RetinaNet算法笔记
RetinaNet算法笔记
- 1.核心思想
-
- 1.1 focal loss损失
- 1.2 简单的网络结构
- 2.网络结构
-
- 2.1 backbone网络
- 2.2 FPN网络
- 2.3 head网络
-
- 2.3.1 分类子网络
- 2.3.2 回归子网络
- 3.损失函数计算
-
- 3.1 anchor及正负样本分配
-
- 3.1.1 anchor的基础尺寸、长宽比、尺度
- 3.1.2 正负样本分配
- 3.2 边界框回归损失函数
- 3.3 focal loss分类损失
-
- 3.3.1 standard binary cross entropy
-
- 3.3.1.1 基本公式
- 3.3.1.2 简单/困难样本的定义
- 3.3.2 Balanced Cross Entropy(BCE)
-
- 3.3.2.1 基本公式
- 3.3.2.2 类内前景背景类不平衡和类间不平衡
- 3.3.2.3 总结
- 3.3.3 focal loss
-
- 3.3.3.1 基本形式
- 3.3.3.2 focal loss分类损失计算
- 4.推理
- 5.总结以及疑问
本文的大多数公式、图均来自RetinaNet原论文,其余来自自己编辑,下文不再阐述。
1.核心思想
1.1 focal loss损失
一阶段检测器整体流程简单、速度更快,但是精度比不过二阶段检测器。本文发现精度低的主要原因是前景背景不平衡(不是具体目标类别间的不平衡),因为只有少量的anchor才会预测gt box,这些称为正样本,也叫前景类;此外还有大量的anchor没有分配任何gt box,去掉忽略样本外,剩下的未分配anchor仍然会参与计算损失,这些为负样本。这些简单负样本的数量大大超过正样本的数量,其产生的损失主导了总损失从而主导了训练,这就是前景背景类别不平衡问题。
为了解决前景背景类别不平衡问题,本篇论文设计了focal loss,降低简单样本的损失的权重,使网络关注困难样本的训练。
注意,focal loss只是区分简单样本和困难样本,不区分正负样本,只不过在目标检测领域简单样本大多为负样本(纯背景样本)罢了,所以focal loss主要降低的是简单负样本的权重,下文详述。
RetinaNet网络第一次使one-stage检测算法具有可以和two-stage算法相比较的精度,意义重大。
1.2 简单的网络结构
为了便于验证focal loss的作用,RetinaNet使用现有的ResNet,并对FPN进行了简单改进,再加上head网络,设计了一个极为简单的检测网络,这个检测网络并不是RetinaNet的重点。
2.网络结构
简单讲一下RetinaNet的网络结构,方便后续讨论focal loss,网络结构如下图。

2.1 backbone网络
ResNet网络,没有改动。
2.2 FPN网络
在原有的FPN基础上,进行了微小的改进。原始的FPN使用P2-P6层级,而RetinaNet使用P3-P7特征层级,因为P2的计算量太大,P7可以提高大目标的检测能力。此外,原始的P6是C5下采样得到的,而本文的P6是C5+3x3conv-stride2得到,P7是P6先进行ReLu再进行3x3conv-stride2得到。
2.3 head网络
RetinaNet的head是解耦head ,由两部分组成:分类子网络head和回归子网络head组成。
注意:RetinaNet只有两个预测分支,没有第三个分支,不像YOLOv3或者FCOS那样,还有一个置信度或者centerness分支。
2.3.1 分类子网络
4个3x3的conv+ReLu,通道数均为256,最后一个是3x3conv+sigmoid,通道数为KA,A是anchor个数,K是类别个数,如COCO为80。所有特征层级共享分类head。
注意,是K个二分类器,不是一个softmax多分类器,和YOLOv3一样。
2.3.2 回归子网络
网络结构和分类子网络一样,只是最后的输出层的激活函数和通道数不一样,使用线性激活(无激活),4*A个通道。应该也是所有层级共享回归head,并且边界框编解码方式和R-CNN一样。
3.损失函数计算
3.1 anchor及正负样本分配
3.1.1 anchor的基础尺寸、长宽比、尺度
P3-P7特征层级上anchors的基础尺寸分别为322-5122,长宽比为{1:2,1:1,2:1},尺度分别为{20,2(1/3),2^(2/3)},即每个层级有9个anchors。
3.1.2 正负样本分配
分配方式和Faster RCNN一样,但是分配IOU阈值不一样。具体而言,对于每个gt box,和它的IOU阈值大于0.5的anchor,都是正样本,这些正样本anchor,其类别回归标签是one-hot形式,也就是没有标签平滑(RPN中是不分类别的提案框,因此类别标签是1);那些和所有gt box的IOU都小于0.4的,是背景样本;0.4-0.5之间的是忽略样本。作为对比,faster RCNN的两个阈值是0.3和0.7。
3.2 边界框回归损失函数
使用的是标注的smooth L1 loss,边界框编解码方式和R-CNN一样,并且只有正样本才计算回归损失。
3.3 focal loss分类损失
RetinaNet的重点,也是本笔记的重中之重,会涉及简单/困难样本的划分、前景/背景类不平衡问题的阐述等等,以及focal loss解决的到底是这两个问题中的哪个问题。
3.3.1 standard binary cross entropy
3.3.1.1 基本公式
首先看binary cross entropy loss,原论文公式如下(对公式进行了重写),对数应该是以e为底的。

从公式中可以看出,p是分类器给出的当前样本属于该类别的概率,如果p很小(一般<0.5),说明分类器认为样本不是该类别;如果概率很大(一般>0.5),说明分类器认为当前样本是该类别。可以看出,p的定义没有考虑样本的标签,不管该样本的标签是或不是该类别,仅看p无法判断分类器是否预测正确。
改写公式后,pt的定义中考虑了样本的标签,pt的实际含义是:pt的大小表明了分类器分类正确的程度,如果pt很大(>0.5),说明分类器分类正确(不管样本是不是该类别);如果pt很小,说明分类器分类错误。
3.3.1.2 简单/困难样本的定义
由pt定义的binary cross entropy loss图如下所示

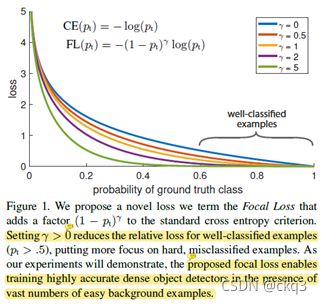
从图中可以看到CE loss曲线,如果pt很大,说明分类器分类正确,该样本产生的损失就比较小,说明对当前分类器来讲,该样本已经分类正确了,这是个很简单的样本;如果pt很小,说明分类器错误,损失就比较大,说明对当前分类器来讲,该样本还不能正确分类,这是个困难样本。
标准交叉熵损失的问题是:即便是很简单的样本(pt>>0.5,比如说pt=0.8),还是会产生不可忽视的损失。对one-stage检测器来说,由于存在大量简单样本(纯背景样本),这些简单样本叠加起来,可能会超过困难样本的损失,导致训练效果不好。
因此,one-stage检测器精度低的问题,可以说是简单/困难样本的loss不平衡问题,但因为大多简单样本就是背景样本,所以也可以说是前景/背景类别不平衡问题,。
下面也是分别从前景/背景类别不平衡和简单/困难不平衡两个角度来解决。
3.3.2 Balanced Cross Entropy(BCE)
3.3.2.1 基本公式
BCE用来解决类别不平衡问题。添加一个加权因子α,如果样本属于该类别,产生的损失的权重为α;如果不属于该类别,权重为1-α,公式如下:

为便于表示和计算,我们将p表示为pt的形式,并以同样的方式表示α,公式如下:
![]()
3.3.2.2 类内前景背景类不平衡和类间不平衡
(1)类内前景背景类不平衡
