神经网络与深度学习复习大纲
第一章(问答题)
1.神经网络是什么?深度学习是什么?
神经网络:一种以(人工))神经元为基本单元的模型
深度学习:一类机器学习问题,主要解决贡献度分配问题
2.常用的深度学习框架是什么?
PaddlePaddle、Tensorflow、Caffe、Theano、MXNet、Torch和PyTorch
3.人工智能的研究领域是什么?
机器感知(计算机视觉、语音信息处理)
学习(模式识别、机器学习、强化学习)
语言(自然语言处理)
记忆(知识表示)
决策(规划、数据挖掘)
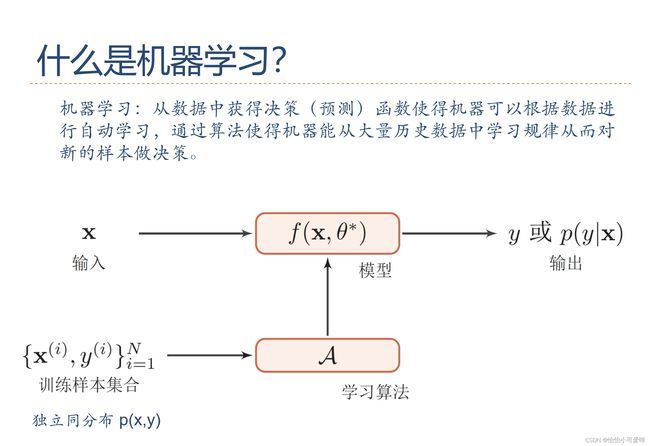
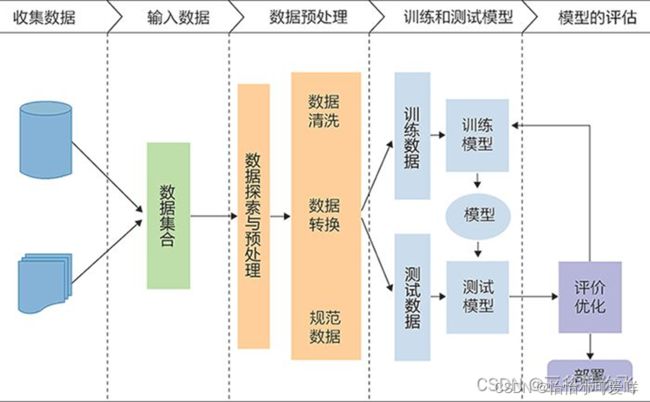
4.描述机器学习的过程/流程。设计一个学习算法描述输入与输出变量之间的相关模型。

1. 收集数据:
收集到的数据的质量和数量将直接决定预测模型是否能够建好。需要将收集的数据去重复、标准化、错误修正等,保存成数据库文件或者csv格式文件,为下一步数据的加载做准备。
2. 分析数据:
分析数据主要是数据发现,比如找出每列的最大、最小值、平均值、方差、中位数、三分位数、四分位数、某些特定值(比如零值)所占比例或者分布规律等等都要有一个大致的了解。了解这些最好的办法就是可视化,谷歌的开源项目facets可以很方便的实现。另一方面要确定自变量(x1…xn)和因变量y,找出因变量和自变量的相关性,确定相关系数。
3. 特征选择:
特征的好坏很大程度上决定了分类器的效果。将上一步骤确定的自变量进行筛选,筛选可以手工选择或者模型选择,选择合适的特征,然后对变量进行命名以便更好的标记。命名文件要存下来,在预测阶段的时候会用到。
4. 向量化:
向量化是对特征提取结果的再加工,目的是增强特征的表示能力,防止模型过于复杂和学习困难,比如对连续的特征值进行离散化,label值映射成枚举值,用数字进行标识。这一阶段将产生一个很重要的文件:label和枚举值对应关系,在预测阶段的同样会用到。
5. 拆分数据集:
需要将数据分为两部分。用于训练模型的第一部分将是数据集的大部分。第二部分将用于评估我们训练有素的模型的表现。通常以8:2或者7:3进行数据划分。不能直接使用训练数据来进行评估,因为模型只能记住“问题”。
6. 模型训练:
进行模型训练之前,要确定合适的算法,比如线性回归、决策树、随机森林、逻辑回归、梯度提升、SVM等等。选择算法的时候最佳方法是测试各种不同的算法,然后通过交叉验证选择最好的一个。但是,如果只是为问题寻找一个“足够好”的算法,或者一个起点,也是有一些还不错的一般准则的,比如如果训练集很小,那么高偏差/低方差分类器(如朴素贝叶斯分类器)要优于低偏差/高方差分类器(如k近邻分类器),因为后者容易过拟合。然而,随着训练集的增大,低偏差/高方差分类器将开始胜出(它们具有较低的渐近误差),因为高偏差分类器不足以提供准确的模型。
7. 模型评估:
训练完成之后,通过拆分出来的训练的数据来对模型进行评估,通过真实数据和预测数据进行对比,来判定模型的好坏。模型评估的常见的五个方法:混淆矩阵、提升图&洛伦兹图、基尼系数、ks曲线、roc曲线。混淆矩阵不能作为评估模型的唯一标准,混淆矩阵是算模型其他指标的基础。完成评估后,如果想进一步改善训练,我们可以通过调整模型的参数来实现,然后重复训练和评估的过程。
8. 文件整理:
模型训练完之后,要整理出四类文件,确保模型能够正确运行,四类文件分别为:Model文件、Lable编码文件、元数据文件(算法,参数和结果)、变量文件(自变量名称列表、因变量名称列表)。
9. 接口封装:
通过封装封装服务接口,实现对模型的调用,以便返回预测结果。
10. 上线:
Data--->特征---->f(x)

5.如何开发一个人工智能系统?(同4)
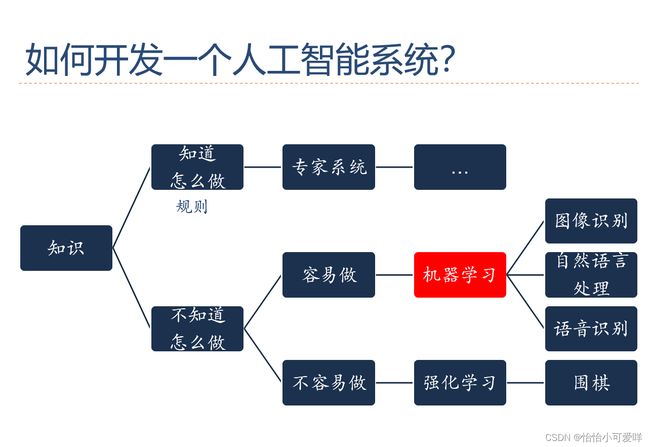
6.深度学习的过程/流程。设计一个学习算法描述输入与输出变量之间的相关模型。其数学描述是?
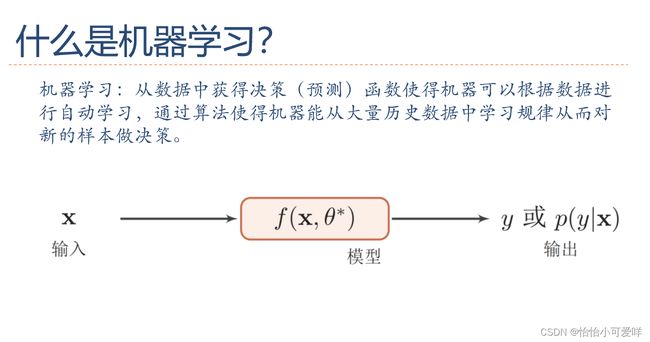
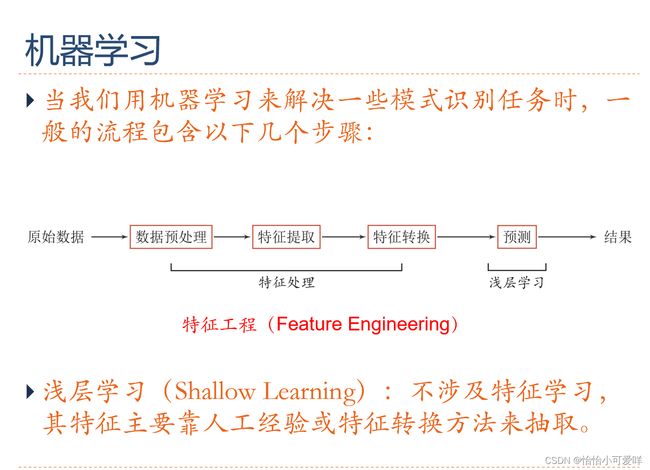
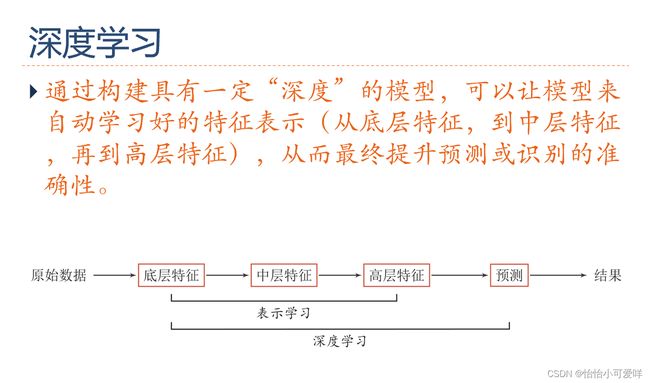
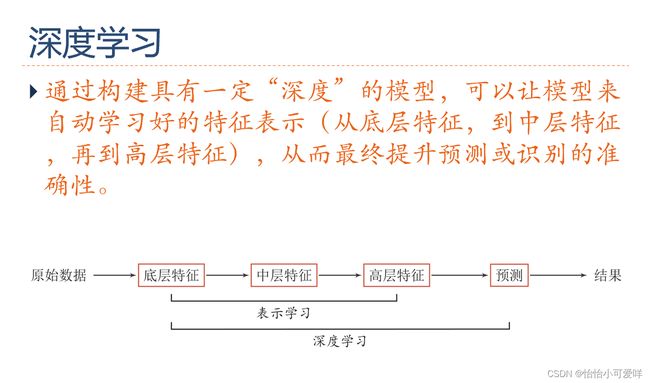
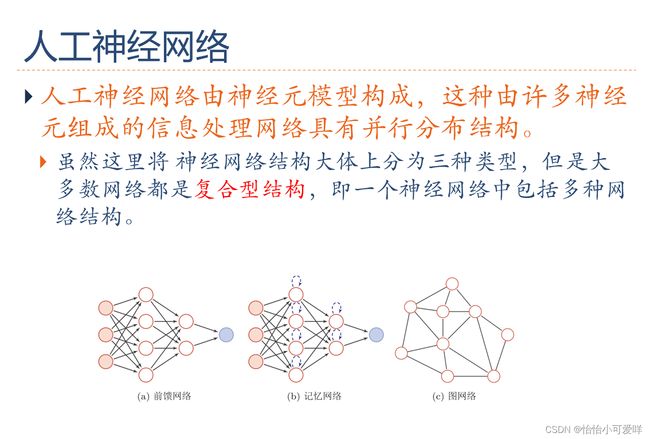
7.深度学习、神经网络的基本网络结构是什么?
第二章
1.几种概率的基本概念和基础计算。
2.采样的定义与操作等。样本划分的比例大小。
给定一个概率分布f(x),生成满足条件的样本。
3.期望的定义,公式与计算。

