Neo4j图数据库使用
Neo4j图数据库使用
使用场景
在当前复杂的大数据场景下,如社交、物流、金融、地图,越来越依赖图形计算来提供更高效、可视化的数据服务,于是各种专用图数据库应运而生
相比较传统的关系型数据库,图数据库天生支持高性能超复杂的关联关系查询,这是最大的优势,以及友好的人机交互可视化数据,擅长处理超复杂的网状关联关系数据,是传统关系型数据库效率的百倍千倍
在社交网络、电信反诈、金融资金流向环路、金融风控、实时推荐、社区发现等具体场景有广泛应用
而当前使用最多,最成熟的就是Neo4j,NASA都在用,所以学它,向qian看
图论基础
- 节点描述域的实体(离散对象)。
- 节点可以有零个或多个标签来定义(分类)它们是哪种类型的节点。
- 关系描述源节点和目标节点之间的连接。
- 关系总是有一个方向(一个方向)。
- 关系必须具有类型(一种类型)才能定义(分类)它们之间的关系类型。
- 节点和关系可以具有属性(键值对),这些属性可以进一步描述它们。
在数学中,图论是对图的研究。
在图中:
- 节点也称为顶点或点。
- 关系也称为边、链接或线。
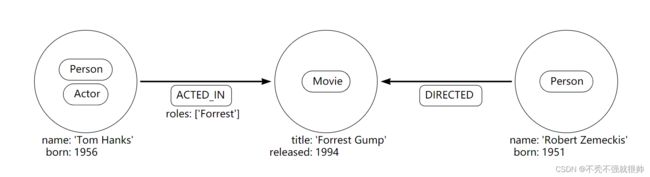
如图,圆形为点,箭头线为边,点和边都有标签类型,表示同一种标签,如Person类型的点、Actor类型的点、ACTED_IN类型的边、Movie、DIRECTED、Person
点和边都有属性,0个或n个键值对类型,如born:1956,边都有方向,同一对点的双向关系一样要两条边
安装
neo4j分社区版企业版,桌面版,我们要在linux上部署,所以用社区版,windows可以用桌面版
系统:ubuntu18.04 server
neo4j: neo4j-community-4.4.3
依赖:JDK11,要先安装,由于neo4j是用scala和java开发的,所以要JRE,而且必须是java11
官网下载:
-
上传到ubuntu,解压
-
添加环境变量到/etc/profile,
export NEO4J_HOME=/opt/neo4j-community-4.4.3 export PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin:$SPARK_HOME/bin:$KYLIN_HOME/bin:$HBASE_HOME/bin:$ROCKETMQ_HOME/bin:$FLINK_HOME/bin:$NEO4J_HOME/bin -
修改conf/neo4j.conf
修改服务主机名,改成自己linux主机名,否则无法远程访问
dbms.connector.bolt.listen_address=h1:7687 dbms.connector.bolt.advertised_address=h1:7687 # HTTP Connector. There can be zero or one HTTP connectors. dbms.connector.http.enabled=true dbms.connector.http.listen_address=h1:7474 dbms.connector.http.advertised_address=h1:7474 -
启动
neo4j start -
访问,用户密码neo4j/neo4j,登录后会提示修改密码
http://h1:7474/browser/

语法
创建方式,页面客户端命令行,交互的方式是Cypher,图库的专用类SQL语言,跟SQL语法完全不同,但增删改查逻辑都类似
创建点
CREATE (p:Person {name: 'Keanu Reeves', born: 1964})
RETURN p

点左侧Graph会看到可视化图,这个p就是一个变量,名称自定义,指向创建的这一点,return返回的就是要显示的变量数据,冒号有点像scala的定义变量写法,冒号前变量名,冒号后变量类型,这里是图顶点label类型,也是自定义类型名,命名规范大驼峰式(首字母全大写类似java class),大括号里的是顶点属性,支持数字,字符串,布尔
创建点边关系
CREATE (a:Person {name: 'Tom Hanks', born: 1956})-[r:ACTED_IN {roles: ['Forrest']}]->(m:Movie {title: 'Forrest Gump', released: 1994})
CREATE (d:Person {name: 'Robert Zemeckis', born: 1951})-[:DIRECTED]->(m)
RETURN a, d, r, m
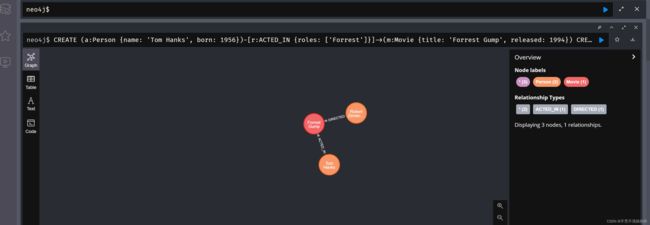
以上创建了一个图pattern,汤姆汉克斯出演阿甘正传,罗伯特*泽米吉斯导演了阿甘正传
边的关系使用“–>”符号,带标签和属性的边用“-[x:LABEL {name: ‘wang’,age: 10}]->”两边分别是两个点,x是变量名,LABEL是边标签类型,大括号内是键值对属性,属性类型支持:数字、字符串、布尔、数组
查询pattern
MATCH (p:Person {name: 'Keanu Reeves'})
RETURN p
这里的MATCH就是匹配图形,按照pattern模式来匹配查找图形,上面就是查询名字叫Keanu Reeves的Person类型的所有顶点
MATCH (p:Person {name: 'Tom Hanks'})-[r:ACTED_IN]->(m:Movie)
RETURN p,r,m
这里查询名叫Tom Hanks的人出演的电影
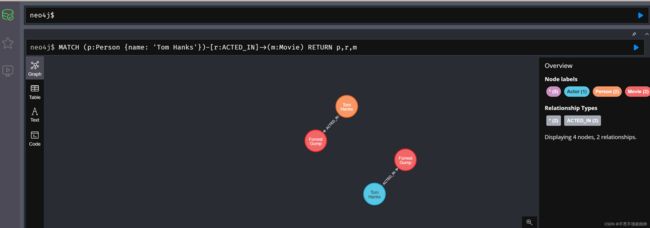
我创建了两次,所有创建了两个一样的,如保证唯一,要加属性唯一约束,类似关系型数据库的主键约束,相同主键属性的数据插入会失败,后面会详细介绍
创建新顶点连接到已有顶点
MATCH (p:Person {name: 'Tom Hanks'})
CREATE (m:Movie {title: 'Cloud Atlas', released: 2012})
CREATE (p)-[r:ACTED_IN {roles: ['Zachry']}]->(m)
RETURN p, r, m
首先查询库已有的名叫Tom Hanks的人,然后创建一个叫Cloud Atlas的电影类型的顶点,再创建关系ACTED_IN,这个人在这个电影里出演了角色Zachry,所以变量无论是创建时定义的还是查询匹配时定义的都能在后续直接使用(p,m,r)
完成模式
在导入外部数据时,当我们不知道库里是否存在某点时,如果存在则不创建也不更新属性,不存在则创建,这个时候需要使用完成模式,类似create table if not exists
MERGE (m:Movie {title: '霸王别姬'})
ON CREATE SET m.released = 1993
RETURN m
MERGE (m:Movie {title: '霸王别姬'})
ON CREATE SET m.released = 2016
RETURN m
我们创建了两次霸王别姬,第二次不会创建,因为库里已有,merge先查库是否存在,不存在则创建,否则不创建,on create set是添加附加属性,可省略
同样可以创建指定边
#创建Actor标签点
merge (p:Actor {name:'张国荣'}) on create set p.born=1956 return p
#创建指定Actor出演的指定电影的关系边,如果已存在则不创建
match (a:Actor {name:'张国荣'}) match (m:Movie {title:'霸王别姬'}) merge (a)-[r:ACTED_IN]->(m) on create set r.roles=['程蝶衣'] return a,r,m

查询过滤
首先把我们创建的图都清空,创建新的图,注意会清空当前库下所有数据,慎用
match (n) detach delete n
创建新的较复杂图用于学习查询语句
CREATE (matrix:Movie {title: 'The Matrix', released: 1997})
CREATE (cloudAtlas:Movie {title: 'Cloud Atlas', released: 2012})
CREATE (forrestGump:Movie {title: 'Forrest Gump', released: 1994})
CREATE (keanu:Person {name: 'Keanu Reeves', born: 1964})
CREATE (robert:Person {name: 'Robert Zemeckis', born: 1951})
CREATE (tom:Person {name: 'Tom Hanks', born: 1956})
CREATE (tom)-[:ACTED_IN {roles: ['Forrest']}]->(forrestGump)
CREATE (tom)-[:ACTED_IN {roles: ['Zachry']}]->(cloudAtlas)
CREATE (robert)-[:DIRECTED]->(forrestGump)
那怎么查刚创建的图呢?我们一步步来
where过滤
MATCH (m:Movie)
WHERE m.title = 'The Matrix'
RETURN m
同样的照着前面我们学过的可以这样查
MATCH (m:Movie {title:'The Matrix'})
RETURN m
使用复杂条件
MATCH (p:Person)-[r:ACTED_IN]->(m:Movie)
WHERE p.name =~ 'K.+' OR m.released > 2000 OR 'Neo' IN r.roles
RETURN p, r, m
注意“=~”表示正则表达式匹配
模式条件过滤
MATCH (p:Person)-[:ACTED_IN]->(m)
WHERE NOT (p)-[:DIRECTED]->()
RETURN p, m
意思是一个人演了电影但没有导演过任何电影,返回这个人和出演的电影
于是返回汤姆汉克斯,和他演的两部电影
return返回值
返回值类型不仅仅可以是点和边,还可以是各种点边属性文本,并支持各种函数
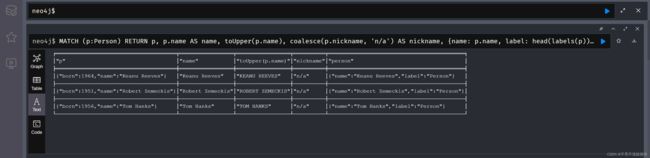
MATCH (p:Person)
RETURN
p,
p.name AS name,
toUpper(p.name),
coalesce(p.nickname, 'n/a') AS nickname,
