HOG 梯度方向直方图
Histogram of Oriented Gridients,缩写为HOG,是目前计算机视觉、模式识别领域很常用的一种描述图像局部纹理的特征。这个特征名字起的也很直白,就是说先计算图片某一区域中不同方向上梯度的值,然后进行累积,得到直方图,这个直方图呢,就可以代表这块区域了,也就是作为特征,可以输入到分类器里面了。那么,接下来介绍一下HOG的具体原理和计算方法,以及一些引申。
1.分割图像
因为HOG是一个局部特征,因此如果你对一大幅图片直接提取特征,是得不到好的效果的。原理很简单。从信息论角度讲,例如一幅640*480的图像,大概有30万个像素点,也就是说原始数据有30万维特征,如果直接做HOG的话,就算按照360度,分成360个bin,也没有表示这么大一幅图像的能力。从特征工程的角度看,一般来说,只有图像区域比较小的情况,基于统计原理的直方图对于该区域才有表达能力,如果图像区域比较大,那么两个完全不同的图像的HOG特征,也可能很相似。但是如果区域较小,这种可能性就很小。最后,把图像分割成很多区块,然后对每个区块计算HOG特征,这也包含了几何(位置)特性。例如,正面的人脸,左上部分的图像区块提取的HOG特征一般是和眼睛的HOG特征符合的。
接下来说HOG的图像分割策略,一般来说有overlap和non-overlap两种,如下图所示。overlap指的是分割出的区块(patch)互相交叠,有重合的区域。non-overlap指的是区块不交叠,没有重合的区域。这两种策略各有各的好处。


先说overlap,这种分割方式可以防止对一些物体的切割,还是以眼睛为例,如果分割的时候正好把眼睛从中间切割并且分到了两个patch中,提取完HOG特征之后,这会影响接下来的分类效果,但是如果两个patch之间overlap,那么至少在一个patch会有完整的眼睛。overlap的缺点是计算量大,因为重叠区域的像素需要重复计算。
再说non-overlap,缺点就是上面提到的,有时会将一个连续的物体切割开,得到不太“好”的HOG特征,优点是计算量小,尤其是与Pyramid(金字塔)结合时,这个优点更为明显。
2.计算每个区块的方向梯度直方图
将图像分割后,接下来就要计算每个patch的方向梯度直方图。步骤如下:
A.利用任意一种梯度算子,例如:sobel,laplacian等,对该patch进行卷积,计算得到每个像素点处的梯度方向和幅值。具体公式如下:
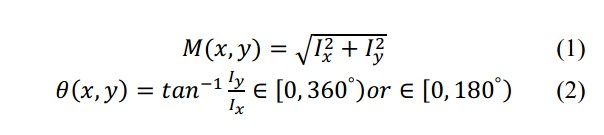
其中,Ix和Iy代表水平和垂直方向上的梯度值,M(x,y)代表梯度的幅度值,θ(x,y)代表梯度的方向。
B.将360度(2*PI)根据需要分割成若干个bin,例如:分割成12个bin,每个bin包含30度,整个直方图包含12维,即12个bin。然后根据每个像素点的梯度方向,利用双线性内插法将其幅值累加到直方图中。
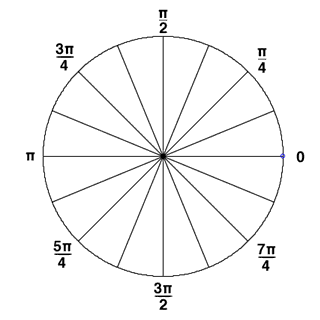

C.(可选)将图像分割成更大的Block,并利用该Block对其中的每个小patch进行颜色、亮度的归一化,这一步主要是用来去掉光照、阴影等影响的,对于光照影响不剧烈的图像,例如很小区域内的字母,数字图像,可以不做这一步。而且论文中也提及了,这一步的对于最终分类准确率的影响也不大。
3.组成特征
将从每个patch中提取出的“小”HOG特征首尾相连,组合成一个大的一维向量,这就是最终的图像特征。可以将这个特征送到分类器中训练了。例如:有4*4=16个patch,每个patch提取12维的小HOG,那么最终特征的长度就是:16*12=192维。
4.一些引申
与pyramid相结合,即PHOG。PHOG指的是,对同一幅图像进行不同尺度的分割,然后计算每个尺度中patch的小HOG,最后将他们连接成一个很长的一维向量,作为特征。例如:对一幅512*512的图像先做3*3的分割,再做6*6的分割,最后做12*12的分割。接下来对分割出的patch计算小HOG,假设为12个bin即12维。那么就有9*12+36*12+144*12=2268维。需要注意的是,在将这些不同尺度上获得的小HOG连接起来时,必须先对其做归一化,因为3*3尺度中的HOG任意一维的数值很可能比12*12尺度中任意一维的数值大很多,这是因为patch的大小不同造成的。PHOG相对于传统HOG的优点,是可以检测到不同尺度的特征,表达能力更强。缺点是数据量和计算量都比HOG大了不少。
参考文献:
Navneet Dalal and Bill Triggs,《Histograms of Oriented Gradients for Human Detection》,2005
A. Bosch, A. Zisserman, and X. Munoz, 《Representing shape with a spatial pyramid kernel》,2007
方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。此方法使用了图像的本身的梯度方向特征,类似于边缘方向直方图方法,SIFT描述子,和上下文形状方法,但其特征在于其在一个网格密集的大小统一的方格单元上计算,而且为了提高精确度使用了重叠的局部对比度归一化的方法。
