:'runs/train/exp8/weights/best.pt'
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
# 只保存最后一次训练(epoch)的模型 权重数据
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
# 是否只在最后一次训练进行测深
parser.add_argument('--notest', action='store_true', help='only test final epoch')
# 是否采用锚点 锚点和锚框
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
# 是否将图片进行缓存
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
# 对上一轮训练结果不好的图片,在下一轮加一些权重
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
# 对图片尺寸进行变换
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
# 训练的数据集是单类别还是多类别
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
# adam是个优化器,如果为TRUE,则选用此优化器,False则选择随机梯度下降优化器
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
# DDP多个显卡时,所设置的参数。
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
# 建议运行前 --workers设置为0
parser.add_argument('--workers', type=int, default=0, help='maximum number of dataloader workers')
# 项目保存位置
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--entity', default=None, help='W&B entity')
# 保存的文件名
parser.add_argument('--name', default='exp', help='save to project/name')
# 是否保存在同一个exp,还是会增加12345
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
# 对学习速率进行调整
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
# 对label进行平滑,放在分类过程中的过拟合
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
# 模型日志
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
# Ctrl+F发现搜不到,说明这个功能还未实现,只是初步构想
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
opt = parser.parse_args()
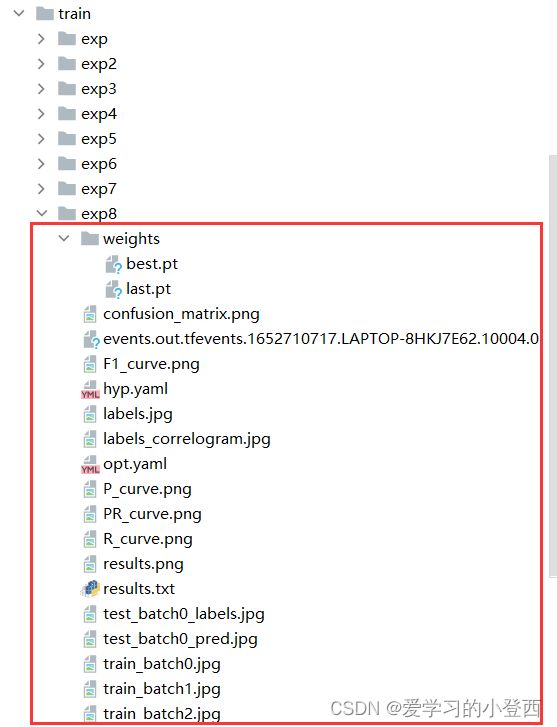
结果:
2. 利用云端GPU训练YOLOv5
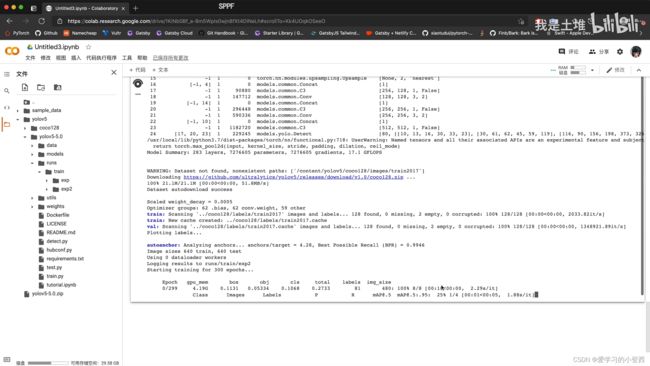
首先打开云端GPU——Google colaboratory
网址:https://colab.research.google.com/notebooks/welcome.ipynb
①登录

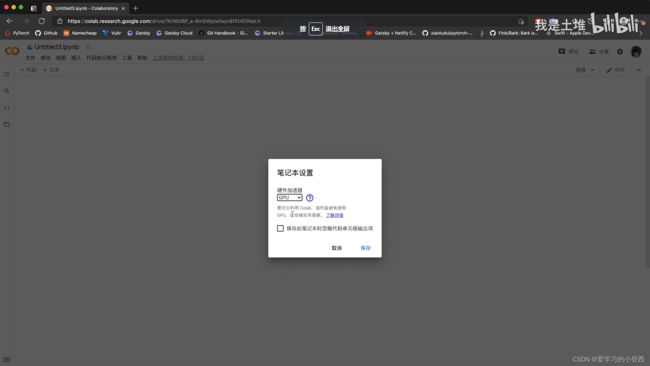
②新建笔记本——修改——笔记本设置——GPU
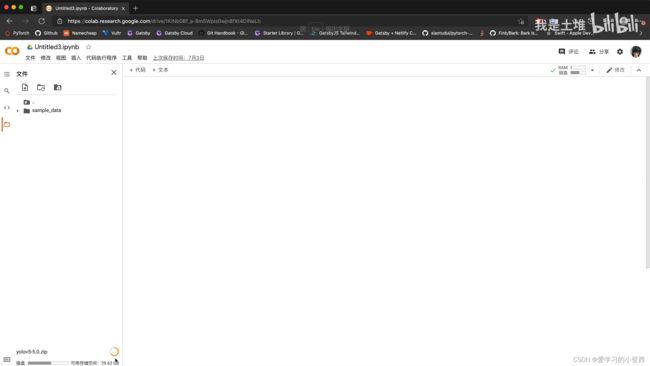
③将项目进行打包成zip,然后上传文件夹
④新建代码行,对文件进行解压缩
!unzip 需要解压缩文件的路径 -d 指定解压后的文件夹路径
⑤进入项目目录
%cd 项目所在目录

⑥配置程序运行所需的环境
!pip install -r requirements.txt
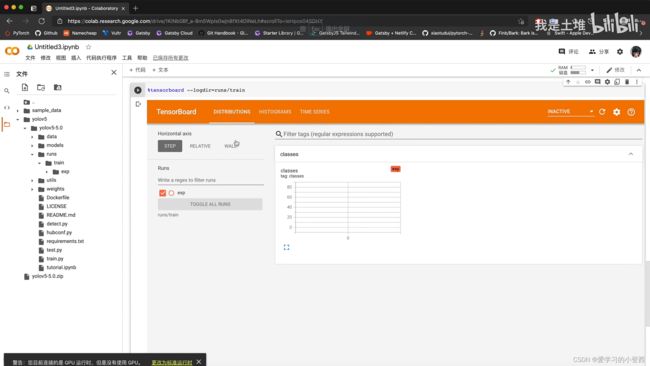
⑦启动tensorboard
%load_ext tensorboard # 添加插件
%tensorboard --logdir=run/train # 启动tensorboard
⑧开始训练
!python train.py --rect