性能是A100 2.4倍,AMD官宣两款HPC新品,还拿下了Meta
计算机视觉研究院专栏
作者:Edison_G
AMD 宣布将在 2022 年初推出带有 AMD 3D V-Cache 的第三代 EPYC 处理器和 Instinct MI200 系列 GPU 加速器。
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
本篇文章转自于“机器之心”

几年来,AMD 一直在行业内稳步前进。一方面,它在消费芯片市场与传统竞争对手英特尔、英伟达竞争;另一方面,AMD 正在努力重新进入处理器行业的关键领域:服务器市场。
随着创建和生成的数据越来越多,对能够分析海量数据并从中做出推断的高性能计算平台的需求呈指数增长。现在,AMD 宣布将在 2022 年初推出带有 AMD 3D V-Cache 的第三代 EPYC 处理器和 Instinct MI200 系列 GPU 加速器,旨在使用领先的内存和互连技术满足这些需求,这些技术将为 AMD 的数据中心产品和平台带来显著的性能改进。
搭载 AMD 3D V-Cache 的第三代 EPYC 处理器
几个月前,AMD 透露其消费级锐龙处理器将采用 3D V-Cache 技术。3D V-Cache 本质上是在台积电 7nm 节点上制造的 64MB SRAM 缓存,它直接连接在基于 Zen3 的处理器中每个 CCD 的顶部,将处理器内核可用的高速 L3 缓存量有效地增加了三倍。额外的缓存使用 TSV 直接与 CCD 相连,没有任何焊接凸点(soldered bump)。现在,AMD 的 EPYC 服务器处理器也将拥有这些优势。

带有 AMD 3D V-Cache 的第三代 AMD EPYC 处理器。
为了将 3D V-Cache 引入 EPYC,AMD 与台积电合作,将缓存裸晶(die)减薄并添加必要的硅结构,将缓存和计算 die 粘合成一个无缝表面。组装好的 3D 堆叠芯片具有与 AMD 标准处理器芯片相似的外形,具有 3D V-cache 的第三代 EPYC 处理器与现有平台和插槽引脚兼容。
在计算能力方面,具有 3D V-Cache 的第三代 EPYC 处理器与现有的 EPYC 处理器相似。它们将提供多达 64 个内核(128 个线程),但具有 3D V-Cache 的新处理器能提供高达 3 倍的 L3 缓存。具有 3D V-cache 的第三代 EPYC 处理器每个插槽将具有高达 804MB 的总缓存,这比现有的 EPYC 处理器(最高为 256MB)有了巨大的提升。基于此,AMD 声称在某些 HPC 工作负载中性能可以提高 50%。

带有 AMD 3D V-Cache 的第三代 AMD EPYC 的性能。
与竞品相比,AMD 声称在 Ansys 机械有限元分析工作负载中,双插槽 32 核 2P EYPC 75F3 系统优于 32 核 2P Xeon 8362 系统高达 33%。在由 Altair Radioss 进行的 Structural 分析测试中该优势高达 34%,在 Ansys CFX 流体动力学分析中高达 40%。
Instinct MI200:首款 6nm 多芯片封装 GPU
除了配备 3DV 的第三代 EPYC 处理器外,AMD 还推出了迄今为止最强大的 GPU 加速器「AMD Instinct MI200 系列」。与基于 RDNA 2 架构、面向消费者的 Radeon 系列 GPU 不同,AMD Instinct 加速器采用 CDNA 2 架构,它专为高性能标量和矢量处理工作负载设计,并结合了新的矩阵核心引擎。
AMD 表示,面向数据中心的最新 GPU 的高性能计算 (HPC) 速度将提高 9.5 倍,AI 工作负载的速度将比竞品 GPU 快 1.2 倍(例如英伟达 GPU)。Instinct MI200 是专为数据中心设计的一系列 GPU 中的最新款,而非面向游戏和桌面图形处理。
对于此次更新,AMD 特别专注于提升双精度浮点运算的性能,这就是为什么声称 HPC 的性能改进大于 AI 处理的原因。AMD 数据中心 GPU 加速器企业副总裁 Brad McCreadie 表示:「我们的目标是让这款设备在需要双精度运算的最棘手的科学问题上做到非常好,这就是我们向前迈出的最大一步。」

