【机器学习】网格搜索、随机搜索和贝叶斯搜索实用教程
在机器学习中,超参数是指无法从数据中学习而需要在训练前提供的参数。机器学习模型的性能在很大程度上依赖于寻找最佳超参数集。
超参数调整一般是指调整模型的超参数,这基本上是一个非常耗时的过程。在本文中,小编将和你一起研习 3 种最流行的超参数调整技术:网格搜索、随机搜索和贝叶斯搜索。其实还有第零种调参方法,就是手动调参,因为简单机械,就不在本文讨论范围内。为方便阅读,列出本文的结构如下:
1.获取和准备数据
2.网格搜索
3.随机搜索
4.贝叶斯搜索
5.写在最后
![]()
获取和准备数据
![]()
为演示方便,本文使用内置乳腺癌数据来训练支持向量分类(SVC)。可以通过load_breast_cancer函数获取数据。
import pandas as pd
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
df_X = pd.DataFrame(cancer['data'], columns=cancer['feature_names'])
df_X.head()
接下来为特征和目标标签创建df_X和df_y,如下所示:
df_y = pd.DataFrame(cancer['target'], columns=['Cancer'])
df_y.head()
PS :如果想了解更多关于数据集的信息,可以运行
print(cancer['DESCR'])打印出摘要和特征信息。
接下来,使用training_test_split()方法将数据集拆分为训练集 (70%) 和测试集 (30%) :
# train test split
from sklearn.model_selection import train_test_split
import numpy as np
X_train, X_test, y_train, y_test = train_test_split(df_X, np.ravel(df_y), test_size=0.3)我们将训练支持向量分类器(SVC) 模型。正则化参数C和核系数gamma是 SVC 中最重要的两个超参数:
正则化参数
C决定了正则化的强度。核系数
gamma控制核的宽度。SVC默认使用径向基函数 (RBF)核(也称为高斯核)。
我们将在以下教程中调整这两个参数。
![]()
网格搜索
![]()
最优值C和gamma是比较难找得到的。最简单的解决方案是尝试一堆组合,看看哪种组合效果最好。这种创建参数“网格”并尝试所有可能组合的方法称为网格搜索。
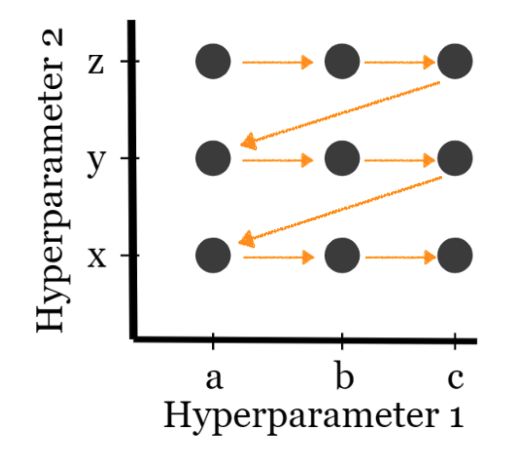 网格搜索——尝试所有可能的组合
网格搜索——尝试所有可能的组合
这种方法非常常见,所以Scikit-learn在GridSearchCV中内置了这种功能。CV 代表交叉验证,这是另一种评估和改进机器学习模型的技术。
GridSearchCV需要一个描述准备尝试的参数和要训练的模型的字典。网格搜索的参数网格定义为字典,其中键是参数,值是要测试的一系列设置值。下面动手试试,首先定义候选参数C和gamma,如下所示:
param_grid = {
'C': [0.1, 1, 10, 100, 1000],
'gamma': [1, 0.1, 0.01, 0.001, 0.0001]
}接下来创建一个GridSearchCV对象,并使用训练数据进行训练模型。
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
grid = GridSearchCV(
SVC(),
param_grid,
refit=True,
verbose=3
)
一旦训练完成后,我们可以通过GridSearchCV的best_params_属性查看搜索到的最佳参数,并使用best_estimator_属性查看最佳模型:
# 找到最好的参数
grid.best_params_{'C': 1, 'gamma': 0.0001}# 找到最好的模型
grid.best_estimator_SVC(C=1, gamma=0.0001)训练完成后,现在选择并采用该网格搜索到的最佳模型,并使用测试集进行预测并创建分类报告和混淆矩阵。
# 使用最好的估计器进行预测
grid_predictions = grid.predict(X_test)
# 混淆矩阵
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test, grid_predictions))[[ 55 5]
[ 1 110]]# 分类模型报告
print(classification_report(y_test, grid_predictions))precision recall f1-score support
0 0.98 0.92 0.95 60
1 0.96 0.99 0.97 111
accuracy 0.96 171
macro avg 0.97 0.95 0.96 171
weighted avg 0.97 0.96 0.96 171![]()
随机搜索
![]()
网格搜索尝试超参数的所有组合,因此增加了计算的时间复杂度,在数据量较大,或者模型较为复杂等等情况下,可能导致不可行的计算成本,这样网格搜索调参方法就不适用了。然而,随机搜索提供更便利的替代方案,该方法只测试你选择的超参数组成的元组,并且超参数值的选择是完全随机的,如下图所示。
 随机搜索尝试随机组合
随机搜索尝试随机组合
这种方法也很常见,所以Scikit-learn在RandomizedSearchCV中内置了这种功能。函数 API 与GridSearchCV类似。
首先指定参数C和gamma以及参数值的候选样本的分布,如下所示:
import scipy.stats as stats
from sklearn.utils.fixes import loguniform
# 指定采样的参数和分布
param_dist = {
'C': stats.uniform(0.1, 1e4),
