如何使用 Kubevirt 管理 Kubernetes 中的虚拟机
公众号关注 「奇妙的 Linux 世界」
设为「星标」,每天带你玩转 Linux !

kubevirt 以 CRD 形式将 VM 管理接口接入到kubernetes,通过一个pod去使用libvirtd管理VM方式,实现pod与VM的一对一对应,做到如同容器一般去管理虚拟机,并且做到与容器一样的资源管理、调度规划。
本文中所有涉及的代码可以从我的 Github(https://github.com/SimpCosm/manifest/tree/master/kubevirt) 中找到。
背景介绍
CRD 设计
Kubevirt 主要实现了下面几种资源,以实现对虚拟机的管理:
VirtualMachineInstance(VMI): 类似于 kubernetes Pod,是管理虚拟机的最小资源。一个VirtualMachineInstance对象即表示一台正在运行的虚拟机实例,包含一个虚拟机所需要的各种配置。通常情况下用户不会去直接创建 VMI 对象,而是创建更高层级的对象,即 VM 和 VMRS。VirtualMachine(VM): 为集群内的VirtualMachineInstance提供管理功能,例如开机/关机/重启虚拟机,确保虚拟机实例的启动状态,与虚拟机实例是 1:1 的关系,类似与spec.replica为 1 的 StatefulSet。VirtualMachineInstanceReplicaSet: 类似ReplicaSet,可以启动指定数量的VirtualMachineInstance,并且保证指定数量的VirtualMachineInstance运行,可以配置 HPA。
架构设计
为什么kube-virt可以做到让虚拟机无缝的接入到 K8S?首先,先给大家介绍一下它的整体架构。
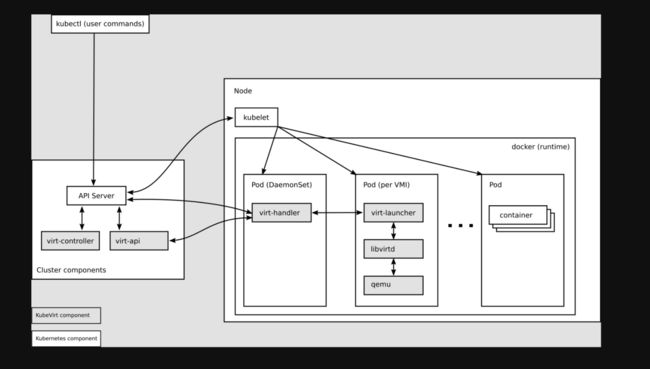
virt-api
kubevirt是以CRD形式去管理vm pod, virt-api 就是所有虚拟化操作的入口,包括常规的 CRD 更新验证以及vm start、stop
virt-controlller
Virt-controller会根据 vmi CRD,生成对应的 virt-lancher pod,并维护 CRD 的状态
virt-handler
virt-handler会以 Daemonset 形式部署在每个节点上,负责监控节点上每个虚拟机实例状态变化,一旦检测到状态变化,会进行响应并确保相应操作能达到所需(理想)状态。virt-handler保持集群级VMI Spec与相应 libvirt 域之间的同步;报告 Libvirt 域状态和集群Spec的变化;调用以节点为中心的插件以满足VMI Spec定义的网络和存储要求。
virt-launcher
每个
virt-lanuncher pod对应着一个VMI, kubelet 只是负责virt-lanuncher pod运行状态,不会去关心 VMI 创建情况。virt-handler会根据 CRD 参数配置去通知 virt-lanuncher 去使用本地 libvirtd 实例来启动VMI, virt-lanuncher 就会通过 pid 去管理VMI,如果 pod生命周期结束,virt-lanuncher 也会去通知VMI去终止。每个 virt-lanuncher pod 对应一个libvirtd,virt-lanuncher通过 libvirtd 去管理VM的生命周期,这样做到去中心化,不再是以前虚拟机那套做法,一个 libvirtd 去管理多个VM。
libvirtd
An instance of libvirtd is present in every VMI pod. virt-launcher uses libvirtd to manage the life-cycle of the VMI process.
virtctl
virctl 是kubevirt自带类似kubectl命令,它是越过virt-lancher pod这层去直接管理vm,可以控制 vm 的start、stop、restart。
VM 流程
上述架构里其实已经部分简述了VM的创建流程,以下进行流程梳理:
K8S API 创建 VMI CRD对象
virt-controller监听到VMI创建时,会根据 VMI 配置生成 pod spec文件,创建virt-launcher podsvirt-controller发现 virt-launcher pod创建完毕后,更新VMI CRD状态virt-handler监听到 VMI 状态变更,通信virt-launcher去创建虚拟机,并负责虚拟机生命周期管理
如下图所示:
Client K8s API VMI CRD Virt Controller VMI Handler
-------------------------- ----------- ------- ----------------------- ----------
listen <----------- WATCH /virtualmachines
listen <----------------------------------- WATCH /virtualmachines
| |
POST /virtualmachines ---> validate | |
create ---> VMI ---> observe --------------> observe
| | v v
validate <--------- POST /pods defineVMI
create | | |
| | | |
schedPod ---------> observe |
| | v |
validate <--------- PUT /virtualmachines |
update ---> VMI ---------------------------> observe
| | | launchVMI
| | | |
: : : :
| | | |
DELETE /virtualmachines -> validate | | |
delete ----> * ---------------------------> observe
| | shutdownVMI
| | |
: : :部署流程
本实验在腾讯云上进行,创建一个包含黑石机型的 TKE 集群。
节点初始化
节点上需要安装 libvirt 和 qemu 软件包:
# Ubuntu
$ apt install -y qemu-kvm libvirt-bin bridge-utils virt-manager
# CentOS
$ yum install -y qemu-kvm libvirt virt-install bridge-utils查看节点是否支持 KVM 硬件虚拟化
[root@VM-4-27-centos ~]# virt-host-validate qemu
QEMU: Checking for hardware virtualization : PASS
QEMU: Checking if device /dev/kvm exists : PASS
QEMU: Checking if device /dev/kvm is accessible : PASS
QEMU: Checking if device /dev/vhost-net exists : PASS
QEMU: Checking if device /dev/net/tun exists : PASS
QEMU: Checking for cgroup 'cpu' controller support : PASS
QEMU: Checking for cgroup 'cpuacct' controller support : PASS
QEMU: Checking for cgroup 'cpuset' controller support : PASS
QEMU: Checking for cgroup 'memory' controller support : PASS
QEMU: Checking for cgroup 'devices' controller support : PASS
QEMU: Checking for cgroup 'blkio' controller support : PASS
QEMU: Checking for device assignment IOMMU support : PASS
QEMU: Checking if IOMMU is enabled by kernel : WARN (IOMMU appears to be disabled in kernel. Add intel_iommu=on to kernel cmdline arguments)
QEMU: Checking for secure guest support : WARN (Unknown if this platform has Secure Guest support)检查此时节点上已经加载了 kvm
[root@VM-4-27-centos ~]# lsmod | grep kvm
kvm_intel 315392 15
kvm 847872 1 kvm_intel
irqbypass 16384 17 kvm安装 kubevirt
$ export VERSION=$(curl -s https://api.github.com/repos/kubevirt/kubevirt/releases | grep tag_name | grep -v -- '-rc' | head -1 | awk -F': ' '{print $2}' | sed 's/,//' | xargs)
$ kubectl apply -f https://github.com/kubevirt/kubevirt/releases/download/${VERSION}/kubevirt-operator.yaml
$ kubectl apply -f https://github.com/kubevirt/kubevirt/releases/download/${VERSION}/kubevirt-cr.yaml备注:如果之前节点不支持硬件虚拟化,可以通过修改 kubevirt-cr 来开启软件模拟模式,参考 https://kubevirt.io/user-guide/operations/installation/#installing-kubevirt-on-kubernetes
部署结果
$ kubectl -n kubevirt get pod
NAME READY STATUS RESTARTS AGE
virt-api-64999f7bf5-n9kcl 1/1 Running 0 6d
virt-api-64999f7bf5-st5qv 1/1 Running 0 6d8h
virt-controller-8696ccdf44-v5wnq 1/1 Running 0 6d
virt-controller-8696ccdf44-vjvsw 1/1 Running 0 6d8h
virt-handler-85rdn 1/1 Running 3 7d19h
virt-handler-bpgzp 1/1 Running 21 7d19h
virt-handler-d55c7 1/1 Running 1 7d19h
virt-operator-78fbcdfdf4-sf5dv 1/1 Running 0 6d8h
virt-operator-78fbcdfdf4-zf9qr 1/1 Running 0 6d部署 Containerized Data Importer
Containerized Data Importer(CDI)项目提供了用于使 PVC 作为 KubeVirt VM 磁盘的功能。参考 [https://github.com/kubevirt/containerized-data-importer#deploy-it:
$ export VERSION=$(curl -s https://github.com/kubevirt/containerized-data-importer/releases/latest | grep -o "v[0-9]\.[0-9]*\.[0-9]*")
$ kubectl create -f https://github.com/kubevirt/containerized-data-importer/releases/download/$VERSION/cdi-operator.yaml
$ kubectl create -f https://github.com/kubevirt/containerized-data-importer/releases/download/$VERSION/cdi-cr.yaml部署 HostPath Provisioner
在本次实验中,采用 PVC 作为持久化存储,但是在腾讯云黑石服务器集群使用 CBS 作为 PVC 时,发现存在 PVC 挂载不到 Pod 的问题,于是选择使用了 kubevirt 提供的 hostpath-provisioner 作为 PVC 的 provisioner。
参考 https://github.com/kubevirt/hostpath-provisioner,hostpath-provisioner 作为 DaemonSet 运行在每个节点上,可以通过 https://github.com/kubevirt/hostpath-provisioner-operator 来部署,部署方式如下:
# hostpath provisioner operator 依赖于 cert manager 提供鉴权能力
$ kubectl create -f https://github.com/cert-manager/cert-manager/releases/download/v1.7.1/cert-manager.yaml
# 创建 hostpah-provisioner namespace
$ kubectl create -f https://raw.githubusercontent.com/kubevirt/hostpath-provisioner-operator/main/deploy/namespace.yaml
# 部署 operator
$ kubectl create -f https://raw.githubusercontent.com/kubevirt/hostpath-provisioner-operator/main/deploy/operator.yaml -n hostpath-provisioner
$ kubectl create -f https://raw.githubusercontent.com/kubevirt/hostpath-provisioner-operator/main/deploy/webhook.yaml接下来创建 CR 作为后端存储,这里指定了 Node 上的 /var/hpvolumes 作为实际数据存放位置:
apiVersion: hostpathprovisioner.kubevirt.io/v1beta1
kind: HostPathProvisioner
metadata:
name: hostpath-provisioner
spec:
imagePullPolicy: Always
storagePools:
- name: "local"
path: "/var/hpvolumes"
workload:
nodeSelector:
kubernetes.io/os: linux真正创建 PVC 之后,可以在对应目录看到存放的 image
[root@VM-4-27-centos hostpath-provisioner]# tree /var/hpvolumes/csi/
/var/hpvolumes/csi/
|-- pvc-11d671f7-efe3-4cb0-873b-ebd877af53fe
| `-- disk.img
|-- pvc-a484dae6-720e-4cc4-b1ab-8c59eec7a963
| `-- disk.img
`-- pvc-de897334-cb72-4272-bd76-725663d3f515
`-- disk.img
3 directories, 3 files
[root@VM-4-27-centos hostpath-provisioner]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
iso-win10 Bound pvc-de897334-cb72-4272-bd76-725663d3f515 439Gi RWO hostpath-csi 23h
iso-win10-2 Bound pvc-a484dae6-720e-4cc4-b1ab-8c59eec7a963 439Gi RWO hostpath-csi 23h