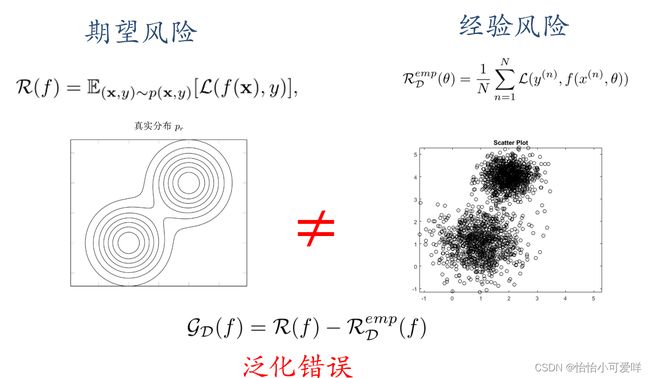
泛化错误可以衡量一个机器学习模型是否可以很好地泛化到未知数据。机器学习的目标是减少泛化错误。%泛化错误一般表现为一个模型在训练集和测试集上错误率的。

4.如何从大量数据中学习规律并预测?
5.机器学习的四要素(数据、模型、学习准则、优化算法)。

6.损失函数定义与相关计算。学习准则中最终是一个什么问题?

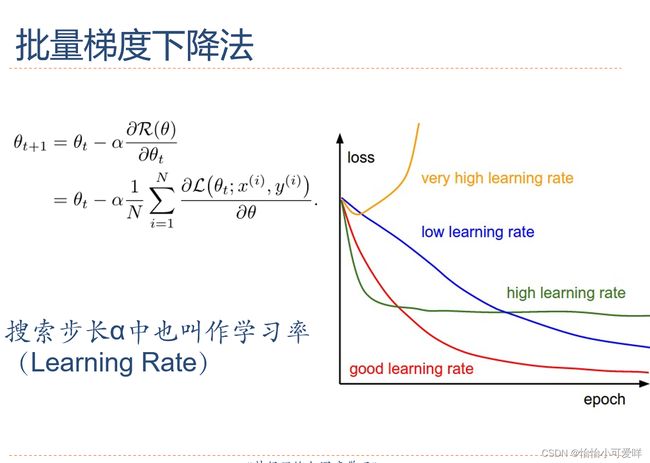
7.梯度下降及其衍生的算法定义与计算


第一章(问答题)
1.神经网络是什么?深度学习是什么?
神经网络:一种以(人工))神经元为基本单元的模型
深度学习:一类机器学习问题,主要解决贡献度分配问题
2.常用的深度学习框架是什么?
PaddlePaddle、Tensorflow、Caffe、Theano、MXNet、Torch和PyTorch
3.人工智能的研究领域是什么?
机器感知(计算机视觉、语音信息处理)
学习(模式识别、机器学习、强化学习)
语言(自然语言处理)
记忆(知识表示)
决策(规划、数据挖掘)
4.描述机器学习的过程/流程。设计一个学习算法描述输入与输出变量之间的相关模型。
1. 收集数据:
收集到的数据的质量和数量将直接决定预测模型是否能够建好。需要将收集的数据去重复、标准化、错误修正等,保存成数据库文件或者csv格式文件,为下一步数据的加载做准备。
2. 分析数据:
分析数据主要是数据发现,比如找出每列的最大、最小值、平均值、方差、中位数、三分位数、四分位数、某些特定值(比如零值)所占比例或者分布规律等等都要有一个大致的了解。了解这些最好的办法就是可视化,谷歌的开源项目facets可以很方便的实现。另一方面要确定自变量(x1…xn)和因变量y,找出因变量和自变量的相关性,确定相关系数。
3. 特征选择:
特征的好坏很大程度上决定了分类器的效果。将上一步骤确定的自变量进行筛选,筛选可以手工选择或者模型选择,选择合适的特征,然后对变量进行命名以便更好的标记。命名文件要存下来,在预测阶段的时候会用到。
4. 向量化:
向量化是对特征提取结果的再加工,目的是增强特征的表示能力,防止模型过于复杂和学习困难,比如对连续的特征值进行离散化,label值映射成枚举值,用数字进行标识。这一阶段将产生一个很重要的文件:label和枚举值对应关系,在预测阶段的同样会用到。
5. 拆分数据集:
需要将数据分为两部分。用于训练模型的第一部分将是数据集的大部分。第二部分将用于评估我们训练有素的模型的表现。通常以8:2或者7:3进行数据划分。不能直接使用训练数据来进行评估,因为模型只能记住“问题”。
6. 模型训练:
进行模型训练之前,要确定合适的算法,比如线性回归、决策树、随机森林、逻辑回归、梯度提升、SVM等等。选择算法的时候最佳方法是测试各种不同的算法,然后通过交叉验证选择最好的一个。但是,如果只是为问题寻找一个“足够好”的算法,或者一个起点,也是有一些还不错的一般准则的,比如如果训练集很小,那么高偏差/低方差分类器(如朴素贝叶斯分类器)要优于低偏差/高方差分类器(如k近邻分类器),因为后者容易过拟合。然而,随着训练集的增大,低偏差/高方差分类器将开始胜出(它们具有较低的渐近误差),因为高偏差分类器不足以提供准确的模型。
7. 模型评估:
训练完成之后,通过拆分出来的训练的数据来对模型进行评估,通过真实数据和预测数据进行对比,来判定模型的好坏。模型评估的常见的五个方法:混淆矩阵、提升图&洛伦兹图、基尼系数、ks曲线、roc曲线。混淆矩阵不能作为评估模型的唯一标准,混淆矩阵是算模型其他指标的基础。完成评估后,如果想进一步改善训练,我们可以通过调整模型的参数来实现,然后重复训练和评估的过程。
8. 文件整理:
模型训练完之后,要整理出四类文件,确保模型能够正确运行,四类文件分别为:Model文件、Lable编码文件、元数据文件(算法,参数和结果)、变量文件(自变量名称列表、因变量名称列表)。
9. 接口封装:
通过封装封装服务接口,实现对模型的调用,以便返回预测结果。
10. 上线:
Data--->特征---->f(x)
5.如何开发一个人工智能系统?(同4)

6.深度学习的过程/流程。设计一个学习算法描述输入与输出变量之间的相关模型。其数学描述是?

