【语音】论文阅读笔记 Non-autoregressive Error Correction for CTC-based ASR with Phone-conditioned Masked LM
目录
- 摘要
- 介绍
- 预备和相关工作
-
- 1. CTC-based ASR
- 2. Masked LM
- 3. ASR error correction
- 提出的方法
-
- 1. Phone-conditioned Masked LM (PC-MLM)
- 2. Error Correction with PC-MLM
- 3. Deletable PC-MLM
- 实验评估
-
- 1. 实验配置
- 2. 实验结果
- 总结
论文地址: here
摘要
在语音识别中,CTC模型因为天然的non-autoregressive特性,深受广大研究者的青睐。为了充分利用大量的文本数据优势,CTC模型通常会和LM模型进行融合,常用的融合方法包括重打分和浅融合。然而这两种融合方法由于beam search的引入,破坏了CTC模型的non-autoregressive特性,因此造成了语音识别模型推理速度的下降。
作者提出了PC-MLM(phone-conditioned Masked LM)错误校验方法。只需要对CTC的贪婪解码算法中置信度较低的Token进行mask,然后使用PC-MLM对mask的token进行预测即可。PC-MLM模型的输入为CTC模型的phone预测序列和masked token序列。另外,作者进一步将PC-MLM扩展为Deletable PC-MLM,有效缓解了插入错误。因为CTC和PC-MLM都是non-autoregressive的,作者提出的方法实现了CTC模型和LM模型的快速融合。实验结果显示,在CSJ和TED-LIUM2上,作者提出的方法推理速度更快,并且在CSJ上取得了更高的语音识别准确率。
介绍
常见的端到端语音识别方法包括基于CTC的模型、基于Attention的序列模型和RNN-T模型。其中基于CTC的模型可以同时并行预测所有token,也称之为非自回归预测。相反,基于Attention和RNN-T的模型都需要一个token一个token的预测,也称之为回归预测。
端到端语音识别模型的训练需要成对的语音-文本 数据。然而,在某个目标领域很难获取到大量的这种成对数据。但是,另一方面目标领域可能有很多领域内的文本数据。一种普遍的做法是将语音识别模型和外部LM融合,从而可以利用这些大量的文本数据。重打分融合方法,使用LM对语音识别的n-best预测结果进行重打分,得分最高的预测结果作为最终的预测结果。浅融合方法,在语音识别的每一步解码过程中将LM模型和ASR模型进行插值得分计算。这两种融合方法简单有效,因此被广泛应用于基于CTC的语音识别模型中。然而它们破坏了推理的高效性,这种高效性是CTC模型相比其它的端到端语音识别模型的一个非常重要优势。具体地说,使用beam-search寻找n-best预测结果破坏了它的非自回归特性。
除了重打分和前融合方法,还有基于KD(知识蒸馏)的LM融合方法,主要应用于基于attention的模型。LM模型的知识(教师模型)在ASR模型训练过程中教给了ASR模型(student)。尽管KD融合方法的优势在于,在预测时没有增加任何额外步骤,但这种方法获取的收益有限,可能是因为LM不能直接作用于ASR模型的推理。
在本论文中,作者提出了ASR错误校验方法,一个MLM(masked LM)负责对CTC预测序列中低置信度的token进行纠正。这种方法不需要beam-search,就能把所有低置信度的token并行进行纠正。也就是ASR和纠错过程都是非自回归的。然而MLM的效果并不是很好,可能是因为它没有考虑声学信息。为了解决这个问题,作者提出了Phone-based Masked LM(PC-MLM),将音素信息也加入进来。在CTC模型训练中引入了多任务训练,基于encoder的中间层预测音素。PC-MLM可以同时利用单词和音素信息进行纠错。同时为了减少插入错误,作者提出了Deletable PC-MLM,该方法可以对插入错误进行预测并删除。
预备和相关工作
1. CTC-based ASR
X = ( x , . . . , x t , . . . x T ) X = (x, ..., x_t, ... x_T) X=(x,...,xt,...xT)表示输入的声学特征; y = ( y 1 , . . . , y i , . . . , y L ) y=(y_1, ..., y_i, ..., y_L) y=(y1,...,yi,...,yL)表示输入 X X X对应的文本序列。CTC的encoder网络将输入 X X X编码为高层表示,长度为 T ′ {T}' T′。基于CTC的模型可以根据encoder编码预测帧级别的输出路径 π = ( π 1 , . . , π T ′ ) \pi =(\pi_1,..,\pi_{{T}'}) π=(π1,..,πT′)。 ν \nu ν表示单词集合, ϕ \phi ϕ表示blank。在 t t t时刻CTC输出字符 v v v的预测概率可以用以下公式表示:
P C T C ( t , v ) = p ( v ∣ X , t ) P_{CTC}^{(t,v)}=p(v|X, t) PCTC(t,v)=p(v∣X,t)
其中 v ∈ ν ∪ { ϕ } v\in \nu \cup \left \{ \phi \right \} v∈ν∪{ϕ}。在贪婪 解码中,CTC路径 π \pi π可以通过下面的公式计算:
π t = a r g m a x v P C T C ( t , v ) \pi_t=\underset{v}{argmax}P_{CTC}^{(t,v)} πt=vargmaxPCTC(t,v)
在使用beam search进行解码的时候, π t \pi_t πt依赖于前面的解码结果 π t < t = ( π 1 , . . . , π t − 1 ) \pi_{t
CTC的loss定义在所有能规约为 y y y的可能路径上:
L c t c = − l o g ( y ∣ X ) = − ∑ π ∈ B − 1 ( y ) l o g p ( π ∣ X ) \mathcal{L}_{ctc}=-log(y|X) = - \underset{{\pi\in\mathcal{B}^{-1}(y)}}{\sum}log\ p(\pi|X) Lctc=−log(y∣X)=−π∈B−1(y)∑log p(π∣X)
2. Masked LM
Masked LM最初由BERT作为预训练任务设计出来,其在众多的NLP下游任务上展示了卓越的性能。在MLM训练时,一些输入token(通常15%)被遮蔽掉,模型会对相应的原始token进行预测。MLM根据左右未遮蔽的token并行/非自回归地预测所有被遮蔽的token。定义预测第 i i i个token为 v ∈ V v\in\mathcal{V} v∈V的概率为: P M L M ( i , v ) = p ( v ∣ y ( m a s k ) , i ) P_{MLM}^{(i,v)}=p(v|y^{(mask)},i) PMLM(i,v)=p(v∣y(mask),i)其中 y ( m a s k ) y^{(mask)} y(mask)的第 i i i个token被遮蔽。通常地,RNN或者Transformer LM通过重打分和浅融合的方式被应用于ASR任务中。它们在给定左侧上下文时可以自回归地预测下一个token。最近,MLM通过重打分或知识蒸馏的方法被应用于ASR中。实验研究表明,MLM相比传统LM表现地更好,因为它使用了双向上下文信息。然而,在测试时使用MLM进行重打分会耗费很多时间,因为在对一个长度为 L L L的待打分预测序列重打分时需要遮蔽每一个token,共需要 L L L步。在使用MLM进行知识蒸馏训练时,最小化下面基于 KL散度的目标函数:
L = − ∑ i = 1 L ∑ v ∈ V P M L M ( i , v ) l o g P A t t ( i , v ) \mathcal{L}=-\sum_{i=1}^{L}\sum_{v\in\mathcal{V}}P_{MLM}^{(i,v)}log\ P_{Att}^{(i,v)} L=−i=1∑Lv∈V∑PMLM(i,v)log PAtt(i,v) 其中 P A t t ( i , v ) P_{Att}^{(i,v)} PAtt(i,v)表示基于attention的ASR模型预测第 i i i个token为 v v v的概率。在前人的研究工作中,学生模型被限定为基于attention的模型,可以输出像MLM一样token级别的预测。
作为MLM的扩展,conditional MLM(CMLM)在非自回归神经网络机器翻译中被提出来。CMLM是一个encoder-decoder结构,基于源文本和非遮蔽的翻译文本可以预测所有被遮蔽的token。在ASR领域,Audio-CMLM模型和mask CTC模型在非自回归ASR系统中采用了CMLM架构。在mask CTC中,和作者提出的方法类似,CTC输出中低置信度的token使用CMLM被纠正。然而它是基于声学特征的,并且基于audio-text成对数据和CTC模型一起训练。作者提出的PC-MLM是基于音素token的,并且和CTC模型的训练是分开的,只基于文本数据就可以训练。
3. ASR error correction
ASR错误纠正的目标是使用一个更高层的模型对ASR模型产生的错误进行纠正。最近一些研究,类似神经网络机器翻译,采用自回归序列-序列模型进行建模将ASR的预测序列转换为正确的。这些模型的训练通常基于成对的ASR预测序列和对应的正确文本。然而,这些成对的数据由有限的成对的语音和文本数据生成,因此可能会使纠错模型过拟合。一些研究会通过预训练LM模型进行初始化,从而可以利用text-only数据。预训练模型包括BERT、BART等。在文献22中,将TTS合成语音的识别结果作为伪ASR预测序列。在文献25中,使用基于n-gram混淆矩阵产生文本级别的模拟错误。在文献25中,将一个音素级别的编码器添加到序列-序列模型中,从而引入音素信息。更近的工作中,文献29提出了一个基于编辑距离的非自回归纠错模型。在文本中,phone-condition MLM作为纠错模型。它的训练不需要成对的数据只需要文本数据并且实现了非自回归和音素感知级别的纠错。
提出的方法
1. Phone-conditioned Masked LM (PC-MLM)
PC-MLM是一个音素到词转换的模型,它由基于transformer的CMLM(文献19)组成。PC-MLM模型接收音素序列 p p p输入到编码器,接收词序 y ( m a s k ) y^{(mask)} y(mask)输入到解码器,可以预测遮蔽位置的词token。假设 y ( m a s k ) y^{(mask)} y(mask)的第 i i i个token被遮蔽,则第 i i i个token被预测为 v ∈ V v\in\mathcal{V} v∈V的概率为:
P P C − M L M ( i , v ) = p ( v ∣ p , y ( m a s k ) , i ) P_{PC-MLM}^{(i,v)}=p(v|p, y^{(mask)}, i) PPC−MLM(i,v)=p(v∣p,y(mask),i)
音素信息可以通过词序列和词典自动获取,因此PC-MLM可以像LM模型一样只用文本数据进行训练。为了防止过你和,一些音素token在训练时会被随机遮蔽(20%),这个也被称之为“文本增强”(文献31)。
2. Error Correction with PC-MLM
