以几篇自动驾驶感知论文为例,试着锻炼寻找“领域知识”的能力
一个新领域研究的兴起有时要经历以下几个阶段,首先是得到该领域的一个普遍性的问题,然后将另一个已成熟的领域的一些成熟的方法和技术直接迁移到这个新领域试着解决这个普遍性的问题,接着就会发现两个领域之间的差异性使得直接迁移的方法失效,这时人们会思考这个新领域所特有的一些“本质属性”,通常该本质属性就是产生该领域普遍性问题的根本原因,同时也是使得从其他领域被直接迁移的方法失效的根本原因。在得到该本质属性后,针对其提出的针对性的且极具领域特色的方法才会被认定为解决该领域普遍性问题的基础参照(baseline)。
就以最近新接触到的自动驾驶感知领域的几篇论文为例,试着寻找下这些“本质属性”。
SCNN: Spatial As Deep: Spatial CNN for Traffic Scene Understanding[1][2]
文章大体上是使用分割网络对车载相机图像中的图像进行分割。
是比较早的工作,这时候的对于卷积网络的思考还没有现在这么固化。
于是本文提出了一种新的针对性的分割网络用于车道线的提取,相比于传统网络在各个层之间直接进行卷积的方法不同的是,该网络按照一定方向(上、下、左、右)按照顺序进行卷积,作者认为这样更符合真实世界中物体结构的延伸,尤其是车道线这种持续延伸的目标。
后来作者还另外证明了该种网络对于分割细长类物体的效果格外好。
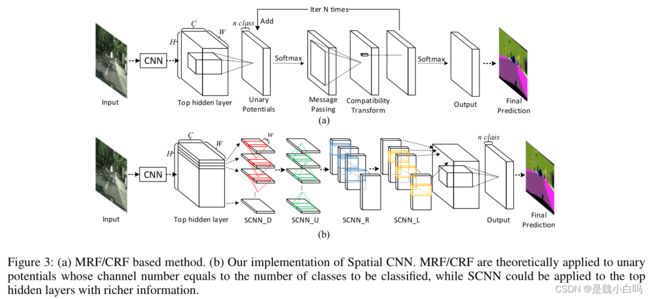
图中的上半部分是传统的网络结构,下半部分是作者自己的结构,可以看出,区别在于中间的那一段,传统方法中,按照二维结构直接进行卷积,一层一层传递下去,而作者在这部分先进行切片,再按照顺序进行卷积。顺序一共四种:下、上、右、左,分别对应图中的"SCNN_D", "SCNN_U", "SCNNR", "SCNNL", 所以切片分为横着切和竖着切,横竖各两次。
需要注意的是,这里的切片模型只是网络的一部分,其他卷积层、全连接层等仍然存在,作者所采用的方法也不是直接设计一个全新的网络,而是把这四个顺序卷积的部分嵌入到一个已有的网络模型中去,作者选用的网络是LargeFOV。新的网络如下图所示。

这里(a)是训练的网络,(b)是用网络进行预测的流程,需要注意的是,(b)中右侧输出了四个数值,这四个数分别对应四条车道线的概率,0.99就是有车道线,0.02就是没有车道线,所以图中就显示了三条车道线,至于为啥是四条,这就属于作者设置的一个先验信息了,如果超过四条,最终也只会输出四条。当然,他既然这么做,就说明至少这个数据集里没有超过四条的。
本文章核心工作是提出了一种新的网络结构,除了结构部分,在训练和测试流程上与其他方法没有大的区别,所以算法流程部分其实就是介绍网络结构的部分。
上面提到,本文中只是在流程中的一部分使用了这种SCNN结构,理解为这种思想更好的利用了全局信息也是可以说得通的。
这篇文章与自动驾驶感知的联系这部分落笔在“在使用这种新型的结构后,网络对于细长、大型类的物体分割效果更好,即对于车道线检测有更好的效果”。
Towards End-to-End Lane Detection: an Instance Segmentation Approach[3][4]
针对之前算法不能解决以下问题:predifined,fixed number of lanes和 lane changes。设计了一个多任务网络分支,主要是车道线分割分支和车道线嵌入分支,可以进行end-to-end的训练,并通过训练网络学习变换参数。
车道分割分支具有两个输出类别,即背景或车道。
车道嵌入分支进一步将分段的车道像素分解成不同的车道实例(instance)。
通过将车道检测问题分解为上述两个任务,我们可以充分利用车道分割分支的功能,而不必为不同的车道分配不同的类别。
针对之前采用固定透视变换转换到“bird-eye”图再进行车道线拟合,本文提出训练一个网络训练来得到其变换系数,可以对多种道路变化鲁棒。
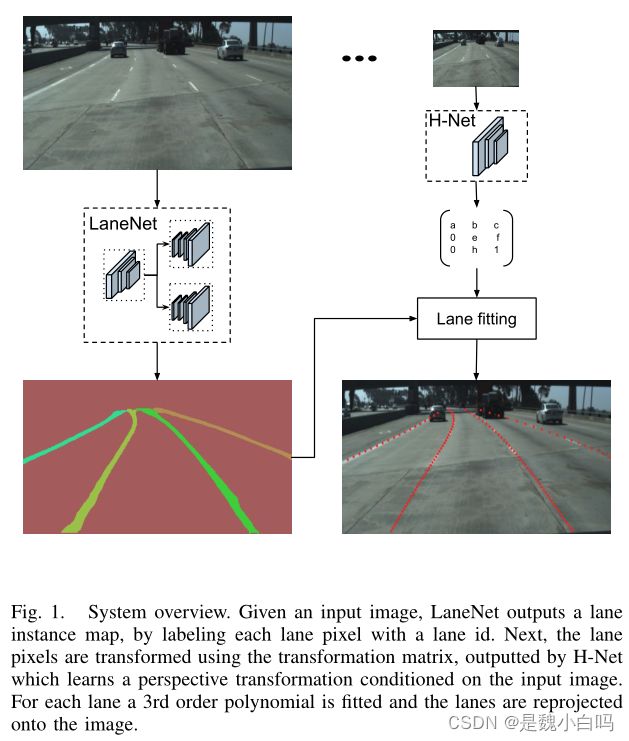