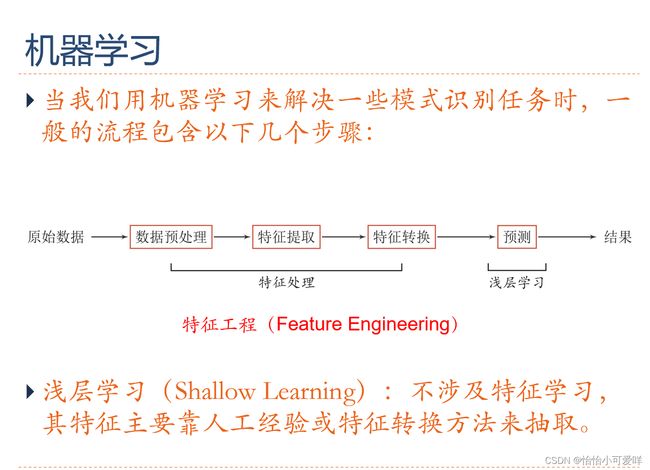
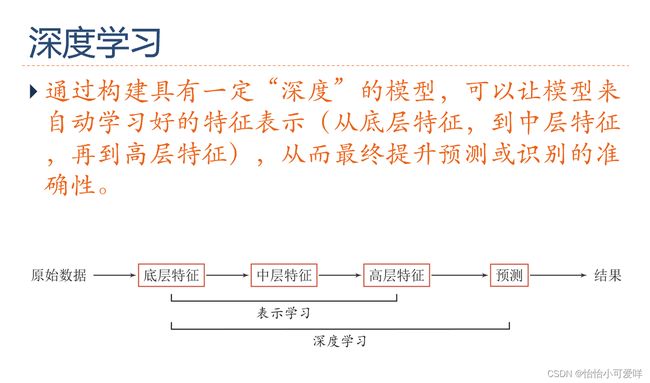
7.深度学习、神经网络的基本网络结构是什么?
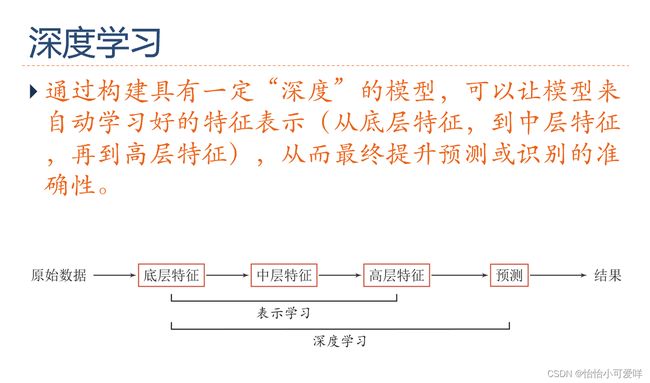


第二章
1.几种概率的基本概念和基础计算。
2.采样的定义与操作等。样本划分的比例大小。
给定一个概率分布f(x),生成满足条件的样本。
3.期望的定义,公式与计算。

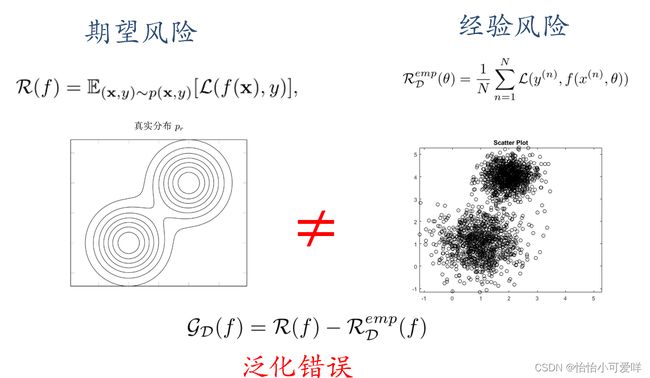
泛化错误可以衡量一个机器学习模型是否可以很好地泛化到未知数据。机器学习的目标是减少泛化错误。%泛化错误一般表现为一个模型在训练集和测试集上错误率的。

4.如何从大量数据中学习规律并预测?
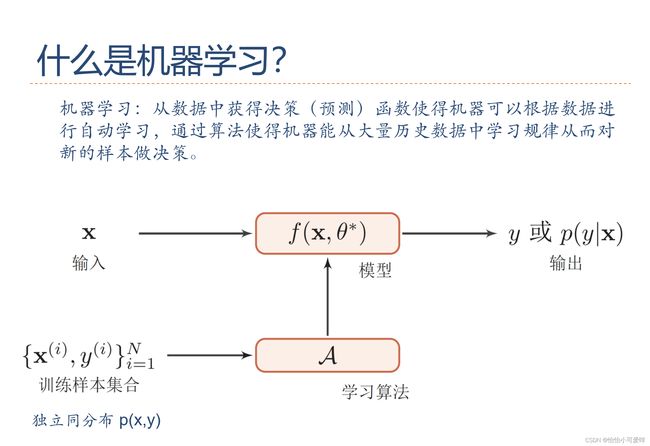
5.机器学习的四要素(数据、模型、学习准则、优化算法)。

6.损失函数定义与相关计算。学习准则中最终是一个什么问题?

7.梯度下降及其衍生的算法定义与计算



8.泛化和正则化的概念
9.期望风险与经验风险的关系。

10.正则化的方式及其概念。
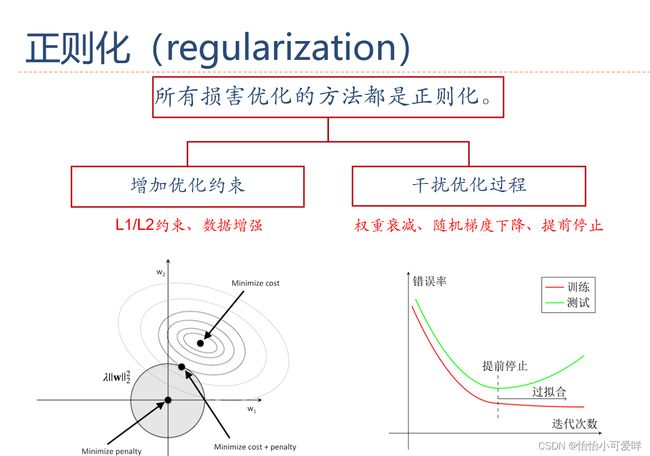
11.模型选择的问题。(欠拟合、过拟合等)

12.四种准则之间的关系。


13.如何选择模型?



(274条消息) 机器学习-->期望风险、经验风险与结构风险之间的关系_liyajuan521的博客-CSDN博客_经验风险最小化
14.偏差与方差之间的关系。

(274条消息) 方差和偏差的关系_贾世林jiashilin的博客-CSDN博客_偏差和方差
第三章
1.图像分类的过程(线性分类为例)

(275条消息) 计算机视觉-----图像分类综述_Avery123123的博客-CSDN博客_图像分类
2.运用词袋模型进行文本分类的过程(线性分类为例)



词袋模型(文本/图像的应用) - 简书 (jianshu.com)
词袋模型(新闻文本分类) - 简书 (jianshu.com)
3.线性分类器模型的概念以及基本操作。

(275条消息) 线性分类器相关概念总结_我什么也不会TwT的博客-CSDN博客_线性分类器的介绍
4.二分类与多分类问题的异同与概念。

(275条消息) 二分类、多分类与多标签问题的区别及对应损失函数的选择_lyy14011305的博客-CSDN博客_二分类损失函数
5.线性模型(4种)的异同对比与概念。
-
- Logistic Regression
- Softmax Regression
- Perceptron
- SVM
算法理论03 感知机(Perceptron) - 知乎 (zhihu.com)
(275条消息) 感知机、线性回归、逻辑回归的简单对比_wgdzz的博客-CSDN博客
Logistic回归(逻辑回归)和softmax回归 - Luv_GEM - 博客园 (cnblogs.com)
支持向量机(SVM)——原理篇 - 知乎 (zhihu.com)
6.信息熵的定义,自信息与交叉熵的计算
信息论2(自信息、信息熵、联合熵、条件熵、交叉熵、相对熵(KL散度)、互信息、最大互信息系数) - 简书 (jianshu.com)
7.Logistic 回归的全部定义(包括激活函数、损失函数、更新过程)与计算
(276条消息) Logistic回归-模型·损失函数·参数更新_usj的博客-CSDN博客
(275条消息) logistic回归详解_站在风口的骚人的博客-CSDN博客_logistic回归
8.Softmax回归的全部定义(包括激活函数、损失函数、更新过程)与计算