在这个研究中,PC-MLM作为一个纠错模型对基于CTC的ASR预测序列进行纠正。本文提出的方法在图一中做了一个形象的展示。置信度分值用于决策哪些预测的token将会被遮蔽掉和纠正。首先,为了获取token级别的置信度分值,需要对帧级别的CTC预测进行规整: A ( i ) = a r g m a x t P C T C ( t , y i ) s . t . π t = y i \mathcal{A}(i)=\underset{t}{argmax}P_{CTC}^{(t,y_i)}\ s.t.\pi_{t}=y_{i} A(i)=targmaxPCTC(t,yi) s.t.πt=yi P C T C ′ ( i , . ) = P C T C ( A ( i ) , . ) P_{CTC}^{'(i,.)}=P_{CTC}^{(\mathcal{A}(i),.)} PCTC′(i,.)=PCTC(A(i),.),其中从 i i i到 t t t的索引映射函数 A \mathcal{A} A从贪婪CTC路径 π \pi π中获取。然后,CTC的输出 y y y的部分token被遮蔽,遮蔽基于置信度得分进行操作: y i ( m a s k ) = { [ m a s k ] P C T C ′ ( i , y i ) < β y i P C T C ′ ( i , y i ) ≥ β y_{i}^{(mask)}=\left\{\begin{matrix} [mask] & {P}_{CTC}^{'(i,y_i)}<\beta\\ y_i & {P}_{CTC}^{'(i,y_i)}\geq \beta \end{matrix}\right. yi(mask)={[mask]yiPCTC′(i,yi)<βPCTC′(i,yi)≥β
出了词级别的 y ( m a s k ) y^{(mask)} y(mask),作者提出了在PC-MLM的错误纠正中,使用音素级别的上下文 p p p。通过层级多任务学习框架获取音素级别的预测,具体来讲在编码层的中间层添加音素级别的辅助目标。这种方法同时提升了基于最后一层的词级别ASR模型效果。
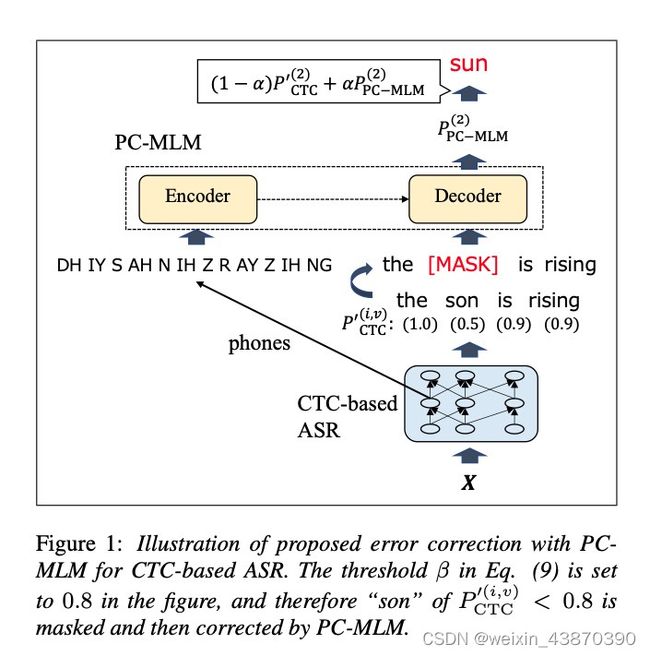
PC-MLM在给定 y m a s k y^{mask} ymask和 p p p时,可以输出 P P C − M L M ( i , v ) P_{PC-MLM}^{(i,v)} PPC−MLM(i,v)。最终,为了得到纠错后的预测 y c o r r e c t y^{correct} ycorrect,可以直接使用PC-MLM输出的概率进行纠正。作者同时也提出抗议使用CTC和PC-MLM差值计算 y c o r r e c t y^{correct} ycorrect:
y i c o r r e c t = a r g m a x v ( ( 1 − α ) P C T C ′ ( i , y i ) + α P P C − M L M ( i , v ) ) y_{i}^{correct}=\underset{v}{argmax}((1-\alpha){P}_{CTC}^{'(i,y_i)}+\alpha P_{PC-MLM}^{(i,v)}) yicorrect=vargmax((1−α)PCTC′(i,yi)+αPPC−MLM(i,v))
本文提出的方法相比现有的LM融合CTC的方法,例如重打分和浅融合,具有推理迅速的优势。这个方法只需要1-best预测,然而重打分和浅融合在解码时/后需要n-best预测。对于CTC,1-best预测可以通过非自回归产生,然而n-best需要通过自回归方式产生,这对推理的速度将会产生重要影响。在获取预测序列之后,PC-MLM通过非自回归的方式纠正token,这非常快。作者提出的方法同样可以应用于attention和transducer模型的解码输出。更进一步,这种方法除了结合CTC模型,同样可以将LM应用于非自回归模型比如A-CMLM、LASO、Insertion Transformer等,这些模型因为没有beam search所以很难和LM进行融合。
3. Deletable PC-MLM