这篇文章的作者Navneet Dalal和Bill Triggs是法国国家计算机技术和控制研究所French National Institute for Research in Computer Science and Control (INRIA)的研究员。他们在这篇文章中首次提出了HOG方法。这篇文章被发表在2005年的CVPR上。他们主要是将这种方法应用在静态图像中的行人 检测上,但在后来,他们也将其应用在电影和视频中的行人检测,以及静态图像中的车辆和常见动物的检测。
HOG描述器最重要的思想是:在一副图像中,局部目标的表象和形状(appearance and shape)能够被梯度或边缘的方向密度分布很好地描述。具体的实现方法是:首先将图像分成小的连通区域,我们把它叫细胞单元(cell)。然后采集细胞单元中各像素点的梯度或边缘的方向直方图。最后把这些直方图组合起来就可以构成特征描述器。为了提高性能,我们还可以把这些局部直方图在图像的更大的范围内(我们把它叫区间或block)进行对比度归一化(contrast-normalized),所采用的方法是:先计算各直方图在这个区间(block)中的密度,然后根据这个密度对区间中的各个细胞单元做归一化。通过这个归一化后,能对光照变化和阴影获得更好的效果。
与其他的特征描述方法相比,HOG描述器后很多优点。首先,由于HOG方法是在图像的局部细胞单元上操作,所以它对图像几何的(geometric)和光学的(photometric)形变都能保持很好的不变性,这两种形变只会出现在更大的空间领域上。
图像处理流程为:

而具体的区域分块图,cell和Block的关系图为:
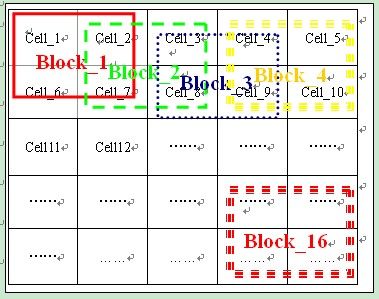

上面两图充分说明了cell和Block的关系。如图一,假设图像为40*40,假定每个Block有2*2个cell,每个cell为8*8,因此有4*4个Block存在。
另外,每个cell的梯度方向分成z个方向块,使用cell中的梯度方向和幅度对z个方向进行加权投影,最后每个cell产生z维的特征向量。Dalal等用于人体检测的HOG选取z=9,即将360度分成9个方向块,继而用于对方向梯度进行投影,如下图:
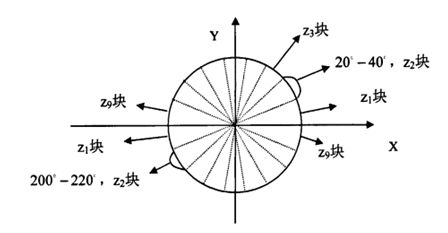
算法的实现:
(1)色彩和伽马归一化 (color and gamma normalization)
作者分别在灰度空间、RGB色彩空间和LAB色彩空间上对图像进行色彩和 伽马归一化,但实验结果显示,这个归一化的预处理工作对最后的结果没有影响,原因可能是:在后续步骤中也有归一化的过程,那些过程可以取代这个预处理的归一化。所以,在实际应用中,这一步可以省略。
(2)梯度的计算(Gradient computation)
最常用的方法是:简单地使用一个一维的离散微分模板(1-D centered point discrete derivative mask)在一个方向上或者同时在水平和垂直两个方向上对图像进行处理,更确切地说,这个方法需要使用下面的滤波器核滤除图像中的色彩或变化剧烈的数据(color or intensity data)
作者也尝试了其他一些更复杂的模板,如3×3 Sobel 模板,或对角线模板(diagonal masks),但是在这个行人检测的实验中,这些复杂模板的表现都较差,所以作者的结论是:模板越简单,效果反而越好。作者也尝试了在使用微分模板前加入一个高斯平滑滤波,但是这个高斯平滑滤波的加入使得检测效果更差,原因是:许多有用的图像信息是来自变化剧烈的边缘,而在计算梯度之前加入高斯滤波会把这些边缘滤除掉。
(3)构建方向的直方图(creating the orientation histograms)
第三步就是为图像的每个细胞单元构建梯度方向直方图。细胞单元中的每一个像素点都为某个基于方向的直方图通道(orientation-based histogram channel)投票。投票是采取加权投票(weighted voting)的方式,即每一票都是带权值的,这个权值是根据该像素点的梯度幅度计算出来。可以采用幅值本身或者它的函数来表示这个权值,实际测试表明:使用幅值来表示权值能获得最佳的效果,当然,也可以选择幅值的函数来表示,比如幅值的平方根(square root)、幅值的平方(square of the gradient magnitude)、幅值的截断形式(clipped version of the magnitude)等。细胞单元(cell)可以是矩形的(rectangular),也可以是星形的(radial)。直方图通道是平均分布在0°-180°(无 向)或0°-360°(有向)范围内。作者发现,采用无向的梯度和9个直方图通道,能在行人检测试验中取得最佳的效果。
(4)把细胞单元(cell)组合成大的区间(grouping the cells together into larger blocks)