解释一下pixel embedding:embedding与segmentation是encoder里并行的两个分支,encoder是有三个阶段的,其中前两个阶段两个分支是共享参数的,最后一层不共享,分别生成一个channel的二值分割图片,另一个生成n-channel的嵌入向量,其中n是嵌入尺寸。然后经过融合后进行聚类操作。

解释一下为什么要学习H矩阵并做变换:一般地,分割车道线之后是还需要对分割结果进行曲线拟合以生成车道线的。而拟合曲线的时候一般会把图像转换到鸟瞰图角度,也就是让车道线都平行、这样便于拟合、可靠性高,然后求出相应点之后在影射回来,这个变换矩阵之前都是固定的,现在作者让它变为可学习的,鲁棒性更高些。
“使用CNN分割车道线”这一思想倒是不难想到,但将CNN分割应用到自动驾驶感知或者更具体地说应用到车道线检测任务中,需要考虑到什么问题那?这就是这篇论文的落笔,即解决“车道线数目变化(pixel embedding)以及车道视角变化(a learned perspective transformation)”的问题。
Ultra Fast Structure-aware Deep Lane Detection
从目前自动驾驶遇到的两个问题入手:
1.computational cost:自动驾驶的车辆上往往有多个摄像头,如果同时对每个车辆的摄像头进行道路线进行识别的话,需要耗费大量的计算资源,因此需要计算复杂度更低的车道线检测方法。
2.no-visual-clue:在很多道路上,由于车辆拥堵,车道线被车挡住了,需要通过车的位置和环境的语义信息去猜测。在这种情况下,没有视觉信息(车道的颜色 形状)去引导车道线的识别,造成了很大的困难。

其中的第一点更多的是为了凸显本文提出方法的速度而特意提到的,第二点倒像是提出这种方法后,偶然发现这种方法可以解决这类问题。
总之,这篇论文的切入点其实不是上述两点,而是:
Also, there exists a phenomenon that the lanes are represented as segmented binary
features rather than lines or curves. Although deep segmentation methods dominate the
lane detectionfields, this kind of representation makes these methods hard to explicitly
utilize the prior information like rigidity and smoothness of lanes.
之前的方法中,车道线会被表示为分割(分段)的二进制特征,而不是线型(line)或者曲线型(curves),虽然深度分割方法在车道线检测领域占据主导位置,但这种表示方法使得这些方法很难显示地利用车道的刚性和光滑性等先验信息。
也就是UFast这篇论文真正想要解决的是以往的深度学习方法中对于车道线本身所特有的刚性、平滑性这些很重要的属性没有有效利用的问题(我们知道以往直接分割得到的二维图还需要有额外的曲线拟合这一步)。UFast的落笔在于提出一种新的车道线检测方案,即通过grid cells使得网络考虑车道线的特有属性的基础上进行学习,从而完成任务。
Focus on Local: Detecting Lane Marker from Bottom Up via Key Point
看完UFast之后再看这篇论文,其实大概就可以知道,这种脱离分割的方法,大多都会针对分割的运行速度批判一番。这样说一点问题没有,不过还是那句话,这是顺便解决的问题。
而真正需要注意的论述是:
However, the mostly used frameworks can not be seamlessly generalized to curved-shaped lane lines because lane detection task requires precise representation of local positions and global shapes simultaneously, showing their own limitations.