'gamma': loguniform(1e-6, 1e+1),
}接下来创建一个RandomizedSearchCV带参数n_iter_search的对象,并将使用训练数据来训练模型。
n_iter_search = 20
random_search = RandomizedSearchCV(
SVC(),
param_distributions=param_dist,
n_iter=n_iter_search,
refit=True,
verbose=3)
random_search.fit(X_train, y_train) 输出示例
输出示例
同样,一旦训练完成后,我们可以通过RandomizedSearchCV的best_params_属性查看搜索到的最佳参数,并使用best_estimator_属性查看得到的最佳模型:
>>> random_search.best_params_
{'C': 559.3412579902997, 'gamma': 0.00022332416796205752}
>>> random_search.best_estimator_
SVC(C=559.3412579902997, gamma=0.00022332416796205752)预测 RandomizedSearchCV 并创建报告。
最后,我们采用最终确定的最佳随机搜索模型,并使用测试集进行预测,并创建分类报告和混淆矩阵查看模型效果。
# 使用最好的估计器进行预测
random_predictions = random_search.predict(X_test)
from sklearn.metrics import classification_report, confusion_matrix
# Confusion matrics
print(confusion_matrix(y_test, random_predictions))[[ 57 3]
[ 3 108]]# 分类评价报告
print(classification_report(y_test, random_predictions))precision recall f1-score support
0 0.95 0.95 0.95 60
1 0.97 0.97 0.97 111
accuracy 0.96 171
macro avg 0.96 0.96 0.96 171
weighted avg 0.96 0.96 0.96 171![]()
贝叶斯搜索
![]()
贝叶斯搜索使用贝叶斯优化技术对搜索空间进行建模,以尽快获得优化的参数值。它使用搜索空间的结构来优化搜索时间。贝叶斯搜索方法使用过去的评估结果来采样最有可能提供更好结果的新候选参数(如下图所示)。
 贝叶斯搜索
贝叶斯搜索
Scikit-Optimize[1]库带有 BayesSearchCV 实现。
首先指定参数C和gamma以及参数值的候选样本的分布,如下所示:
from skopt import BayesSearchCV
# 参数范围由下面的一个指定
from skopt.space import Real, Categorical, Integer
search_spaces = {
'C': Real(0.1, 1e+4),
'gamma': Real(1e-6, 1e+1, 'log-uniform'),
}接下来创建一个RandomizedSearchCV带参数n_iter_search的对象,并将使用训练数据来训练模型。
n_iter_search = 20
bayes_search = BayesSearchCV(
SVC(),
search_spaces,
n_iter=n_iter_search,
cv=5,
verbose=3
)
bayes_search.fit(X_train, y_train)
同样,一旦训练完成后,我们可以通过检查发现的最佳参数BayesSearchCV的best_params_属性,并在最佳估计best_estimator_属性:
bayes_search.best_params_OrderedDict([('C', 0.25624177419852506),
('gamma', 0.00016576008531229226)])bayes_search.best_estimator_SVC(C=0.25624177419852506,
gamma=0.00016576008531229226)最后,我们采用贝叶斯搜索模型并使用测试集创建一些预测,并为它们创建分类报告和混淆矩阵。
bayes_predictions = bayes_search.predict(X_test)
from sklearn.metrics import classification_report,confusion_matrix
# 混淆矩阵
print(confusion_matrix(y_test, bayes_predictions))[[ 51 9]
[ 1 110]]# 分类评价报告
print(classification_report(y_test, bayes_predictions))precision recall f1-score support
0 0.98 0.85 0.91 60
1 0.92 0.99 0.96 111
accuracy 0.94 171
macro avg 0.95 0.92 0.93 171
weighted avg 0.94 0.94 0.94 171![]()
写在最后
![]()
在本文中,我们介绍了 3 种最流行的超参数优化技术,这些技术用于获得最佳超参数集,从而训练稳健的机器学习模型。
一般来说,如果组合的数量足够有限,我们可以使用网格搜索技术。但是当组合数量增加时,我们应该尝试随机搜索或贝叶斯搜索,因为它们在计算上并不昂贵。

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载黄海广老师《机器学习课程》视频课黄海广老师《机器学习课程》711页完整版课件本站qq群554839127,加入微信群请扫码:
