《剑指offer》题解——week4(持续更新)
❤ 作者主页:Java技术一点通的博客
❀ 个人介绍:大家好,我是Java技术一点通!( ̄▽ ̄)~*
❀ 微信公众号:Java技术一点通
记得点赞、收藏、评论⭐️⭐️⭐️
认真学习!!!
文章目录
- 一、剑指 Offer 33. 二叉搜索树的后序遍历序列
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 二、剑指 Offer 34. 二叉树中和为某一值的路径
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 三、剑指 Offer 35. 复杂链表的复制
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 四、剑指 Offer 36. 二叉搜索树与双向链表
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 五、剑指 Offer 37. 序列化二叉树
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 六、剑指 Offer 38. 字符串的排列
-
- 1. 题目描述
- 2. 思路分析
- 代码实现
- 六、剑指 Offer 39. 数组中出现次数超过一半的数字
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 七、剑指 Offer 40. 最小的k个数
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 八、剑指 Offer 41. 数据流中的中位数
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 九、剑指 Offer 42. 连续子数组的最大和
-
- 1. 题目描述
- 2. 思路分析
- 3.代码实现
- 十、剑指 Offer 43. 1~n 整数中 1 出现的次数
-
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
一、剑指 Offer 33. 二叉搜索树的后序遍历序列
1. 题目描述

2. 思路分析
什么是二叉搜索树?
它或者是一棵空树,或者是具有下列性质的二叉树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉搜索树。
递归解析:
-
终止条件: 当
l >= r,说明此子树节点数量 ⩽ \leqslant ⩽ 1 ,无需判别正确性,因此直接返回true; -
递推过程:
-
划分左右子树: 遍历给定数组的
[l, r]区间元素,寻找第一个大于根节点的结点,记索引为k。此时,可划分出左子树区间为[l, k - 1]、右子树区间为[k,, r - 1]、根节点索引为r。 -
判断是否为二叉搜索树:
- 左子树区间
[l, k - 1]内的所有结点对应<postorder[k]。而 在第1.划分左右子树步骤已经保证左子树区间的正确性,因此只需要判断右子树区间即可。 - 右子树区间
[k,, r - 1]内的所有结点对应>postorder[k]。实现方式为遍历右子树区间,当遇到 ⩽ \leqslant ⩽postorder[k]的节点则直接返回false
- 左子树区间
-
-
返回值: 所有子树都需正确才判定为正确的二叉搜索树的后序遍历。因此使用 与逻辑符 && 连接。
dfs(l, k - 1):判断 此树的左子树 是否正确。dfs(k, r - 1):判断 此树的右子树 是否正确。
3. 代码实现
class Solution {
public:
vector seq;
bool verifyPostorder(vector& postorder) {
seq = postorder;
if (seq.empty()) return true;
return dfs(0, seq.size() - 1);
}
bool dfs(int l, int r) {
if (l >= r) return true;
int root = seq[r];
int k = l;
while (k < r && seq[k] < root) k ++;
for (int i = k; i < r; i ++ )
if (seq[i] < root)
return false;
return dfs(l, k - 1) && dfs(k, r - 1);
}
};
二、剑指 Offer 34. 二叉树中和为某一值的路径
1. 题目描述

2. 思路分析
做法是使用 DFS,在 DFS 过程中记录路径以及路径对应的元素和,当出现元素和为 target,且到达了叶子节点,说明找到了一条满足要求的路径,将其加入答案。
使用 DFS 的好处是在记录路径的过程中可以使用回溯的方式进行记录及回退,而无须时刻进行路径数组的拷贝。
dfs(root, target)函数:
- 终止条件: 若节点 root 为空,则直接返回。
- 递推过程:
- 路径更新: 将当前节点值
root->val加入路径path; - 目标值更新:
target = target - root->val(知道目标值target减至 0 ); - 路径记录: 当该点位叶子节点
&&路径和等于目标值,则将此路径path加入res。 - 先序遍历: 递归左 / 右子节点。
- 回溯: 向上回溯前,需要将当前节点从路径
path中删除,即执行path.pop_back()。
- 路径更新: 将当前节点值
3. 代码实现
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector> ans;
vector path;
vector> pathSum(TreeNode* root, int target) {
dfs(root, target);
return ans;
}
void dfs(TreeNode *root, int target) {
if (!root) return;
path.push_back(root->val);
target -= root->val;
if (!root->left && !root->right && !target) ans.push_back(path);
dfs(root->left, target);
dfs(root->right, target);
path.pop_back();
}
};
三、剑指 Offer 35. 复杂链表的复制
1. 题目描述
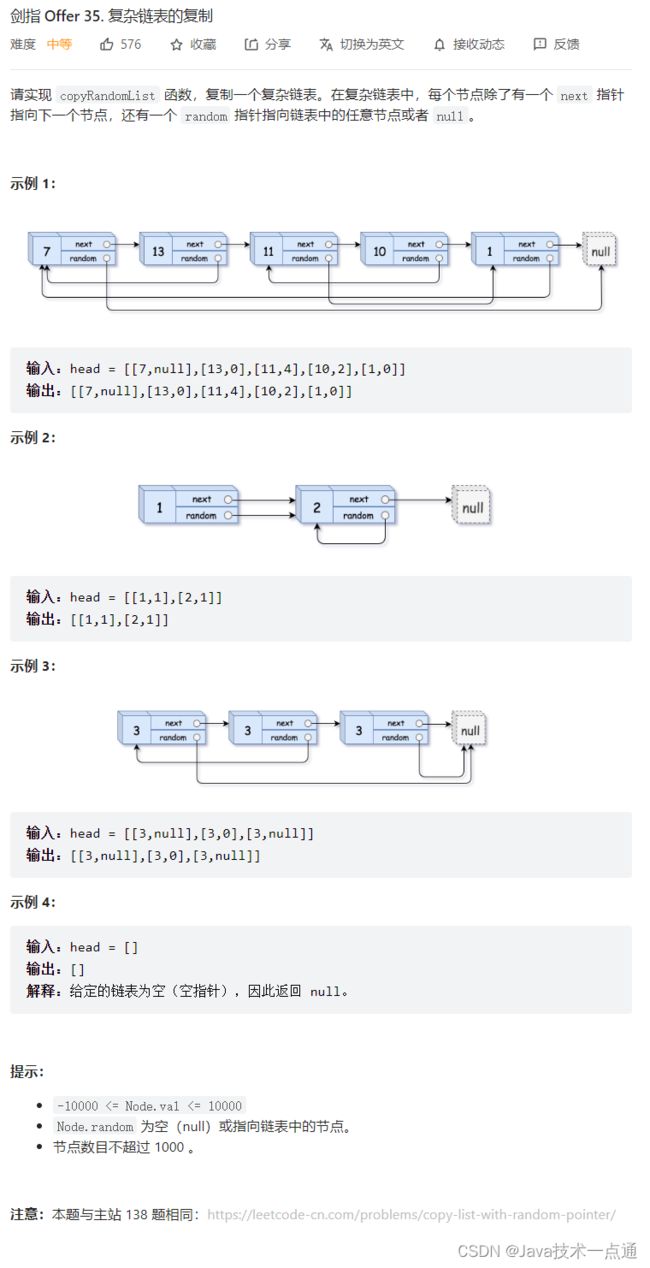
2. 思路分析
拼接 + 拆分
考虑构建 原节点 1 -> 新节点 1 -> 原节点 2 -> 新节点 2 -> …… 的拼接链表,如此便可在访问原节点的 random 指向节点的同时找到新对应新节点的 random 指向节点。
算法流程:
-
复制各节点,构建拼接链表:
- 设原链表为
node1 -> node2 -> ...,构建的拼接链表如下所示:
node1 -> n o d e 1 n e w node1_{new} node1new -> node2 -> n o d e 2 n e w node2_{new} node2new -> …
- 设原链表为
-
构建新链表各节点的
random指向:- 当访问原节点
cur的随机指向节点cur.random时,对应新节点cur.next的随机指向节点为cur.random.next。
- 当访问原节点
-
拆分原 / 新链表:
- 设置虚拟头节点(-1),将
cur指向该虚拟头节点,p指向原链接的头节点,遍历执行cur->next = p->next和p->next = p->next->next将两链表拆分开。
- 设置虚拟头节点(-1),将
-
返回值:
返回虚拟头节点的next即可。
3. 代码实现
/*
// Definition for a Node.