9.感知器的全部定义(包括激活函数、损失函数、更新过程)与计算
零基础入门深度学习 | 第一章:感知器 - 知乎 (zhihu.com)
10.支持向量机的全部定义(包括激活函数、损失函数、更新过程)与计算
支持向量机(SVM)——原理篇 - 知乎 (zhihu.com)
11.异或问题(线性不可分问题)用线性模型的解决方式。
线性神经网络解决异或问题 - 简书 (jianshu.com)
第四章
1.人工神经元的基本概念。
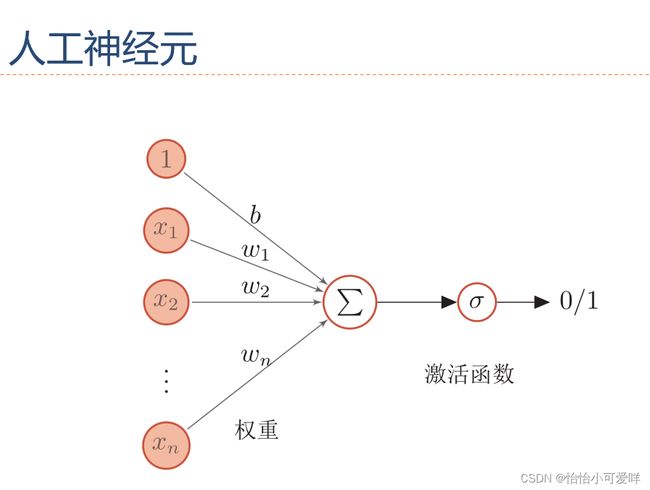
人工神经元就是受自然神经元静息和动作电位的产生机制启发而建立的一个运算模型。
给初学者们讲解人工神经网络(ANN)_神经元 (sohu.com)
2.激活函数的性质和常见的激活函数(公式、特性、导数等)。

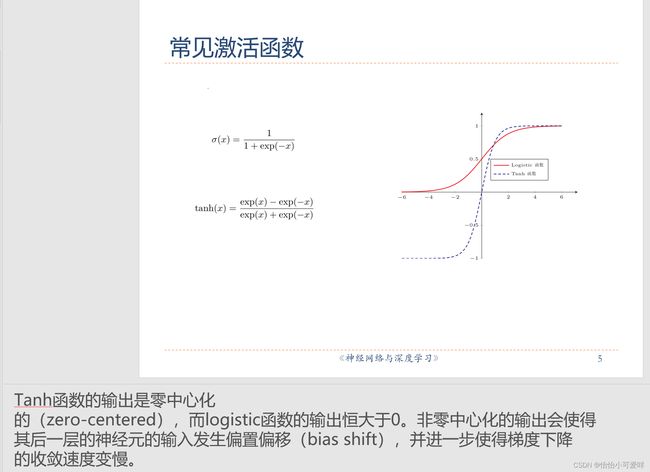
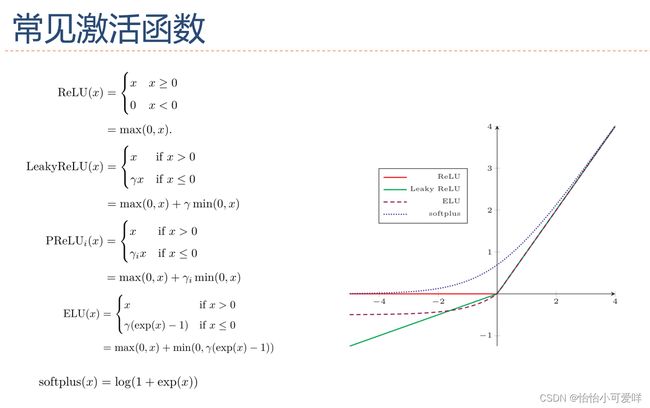
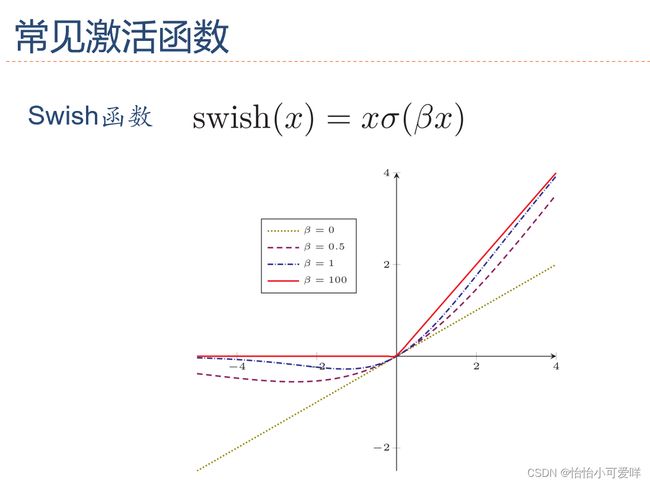

(276条消息) 激活函数的性质、表达式及其优劣:Sigmoid -> Tanh -> ReLU -> Leaky ReLU 、PReLU、RReLU 、ELUs-> Maxout_姬香的博客-CSDN博客_激活函数性质
3.神经网络的定义与特点。
(276条消息) 深度学习导航(一)——神经网络的定义和基本概念_晨风默语的博客-CSDN博客_神经网络定义
(276条消息) 深度学习之前馈神经网络(前向传播和误差反向传播)_SongEsther的博客-CSDN博客


4.神经网络的三种结构及其特性。
(276条消息) 三种常见的神经网络_dyna_lidan的博客-CSDN博客_神经网络算法三大类
5.前馈神经网络的特点、信息传递过程、计算过程等。


(276条消息) 深度学习之前馈神经网络(前向传播和误差反向传播)_SongEsther的博客-CSDN博客
6.如何计算通过链式法则计算梯度。

7.反向传播算法的定义(为什么叫反向传播算法)。


反向传播——机器学习 (ngui.cc)
8.会画计算图,会使用计算图求微分。
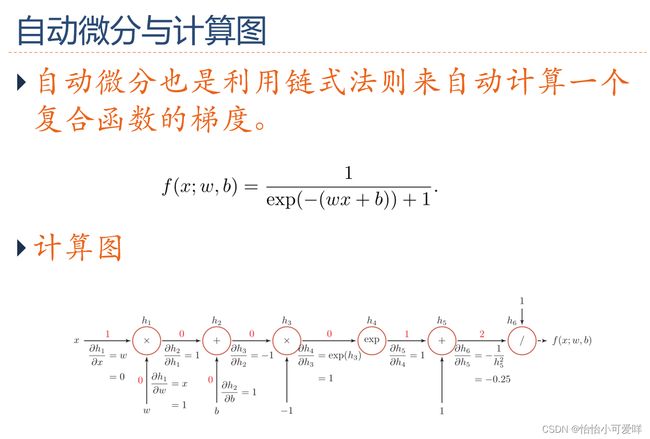

(276条消息) PyTorch 101, Part1:计算图的理解、自动微分和Autograd模块_lp_oreo的博客-CSDN博客
(276条消息) 计算图与自动微分 优化问题_生命苦短 必须喜感的博客-CSDN博客
9.自微分的原理。


(276条消息) 自动微分(Automatic Differentiation)简介——tensorflow核心原理_浮生了大白的博客-CSDN博客
10.优化问题:非凸优化问题、梯度消失问题及其问题所要的需求。
(276条消息) 非凸优化可采用的方法_三年得的博客-CSDN博客_非凸优化转化为凸优化



(276条消息) 神经网络中怎么解决梯度消失问题_Echo-z的博客-CSDN博客_梯度消失的解决方法
第五章
1.全连接前馈神经网络的缺点。
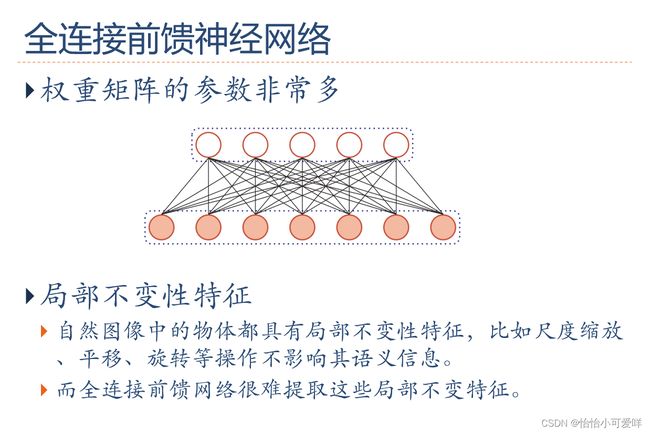
2.卷积神经网络的定义以及结构特性。

