目标检测的图像特征提取之(一)HOG特征
1、HOG特征:
方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。Hog特征结合SVM分类器已经被广泛应用于图像识别中,尤其在行人检测中获得了极大的成功。需要提醒的是,HOG+SVM进行行人检测的方法是法国研究人员Dalal在2005的CVPR上提出的,而如今虽然有很多行人检测算法不断提出,但基本都是以HOG+SVM的思路为主。
(1)主要思想:
在一副图像中,局部目标的表象和形状(appearance and shape)能够被梯度或边缘的方向密度分布很好地描述。(本质:梯度的统计信息,而梯度主要存在于边缘的地方)。
(2)具体的实现方法是:
首先将图像分成小的连通区域,我们把它叫细胞单元。然后采集细胞单元中各像素点的梯度的或边缘的方向直方图。最后把这些直方图组合起来就可以构成特征描述器。
(3)提高性能:
把这些局部直方图在图像的更大的范围内(我们把它叫区间或block)进行对比度归一化(contrast-normalized),所采用的方法是:先计算各直方图在这个区间(block)中的密度,然后根据这个密度对区间中的各个细胞单元做归一化。通过这个归一化后,能对光照变化和阴影获得更好的效果。
(4)优点:
与其他的特征描述方法相比,HOG有很多优点。首先,由于HOG是在图像的局部方格单元上操作,所以它对图像几何的和光学的形变都能保持很好的不变性,这两种形变只会出现在更大的空间领域上。其次,在粗的空域抽样、精细的方向抽样以及较强的局部光学归一化等条件下,只要行人大体上能够保持直立的姿势,可以容许行人有一些细微的肢体动作,这些细微的动作可以被忽略而不影响检测效果。因此HOG特征是特别适合于做图像中的人体检测的。
2、HOG特征提取算法的实现过程:
大概过程:
HOG特征提取方法就是将一个image(你要检测的目标或者扫描窗口):
1)灰度化(将图像看做一个x,y,z(灰度)的三维图像);
2)采用Gamma校正法对输入图像进行颜色空间的标准化(归一化);目的是调节图像的对比度,降低图像局部的阴影和光照变化所造成的影响,同时可以抑制噪音的干扰;
3)计算图像每个像素的梯度(包括大小和方向);主要是为了捕获轮廓信息,同时进一步弱化光照的干扰。
4)将图像划分成小cells(例如6*6像素/cell);
5)统计每个cell的梯度直方图(不同梯度的个数),即可形成每个cell的descriptor;
6)将每几个cell组成一个block(例如3*3个cell/block),一个block内所有cell的特征descriptor串联起来便得到该block的HOG特征descriptor。
7)将图像image内的所有block的HOG特征descriptor串联起来就可以得到该image(你要检测的目标)的HOG特征descriptor了。这个就是最终的可供分类使用的特征向量了。

具体每一步的详细过程如下:
(1)标准化gamma空间和颜色空间
为了减少光照因素的影响,首先需要将整个图像进行规范化(归一化)。在图像的纹理强度中,局部的表层曝光贡献的比重较大,所以,这种压缩处理能够有效地降低图像局部的阴影和光照变化。因为颜色信息作用不大,通常先转化为灰度图;
Gamma压缩公式:
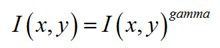
比如可以取Gamma=1/2;
(2)计算图像梯度
计算图像横坐标和纵坐标方向的梯度,并据此计算每个像素位置的梯度方向值;求导操作不仅能够捕获轮廓,人影和一些纹理信息,还能进一步弱化光照的影响。
图像中像素点(x,y)的梯度为:

最常用的方法是:首先用[-1,0,1]梯度算子对原图像做卷积运算,得到x方向(水平方向,以向右为正方向)的梯度分量gradscalx,然后用[1,0,-1]T梯度算子对原图像做卷积运算,得到y方向(竖直方向,以向上为正方向)的梯度分量gradscaly。然后再用以上公式计算该像素点的梯度大小和方向。
(3)为每个细胞单元构建梯度方向直方图
第三步的目的是为局部图像区域提供一个编码,同时能够保持对图像中人体对象的姿势和外观的弱敏感性。
我们将图像分成若干个“单元格cell”,例如每个cell为6*6个像素。假设我们采用9个bin的直方图来统计这6*6个像素的梯度信息。也就是将cell的梯度方向360度分成9个方向块,如图所示:例如:如果这个像素的梯度方向是20-40度,直方图第2个bin的计数就加一,这样,对cell内每个像素用梯度方向在直方图中进行加权投影(映射到固定的角度范围),就可以得到这个cell的梯度方向直方图了,就是该cell对应的9维特征向量(因为有9个bin)。
像素梯度方向用到了,那么梯度大小呢?梯度大小就是作为投影的权值的。例如说:这个像素的梯度方向是20-40度,然后它的梯度大小是2(假设啊),那么直方图第2个bin的计数就不是加一了,而是加二(假设啊)。
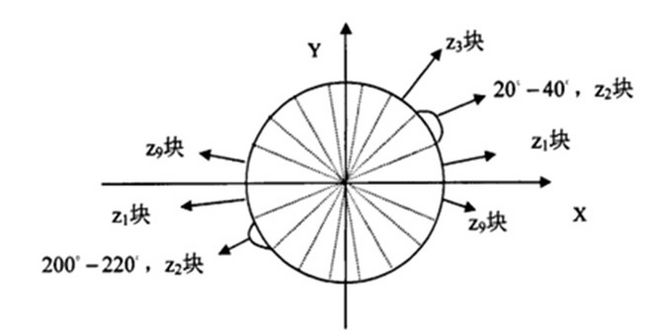
细胞单元可以是矩形的(rectangular),也可以是星形的(radial)。
(4)把细胞单元组合成大的块(block),块内归一化梯度直方图
由于局部光照的变化以及前景-背景对比度的变化,使得梯度强度的变化范围非常大。这就需要对梯度强度做归一化。归一化能够进一步地对光照、阴影和边缘进行压缩。
作者采取的办法是:把各个细胞单元组合成大的、空间上连通的区间(blocks)。这样,一个block内所有cell的特征向量串联起来便得到该block的HOG特征。这些区间是互有重叠的,这就意味着:每一个单元格的特征会以不同的结果多次出现在最后的特征向量中。我们将归一化之后的块描述符(向量)就称之为HOG描述符。
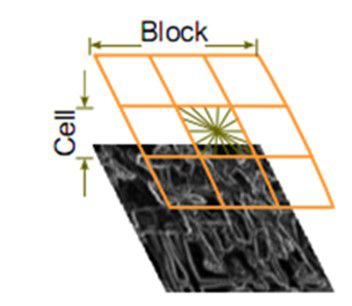
区间有两个主要的几何形状——矩形区间(R-HOG)和环形区间(C-HOG)。R-HOG区间大体上是一些方形的格子,它可以有三个参数来表征:每个区间中细胞单元的数目、每个细胞单元中像素点的数目、每个细胞的直方图通道数目。
例如:行人检测的最佳参数设置是:3×3细胞/区间、6×6像素/细胞、9个直方图通道。则一块的特征数为:3*3*9;
(5)收集HOG特征
最后一步就是将检测窗口中所有重叠的块进行HOG特征的收集,并将它们结合成最终的特征向量供分类使用。
(6)那么一个图像的HOG特征维数是多少呢?
顺便做个总结:Dalal提出的Hog特征提取的过程:把样本图像分割为若干个像素的单元(cell),把梯度方向平均划分为9个区间(bin),在每个单元里面对所有像素的梯度方向在各个方向区间进行直方图统计,得到一个9维的特征向量,每相邻的4个单元构成一个块(block),把一个块内的特征向量联起来得到36维的特征向量,用块对样本图像进行扫描,扫描步长为一个单元。最后将所有块的特征串联起来,就得到了人体的特征。例如,对于64*128的图像而言,每8*8的像素组成一个cell,每2*2个cell组成一个块,因为每个cell有9个特征,所以每个块内有4*9=36个特征,以8个像素为步长,那么,水平方向将有7个扫描窗口,垂直方向将有15个扫描窗口。也就是说,64*128的图片,总共有36*7*15=3780个特征。
HOG维数,16×16像素组成的block,8x8像素的cell
注释:
行人检测HOG+SVM
总体思路:
1、提取正负样本hog特征
2、投入svm分类器训练,得到model
3、由model生成检测子
4、利用检测子检测负样本,得到hardexample
5、提取hardexample的hog特征并结合第一步中的特征一起投入训练,得到最终检测子。
深入研究hog算法原理:
一、hog概述
hog是05年一位nb的博士提出来的,论文链接 http://wenku.baidu.com/view/676f2351f01dc281e53af0b2 .html
终于到10月了,终于可以松一口气了,整理一下hog的算法流程。
最近要做图像特征提取,可能要用下HOG特征,所以研究了下OpenCV的HOG描述子。OpenCV中的HOG特征提取功能使用了HOGDescriptor这个类来进行封装,其中也有现成的行人检测的接口。
然而,无论是OpenCV官方说明文档还是各个中英文网站目前都没有这个类的使用说明,所以在这里把研究的部分心得分享一下。
首先我们进入HOGDescriptor所在的头文件,看看它的构造函数需要哪些参数。
- CV_WRAP HOGDescriptor() : winSize(64,128), blockSize(16,16), blockStride(8,8),
- cellSize(8,8), nbins(9), derivAperture(1), winSigma(-1),
- histogramNormType(HOGDescriptor::L2Hys), L2HysThreshold(0.2), gammaCorrection(true),
- nlevels(HOGDescriptor::DEFAULT_NLEVELS)
- {}
CV_WRAP HOGDescriptor() : winSize(64,128), blockSize(16,16), blockStride(8,8),
cellSize(8,8), nbins(9), derivAperture(1), winSigma(-1),
histogramNormType(HOGDescriptor::L2Hys), L2HysThreshold(0.2), gammaCorrection(true),
nlevels(HOGDescriptor::DEFAULT_NLEVELS)
{}- CV_WRAP HOGDescriptor(Size _winSize, Size _blockSize, Size _blockStride,
- Size _cellSize, int _nbins, int _derivAperture=1, double _winSigma=-1,
- int _histogramNormType=HOGDescriptor::L2Hys,
- double _L2HysThreshold=0.2, bool _gammaCorrection=false,