iso-win10-3 Bound pvc-11d671f7-efe3-4cb0-873b-ebd877af53fe 439Gi RWO hostpath-csi 22h接下来需要创建对应的 storageclass,注意这里的 storagePool 即是刚才创建 CR 里面的 local:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: hostpath-csi
provisioner: kubevirt.io.hostpath-provisioner
reclaimPolicy: Delete
volumeBindingMode: WaitForFirstConsumer
parameters:
storagePool: local配置 HardDisk
参考 https://kubevirt.io/user-guide/operations/activating_feature_gates/,打开 kubevirt 的 HardDisk 模式:
$ cat << END > enable-feature-gate.yaml
---
apiVersion: kubevirt.io/v1
kind: KubeVirt
metadata:
name: kubevirt
namespace: kubevirt
spec:
configuration:
developerConfiguration:
featureGates:
- HardDisk
- DataVolumes
END
$ kubectl apply -f enable-feature-gate.yaml客户端准备
Kubevirt 提供了一个命令行工具 virtctl,可以直接下载:
$ export VERSION=$(curl -s https://api.github.com/repos/kubevirt/kubevirt/releases | grep tag_name | grep -v -- '-rc' | head -1 | awk -F': ' '{print $2}' | sed 's/,//' | xargs)
$ curl -L -o /usr/local/bin/virtctl https://github.com/kubevirt/kubevirt/releases/download/$VERSION/virtctl-$VERSION-linux-amd64
$ chmod +x /usr/local/bin/virtctl也可以通过 krew 安装为 kubectl 的插件:
$ kubectl krew install virt创建 Linux 虚拟机
以下是一个创建 Linux 虚拟机的 VMI 示例,基于此 VMI 会自动创建一个 VM。在这个 CR 里面,指定了一个虚拟机需要的几个关键元素:
Domain:domain 是一个虚拟机都需要的根元素,指定了虚拟机需要的所有资源。kubevirt 会根据这个 domain spec 转换成 libvirt 的 XML 文件,创建虚拟机。
存储:
spec.volumes表示真正的存储后端,spec.domain.devices.disks表示这个 VM 要使用什么存储。具体参考存储一节。网络:
spec.networks表示真正的网络后端,spec.domain.devices.interfaces表示这个 VM 使用什么类型网卡设备
apiVersion: kubevirt.io/v1alpha3
kind: VirtualMachineInstance
metadata:
name: testvmi-nocloud2
spec:
terminationGracePeriodSeconds: 30
domain:
resources:
requests:
memory: 1024M
devices:
disks:
- name: containerdisk
disk:
bus: virtio
- name: emptydisk
disk:
bus: virtio
- disk:
bus: virtio
name: cloudinitdisk
interfaces:
- bridge: {}
name: default
networks:
- name: default
pod: {}
volumes:
- name: containerdisk
containerDisk:
image: kubevirt/fedora-cloud-container-disk-demo:latest
- name: emptydisk
emptyDisk:
capacity: "2Gi"
- name: cloudinitdisk
cloudInitNoCloud:
userData: |-
#cloud-config
password: fedora
chpasswd: { expire: False }创建以下 VirtualMachineInstance CR 之后,可以看到集群中启动了 virt-launcher-testvmi-nocloud2-jbbhs 这个 Pod。查看 Pod 和 虚拟机:
[root@VM-4-27-centos ~]# kubectl get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
virt-launcher-testvmi-nocloud2-jbbhs 2/2 Running 0 24h 172.16.0.24 10.3.4.27 1/1
[root@VM-4-27-centos ~]# kubectl get vmi
NAME AGE PHASE IP NODENAME READY
testvmi-nocloud2 24h Running 172.16.0.24 10.3.4.27 True 登陆虚拟机,账号和密码都是 fedora:
[root@VM-4-27-centos ~]# ssh [email protected]
[email protected]'s password:
Last login: Wed Feb 23 06:30:38 2022 from 172.16.0.1
[fedora@testvmi-nocloud2 ~]$ uname -a
Linux testvmi-nocloud2 5.6.6-300.fc32.x86_64 #1 SMP Tue Apr 21 13:44:19 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
[fedora@testvmi-nocloud2 ~]$ ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 5e:04:61:17:c1:c9 brd ff:ff:ff:ff:ff:ff
altname enp1s0
inet 172.16.0.24/26 brd 172.16.0.63 scope global dynamic noprefixroute eth0
valid_lft 86226231sec preferred_lft 86226231sec
inet6 fe80::5c04:61ff:fe17:c1c9/64 scope link
valid_lft forever preferred_lft forever 创建 Windows 虚拟机
上传镜像
CDI 提供了使用 PVC 作为虚拟机磁盘的方案,CDI 支持以下几种模式导入镜像到 PVC:
通过 URL 导入虚拟机镜像到 PVC,URL 可以是 http 链接,s3 链接
Clone 一个已经存在的 PVC
通过 container registry 导入虚拟机磁盘到 PVC,需要结合
ContainerDisk使用通过客户端上传本地镜像到 PVC
这里使用第四种方式,通过 virtctl 命令行工具,结合 CDI 项目上传本地镜像到 PVC:
$ virtctl image-upload \
--image-path='Win10_20H2_Chinese(Simplified)_x64.iso' \
--storage-class hostpath-csi \
--pvc-name=iso-win10 \
--pvc-size=10Gi \
--uploadproxy-url=https:// \
--insecure \
--wait-secs=240
PersistentVolumeClaim default/iso-win10 created
Waiting for PVC iso-win10 upload pod to be ready...