本文认为,车道线检测任务对于局部位置和全局形状都有着严格的要求,给予分割的方法需要后端进行聚类操作,就不能很好地“无缝”衔接这个任务。
更详细点说:基于语义分割的方法预测车道标记区域的二值掩模,在训练和推理中插入聚类模型,将被掩蔽的像素分组到单个实例中,最后使用曲线拟合得到参数化结果。然而,聚类过程使训练和推理流水线变得复杂。此外,曲线拟合的像素级输入往往是冗余的和噪声的,这些都给最终结果的准确性带来了负面影响。
本文认为以往的分割方法是针对紧凑目标而设计的,在面对大规模目标时对像素级误差并不敏感,而车道线通常会占据图像中很大一部分(意思是属于上述的大规模的定义),像素级定位错误会显著影响检测性能。

FoloLane的落笔在:CNN学习的特征的有限视场(FOV)不足以对相距太远的内容建模,即@中所述。换句话说就是:局部位置精度和全局形状信息都很重要,以往的方法没有考虑到这点,而是用特征点加偏移量(网络双分支推理)这种方法可以做到。
@:这些解决方案中的大多数直接对全局几何进行建模,网络必须产生高维输出来描述曲线。然而,从理论上讲,不紧凑的输出增加了对数据和模型容量的需求,最终掩盖了结果模型的泛化能力
Line-CNN: End-to-End Traffic Line Detection With Line Proposal Unit
引言部分中提到的关于“在道路区域检测和测导线检测两种任务中为什么后者比较有意义”这一观点的陈述比较有意思:
As the latter can not only determine the drivable path constrained by the parallel lines, but also carries the traffic rules (e.g., double lines through which vehicles are normally forbidden to pass) and complete global structures that are not reflected by road region segmentation, this paper focuses on the task of traffic line detection.
可通行区域可通过平行的车道线的约束约束确定,还可以包含一些交通规则(如禁止车辆通过双线),以及提供完整的道路区域分割未反映的全局结构。
这篇论文的落笔很容易找到,即在摘要中提到的,以往的方法是先进行线段检测然后进行聚类,他们认为这样做忽略了整条车道线的全局语义信息。而line-CNN利用line-archor作为提议,引导网络学习line特征,将车道线检测问题转化为对line的选择问题,从而利用了全局信息。
这篇论文是比较好的,因为我认为是有两个落笔点的存在。在以往的车道线检测论文中虽然也提到的车道线很容易被遮挡问题,但好像都是“顺便解决的”,只有line-cnn可以说是特意解决的。
还有一个比较有趣的点,也是建立在“考虑全局语义信息”这一观点之上,即论述了一下直接使用RCNN这类区域提议生成检测的方法为什么不行:
This is because the lines are very different from regions as they are slenderer and less compact. The region detectors produce a coarse bounding box to locate the object region. However, the line is usually a curve travelling through an entire scenario that yet only consumes a small proportion of the pixels. As a result, if we use a bounding box to enclose a line, the box will contain many redundant pixels that do not correspond to the line, which is definitely inaccurate and meaningless.
车道线更加的细长,更不紧凑,在一个检测框中只有细长的一部分时域检测对象,其余都是冗余的。
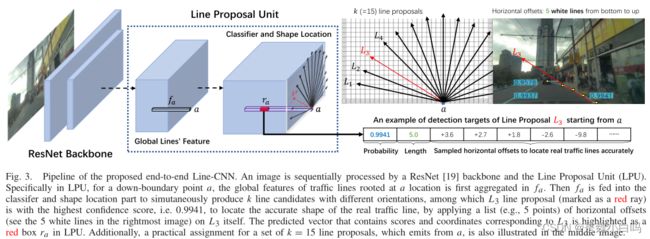
简单说一下是方法流程:1.首先通过fa聚集以某一位置为根的line的全局特征并推理a。2.随后fa被输入到分类器和形状定位部分,产生具有不同方向的k条候选线line。3.从线条建议中选取得分最高的line并通过偏移量拟合真实的准确形状得到最后结果。
参考
[1] 自动驾驶|车道线检测:SCNN(一) - 知乎
[2] 深度学习笔记(十四)车道线检测 SCNN - osc_b07navmi的个人空间 - OSCHINA - 中文开源技术交流社区
[3] 论文阅读《Towards End-to-End Lane Detection: an Instance Segmentation Approach》 - 王老头 - 博客园
[4] [车道线检测论文学习] Towards End-to-End Lane Detection: an Instance Segmentation Approach_Holeung blog-CSDN博客
[5]【车道线检测论文阅读笔记——经典论文粗读汇总】_selami的博客-CSDN博客