- int _nlevels=HOGDescriptor::DEFAULT_NLEVELS)
- : winSize(_winSize), blockSize(_blockSize), blockStride(_blockStride), cellSize(_cellSize),
- nbins(_nbins), derivAperture(_derivAperture), winSigma(_winSigma),
- histogramNormType(_histogramNormType), L2HysThreshold(_L2HysThreshold),
- gammaCorrection(_gammaCorrection), nlevels(_nlevels)
- {}
CV_WRAP HOGDescriptor(Size _winSize, Size _blockSize, Size _blockStride,
Size _cellSize, int _nbins, int _derivAperture=1, double _winSigma=-1,
int _histogramNormType=HOGDescriptor::L2Hys,
double _L2HysThreshold=0.2, bool _gammaCorrection=false,
int _nlevels=HOGDescriptor::DEFAULT_NLEVELS)
: winSize(_winSize), blockSize(_blockSize), blockStride(_blockStride), cellSize(_cellSize),
nbins(_nbins), derivAperture(_derivAperture), winSigma(_winSigma),
histogramNormType(_histogramNormType), L2HysThreshold(_L2HysThreshold),
gammaCorrection(_gammaCorrection), nlevels(_nlevels)
{}- CV_WRAP HOGDescriptor(const String& filename)
- {
- load(filename);
- }
CV_WRAP HOGDescriptor(const String& filename)
{
load(filename);
}- HOGDescriptor(const HOGDescriptor& d)
- {
- d.copyTo(*this);
- }
HOGDescriptor(const HOGDescriptor& d)
{
d.copyTo(*this);
}我们看到HOGDescriptor一共有4个构造函数,前三个有CV_WRAP前缀,表示它们是从DLL里导出的函数,即我们在程序当中可以调用的函数;最后一个没有上述的前缀,所以我们暂时用不到,它其实就是一个拷贝构造函数。
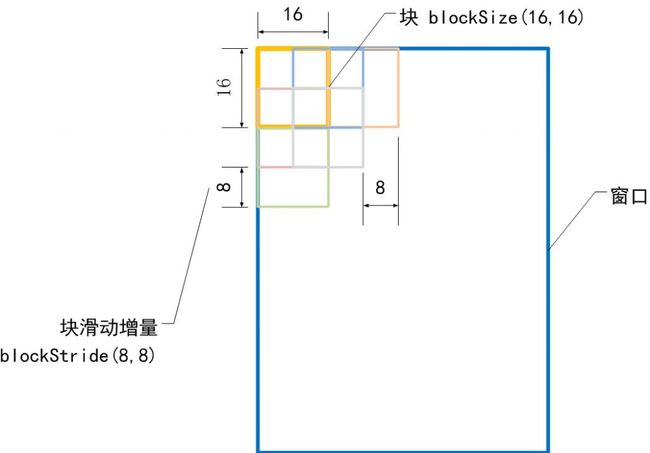
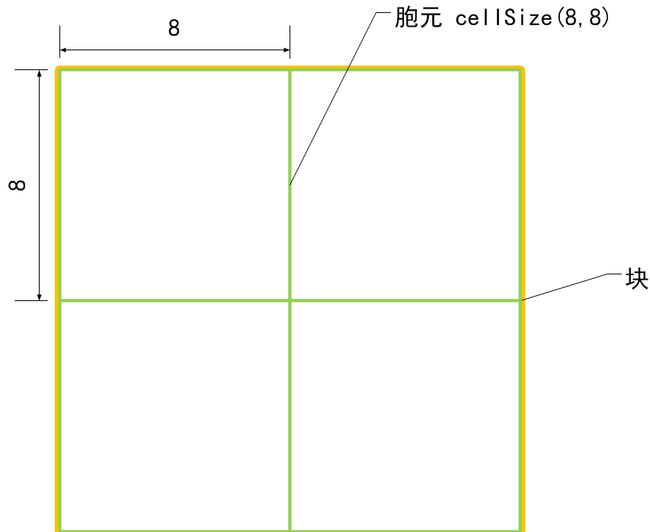
下面我们就把注意力放在前面的构造函数的参数上面吧,这里有几个重要的参数要研究下:winSize(64,128), blockSize(16,16), blockStride(8,8), cellSize(8,8), nbins(9)。上面这些都是HOGDescriptor的成员变量,括号里的数值是它们的默认值,它们反应了HOG描述子的参数。这里做了几个示意图来表示它们的含义。
窗口大小 winSize
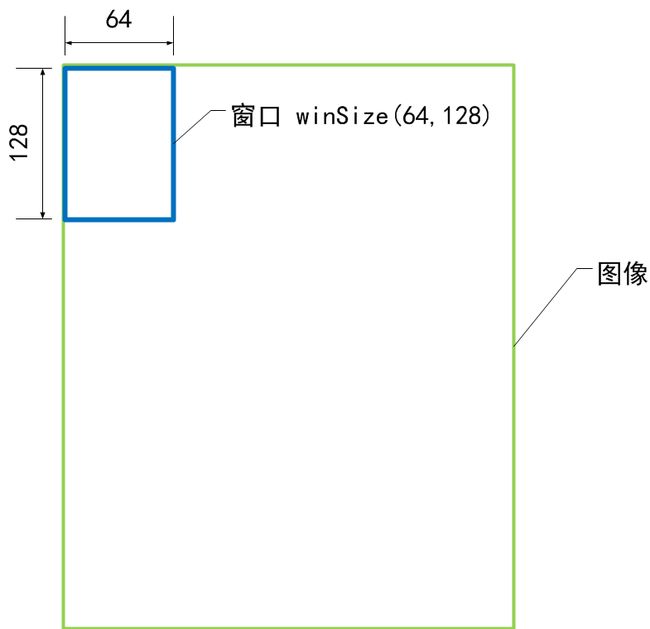
块大小 blockSize
胞元大小 cellSize
梯度方向数 nbins
nBins表示在一个胞元(cell)中统计梯度的方向数目,例如nBins=9时,在一个胞元内统计9个方向的梯度直方图,每个方向为180/9=20度。
HOG描述子维度
在确定了上述的参数后,我们就可以计算出一个HOG描述子的维度了。OpenCV中的HOG源代码是按照下面的式子计算出描述子的维度的。
- size_t HOGDescriptor::getDescriptorSize()const
- {
- CV_Assert(blockSize.width % cellSize.width == 0 &&
- blockSize.height % cellSize.height == 0);
- CV_Assert((winSize.width - blockSize.width) % blockStride.width == 0 &&
- (winSize.height - blockSize.height) % blockStride.height == 0 );
- return (size_t)nbins*
- (blockSize.width/cellSize.width)*
- (blockSize.height/cellSize.height)*
- ((winSize.width - blockSize.width)/blockStride.width + 1)*
- ((winSize.height - blockSize.height)/blockStride.height + 1);
- }
size_t HOGDescriptor::getDescriptorSize() const
{
CV_Assert(blockSize.width % cellSize.width == 0 &&
blockSize.height % cellSize.height == 0);
CV_Assert((winSize.width - blockSize.width) % blockStride.width == 0 &&
(winSize.height - blockSize.height) % blockStride.height == 0 );
return (size_t)nbins*
(blockSize.width/cellSize.width)*
(blockSize.height/cellSize.height)*
((winSize.width - blockSize.width)/blockStride.width + 1)*
((winSize.height - blockSize.height)/blockStride.height + 1);
}
Histogram of Oriented Gridients,缩写为HOG,是目前计算机视觉、模式识别领域很常用的一种描述图像局部纹理的特征。这个特征名字起的也很直白,就是说先计算图片某一区域中不同方向上梯度的值,然后进行累积,得到直方图,这个直方图呢,就可以代表这块区域了,也就是作为特征,可以输入到分类器里面了。那么,接下来介绍一下HOG的具体原理和计算方法,以及一些引申。
1.分割图像
因为HOG是一个局部特征,因此如果你对一大幅图片直接提取特征,是得不到好的效果的。原理很简单。从信息论角度讲,例如一幅640*480的图像,大概有30万个像素点,也就是说原始数据有30万维特征,如果直接做HOG的话,就算按照360度,分成360个bin,也没有表示这么大一幅图像的能力。从特征工程的角度看,一般来说,只有图像区域比较小的情况,基于统计原理的直方图对于该区域才有表达能力,如果图像区域比较大,那么两个完全不同的图像的HOG特征,也可能很相似。但是如果区域较小,这种可能性就很小。最后,把图像分割成很多区块,然后对每个区块计算HOG特征,这也包含了几何(位置)特性。例如,正面的人脸,左上部分的图像区块提取的HOG特征一般是和眼睛的HOG特征符合的。
接下来说HOG的图像分割策略,一般来说有overlap和non-overlap两种,如下图所示。overlap指的是分割出的区块(patch)互相交叠,有重合的区域。non-overlap指的是区块不交叠,没有重合的区域。这两种策略各有各的好处。


先说overlap,这种分割方式可以防止对一些物体的切割,还是以眼睛为例,如果分割的时候正好把眼睛从中间切割并且分到了两个patch中,提取完HOG特征之后,这会影响接下来的分类效果,但是如果两个patch之间overlap,那么至少在一个patch会有完整的眼睛。overlap的缺点是计算量大,因为重叠区域的像素需要重复计算。
再说non-overlap,缺点就是上面提到的,有时会将一个连续的物体切割开,得到不太“好”的HOG特征,优点是计算量小,尤其是与Pyramid(金字塔)结合时,这个优点更为明显。
2.计算每个区块的方向梯度直方图
将图像分割后,接下来就要计算每个patch的方向梯度直方图。步骤如下:
A.利用任意一种梯度算子,例如:sobel,laplacian等,对该patch进行卷积,计算得到每个像素点处的梯度方向和幅值。具体公式如下:
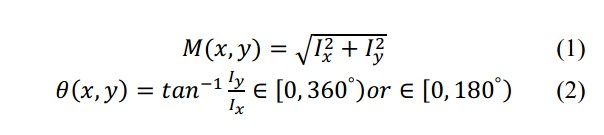
其中,Ix和Iy代表水平和垂直方向上的梯度值,M(x,y)代表梯度的幅度值,θ(x,y)代表梯度的方向。
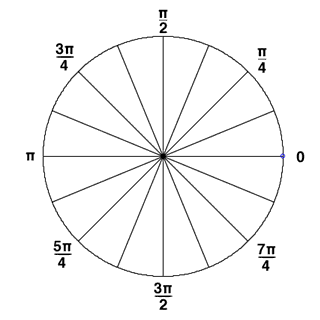
B.将360度(2*PI)根据需要分割成若干个bin,例如:分割成12个bin,每个bin包含30度,整个直方图包含12维,即12个bin。然后根据每个像素点的梯度方向,利用双线性内插法将其幅值累加到直方图中。

C.(可选)将图像分割成更大的Block,并利用该Block对其中的每个小patch进行颜色、亮度的归一化,这一步主要是用来去掉光照、阴影等影响的,对于光照影响不剧烈的图像,例如很小区域内的字母,数字图像,可以不做这一步。而且论文中也提及了,这一步的对于最终分类准确率的影响也不大。
3.组成特征
将从每个patch中提取出的“小”HOG特征首尾相连,组合成一个大的一维向量,这就是最终的图像特征。可以将这个特征送到分类器中训练了。例如:有4*4=16个patch,每个patch提取12维的小HOG,那么最终特征的长度就是:16*12=192维。
4.一些引申
与pyramid相结合,即PHOG。PHOG指的是,对同一幅图像进行不同尺度的分割,然后计算每个尺度中patch的小HOG,最后将他们连接成一个很长的一维向量,作为特征。例如:对一幅512*512的图像先做3*3的分割,再做6*6的分割,最后做12*12的分割。接下来对分割出的patch计算小HOG,假设为12个bin即12维。那么就有9*12+36*12+144*12=2268维。需要注意的是,在将这些不同尺度上获得的小HOG连接起来时,必须先对其做归一化,因为3*3尺度中的HOG任意一维的数值很可能比12*12尺度中任意一维的数值大很多,这是因为patch的大小不同造成的。PHOG相对于传统HOG的优点,是可以检测到不同尺度的特征,表达能力更强。缺点是数据量和计算量都比HOG大了不少。
参考文献:
Navneet Dalal and Bill Triggs,《Histograms of Oriented Gradients for Human Detection》,2005
A. Bosch, A. Zisserman, and X. Munoz, 《Representing shape with a spatial pyramid kernel》,2007