这些特性使得卷积神经网络具有一定程度上的平移、缩放和扭曲不变性。
3.卷积的定义以及计算,卷积的类型(卷积填充补零的数量等)。

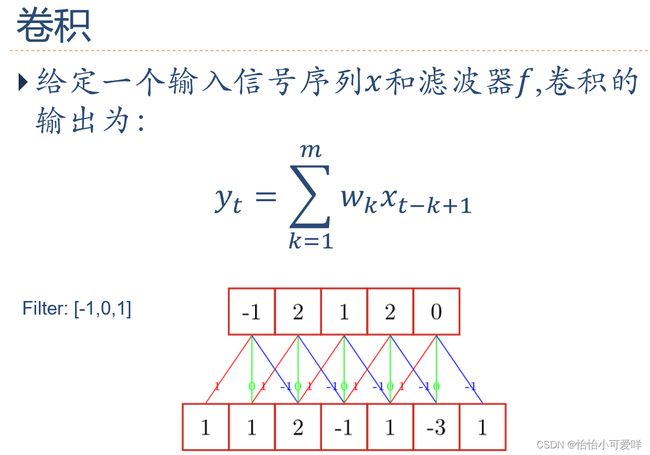
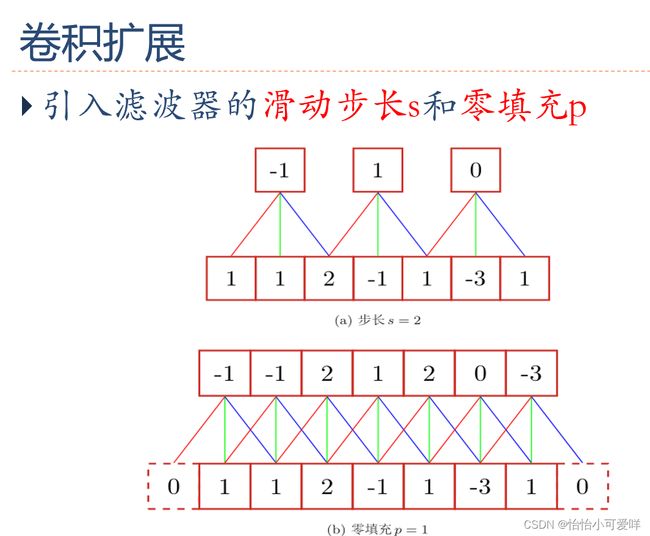

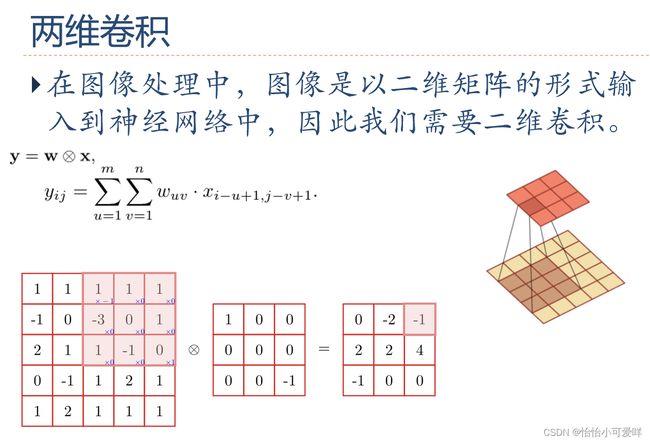

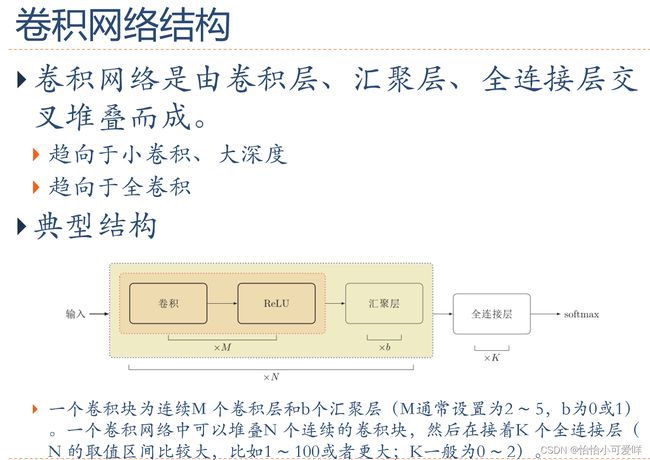
4.卷积神经网络的计算(池化技术=聚汇、互相关等)。
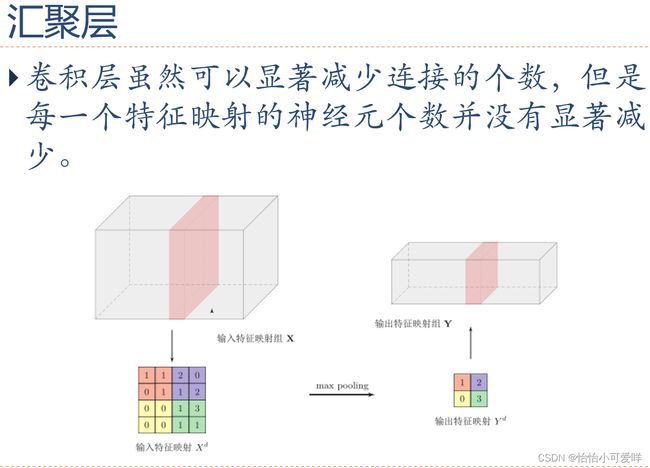
(279条消息) 卷积神经网络的卷积及池化(pooling)_jenny_paofu的博客-CSDN博客_卷积池化
卷积神经网络 - 汇聚层 - 知乎 (zhihu.com)

(279条消息) 卷积运行 和 互相关运算_yjinyyzyq的博客-CSDN博客_互相关运算
5.典型的卷积神经网络(共8种,其工作原理等要搞清楚)。

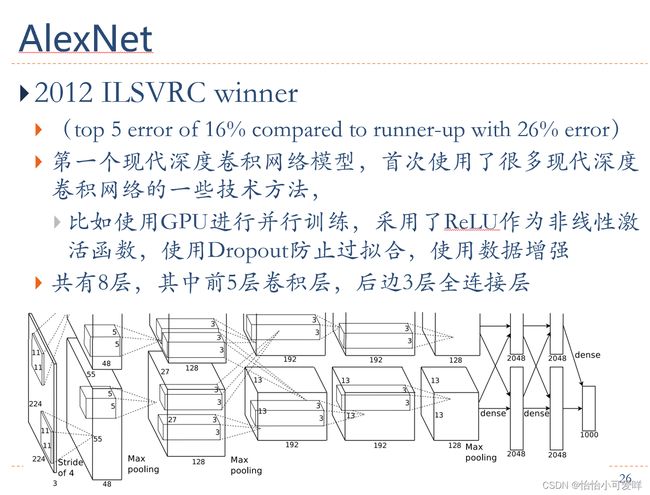
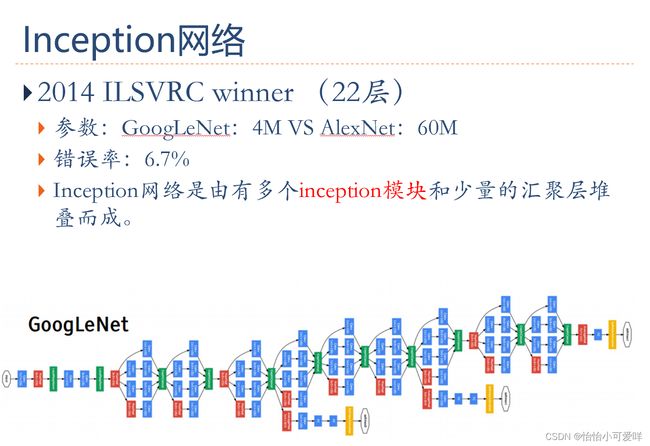