AMD Instinct MI200.
AMD Instinct MI200 系列 GPU 加速器采用双芯片设计,由大约 580 亿个晶体管(6nm 制造)组成。MI200 将拥有多达 14080 个流处理器,组装为 220 个 CU(计算单元),具有多达 880 个第二代矩阵内核,搭配高达 128GB(8 堆栈)的 1.6GHz HBM2E 显存,通过 8192 位的接口,实现 3.2 TB/s 的峰值内存带宽。MI200 系列还包含多达 8 个第三代 Infinity Fabric 链路,在 Instinct MI200 GPU 加速器和 EPYC 处理器之间提供高带宽连接。

AMD Instinct MI200 系列的特性和技术。
为了构建这些双芯片 GPU 加速器,AMD 正在使用一种新的封装技术,名为「2.5D Elevated Fanout Bridge(EFB)」。EFB 是一种超高带宽芯片互连方法,可用于标准基板和倒装芯片制造处理器,与同类的多芯片互连解决方案相比,其成本和复杂性较低。
Instinct MI250X 将位于 AMD 高性能计算 GPU 堆栈的顶部,并具有完整的 220 CU 和 128GB 的 HBM2E 配置,还会有一个「标准」的 MI250 模型,它在某种程度上减少了 208 个 CU,总共有 13312 个流处理器,但具备相同的内存配置。
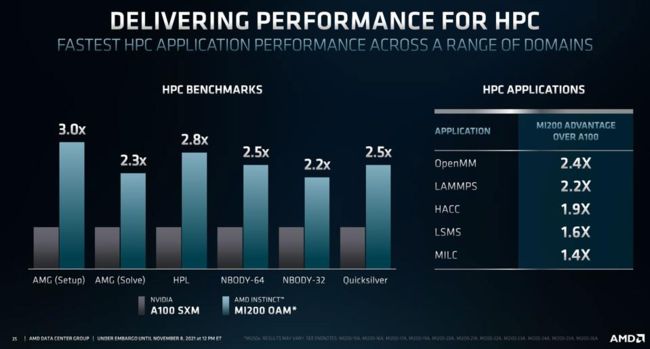
AMD Instinct MI200 vs. NVIDIA A100.
在性能方面,AMD 本次的发布内容依旧令人印象深刻。在一系列 HPC 基准测试中,将 AMD Instinct MI200 OAM 模块与 NVIDIA 的 A100 SXM 进行对比,MI200 提供了 2.2 到 3 倍的计算性能。在一系列 HPC 应用中,AMD 发布了类似的内容,MI200 比 A100 具有 1.4 到 2.4 倍的算力优势。
同时,AMD 宣布了 Facebook 母公司 Meta 数据中心将使用 AMD 生产的芯片。消息公布后,AMD 股价创历史新高,上涨 12% 以上,市值突破 1800 亿美元。

上个月,苏妈表示,最近一个季度,AMD 数据中心芯片的销售额同比增长了一倍,占 AMD 销售额的 20%。数据中心芯片是 AMD 嵌入式、企业级和半定制业务的一部分,该业务上一季度的销售额为 19 亿美元,同比增长 69%。
AMD 的 Instinct MI200 系列加速器将利用开放式硬件计算加速器模块(或 OAM)外形,不过 MI240 也将作为现有服务器的 PCIe 附加卡提供。AMD Instinct MI200 系列 GPU 加速器和具有 3D V-Cache 的第三代 EPYC 处理器都将于 2022 年第一季度上市。
参考链接:https://www.forbes.com/sites/marcochiappetta/2021/11/08/amd-unveils-epyc-with-3d-v-cache-and-powerful-instinct-mi200-accelerators-for-exascale-supercomputers/?ss=ai&sh=46e730e02529
© THE END
转载请联系本公众号获得授权
![]()
计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
MUCNetV2:内存瓶颈和计算负载问题一举突破?分类&检测都有较高性能(附源代码下载)
旋转角度目标检测的重要性!!!(附源论文下载)
双尺度残差检测器:无先验检测框进行目标检测(附论文下载)
Fast YOLO:用于实时嵌入式目标检测(附论文下载)
Micro-YOLO:探索目标检测压缩模型的有效方法(附论文下载)
目标检测干货 | 多级特征重复使用大幅度提升检测精度(文末附论文下载)
多尺度深度特征(下):多尺度特征学习才是目标检测精髓(论文免费下载)
多尺度深度特征(上):多尺度特征学习才是目标检测精髓(干货满满,建议收藏)