{name: p.name, label: head(labels(p))} AS person
还可以按标签类型去重
MATCH (n)
RETURN DISTINCT labels(n) AS Labels
╒══════════╕
│"Labels" │
╞══════════╡
│["Movie"] │
├──────────┤
│["Person"]│
└──────────┘
支持聚合
MATCH (:Person)
RETURN count(*) AS people
╒════════╕
│"people"│
╞════════╡
│3 │
└─────
MATCH (actor:Person)-[:ACTED_IN]->(movie:Movie)<-[:DIRECTED]-(director:Person)
RETURN actor, director, count(*) AS collaborations
╒════════════════════════════════╤══════════════════════════════════════╤════════════════╕
│"actor" │"director" │"collaborations"│
╞════════════════════════════════╪══════════════════════════════════════╪════════════════╡
│{"born":1956,"name":"Tom Hanks"}│{"born":1951,"name":"Robert Zemeckis"}│1 │
└────────────────────────────────┴─────────────────
按演员和导演分组计数,统计合作的电影数
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)
RETURN a, count(*) AS appearances
ORDER BY appearances DESC LIMIT 10
╒════════════════════════════════╤═════════════╕
│"a" │"appearances"│
╞════════════════════════════════╪═════════════╡
│{"born":1956,"name":"Tom Hanks"}│2 │
└──────────────────────────
排序和分页,跟sql类似
MATCH (m:Movie)<-[:ACTED_IN]-(a:Person)
RETURN m.title AS movie, collect(a.name) AS cast, count(*) AS actors
╒══════════════╤═════════════╤════════╕
│"movie" │"cast" │"actors"│
╞══════════════╪═════════════╪════════╡
│"Forrest Gump"│["Tom Hanks"]│1 │
├──────────────┼──────
│"Cloud Atlas" │["Tom Hanks"]│1 │
└──────────────┴──────
collect将聚合合并成一个list
union [all]
类似sql,合并两个查询结果集
MATCH (actor:Person)-[r:ACTED_IN]->(movie:Movie)
RETURN actor.name AS name, type(r) AS type, movie.title AS title
UNION
MATCH (director:Person)-[r:DIRECTED]->(movie:Movie)
RETURN director.name AS name, type(r) AS type, movie.title AS title
╒═════════════════╤══════════╤══════════════╕
│"name" │"type" │"title" │
╞═════════════════╪══════════╪══════════════╡
│"Tom Hanks" │"ACTED_IN"│"Forrest Gump"│
├─────────────────┼───────
│"Tom Hanks" │"ACTED_IN"│"Cloud Atlas" │
├─────────────────┼───────
│"Robert Zemeckis"│"DIRECTED"│"Forrest Gump"│
└─────────────────┴──────┘
同样的作用,还可以这样写,表示某人出演或导演某电影
MATCH (actor:Person)-[r:ACTED_IN|DIRECTED]->(movie:Movie)
RETURN actor.name AS name, type(r) AS type, movie.title AS title
with子句
使用with子句可以在后续直接使用子句变量,组成大的复杂查询
MATCH (person:Person)-[:ACTED_IN]->(m:Movie)
WITH person, count(*) AS appearances, collect(m.title) AS movies
WHERE appearances > 1
RETURN person.name, appearances, movies
查询写入优化
创建索引
CREATE INDEX example_index_1 FOR (a:Actor) ON (a.name)
CREATE INDEX example_index_2 FOR (a:Actor) ON (a.name, a.born)
类似sql,索引可以提前排序,极大加快查询速度,索引是隐式的,自动会走索引查询:example_index_1
MATCH (actor:Actor {name: 'Tom Hanks'})
RETURN actor
可以查看已定义的索引列表
SHOW INDEXES YIELD name, labelsOrTypes, properties, type
╒═════════════════╤═══════════════╤═══════════════╤════════╕
│"name" │"labelsOrTypes"│"properties" │"type" │
╞═════════════════╪═══════════════╪═══════════════╪════════╡
│"example_index_1"│["Actor"] │["name"] │"BTREE" │
├─────────────────┼───────────────┼───────────────┼────────┤
│"example_index_2"│["Actor"] │["name","born"]│"BTREE" │
├─────────────────┼───────────────┼───────────────┼────────┤
│"index_343aff4e" │null │null │"LOOKUP"│
├─────────────────┼───────────────┼───────────────┼────────┤
│"index_f7700477" │null │null │"LOOKUP"│
└─────────────────┴───────────────┴───────────────┴────────┘
创建约束
创建唯一性约束
CREATE CONSTRAINT constraint_example_1 FOR (movie:Movie) REQUIRE movie.title IS UNIQUE
这里创建点为Movie类型,title属性要唯一,否则插入同样属性点会失败
我们再创建一个同样title的电影
create (m:Movie {title:'The Matrix'})
会直接报错

查询库内已定义的所有约束
SHOW CONSTRAINTS YIELD id, name, type, entityType, labelsOrTypes, properties, ownedIndexId
╒════╤══════════════════════╤════════════╤════════════╤═══════════════╤════════════╤══════════════╕
│"id"│"name" │"type" │"entityType"│"labelsOrTypes"│"properties"│"ownedIndexId"│
╞════╪══════════════════════╪════════════╪════════════╪═══════════════╪════════════╪══════════════╡
│6 │"constraint_example_1"│"UNIQUENESS"│"NODE" │["Movie"] │["title"] │5 │
└────┴──────────────────────┴────────────┴────────────┴───
数据导入
数据删除
导入数据前避免约束、索引导致的失败,先删除所有数据、约束、索引
match (n) detach delete n
查询当前库所有索引和约束
:schema
Index Name Type Uniqueness EntityType LabelsOrTypes Properties State
example_index_2 BTREE NONUNIQUE NODE [ "Actor" ] [ "name", "born" ] ONLINE
index_343aff4e LOOKUP NONUNIQUE NODE [] [] ONLINE
index_f7700477 LOOKUP NONUNIQUE RELATIONSHIP [] [] ONLINE
Constraints
None
Execute the following command to visualize what's related, and how
删除约束
drop constraint on (m:Movie) assert m.title is unique
删除索引
drop index on :Actor(name,born)
从csv文件批量导入数据到图库
创建csv文件
Person.csv
id,name 1,Charlie Sheen 2,Michael Douglas 3,Martin Sheen 4,Morgan FreemanMovie.csv
id,title,country,year 1,Wall Street,USA,1987 2,The American President,USA,1995 3,The Shawshank Redemption,USA,1994Role.csv
personId,movieId,role 1,1,Bud Fox 4,1,Carl Fox 3,1,Gordon Gekko 4,2,A.J. MacInerney 3,2,President Andrew Shepherd 5,3,Ellis Boyd 'Red' Redding角色的前两列为人和电影的id表示指向关系ACTED_IN,将上述文件上传到neo4j服务器上NEO4J_HOME/import/目录下(可修改配置自定义)
提前创建约束和索引
CREATE CONSTRAINT personIdConstraint FOR (person:Person) REQUIRE person.id IS UNIQUE CREATE CONSTRAINT movieIdConstraint FOR (movie:Movie) REQUIRE movie.id IS UNIQUE CREATE INDEX FOR (c:Country) ON (c.name)先导入顶点数据,人和电影
#创建人 LOAD CSV WITH HEADERS FROM "file:///Person.csv" AS csvLine CREATE (p: Person {id: toInteger(csvLine.id),name: csvLine.name}) #创建电影和国家的点及边关系 LOAD CSV WITH HEADERS FROM "file:///Movie.csv" as csvLine #完成模式创建County类型顶点,如已存在则不创建 MERGE (c: Country {name: csvLine.country}) CREATE (m: Movie {id: toInteger(csvLine.id),title: csvLine.title,year: toInteger(csvLine.year)}) CREATE (m) -[:ORIGIN]-> (c)查询创建的点和关系
match (p: Person) return p ╒═════════════════════════════════╕ │"p" │ ╞═════════════════════════════════╡ │{"name":"Charlie Sheen","id":1} │ ├─ ─────────────────┤ │{"name":"Michael Douglas","id":2}│ ├─────────────────── │{"name":"Martin Sheen","id":3} │ ├─────────────────── │{"name":"Morgan Freeman","id":4} │ └───────────────────match (m:Movie)-[:ORIGIN]->(c:Country) return m,c ╒═══════════════════════════════════════════════════════╤══════════════╕ │"m" │"c" │ ╞═══════════════════════════════════════════════════════╪══════════════╡ │{"year":1987,"id":1,"title":"Wall Street"} │{"name":"USA"}│ ├──────────────────────────────┼─────────┤ │{"year":1995,"id":2,"title":"The American President"} │{"name":"USA"}│ ├───────────────────────────────┼────────┤ │{"year":1994,"id":3,"title":"The Shawshank Redemption"}│{"name":"USA"}│ └───────────────────────────────┴────────┘
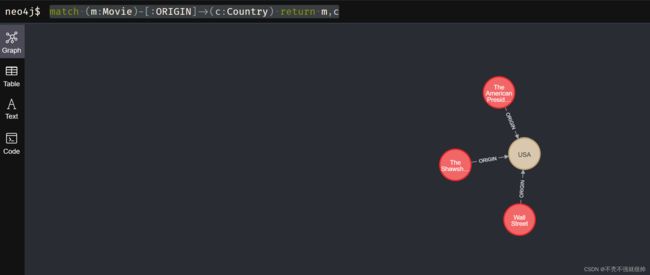
导入出演角色边关系数据
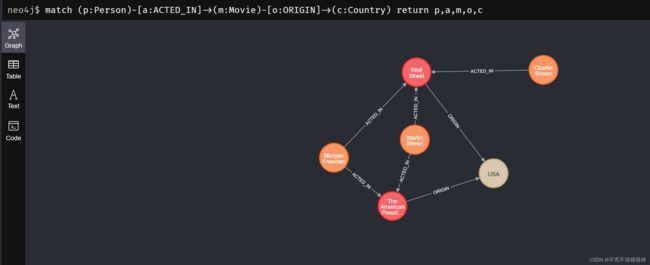
LOAD CSV WITH HEADERS FROM "file:///Role.csv" AS csvLine MATCH (person:Person {id: toInteger(csvLine.personId)}), (movie:Movie {id: toInteger(csvLine.movieId)}) CREATE (person)-[:ACTED_IN {role: csvLine.role}]->(movie)查询完整图
match (p:Person)-[a:ACTED_IN]->(m:Movie)-[o:ORIGIN]->(c:Country) return p,a,m,o,c