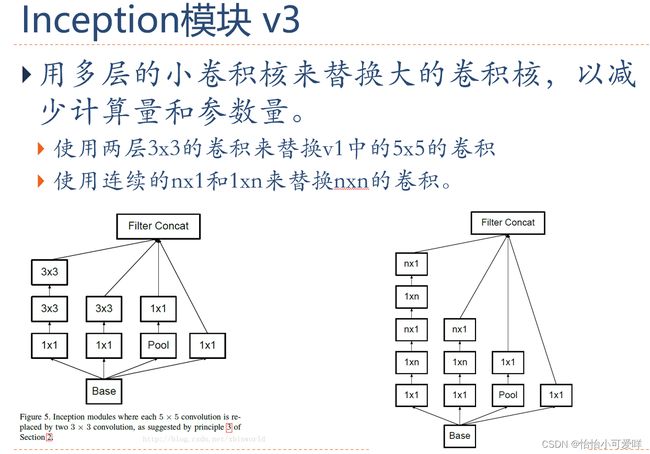

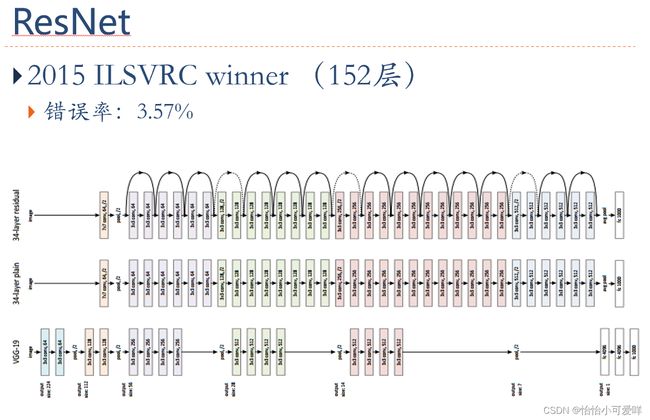


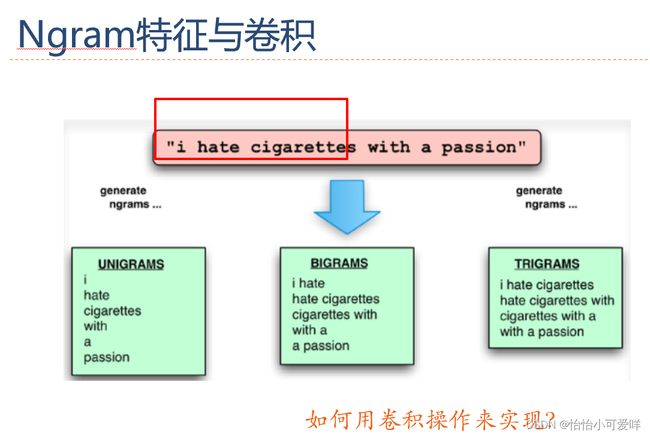
6.卷积神经网络的应用。
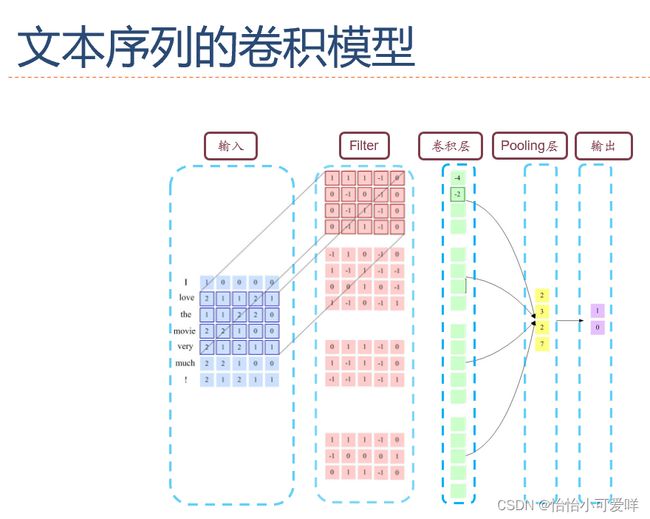





第六章
1.前馈神经网络的缺点。
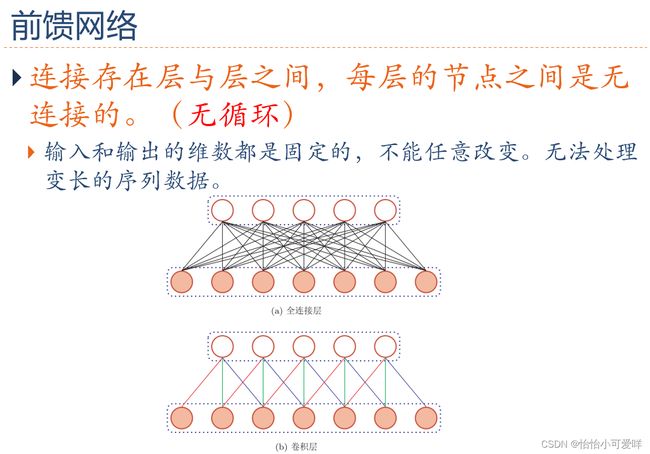

2.如何给网络增加记忆能力。

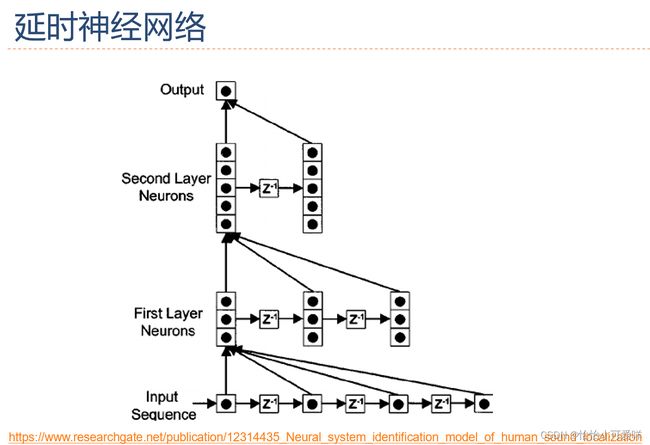

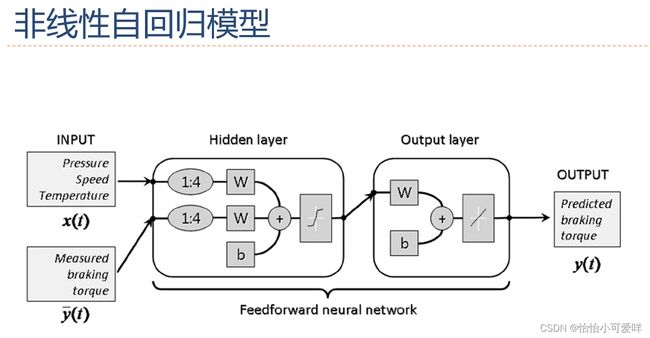
3.循环神经网络的定义以及计算。
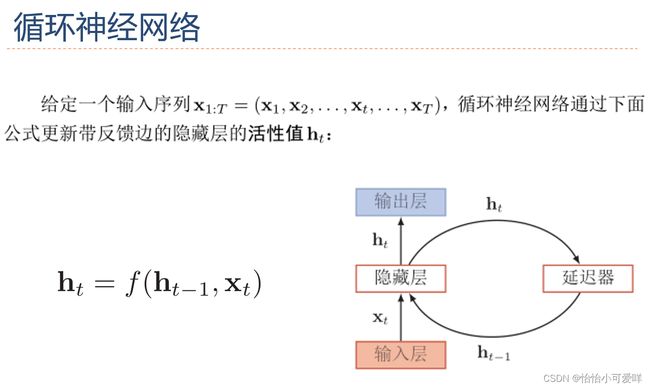


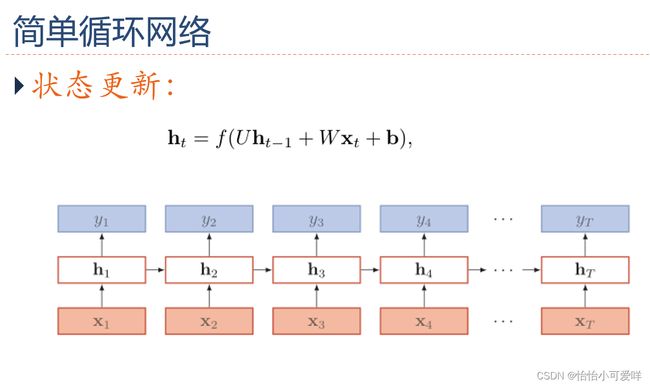
4.循环神经网络应用到机器学习
机器学习系列(10)---循环神经网络的经典应用模式 - 知乎 (zhihu.com)



5.如何解决长程依赖问题


(279条消息) RNN系列之四 长期依赖问题_qq_28437273的博客-CSDN博客_长期依赖问题
6.GRU和LSTM的工作原理、工作流程、两者的异同,如何解决长程依赖问题的。
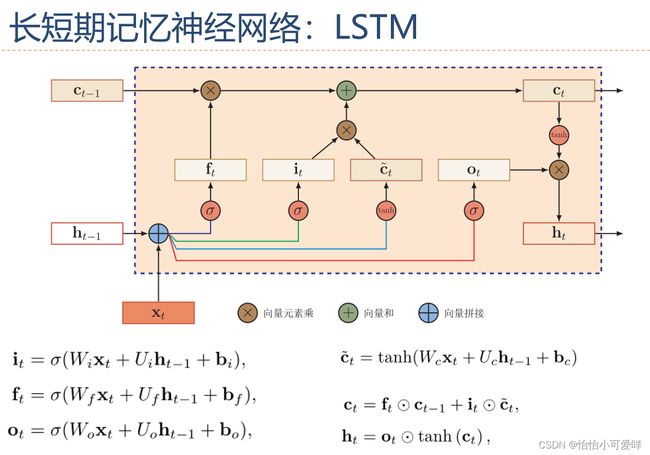


LSTM与GRU的原理 - 知乎 (zhihu.com)

(279条消息) LSTM 和GRU的区别_adrianna_xy的博客-CSDN博客_gru和lstm
7.深层循环网络的定义以及计算。
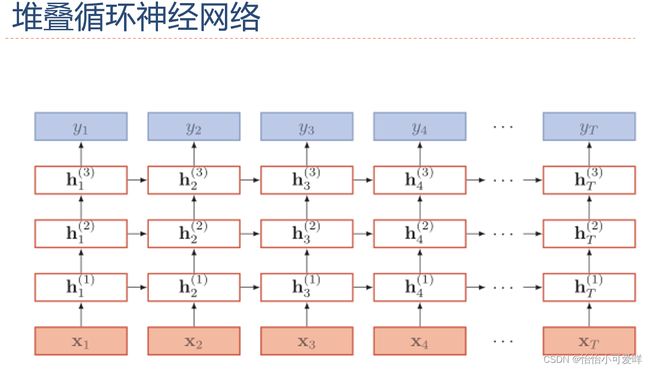

深度学习之14——深层循环神经网络 - 知乎 (zhihu.com)
8. 循环网络的图结构。


第七章
1.神经网络优化的原因与特点。


2优化算法改进的细节(小批量与学习率的关系之类的)


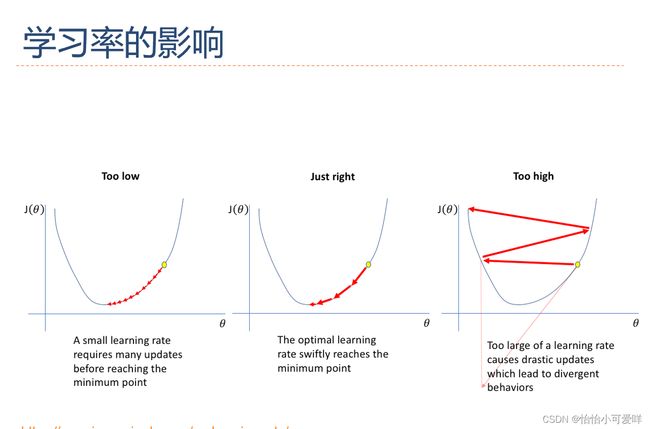
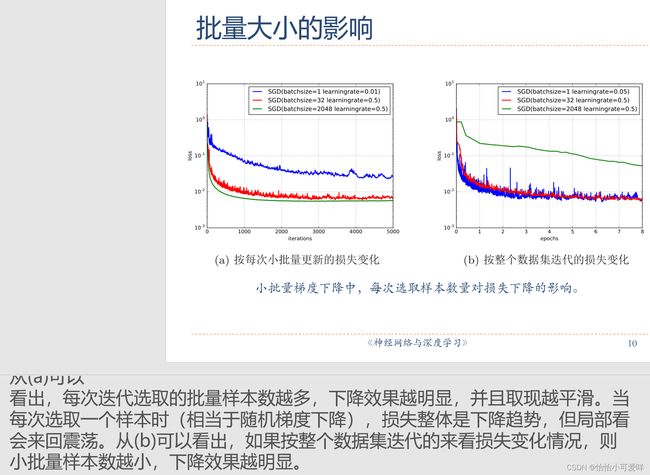

3.动态学习的种类以及其适用范围与原因。

4.梯度方向的优化。
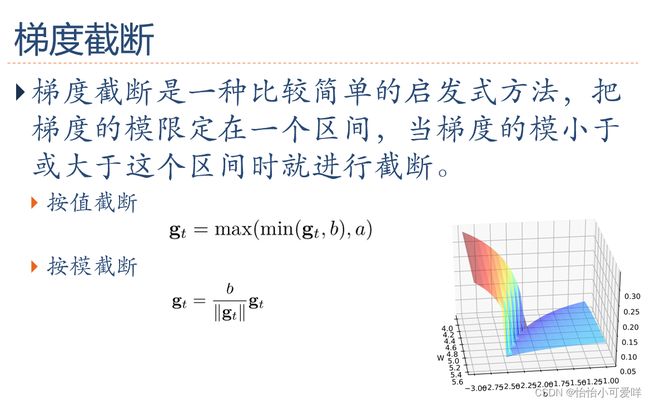
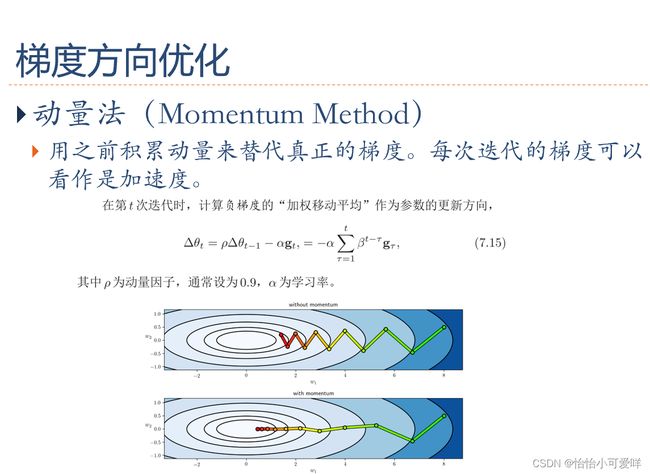

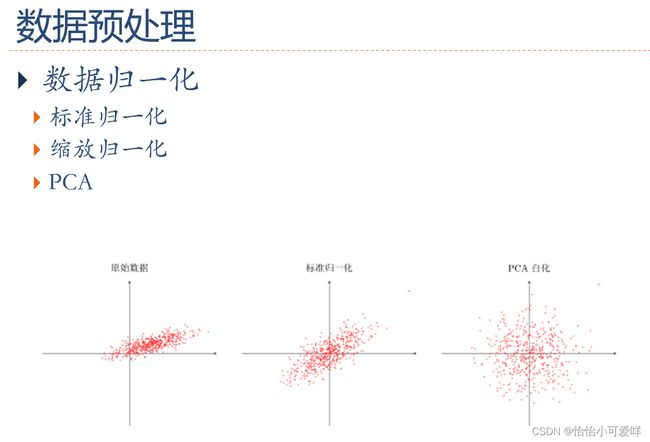
5.参数初始化、数据预处理(规范化)、逐层规范化、超参规范化的概念种类等概念。


每次小批量样本的µ B 和方差σ 2
B 是净输入z
(l) 的函数,而
不是常量。因此在计算参数梯度时需要考虑µ B 和σ 2
B 的影响。当训练完成时,用
整个数据集上的均值µ和方差σ来分别代替每次小批量样本的µ B 和方差σ 2
B 。在
实践中,µ B 和σ 2
B 也可以用移动平均来计算



6.神经网络正则化的原因、正则化与优化之间的关系。

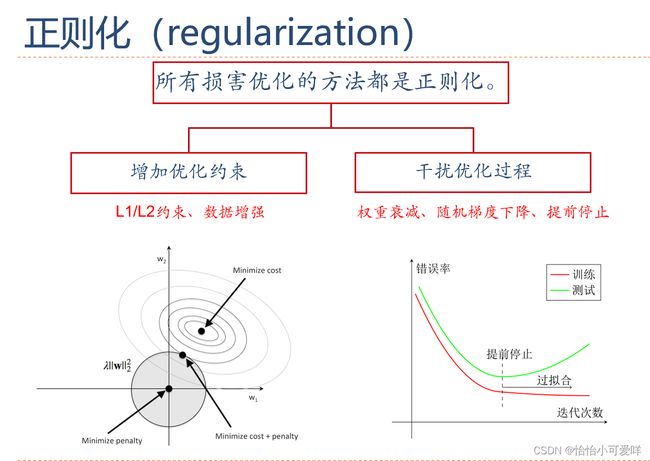
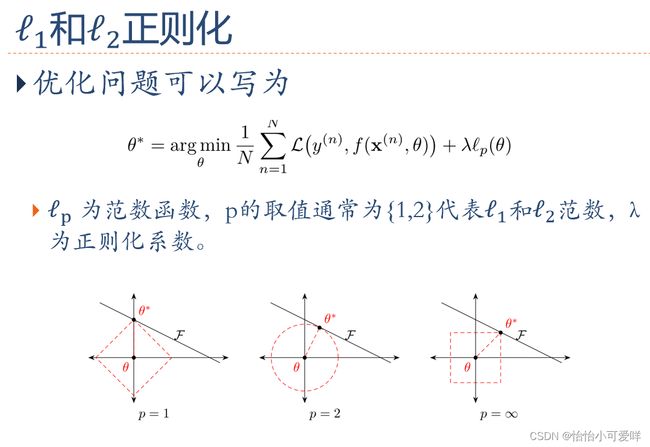
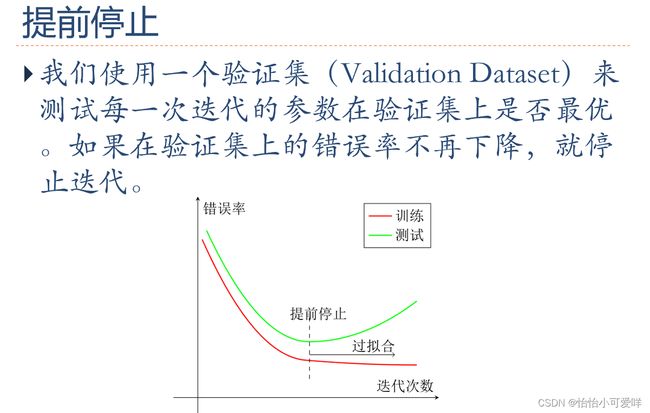
7. 神经网络正则化的方法具体原理以及方法:增加约束(L1和L2增强、数据样本增加)、干扰过程(权重衰减、随机梯度下降、早停法early-stop、暂退法dropout)。


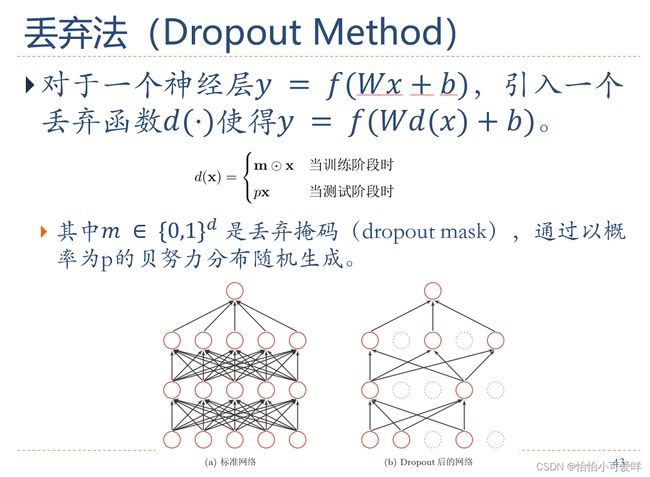

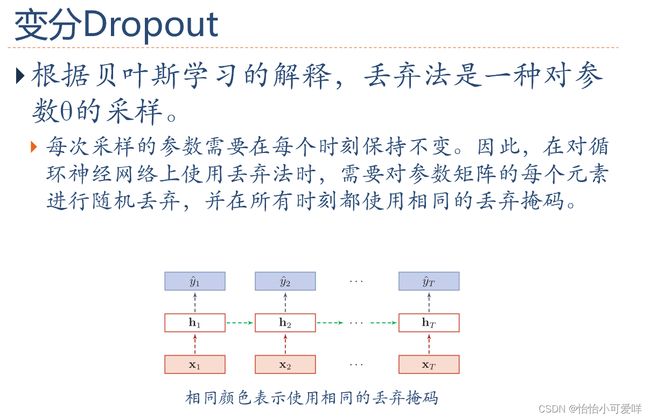




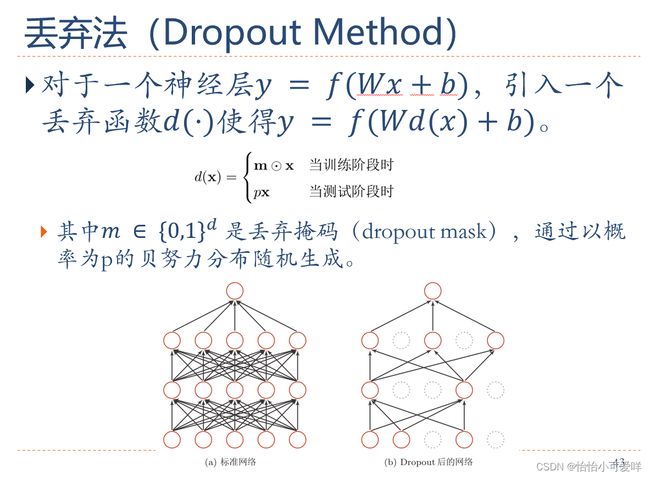

第八章
1.什么是注意力机制、注意力机制的概念。




2.人工神经网络的注意力机制的定义和种类模型。



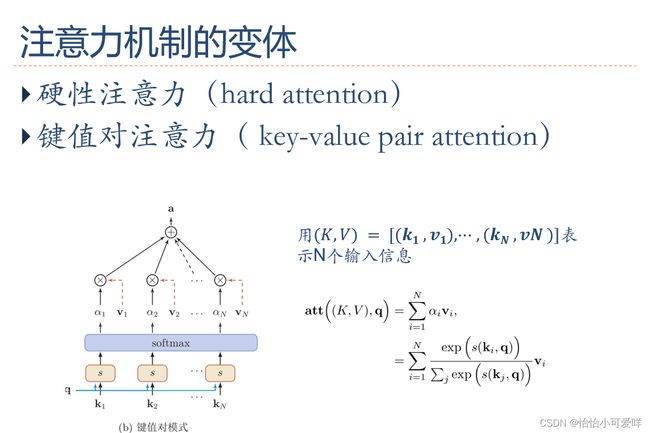


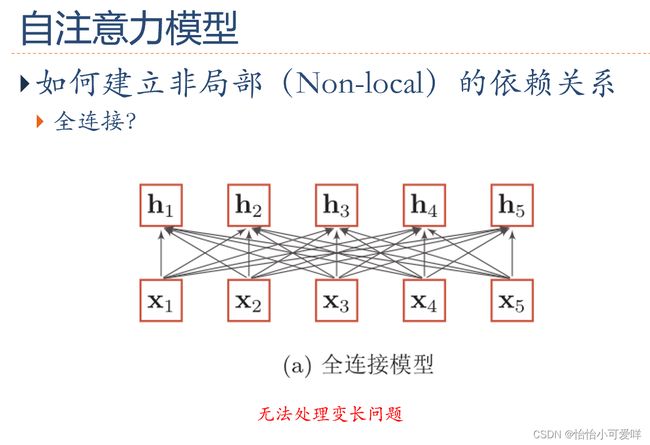
3.自注意力模型的概念,与全连接的区别?自注意力模型的应用


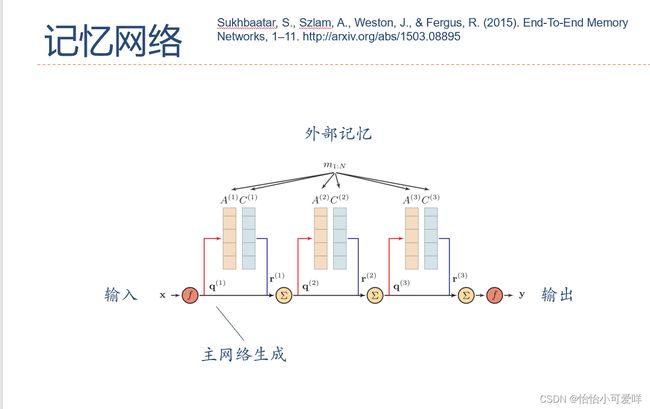
4.外部记忆的种类(结构化外部记忆和联想记忆)、定义和区别。


《神经网络与深度学习-邱锡鹏》习题解答 - 知乎 (zhihu.com)
(274条消息) 【学习笔记】《深度学习与神经网络》——邱锡鹏_CodeLuweir的博客-CSDN博客_神经网络与深度学习 邱锡鹏
神经网络与深度学习试题+答案(10页)-原创力文档 (book118.com)
(293条消息) 深度学习经典试题29道_琴&的博客-CSDN博客_深度学习 试题
《神经网络与深度学习-邱锡鹏》习题解答 - 知乎 (zhihu.com)
深度学习 100 题(转) - 大汤姆 - 博客园 (cnblogs.com)
神经网络基础与应用期末总结 - 知乎 (zhihu.com)