Pod now ready
Uploading data to https://10.111.29.156
5.63 GiB / 5.63 GiB [======================================================================================================================================================] 100.00% 27s
Uploading data completed successfully, waiting for processing to complete, you can hit ctrl-c without interrupting the progress
Processing completed successfully
Uploading Win10_20H2_Chinese(Simplified)_x64.iso completed successfully 参数解释:
–image-path : 操作系统镜像的本地地址
–pvc-name : 指定存储操作系统镜像的 PVC,这个 PVC 不需要提前准备好,镜像上传过程中会自动创建。
–pvc-size : PVC 大小,根据操作系统镜像大小来设定,一般略大一个 G 就行
–uploadproxy-url : cdi-uploadproxy 的 Service IP,可以通过命令
kubectl -n cdi get svc -l cdi.kubevirt.io=cdi-uploadproxy来查看。
创建虚拟机
创建 VirtualMachine CR 之后,可以看到集群中创建了对应的 Pod 和虚拟机:
apiVersion: kubevirt.io/v1alpha3
kind: VirtualMachine
metadata:
name: win10
spec:
running: false
template:
metadata:
labels:
kubevirt.io/domain: win10
spec:
domain:
cpu:
cores: 4
devices:
disks:
- bootOrder: 1
disk:
bus: virtio
name: harddrive
- bootOrder: 2
cdrom:
bus: sata
name: cdromiso
- cdrom:
bus: sata
name: virtiocontainerdisk
interfaces:
- masquerade: {}
model: e1000
name: default
machine:
type: q35
resources:
requests:
memory: 16G
networks:
- name: default
pod: {}
volumes:
- name: cdromiso
persistentVolumeClaim:
claimName: iso-win10-3
- name: harddrive
hostDisk:
capacity: 50Gi
path: /data/disk.img
type: DiskOrCreate
- name: virtiocontainerdisk
containerDisk:
image: kubevirt/virtio-container-disk这里用到了3个 Volume:
harddrive:虚拟机使用的磁盘,即操作系统就会安装在该磁盘上。这里选择
hostDisk直接挂载到宿主机以提升性能,如果使用分布式存储则体验非常不好。cdromiso : 提供操作系统安装镜像,即上文上传镜像后生成的 PVC
iso-win10。virtiocontainerdisk : 由于 Windows 默认无法识别 raw 格式的磁盘,所以需要安装 virtio 驱动。containerDisk 可以将打包好 virtio 驱动的容器镜像挂载到虚拟机中。
启动虚拟机实例:
$ virtctl start win10
# 如果 virtctl 安装为 kubectl 的插件,命令格式如下:
$ kubectl virt start win10查看启动的 VM 实例,Windows 虚拟机已经可以正常运行了。
[root@VM-4-27-centos ~]# kubectl get vmi
NAME AGE PHASE IP NODENAME READY
win10 23h Running 172.16.0.32 10.3.4.27 True
[root@VM-4-27-centos ~]# kubectl get vm
NAME AGE STATUS READY
win10 23h Running True配置 VNC 访问
参考 https://kubevirt.io/2019/Access-Virtual-Machines-graphic-console-using-noVNC.html 可以部署 virtVNC 来访问启动的 Windows 服务器。这里主要是暴露出了一个 NodePort 的服务,可以通过
apiVersion: v1
kind: ServiceAccount
metadata:
name: virtvnc
namespace: kubevirt
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: virtvnc
subjects:
- kind: ServiceAccount
name: virtvnc
namespace: kubevirt
roleRef:
kind: ClusterRole
name: virtvnc
apiGroup: rbac.authorization.k8s.io
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: virtvnc
rules:
- apiGroups:
- subresources.kubevirt.io
resources:
- virtualmachineinstances/console
- virtualmachineinstances/vnc
verbs:
- get
- apiGroups:
- kubevirt.io
resources:
- virtualmachines
- virtualmachineinstances
- virtualmachineinstancepresets
- virtualmachineinstancereplicasets
- virtualmachineinstancemigrations
verbs:
- get
- list
- watch
---
apiVersion: v1
kind: Service
metadata:
labels:
app: virtvnc
name: virtvnc
namespace: kubevirt
spec:
ports:
- port: 80
protocol: TCP
targetPort: 8001
selector:
app: virtvnc
#type: LoadBalancer
type: NodePort
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: virtvnc
namespace: kubevirt
spec:
replicas: 1
selector:
matchLabels:
app: virtvnc
template:
metadata:
labels:
app: virtvnc
spec:
serviceAccountName: virtvnc
containers:
- name: virtvnc
image: quay.io/samblade/virtvnc:v0.1
livenessProbe:
httpGet:
port: 8001
path: /
scheme: HTTP
failureThreshold: 30
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
$ kubectl apply -f virtvnc.yaml通过访问这个 NodePort 服务,既可以

接下来就可以像 https://www.cnblogs.com/ryanyangcs/p/14079144.html 里面指导的一样,安装 Windows 操作系统了。
配置远程连接
尽管 VNC 可以远程访问 Windows 图形界面,但是操作体验比较难受。当系统安装完成后,就可以使用 Windows 的远程连接协议 RDP。选择开始 >设置 >系统>远程桌面,打开启用远程桌面就好了。
现在可以通过 telnet 来测试 RDP 端口 3389 的连通性:
[root@VM-4-27-centos ~]# telnet 172.16.0.32 3389
Trying 172.16.0.32...
Connected to 172.16.0.32.
Escape character is '^]'.如果你的本地电脑能够直连 Pod IP 和 SVC IP,现在就可以直接通过 RDP 客户端来远程连接 Windows 了。如果你的本地电脑不能直连 Pod IP 和 SVC IP,但可以直连 Kubernetes 集群的 Node IP,可以通过 NodePort 来暴露 RDP 端口。具体操作是创建一个 Service,类型为 NodePort:
[root@VM-4-27-centos ~]# virtctl expose vm win10 --name win10-rdp --port 3389 --target-port 3389 --type NodePort
Service win10-rdp successfully exposed for vm win10
[root@VM-4-27-centos ~]#
[root@VM-4-27-centos ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-user LoadBalancer 172.16.253.39 10.3.4.28 443:31525/TCP 27h
kubernetes ClusterIP 172.16.252.1 443/TCP 42h
win10-rdp NodePort 172.16.255.78 3389:32200/TCP 8s 然后就可以通过 Node IP 来远程连接 Windows 了。如果你的本地操作系统是 Windows 10,可以在任务栏的搜索框中,键入“远程桌面连接”,然后选择“远程桌面连接”。在“远程桌面连接”中,键入你想要连接的电脑的名称(从步骤 1),然后选择“连接”。如果你的本地操作系统是 macOS,需要在 App Store 中安装 Microsoft Remote Desktop。
对于以上使用了
windows 访问外网
外网访问 windows
在 Windows 虚拟机中安装 nginx 服务,可以在 Windows 中访问:
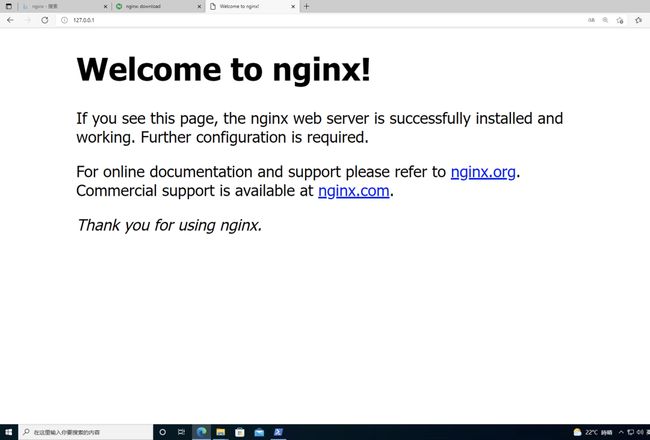
这个时候直接访问 Windows 虚拟机对应的 IP,既可以在集群内访问 Nginx 服务:
[root@VM-4-27-centos ~]# kubectl get vmi win10
NAME AGE PHASE IP NODENAME READY
win10 5d5h Running 172.16.0.32 10.3.4.27 True
[root@VM-4-27-centos ~]# curl 172.16.0.32:80
Welcome to nginx!
Welcome to nginx!
If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.
For online documentation and support please refer to
nginx.org.
Commercial support is available at
nginx.com.
Thank you for using nginx.
为了能够将这个 Windows 虚拟机的服务暴露到外网,创建以下 Service:
apiVersion: v1
kind: Service
metadata:
name: win10-nginx
namespace: default
spec:
externalTrafficPolicy: Cluster
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
kubevirt.io/domain: win10
sessionAffinity: None
type: NodePort可以看到创建了 NodePort 的服务:
[root@VM-4-27-centos ~]# kubectl get svc
win10-nginx NodePort 172.16.255.171 80:31251/TCP 3s 这时候访问 NodePort 的服务就可以访问 Windows 虚拟机提供的服务:

存储
虚拟机镜像(磁盘)是启动虚拟机必不可少的部分,KubeVirt 中提供多种方式的虚拟机磁盘,虚拟机镜像(磁盘)使用方式非常灵活。这里列出几种比较常用的:
PersistentVolumeClaim: 使用 PVC 做为后端存储,适用于数据持久化,即在虚拟机重启或者重建后数据依旧存在。使用的 PV 类型可以是 block 和 filesystem
使用 filesystem 时,会使用 PVC 上的 /disk.img,格式为 RAW 格式的文件作为硬盘。
block 模式时,使用 block volume 直接作为原始块设备提供给虚拟机。
ephemeral : 基于后端存储在本地做一个写时复制(COW)镜像层,所有的写入都在本地存储的镜像中,VM 实例停止时写入层就被删除,后端存储上的镜像不变化。
containerDisk : 基于 scratch 构建的一个 docker image,镜像中包含虚拟机启动所需要的虚拟机镜像,可以将该 docker image push 到 registry,使用时从 registry 拉取镜像,直接使用 containerDisk 作为 VMI 磁盘,数据是无法持久化的。
hostDisk : 使用节点上的磁盘镜像,类似于
hostpath,也可以在初始化时创建空的镜像。dataVolume : 提供在虚拟机启动流程中自动将虚拟机磁盘导入 pvc 的功能,在不使用 DataVolume 的情况下,用户必须先准备带有磁盘映像的 pvc,然后再将其分配给 VM 或 VMI。dataVolume 拉取镜像的来源可以时 http,对象存储,另一块 PVC 等。
更多参考 https://kubevirt.io/user-guide/virtual_machines/disks_and_volumes/
全局路由模式 bridge 网络原理
虚拟机网络就是pod网络,virt-launcher pod网络的网卡不再挂有pod ip,而是作为虚拟机的虚拟网卡的与外部网络通信的交接物理网卡,virt-launcher实现了简单的单ip dhcp server,就是需要虚拟机中启动dhclient,virt-launcher 服务会分配给虚拟机。
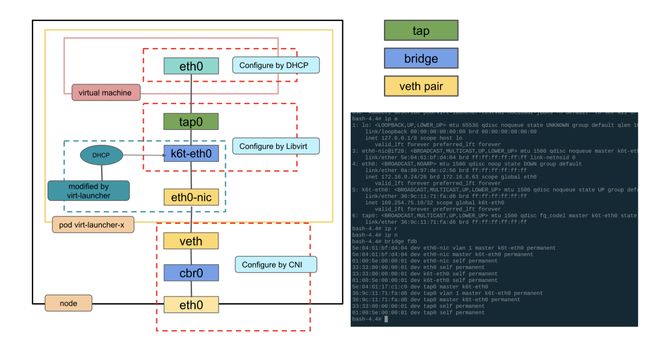
出向:目的地为集群外地址
在虚拟机中查看路由:
[fedora@testvmi-nocloud2 ~]$ ip route
default via 172.16.0.1 dev eth0 proto dhcp metric 100
172.16.0.0/26 dev eth0 proto kernel scope link src 172.16.0.24 metric 100虚拟机 Node1 上所有 Pod 属于同一个 IP 子网 172.20.0.0/26,这些 Pod 都连接到了虚拟网桥 cbr0 上。如上面路由表的第二条路由条目所示,目地地为子网 172.20.0.0/26 的流量将通过虚拟机的 eth0 发出去,eth0 的 Veth pair 对端网卡处于网桥上,因此网桥会收到该数据包。网桥收到数据包后,通过二层转发将该数据包从网桥上连接到目的 Pod 的端口发送出去,数据将到达该端的 Veth pair 对端,即该数据包的目的 Pod 上。
如果是发往外界的 IP,则默认发给网关 172.16.0.1。这里的网关是宿主机上面 cbr0 的地址。
其实这里虚拟机的路由都来自于 launcher Pod 中的路由信息。此时查看 launcher Pod 中的路由信息,已经为空:
[root@VM-4-27-centos ~]# ip r
[root@VM-4-27-centos ~]# ip n查看虚拟机 IP 信息,可以看到虚拟机 IP 为 172.16.0.24,MAC 为 5e:04:61:17:c1:c9,这也是从 launcher Pod 拿来的。
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 5e:04:61:17:c1:c9 brd ff:ff:ff:ff:ff:ff
altname enp1s0
inet 172.16.0.24/26 brd 172.16.0.63 scope global dynamic noprefixroute eth0
valid_lft 85794782sec preferred_lft 85794782sec
inet6 fe80::5c04:61ff:fe17:c1c9/64 scope link
valid_lft forever preferred_lft forever 查看 launcher Pod 中现有的接口,
eth0-nic为 Pod 原来 eth0 的 interfacetap0为虚拟机 eth0 对应的 tap 设备k6t-eth0为 launcher Pod 中的网桥
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0-nic@if28: mtu 1500 qdisc noqueue master k6t-eth0 state UP group default
link/ether 5e:04:61:bf:d4:04 brd ff:ff:ff:ff:ff:ff link-netnsid 0
4: eth0: mtu 1500 qdisc noop state DOWN group default
link/ether 0a:80:97:de:c2:56 brd ff:ff:ff:ff:ff:ff
inet 172.16.0.24/26 brd 172.16.0.63 scope global eth0
valid_lft forever preferred_lft forever
5: k6t-eth0: mtu 1500 qdisc noqueue state UP group default
link/ether 1a:2b:ab:44:18:07 brd ff:ff:ff:ff:ff:ff
inet 169.254.75.10/32 scope global k6t-eth0
valid_lft forever preferred_lft forever
6: tap0: mtu 1500 qdisc fq_codel master k6t-eth0 state UP group default qlen 1000
link/ether 36:9c:11:71:fa:d6 brd ff:ff:ff:ff:ff:ff 可以看到 eth0-nic 和 tap0 都被挂载到网桥 k6t-eth0 上:
# ip link show master k6t-eth0
3: eth0-nic@if28: mtu 1500 qdisc noqueue master k6t-eth0 state UP mode DEFAULT group default
link/ether 5e:04:61:bf:d4:04 brd ff:ff:ff:ff:ff:ff link-netnsid 0
6: tap0: mtu 1500 qdisc fq_codel master k6t-eth0 state UP mode DEFAULT group default qlen 1000
link/ether 36:9c:11:71:fa:d6 brd ff:ff:ff:ff:ff:ff 对于宿主机上 cbr0 的信息:
5: cbr0: mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 92:3f:13:e2:55:c9 brd ff:ff:ff:ff:ff:ff
inet 172.16.0.1/26 brd 172.16.0.63 scope global cbr0
valid_lft forever preferred_lft forever
inet6 fe80::903f:13ff:fee2:55c9/64 scope link
valid_lft forever preferred_lft forever 从虚拟机访问外部网段,比如 8.8.8.8,在 launcher Pod 中抓包,这里在 tap 设备上抓包:
源 IP:虚拟机 eth0 的 IP
源 Mac:虚拟机 eth0 的 MAC
目的 IP:虚拟机网关的 IP,也就是宿主机上的 cbr0 的 IP
目的 Mac: 宿主机上 cbr0 的 MAC
[root@VM-4-27-centos ~]# tcpdump -itap0 -nnvve host 8.8.8.8
dropped privs to tcpdump
tcpdump: listening on tap0, link-type EN10MB (Ethernet), capture size 262144 bytes
20:19:58.369799 5e:04:61:17:c1:c9 > 92:3f:13:e2:55:c9, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 64, id 54189, offset 0, flags [DF], proto ICMP (1), length 84)
172.16.0.24 > 8.8.8.8: ICMP echo request, id 10, seq 1, length 64
20:19:58.371143 92:3f:13:e2:55:c9 > 5e:04:61:17:c1:c9, ethertype IPv4 (0x0800), length 98: (tos 0x64, ttl 117, id 0, offset 0, flags [none], proto ICMP (1), length 84)
8.8.8.8 > 172.16.0.24: ICMP echo reply, id 10, seq 1, length 64Tap 设备接到了网桥上,在网桥 k6t-eth0 设备上抓包,源和目的地址都不变
[root@VM-4-27-centos ~]# tcpdump -ik6t-eth0 -nnvve host 8.8.8.8
dropped privs to tcpdump
tcpdump: listening on k6t-eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
20:28:28.945397 5e:04:61:17:c1:c9 > 92:3f:13:e2:55:c9, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 64, id 21796, offset 0, flags [DF], proto ICMP (1), length 84)
172.16.0.24 > 8.8.8.8: ICMP echo request, id 11, seq 1, length 64
20:28:28.946743 92:3f:13:e2:55:c9 > 5e:04:61:17:c1:c9, ethertype IPv4 (0x0800), length 98: (tos 0x64, ttl 117, id 0, offset 0, flags [none], proto ICMP (1), length 84)
8.8.8.8 > 172.16.0.24: ICMP echo reply, id 11, seq 1, length 64接下来会在 Pod 原来的网口 eth0-nic 上抓到包,源和目的地址都不变:
[root@VM-4-27-centos ~]# tcpdump -ieth0-nic -nnvve host 8.8.8.8
dropped privs to tcpdump
tcpdump: listening on eth0-nic, link-type EN10MB (Ethernet), capture size 262144 bytes
20:30:02.087639 5e:04:61:17:c1:c9 > 92:3f:13:e2:55:c9, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 64, id 2902, offset 0, flags [DF], proto ICMP (1), length 84)
172.16.0.24 > 8.8.8.8: ICMP echo request, id 11, seq 94, length 64
20:30:02.088959 92:3f:13:e2:55:c9 > 5e:04:61:17:c1:c9, ethertype IPv4 (0x0800), length 98: (tos 0x64, ttl 117, id 0, offset 0, flags [none], proto ICMP (1), length 84)
8.8.8.8 > 172.16.0.24: ICMP echo reply, id 11, seq 94, length 64网桥 k6t-eth0 是怎么知道应该把包给到 eth0-nic 呢?这里是在 k6t-eth0 网桥这里做了flood,所有挂接到网桥上的接口都可以抓到访问 8.8.8.8。
虚拟机是怎么知道 172.16.0.1 对应的 MAC 呢?在虚拟机查看 ARP
[fedora@testvmi-nocloud2 ~]$ ip n
172.16.0.1 dev eth0 lladdr 92:3f:13:e2:55:c9 REACHABLE这里即是 cbr0 的 MAC,干掉这个表项之后,可以抓到对应的 arp 包
到达 eth0-nic 之后,就可以到达 Pod 对端的 veth 网口上了,按照全局路由的模式从节点出去。
入向:从节点上访问虚拟机
在全局路由模式中,对于本节点全局路由网段的 IP,默认走节点上的网桥 cbr0
[root@VM-4-27-centos ~]# ip r
172.16.0.0/26 dev cbr0 proto kernel scope link src 172.16.0.1cbr0 网桥挂载了 Pod 的 veth,对于访问虚拟机的 IP,默认通过网桥二层转发到 Pod 对应的 veth pair。到达 Pod 之后,走 Pod 里面的网桥,给到 tap 设备,最后到达虚拟机。
VPC CNI 模式 bridge 网络原理
对于 VPC CNI 网络模式,使用 bridge 的 虚拟机,基本原理与全局路由类似,但是会发现从虚拟机不能访问外网。从 tap 设备也不能够抓到对应的 ip 包,只能抓到 ARP 包。
VPC CNI 模式,Pod 中有默认路由给到缺省网关 169.254.1.1,并且会设置 静态 ARP 条目。Pod 常见设置:
➜ ~ k exec network-tool-549c7756bd-6tfkf -- route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 169.254.1.1 0.0.0.0 UG 0 0 0 eth0
169.254.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
➜ ~ k exec network-tool-549c7756bd-6tfkf -- arp
Address HWtype HWaddress Flags Mask Iface
169.254.1.1 ether e2:62:fb:d2:cb:28 CM eth0但是在虚拟机中,只有默认路由,没有静态的 ARP:
[fedora@testvmi-nocloud2 ~]$ ip r
default via 169.254.1.1 dev eth0 proto dhcp metric 100
169.254.1.1 dev eth0 proto dhcp scope link metric 100
[fedora@testvmi-nocloud2 ~]$ ip n
10.3.1.6 dev eth0 lladdr d2:e9:79:c9:e6:2d STALE
169.254.1.1 dev eth0 INCOMPLETE我们可以从虚拟机和 Pod 中的网桥抓到对应的 ARP 包,但是没有地方给出响应,所以
# 进入 launcher pod netns
[root@VM-1-6-centos ~]# tcpdump -itap0 -nnvve arp
dropped privs to tcpdump
tcpdump: listening on tap0, link-type EN10MB (Ethernet), capture size 262144 bytes
15:46:20.627859 d2:e9:79:c9:e6:2d > 92:7b:a5:ca:24:5a, ethertype ARP (0x0806), length 42: Ethernet (len 6), IPv4 (len 4), Request who-has 10.3.4.17 tell 10.3.1.6, length 28
15:46:20.628185 92:7b:a5:ca:24:5a > d2:e9:79:c9:e6:2d, ethertype ARP (0x0806), length 42: Ethernet (len 6), IPv4 (len 4), Reply 10.3.4.17 is-at 92:7b:a5:ca:24:5a, length 28
[root@VM-1-6-centos ~]# tcpdump -ik6t-eth0 -nnvve arp
dropped privs to tcpdump
tcpdump: listening on k6t-eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
15:47:12.653020 92:7b:a5:ca:24:5a > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Ethernet (len 6), IPv4 (len 4), Request who-has 169.254.1.1 tell 10.3.4.17, length 28
15:47:13.676948 92:7b:a5:ca:24:5a > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Ethernet (len 6), IPv4 (len 4), Request who-has 169.254.1.1 tell 10.3.4.17, length 28
[root@VM-1-6-centos ~]# tcpdump -ieth0-nic -nnvve arp
dropped privs to tcpdump
tcpdump: listening on eth0-nic, link-type EN10MB (Ethernet), capture size 262144 bytes
15:47:23.918394 92:7b:a5:ca:24:5a > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Ethernet (len 6), IPv4 (len 4), Request who-has 169.254.1.1 tell 10.3.4.17, length 28
15:47:24.940922 92:7b:a5:ca:24:5a > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Ethernet (len 6), IPv4 (len 4), Request who-has 169.254.1.1 tell 10.3.4.17, length 28
# 在宿主机 node netns,针对 pod 的 veth pair 抓包
[root@VM-1-6-centos ~]# tcpdump -ienib7c8df57e35 -nnvve arp
dropped privs to tcpdump
tcpdump: listening on enib7c8df57e35, link-type EN10MB (Ethernet), capture size 262144 bytes
15:48:03.853968 92:7b:a5:ca:24:5a > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Ethernet (len 6), IPv4 (len 4), Request who-has 169.254.1.1 tell 10.3.4.17, length 28
15:48:04.876960 92:7b:a5:ca:24:5a > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Ethernet (len 6), IPv4 (len 4), Request who-has 169.254.1.1 tell 10.3.4.17, length 28如果给虚拟机添加上这条静态路由,则可以打通虚拟机网络,这里的 mac 是 Pod 的 veth pair 的 mac 地址:
[fedora@testvmi-nocloud2 ~]$ sudo ip n replace 169.254.1.1 lladdr d2:e9:79:c9:e6:2d dev eth0
[fedora@testvmi-nocloud2 ~]$ ping baidu.com
PING baidu.com (220.181.38.251) 56(84) bytes of data.
64 bytes from 220.181.38.251 (220.181.38.251): icmp_seq=1 ttl=48 time=46.2 ms
64 bytes from 220.181.38.251 (220.181.38.251): icmp_seq=2 ttl=48 time=46.5 ms网络代码阅读
参考 https://github.com/kubevirt/kubevirt/blob/main/docs/devel/networking.md,Kubevirt 中 VM 的 Interface 的配置划分为两个 Phase:
https://github.com/kubevirt/kubevirt/blob/main/docs/devel/networking.md#privileged-vmi-networking-configuration: 在 virt-handler 进程中实现
https://github.com/kubevirt/kubevirt/blob/main/docs/devel/networking.md#unprivileged-vmi-networking-configuration: occurs in the virt-launcher process
Phase1
Phase1 的第一步是决定改使用哪种 BindMechanism,每个 BindMechanism 实现了以下方法:
type BindMechanism interface {
discoverPodNetworkInterface() error
preparePodNetworkInterfaces() error
loadCachedInterface(pid, name string) (bool, error)
setCachedInterface(pid, name string) error
loadCachedVIF(pid, name string) (bool, error)
setCachedVIF(pid, name string) error
// The following entry points require domain initialized for the
// binding and can be used in phase2 only.
decorateConfig() error
startDHCP(vmi *v1.VirtualMachineInstance) error
}一旦 BindMechanism 确定,则依次调用以下方法:
discoverPodNetworkInterface:获取 Pod 网卡设备相关的信息,包括 IP 地址,路由,网关等信息
preparePodNetworkInterfaces:基于前面获取的信息,配置网络
setCachedInterface:缓存接口信息在内存中
setCachedVIF:在文件系统中持久化 VIF 对象,地址
/proc/./root/var/run/kubevirt-private/vif-cache- .json
func (l *podNIC) PlugPhase1() error {
// There is nothing to plug for SR-IOV devices
if l.vmiSpecIface.SRIOV != nil {
return nil
}
state, err := l.state()
if err != nil {
return err
}
switch state {
case cache.PodIfaceNetworkPreparationStarted:
return errors.CreateCriticalNetworkError(fmt.Errorf("pod interface %s network preparation cannot be resumed", l.podInterfaceName))
case cache.PodIfaceNetworkPreparationFinished:
return nil
}
if err := l.setPodInterfaceCache(); err != nil {
return err
}
if l.infraConfigurator == nil {
return nil
}
if err := l.infraConfigurator.DiscoverPodNetworkInterface(l.podInterfaceName); err != nil {
return err
}
dhcpConfig := l.infraConfigurator.GenerateNonRecoverableDHCPConfig()
if dhcpConfig != nil {
log.Log.V(4).Infof("The generated dhcpConfig: %s", dhcpConfig.String())
err = cache.WriteDHCPInterfaceCache(l.cacheCreator, getPIDString(l.launcherPID), l.podInterfaceName, dhcpConfig)
if err != nil {
return fmt.Errorf("failed to save DHCP configuration: %w", err)
}
}
domainIface := l.infraConfigurator.GenerateNonRecoverableDomainIfaceSpec()
if domainIface != nil {
log.Log.V(4).Infof("The generated libvirt domain interface: %+v", *domainIface)
if err := l.storeCachedDomainIface(*domainIface); err != nil {
return fmt.Errorf("failed to save libvirt domain interface: %w", err)
}
}
if err := l.setState(cache.PodIfaceNetworkPreparationStarted); err != nil {
return fmt.Errorf("failed setting state to PodIfaceNetworkPreparationStarted: %w", err)
}
// preparePodNetworkInterface must be called *after* the Generate
// methods since it mutates the pod interface from which those
// generator methods get their info from.
if err := l.infraConfigurator.PreparePodNetworkInterface(); err != nil {
log.Log.Reason(err).Error("failed to prepare pod networking")
return errors.CreateCriticalNetworkError(err)
}
if err := l.setState(cache.PodIfaceNetworkPreparationFinished); err != nil {
log.Log.Reason(err).Error("failed setting state to PodIfaceNetworkPreparationFinished")
return errors.CreateCriticalNetworkError(err)
}
return nil
}Phase2
Phase2 运行在 virt-launcher 中,相比于 phase1 所具有的权限会很多,网络中只具有 CAP_NET_ADMIN 权限。Phase2 也会选择正确的 BindMechanism,然后取得 Phase1 的配置信息(by loading cached VIF object)。基于 VIF 信息, proceed to decorate the domain xml configuration of the VM it will encapsulate
loadCachedInterfaceloadCachedVIFdecorateConfig
func (l *podNIC) PlugPhase2(domain *api.Domain) error {
precond.MustNotBeNil(domain)
// There is nothing to plug for SR-IOV devices
if l.vmiSpecIface.SRIOV != nil {
return nil
}
if err := l.domainGenerator.Generate(); err != nil {
log.Log.Reason(err).Critical("failed to create libvirt configuration")
}
if l.dhcpConfigurator != nil {
dhcpConfig, err := l.dhcpConfigurator.Generate()
if err != nil {
log.Log.Reason(err).Errorf("failed to get a dhcp configuration for: %s", l.podInterfaceName)
return err
}
log.Log.V(4).Infof("The imported dhcpConfig: %s", dhcpConfig.String())
if err := l.dhcpConfigurator.EnsureDHCPServerStarted(l.podInterfaceName, *dhcpConfig, l.vmiSpecIface.DHCPOptions); err != nil {
log.Log.Reason(err).Criticalf("failed to ensure dhcp service running for: %s", l.podInterfaceName)
panic(err)
}
}
return nil
}BindMechanism
DiscoverPodNetworkInterface
func (b *BridgePodNetworkConfigurator) DiscoverPodNetworkInterface(podIfaceName string) error {
link, err := b.handler.LinkByName(podIfaceName)
if err != nil {
log.Log.Reason(err).Errorf("failed to get a link for interface: %s", podIfaceName)
return err
}
b.podNicLink = link
addrList, err := b.handler.AddrList(b.podNicLink, netlink.FAMILY_V4)
if err != nil {
log.Log.Reason(err).Errorf("failed to get an ip address for %s", podIfaceName)
return err
}
if len(addrList) == 0 {
b.ipamEnabled = false
} else {
b.podIfaceIP = addrList[0]
b.ipamEnabled = true
if err := b.learnInterfaceRoutes(); err != nil {
return err
}
}
b.tapDeviceName = virtnetlink.GenerateTapDeviceName(podIfaceName)
b.vmMac, err = virtnetlink.RetrieveMacAddressFromVMISpecIface(b.vmiSpecIface)
if err != nil {
return err
}
if b.vmMac == nil {
b.vmMac = &b.podNicLink.Attrs().HardwareAddr
}
return nil
}PreparePodNetworkInterface
func (b *BridgePodNetworkConfigurator) PreparePodNetworkInterface() error {
// Set interface link to down to change its MAC address
b.handler.LinkSetDown(b.podNicLink)
if b.ipamEnabled {
// Remove IP from POD interface
err := b.handler.AddrDel(b.podNicLink, &b.podIfaceIP)
b.switchPodInterfaceWithDummy();
// Set arp_ignore=1 to avoid
// the dummy interface being seen by Duplicate Address Detection (DAD).
// Without this, some VMs will lose their ip address after a few
// minutes.
b.handler.ConfigureIpv4ArpIgnore();
}
b.handler.SetRandomMac(b.podNicLink.Attrs().Name);
err := b.createBridge();
tapOwner := netdriver.LibvirtUserAndGroupId
if util.IsNonRootVMI(b.vmi) {
tapOwner = strconv.Itoa(util.NonRootUID)
}
createAndBindTapToBridge(b.handler, b.tapDeviceName, b.bridgeInterfaceName, b.launcherPID, b.podNicLink.Attrs().MTU, tapOwner, b.vmi)
b.handler.LinkSetUp(b.podNicLink);
b.handler.LinkSetLearningOff(b.podNicLink);
return nil
}参考资料
https://kubevirt.io/user-guide/
https://github.com/kubevirt/containerized-data-importer#deploy-it
https://github.com/kubevirt/hostpath-provisioner
http://kubevirt.io/api-reference
https://kubevirt.io/user-guide/virtual_machines/disks_and_volumes/
https://kubevirt.io/user-guide/virtual_machines/interfaces_and_networks/
https://github.com/kubevirt/kubevirt/blob/main/docs/devel/networking.md
https://www.cnblogs.com/ryanyangcs/p/14079144.html
原文链接:https://houmin.cc/posts/b2eff5e7/
本文转载自:「k8s技术圈」,原文:https://url.hi-linux.com/Kf2t5,版权归原作者所有。欢迎投稿,投稿邮箱: [email protected]。

最近,我们建立了一个技术交流微信群。目前群里已加入了不少行业内的大神,有兴趣的同学可以加入和我们一起交流技术,在 「奇妙的 Linux 世界」 公众号直接回复 「加群」 邀请你入群。
![]()
你可能还喜欢
点击下方图片即可阅读
使用 Thanos 和 Prometheus 打造一个高可用的 Kubernetes 监控系统
点击上方图片,『美团|饿了么』外卖红包天天免费领

更多有趣的互联网新鲜事,关注「奇妙的互联网」视频号全了解!