class Node {
public:
int val;
Node* next;
Node* random;
Node(int _val) {
val = _val;
next = NULL;
random = NULL;
}
};
*/
class Solution {
public:
Node* copyRandomList(Node* head) {
for (auto p = head; p;) {
auto np = new Node(p->val);
auto next = p->next;
p->next = np;
np->next = next;
p = next;
}
for (auto p = head; p; p = p->next->next) {
if (p->random)
p->next->random = p->random->next;
}
auto dummy = new Node(-1);
auto cur = dummy;
for (auto p = head; p; p = p->next) {
cur->next = p->next;
cur = cur->next;
p->next = p->next->next;
}
return dummy->next;
}
};
四、剑指 Offer 36. 二叉搜索树与双向链表
1. 题目描述

2. 思路分析
本文解法基于性质:二叉搜索树的中序遍历为 递增序列 。
将 二叉搜索树 转换成一个 “排序的循环双向链表” ,其中包含三个要素:
- 排序链表: 节点应从小到大排序,因此应使用 中序遍历 “从小到大”访问树的节点。
- 双向链表: 在构建相邻节点的引用关系时,设前驱节点
pre和当前节点cur,不仅应构建pre.right = cur,也应构建cur.left = pre。 - 循环链表: 设链表头节点
head和尾节点tail,则应构建head.left = tail和tail.right = head。
算法流程:
-
终止条件: 当节点 cur 为空,代表越过叶节点,直接返回;
-
递归左子树: 即
dfs(cur->left); -
构建链表:
- 当
pre为空时: 代表正在访问链表头节点,记为head; - 当
pre不为空时: 修改双向节点引用,即pre.right = cur,cur.left = pre; - 保存
cur: 更新pre = cur,即节点cur是后继节点的pre;
- 当
-
递归右子树: 即
dfs(cur->right);
3. 代码实现
/*
// Definition for a Node.
class Node {
public:
int val;
Node* left;
Node* right;
Node() {}
Node(int _val) {
val = _val;
left = NULL;
right = NULL;
}
Node(int _val, Node* _left, Node* _right) {
val = _val;
left = _left;
right = _right;
}
};
*/
class Solution {
public:
Node* treeToDoublyList(Node* root) {
if (root == NULL) return NULL;
dfs(root);
head->left = pre;
pre->right = head;
return head;
}
Node *pre, *head;
void dfs(Node* cur) {
if (cur == NULL) return;
dfs(cur->left);
if (pre != NULL) pre->right = cur;
else head = cur;
cur->left = pre;
pre = cur;
dfs(cur->right);
}
};
五、剑指 Offer 37. 序列化二叉树
1. 题目描述

2. 思路分析
序列化:将树转为字符串
层序遍历去转化,然后用StringBuilder去拼接,最后转成String。
反序列化:将字符串转化成树
将字符串先变成字符串数组,除去多余的东西,再慢慢转成树。
3. 代码实现
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
public class Codec {
// Encodes a tree to a single string.
