深度学习Pytorch(九)——迁移学习
深度学习Pytorch(九)——迁移学习
文章目录
- 深度学习Pytorch(九)——迁移学习
-
- 一、简介
- 二、实例
-
- 1、导入package
- 2、加载数据
- 3、可视化部分图像数据
- 4、训练model
- 5、可视化模型的预测结果
- 6、迁移学习使用场景1——微调ConvNet
- 7、迁移学习使用场景2——ConvNet作为固定特征提取器
一、简介
实际中,基本上没有人会从零开始(随机初始化)训练一个完整的卷积网络,因为相对于网络,很难得到一个足够大的数据集(网络很深,需要足够大的数据集训练)。通常的做法是在一个很大的数据集进行预训练得到卷积网络ConvNet,之后将这个ConvNet的参数作为目标任务的初始化参数或者固定这些参数。
转移学习使用的两个主要场景:
- 微调ConvNet:使用预训练的网络(如在ImageNet 1000上训练而来的网络)出事胡爱自己的网络,而不是随机初始化。其中其他的训练步骤不变。
- 将ConvNet看成固定的特征提取器:首先固定ConvNet除了最后的全连接层外的其他所有层。最后的全连接层被替换成一个新的随机初始化的层,只有这个新的层会被训练(只有这层参数会在反向传播时更新)
二、实例
使用Pytorch进行迁移学习——训练一个model对蚂蚁和蜜蜂进行分类
1、导入package
# -*- coding: utf-8 -*-
"""
Created on Tue Nov 2 12:21:24 2021
@author: Lenovo
"""
#%%导入package
from __future__ import print_function,division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets,models,transforms
import matplotlib.pyplot as plt
import time
import os
import copy
2、加载数据
在这个例子中时训练一个model来分类ants和bees。ants和bees各有大概120张训练图片,75张验证图片(如下)。从零开始在如此小的数据集进行训练通常很难做到泛化。使用迁移学习,model的泛化能力会相对好。该数据集是ImageNet的一个非常小的自己。数据集——>我在这里(下载,并解压到自己的工作目录)

#%%加载数据
# 在训练集数据扩充和归一化,在验证集只需要归一化
data_transforms={
'train':transforms.Compose([
transforms.RandomResizedCrop(224),#随机裁剪area以后resize
transforms.RandomHorizontalFlip(),#随机水平翻转
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]),
'val':transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]),
}
data_dir='D:\Python\Pytorch\data\hymenoptera_data'
image_datasets={x:datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train','val']}
dataloaders={x:torch.utils.data.DataLoader(image_datasets[x],batch_size=4,
shuffle=True,num_workers=4)
for x in ['train','val']}
dataset_sizes={x:len(image_datasets[x]) for x in ['train','val']}
class_names=image_datasets['train'].classes
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
3、可视化部分图像数据
为了便于了解数据扩充,可视化部分图像数据
#%%可视化部分图像数据
def imshow(inp,title=None):
inp=inp.numpy().transpose((1,2,0))
mean=np.array([0.485,0.456,0.406])
std=np.array([0.229,0.224,0.225])
inp=std*inp+mean
inp=np.clip(inp,0,1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)
# 获取一批训练数据
inputs,classes=next(iter(dataloaders['train']))
#批量制作网格
out=torchvision.utils.make_grid(inputs)
imshow(out,title=[class_names[x] for x in classes])
运行结果

4、训练model
编写一个通用函数来训练模型,下面的参数scheduler是一个来自torch.optim.lr_scheduler的学习效率调整类的对象
#%%训练模型
def train_model(model,criterion,optimizer,scheduler,num_epochs=25):
since=time.time()
best_model_wts=copy.deepcopy(model.state_dict())
best_acc=0.0
for epoch in range(num_epochs):
print('Epoch{}/{}'.format(epoch, num_epochs-1))
print('-'*10)
# 每个epoch都有一个训练个验证阶段
for phase in ['train','val']:
if phase=='train':
scheduler.step()
model.train()#设置模型处于训练模式
else:
model.eval()#设置模型处于评测阶段
running_loss=0.0
running_corrects=0
#迭代数据
for inputs,labels in dataloaders[phase]:
inputs=inputs.to(device)
labels=labels.to(device)
#梯度置零
optimizer.zero_grad()
# 向前传播
with torch.set_grad_enabled(phase=='train'):
outputs=model(inputs)
_,preds=torch.max(outputs,1)
loss=criterion(outputs,labels)
#向后传播,只在训练阶段进行优化
if phase=='train':
loss.backward()
optimizer.step()
# 统计
running_loss+=loss.item()*inputs.size(0)
running_corrects+=torch.sum(preds==labels.data)
epoch_loss=running_loss/dataset_sizes[phase]
epoch_acc=running_corrects.double()/dataset_sizes[phase]
print('{} loss:{:.4f} Acc:{:.4f}'.format(phase, epoch_loss,epoch_acc))
if phase=='val' and epoch_acc>best_acc:
best_acc=epoch_acc
best_model_wts=copy.deepcopy(model.state_dict())
print()
time_elapsed=time.time()-since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed//60, time_elapsed%60))
print('Best val Acc:{:4f}'.format(best_acc))
# 加载最佳模型权重
model.load_state_dict(best_model_wts)
return model
5、可视化模型的预测结果
#%%可视化model的预测结果
def visualize_model(model,num_images=6):#展示少量预测图片的函数
was_training=model.training
model.eval()
images_so_far=0
fig=plt.figure()
with torch.no_grad():
for i,(inputs,labels) in enumerate(dataloaders['val']):
inputs=inputs.to(device)
labels=labels.to(device)
outputs=model(inputs)
_,preds=torch.max(outputs,1)
for j in range(inputs.size()[0]):
images_so_far+=1
ax=plt.subplot(num_images//2,2,images_so_far)
ax.axis('off')
ax.set_title('predicted:{}'.format(class_names[preds[j]]))
imshow(inputs.cpu().data[j])
if images_so_far()==num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
6、迁移学习使用场景1——微调ConvNet
#%%场景1:微调convnet
#加载预训练模型并重置最终完成连接的图层
model_ft=models.resnet18(pretrained=True)
num_ftrs=model_ft.fc.in_features
model_ft.fc=nn.Linear(num_ftrs, 2)
model_ft=model_ft.to(device)
criterion=nn.CrossEntropyLoss()
# 观察所有参数都在优化
optimizer_ft=optim.SGD(model_ft.parameters(), lr=0.001,momentum=0.9)
# 设置gamma=0.1,每7个epoch衰减learning——rate
exp_lr_scheduler=lr_scheduler.StepLR(optimizer_ft,step_size=7,gamma=0.1)
# 训练模型
model_ft=train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,num_epochs=25)
此处在第一次执行过程中会下载一个.pth文件,会很慢(建议大家先执行,查看这个文件下载以后需要放置的位置,将其放在指定位置。文件大家可以直接复制terminal中的路径去下载(原本想给你们放我的链接,但是我的terminal被后面的训练模型输出语句侵占了,找不到了,大家自行下载,有问题再找我吧~)
注:在CPU上这个训练过程需要大概20-30分钟,估计在GPU上只需要1分钟,没有GPU的靓仔哭泣
运行结果
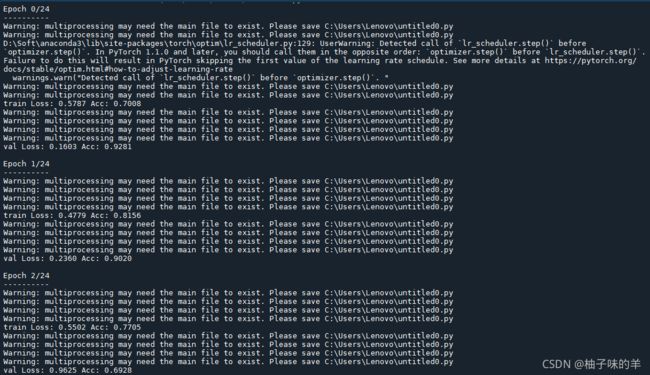
…

不要惊讶,为什么有这么多warning,就是因为我没有一个好习惯——代码永远都是所有的写完或者今天不想写了才知道保存(前段时间哥哥提醒过让我时常保存自己现做的东西,因为前几天停了一次电,咋就,害)但是因为训练时间太久了,我不想再等了,就不再训练了,见谅~
于心不忍,又重新跑了一遍,截了一个好看的图
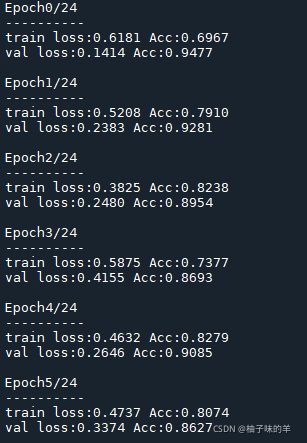
…
来看看训练后的预测结果吧!
#%%
# 模型评估效果可视化
visualize_model(model_ft)
运行结果

感觉还不戳~
7、迁移学习使用场景2——ConvNet作为固定特征提取器
在这里需要冻结除了最后一层之外的所有网络。通过设置requires_grad==Falsebackward()来冻结参数,这样在反向传播backward()的时候梯度才不会被计算
#%%场景2:convnet作为固定特征提取器
model_conv=torchvision.models.resnet18(pretrained=True)
for param in model_conv.parameters():
param.requires_grad=False
num_ftrs=model_conv.fc.in_features
model_conv.fc=nn.Linear(num_ftrs, 2)
model_conv=model_conv.to(device)
criterion=nn.CrossEntropyLoss()
optimizer_conv=optim.SGD(model_conv.fc.parameters(), lr=0.001,momentum=0.9)
exp_lr_scheduler=lr_scheduler.StepLR(optimizer_ft,step_size=7,gamma=0.1)
model_conv=train_model(model_conv, criterion, optimizer_conv, exp_lr_scheduler,num_epochs=25)

这次是好看的训练过程~
#%%
visualize_model(model_conv)
plt.ioff()
plt.show()
运行结果

今日告一段落,赶紧看文献去了,明天有组会~
明天见,明天见~~