上述所讲的类别不平衡,指的是同一个目标类别内的前景类/背景类的类别不平衡,比如说对于某一个类别car,我们假设只有一个特征层级,那么网络共有num_anchor个car二值分类器(每个anchor有C个二值分类器,car二值分类器是C个分类器中的一个),共需要对HWnum_anchor个样本进行预测(因为输出特征图尺寸为H*W,每个位置都是一个样本),假设这张图像中有一个car,那么只有少数几个二值分类器分配到前景样本car,大多数其它car二值分类器是背景样本,所以对car二值分类器来讲,就有非常严重的前景/背景不平衡问题,其实对其它具体目标类别也有前景/背景不平衡问题。
这里的α,是当前样本属于类别car时,car二值分类器产生的损失的权重,如果当前样本不是car,比如说是truck或者是纯背景,那么car二值分类器产生的损失的权重就是1-α。
(2)类间不平衡
其实BCE还可以缓解目标类别之间的类别不平衡问题(类别长尾分布),那就是不同的类别设置不同的α,比如COCO(80个目标类别),就需要设置80个α。
3.3.2.3 总结
BCE可以缓解同一个目标类别内的前景类背景类不平衡,也可以缓解不同具体目标类别间的类别不平衡,RetinaNet中指的是同一个目标类别内的前景类背景类不平衡。
疑问:RetinaNet中的BCE指的是同一个目标类别内的前景类背景类不平衡,既然前景少背景多,那就应该增加前景类的权重,因此α应该大于0.5才对。但是论文中,作者发现,当仅仅使用BCE而不用focal loss时,α=0.75最好,这符合我们的预期;但是当使用focal loss时,α反而取0.25更好,也就是数量少的前景反而权重小,数量大的背景权重大,虽然作者表示focal loss会降低对α的需求,但还是理解不了为什么会<0.5。
3.3.3 focal loss
BCE缓解了前景背景之间的类别不平衡问题,但是没有解决区分简单样本和困难样本,因此提出了focal loss,focal loss解决的是简单/困难样本之间的平衡问题,而不是前景背景不平衡,只不过简单样本大多是背景样本罢了 。
3.3.3.1 基本形式
在标注交叉熵损失基础上添加一个调制项,降低简单样本(loss小的样本)的权重,构成了focal loss的基本形式,而RetinaNet使用了BCE的focal loss形式,公式如下:
![]()
总结:式中, 是最基本的交叉熵损失, 平衡前景/背景不平衡问题, 平衡简单/困难样本不平衡问题。
不同的γ取值,获得的对简单样本的抑制效果如下图所示
3.3.3.2 focal loss分类损失计算
(1)和yolov3中只计算正样本的分类损失不同,RetinaNet是计算所有样本的分类损失,包括正样本、负样本、忽略样本。
(2)计算所有样本的分类损失后,求和,并以正样本个数进行归一化。
(3)实验中,发现γ=2最好,但yolov5中使用的是EfficientDet中的值1.5。
4.推理
(1)前向传播;
(2)NMS前阈值处理:使用置信度0.05进行过滤,并且每个FPN层级最多选1000个框;
(3)NMS处理:把所有层级保留的框都收集起来,进行IOU阈值为0.5的NMS。
5.总结以及疑问
(1)RetinaNet使one-stage检测算法第一次接近了two-stage算法的精度,尤其是focal loss的提出,意义重大。
(2)focal loss完整公式如下
![]()
式中, 是最基本的交叉熵损失, 平衡同一类别内的前景/背景不平衡问题, 平衡简单/困难样本不平衡问题。
只考虑 而不考虑的 话,focal loss其实解决的是简单/困难样本不平衡问题,只不过one-stage算法中简单样本大多是背景样本,因此也可以说focal loss解决的是前景背景不平衡问题。
(3)疑问
focal loss中α参数用来平衡同一类别内的前景/背景不平衡问题,按理说应该>0.5才对,但是实验结果是γ=2.0,α=0.25最好。作者解释说,当γ增大时,就降低了简单背景样本的权重了,就不需要特别强调前景的权重了,所以α应该变小,这一点我认为很对,但是我认为不应该<0.5,不然就无法起到强调前景的作用了,欢迎大家讨论。