public String serialize(TreeNode root) {
if(root == null) return "[]";
StringBuilder res = new StringBuilder();
Queue queue = new LinkedList<>();
queue.add(root);
res.append("{");
while(!queue.isEmpty()){
int len = queue.size();
for(int i=0;i queue = new LinkedList<>();
queue.add(res);
//用i遍历,很巧妙
int i = 1;
while(!queue.isEmpty()){
TreeNode node = queue.poll();
if(!vals[i].equals("#")){
node.left = new TreeNode(Integer.parseInt(vals[i]));
queue.add(node.left);
}
i++;
if(!vals[i].equals("#")){
node.right = new TreeNode(Integer.parseInt(vals[i]));
queue.add(node.right);
}
i++;
}
return res;
}
}
// Your Codec object will be instantiated and called as such:
// Codec codec = new Codec();
// codec.deserialize(codec.serialize(root));
六、剑指 Offer 38. 字符串的排列
1. 题目描述
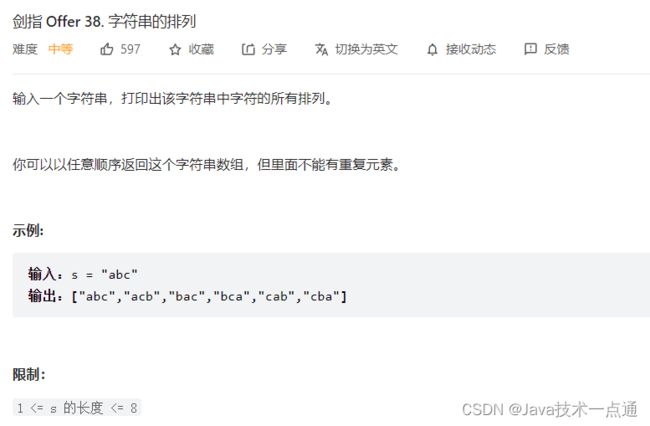
2. 思路分析
dfs:
定义递归函数 dfs(path, u) 表示当前排列为 path,下一个待填入的空位是第 u u u 个空位(下标从 0 开始)。那么该递归函数分为两个情况:
- 如果
u=n,说明我们已经填完了n个空位,找到了一个可行的解,我们将path放入答案数组中,递归结束。 - 如果
ust来标记已经填过的字符,那么在填第 i i i 个字符的时候我们遍历题目给定的 n n n 个字符,如果这个字符没有被标记过,我们就尝试填入,并将其标记,继续尝试填下一个空位,即调用函数dfs(path, u + 1)。回溯时,我们需要要撤销该空位填的字符以及对该字符的标记,并继续向当前空位尝试填入其他没被标记过的字符。
我们只要在递归函数中设定一个规则,保证在填每一个空位的时候重复字符只会被填入一次。具体地,我们首先对原字符串排序,保证相同的字符都相邻,在递归函数中,我们限制每次填入的字符一定是这个字符所在重复字符集合中**「从左往右第一个未被填入的字符」**,即如下的判断条件:
if (i && s[i - 1] == s[i] && st[i - 1]) continue;
代码实现
class Solution {
public:
vector ans;
string path;
vector st;
vector permutation(string s) {
sort(s.begin(), s.end());
st = vector(s.size());
dfs(s, 0);
return ans;
}
void dfs(string s, int u) {
if (u == s.size()) {
ans.push_back(path);
return;
}
for (int i = 0; i < s.size(); i ++ ) {
if (!st[i]) {
if (i && s[i - 1] == s[i] && st[i - 1]) continue;
st[i] = true;
path.push_back(s[i]);
dfs(s, u + 1);
path.pop_back();
st[i] = false;
}
}
}
};
六、剑指 Offer 39. 数组中出现次数超过一半的数字
1. 题目描述

2. 思路分析
我们知道出现次数最多的元素大于 ⌊ n 2 ⌋ \lfloor {n \over 2} \rfloor ⌊2n⌋,所以可以用哈希表来快速统计每个元素出现的次数。
我们使用 哈希映射(HashMap) 来存储每个元素以及出现的次数。对于哈希映射中的每个键值对,键表示一个元素,值表示该元素出现的次数。
我们用一个循环遍历数组 n u m s nums nums 并将数组中的每个元素加入哈希映射中。在这之后,我们遍历哈希映射中的所有键值对,返回值最大的键。我们同样也可以在遍历数组 n u m s nums nums 时候使用打擂台的方法,维护最大的值,这样省去了最后对哈希映射的遍历。
3. 代码实现
class Solution {
public:
int majorityElement(vector& nums) {