由于局部光照的变化 (variations of illumination)以及前景-背景对比度(foreground-background contrast)的变化,使得梯度强度(gradient strengths)的变化范围非常大。这就需要对梯度强度做归一化,作者采取的办法是:把各个细胞单元组合成大的、空间上连通的区间(blocks)。 这样以来,HOG描述器就变成了由各区间所有细胞单元的直方图成分所组成的一个向量。这些区间是互有重叠的,这就意味着:每一个细胞单元的输出都多次作用于最终的描述器。区间有两个主要的几何形状——矩形区间(R-HOG)和环形区间(C-HOG)。R-HOG区间大体上是一些方形的格子,它可以有三个参数来表征:每个区间中细胞单元的数目、每个细胞单元中像素点的数目、每个细胞的直方图通道数目。作者通过实验表明,行人检测的最佳参数设置是:3×3细胞 /区间、6×6像素/细胞、9个直方图通道。作者还发现,在对直方图做处理之前,给每个区间(block)加一个高斯空域窗口(Gaussian spatial window)是非常必要的,因为这样可以降低边缘的周围像素点(pixels around the edge)的权重。
R-HOG跟SIFT描述器看起来很相似,但他们的不同之处是:R-HOG是在单一尺度下、密集的网格内、没有对方向排序的情况下被计算出来(are computed in dense grids at some single scale without orientation alignment);而SIFT描述器是在多尺度下、稀疏的图像关键点上、对方向排序的情况下被计算出来(are computed at sparse scale-invariant key image points and are rotated to align orientation)。补充一点,R-HOG是各区间被组合起来用于对空域信息进行编码(are used in conjunction to encode spatial form information),而SIFT的各描述器是单独使用的(are used singly)。
C- HOG区间(blocks)有两种不同的形式,它们的区别在于:一个的中心细胞是完整的,一个的中心细胞是被分割的。
作者发现 C-HOG的这两种形式都能取得相同的效果。C-HOG区间(blocks)可以用四个参数来表征:角度盒子的个数(number of angular bins)、半径盒子个数(number of radial bins)、中心盒子的半径(radius of the center bin)、半径的伸展因子(expansion factor for the radius)。通过实验,对于行人检测,最佳的参数设置为:4个角度盒子、2个半径盒子、中心盒子半径为4个像素、伸展因子为2。前面提到过,对于R- HOG,中间加一个高斯空域窗口是非常有必要的,但对于C-HOG,这显得没有必要。C-HOG看起来很像基于形状上下文(Shape Contexts)的方法,但不同之处是:C-HOG的区间中包含的细胞单元有多个方向通道(orientation channels),而基于形状上下文的方法仅仅只用到了一个单一的边缘存在数(edge presence count)。
(5)区间归一化 (Block normalization)
区间归一化 (Block normalization)
作者采用了四中不同的方法对区间进行归一化,并对结果进行了比较。引入v表示一个还没有被归一化的向量,它包含了给定区间(block)的所有直方图信息。| | vk | |表示v的k阶范数,这里的k取1、2。用e表示一个很小的常数。这时,归一化因子可以表示如下:
L2-norm:
L1-norm:
L1-sqrt:
还有第四种归一化方式:L2-Hys,它可以通过先进行L2-norm,对结果进行截短(clipping),然后再重新归一化得到。作者发现:采用L2- Hys L2-norm 和 L1-sqrt方式所取得的效果是一样的,L1-norm稍微表现出一点点不可靠性。但是对于没有被归一化的数据来说,这四种方法都表现出来显着的改进。
转自;http://www.cnblogs.com/hrlnw/archive/2013/08/06/2826651.html http://www.cnblogs.com/slysky/archive/2012/04/25/2470057.html
very useful: http://hi.baidu.com/nokltkmtsfbnsyq/item/f4b73d06f066cd193a53eec3
http://www.blogbus.com/shijuanfeng-logs/100675127.html
http://blog.csdn.net/meijia_tts/article/details/7105280
http://blog.csdn.net/anson2004110/article/details/12993999
http://blog.csdn.net/iAm333/article/details/18144575
http://blog.csdn.net/carson2005/article/details/7841443
http://blog.csdn.net/zxia1/article/details/34816003