unordered_map hash;
int ans = 0, cnt = 0;
for (int num : nums) {
hash[num] ++;
if (hash[num] > cnt) {
ans = num;
cnt = hash[num];
}
}
return ans;
}
};
七、剑指 Offer 40. 最小的k个数
1. 题目描述

2. 思路分析
堆:
维护一个大小为k的大根堆,遍历数组,如果堆中的元素个数小于k或者堆顶元素大于当前元素,则将当前元素压入堆中,当堆中的数大于k时弹出堆顶元素。
注意弹出堆顶的顺序是从大到小的k个数,因此要进行逆序操作。
3. 代码实现
class Solution {
public:
vector getLeastNumbers(vector& arr, int k) {
priority_queue heap;
vector res;
if (k == 0) return res;
for (auto x : arr) {
if (heap.size() < k || heap.top() > x) heap.push(x);
if (heap.size() > k) heap.pop();
}
while (heap.size()) {
res.push_back(heap.top());
heap.pop();
}
reverse(res.begin(), res.end());
return res;
}
};
八、剑指 Offer 41. 数据流中的中位数
1. 题目描述

2. 思路分析
建立一个 小根堆 A A A 和 大根堆 B B B ,各保存列表的一半元素,且规定:
- A A A保存较大的一半,长度为 N 2 {N \over 2} 2N (N为偶数) 或 N + 1 2 {{N + 1} \over 2} 2N+1 (N为奇数);
- B B B保存较小的一半,长度为 N 2 {N \over 2} 2N (N为偶数) 或 N − 1 2 {{N - 1} \over 2} 2N−1 (N为奇数);
算法流程:
设元素总数为 N = m + n N = m + n N=m+n ,其中 m m m 和 n n n 分别为 A A A 和 B B B 中的元素个数。
addNum(num) 函数:
1. 当 m = n m = n m=n(即 N N N 为 偶数):需向 A A A 添加一个元素。实现方法:将新元素 n u m num num 插入至 B B B ,再将 B B B 堆顶元素插入至 A A A ;
2. 当 m ≠ n m \ne n m=n(即 N N N 为 奇数):需向 B B B 添加一个元素。实现方法:将新元素 n u m num num 插入至 A A A ,再将 A A A 堆顶元素插入至 B B B ;
假设插入数字 n u m num num 遇到情况
1.。由于 n u m num num 可能属于 “较小的一半” (即属于 B B B ),因此不能将 n u m num num 直接插入至 A A A 。而应先将 n u m num num 插入至 B B B ,再将 B B B 堆顶元素插入至 A A A 。这样就可以始终保持 A A A 保存较大一半、 B B B 保存较小一半。
findMedian() 函数:
- 当 m = n m = n m=n( N N N 为 偶数):则中位数为 ( A A A 的堆顶元素 + B B B 的堆顶元素 )/2。
- 当 m ≠ n m \ne n m=n( N N N 为 奇数):则中位数为 A A A 的堆顶元素。
3. 代码实现
class MedianFinder {
public:
/** initialize your data structure here. */
priority_queue max_heap;
priority_queue, greater> min_heap;
MedianFinder() {
}
void addNum(int num) {
if (max_heap.size() == min_heap.size()) {
max_heap.push(num);
int top = max_heap.top();
max_heap.pop();
min_heap.push(top);
} else {
min_heap.push(num);
int top = min_heap.top();
min_heap.pop();
max_heap.push(top);
}
}
double findMedian() {
if (max_heap.size() == min_heap.size()) {
return (max_heap.top() + min_heap.top()) / 2.0;
} else {
return min_heap.top();
}
}
};
/**
* Your MedianFinder object will be instantiated and called as such:
* MedianFinder* obj = new MedianFinder();
* obj->addNum(num);
* double param_2 = obj->findMedian();
*/
/**
* Your MedianFinder object will be instantiated and called as such:
* MedianFinder* obj = new MedianFinder();
* obj->addNum(num);
* double param_2 = obj->findMedian();
*/
九、剑指 Offer 42. 连续子数组的最大和
1. 题目描述

2. 思路分析
动态规划: f[i]表示以nums[i]结尾的最长连续子串的最大和。
因此我们只需要求出每个位置的 f(i),然后返回 f 数组中的最大值即可。
那么我们如何求 f(i) 呢?我们可以考虑nums[i] 单独成为一段还是加入 f(i-1) 对应的那一段,这取决于 nums[i] 和 f(i−1) + nums[i] 的大小,我们希望获得一个比较大的,于是可以写出这样的动态规划转移方程:f[i] = max(f[i - 1] + nums[i], nums[i]);
3.代码实现
class Solution {
public:
int maxSubArray(vector& nums) {
int n = nums.size(), res = nums[0];
vector f(n);
f[0] = nums[0];
for (int i = 1; i < n; i ++ ) {
f[i] = max(f[i - 1] + nums[i], nums[i]);
res = max(res, f[i]);
}
return res;
}
};
十、剑指 Offer 43. 1~n 整数中 1 出现的次数
1. 题目描述

2. 思路分析
将 1 ~ n n n 的个位、十位、百位、…的 1 出现次数相加,即为 1 出现的总次数。
设数字 n n n 是个 x x x 位数,记 n n n 的第 i i i 位为 n i n_i ni,则可将 n n n写为 n x n_x nx n x − 1 n_{x - 1} nx−1 … n 2 n_2 n2 n 1 n_1 n1:
- 称“ n i n_i ni”为当前位,记为 n u m b e r [ i ] number[i] number[i] ;
- 将“ n i − 1 n_{i - 1} ni−1 n i − 2 n_{i - 2} ni−2… n 2 n_2 n2 n 1 n_1 n1”称为低位,记为 l o w low low;
- 将“ n x n_{x} nx n x − 1 n_{x - 1} nx−1… n i + 2 n_{i + 2} ni+2 n i + 1 n_{i + 1} ni+1”称为高位,记为 h i g h high high;
- 将 1 0 i 10^i 10i称为位因子,记为 t t t;
某位中 1 出现次数的计算方法:
根据当前位 c u r cur cur 值的不同,分为以下三种情况:
- 当
cur = 0时: 此位 1 的出现次数只由高位high决定,计算公式为:
high * t; - 当
cur = 1时: 此位 1 的出现次数由高位high和低位low决定,计算公式为:
high * t + low + 1; - 当
cur = 2, 3, ⋯,9时: 此位 1 的出现次数只由高位 highhigh 决定,计算公式为:
high * t + t;
3. 代码实现
class Solution {
public:
int countDigitOne(int n) {
if (!n) return 0;
vector number;
while (n) number.push_back(n % 10), n /= 10;
long long res = 0;
for (int i = number.size() - 1; i >= 0; i -- ) {
int high = 0, low = 0, t = 1;
for (int j = number.size() - 1; j > i; j -- ) high = high * 10 + number[j];
for (int j = i - 1; j >= 0; j -- ) low = low * 10 + number[j], t *= 10;
if (number[i] == 0) res += high * t;
else if (number[i] == 1) res += high * t + low + 1;
else if (number[i] > 1) res += high * t + t;
}
return res;
}
};
创作不易,如果有帮助到你,请给文章点个赞和收藏,让更多的人看到!!!
关注博主不迷路,内容持续更新中。