训练PC-MLM使用相同数量的token替换遮蔽token,这样只能处理基于CTC的ASR模型的替换错误。作者进一步提出了Deletable PC-MLM去解决插入错误。Deletable PC-MLM为插入错误预测空token ( ϕ ) (\phi) (ϕ),然后通过删除空token得到纠正过的预测结果 y ( c o r r e c t ) y^{(correct)} y(correct)。在训练期间,一些输入token被随机遮蔽(15%),一些遮蔽token [MASK]被随机插入到他们之间。插入遮蔽token的数量从泊松分布( λ \lambda λ=0.2)中采样得到。在遮蔽和插入之后,Deletable PC-MLM被训练去预测原始token或者空token。
实验评估
1. 实验配置
- 训练语料:CSJ 、 TED-LIUM2
CSJ: CSJ-APS 240h 学术报告语音 + CSJ-SPS 280h 即时公开演讲
TED-LIUM2: TED上的英文演讲 - 评估语料:交叉评估,作者假设目标领域只有文本
例如:CSJ-SPS训练,CSJ-APS评估,LM在CSJ-APS文本上训练
Librispeech960朗读语料训练,TED-LIUM2评估,LM在TED-LIUM2文本上训练 - CTC-based ASR:
Transformer Encoder: L=12, H=256, A=4
Linear Layer
Conformer Encoder[38]: 大小一样 - 学习率
Adam optimizer, Noam learning schedule, warmup_n: 25000, k = 5 - 数据增强
SpecAugment - LM
– TransformerLM: L=12, H=256, A=4
– MLM : L=12, H=256, A=4
– PC-MLM : L=4, H=256, A=4
– Deletable PC-MLM : L=12, H=256, A=4 - token: BPE
CSJ: 10872
TED-LIUM2:9798 - 发音词典
CSJ:g2p tool, 45 entries
TED-LIUM1: 官方提供,44 entires
2. 实验结果
- 实验结果一
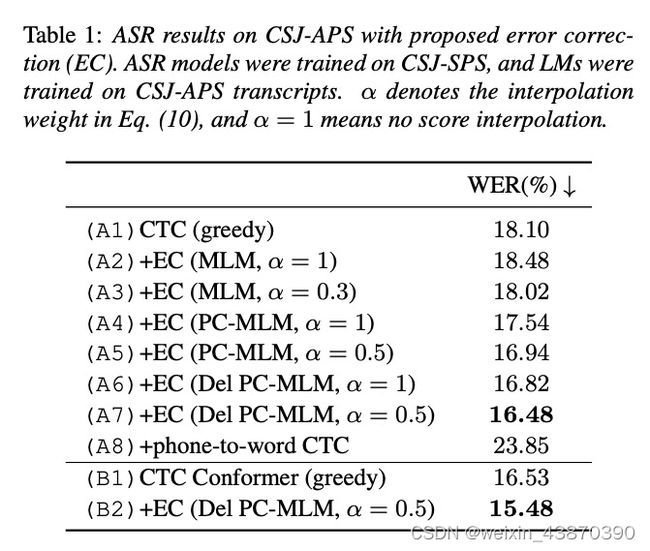
- A1是使用层级多任务训练的,不使用层级多任务训练的WER是18.44%,所以层级多任务训练对ASR任务有帮助;层级多任务训练的phone error rate是9.1%;
- 可以看到当 α \alpha α不等于时效果更好,说明使用差值效果好,也就是加上CTC的分数; α \alpha α的大小是在验证集上确定的;
- MLM效果不好,甚至比greedy还要差;PC-MLM效果明显;Del PC-MLM效果进一步提升;Del PC-MLM可以减少替换、删除错误,但是插入错误变多;phone-to-wordCTC效果不好,可能是因为错误传播;可以看到作者的方法提升明显;
- 实验结果二

- 上表格中提交了作者的方法和其它的LM融合方法。表格中的RTF是在单卡 NVIDIA TITAN V GPU上设置batch为1,并且对五轮结果平均得到的。PC-MLM和MLM比增加了RTF,因为使用了音素token;作者提出的方法比重打分和浅融合快,因为这两个需要beam search;beam search很难进行并行,但是作者的重打分中的transformer推理部分可以并行GPU推理;
- 作者把他们的方法和KD进行了比较。D1和A1比可以看到,推理时间没有增加,但是效果增加有限。在结合Del PC-MLM效果提升明显;
- 实验结果三

- 上表展示了在TED-LIUM2上的效果。可以看到,作者的方法提升了ASR,并且保持了较快的推理速度,和CSJ的表现一致;但是对于WER,作者的方法提升不如重打分和浅融合方法。结合音素信息对WER的提升并不明显。这可能是因为英语是音意文字,日语是表意文字,因此在英语中音素信息和词信息关联更大。这表明,词级别的错误和音素级别的错误可能在同一个位置发生,因此音素信息对词级别纠正帮助不大。另一方面,音素级别的信息对日语词具有互补作用。
总结
作者为基于CTC的ASR模型提出了一个LM融合的方法,也就是通过PC-MLM进行错误纠正。PC-MLM可以利用音素信息对CTC低置信度的token进行纠正。作者展示了他们提出的方法比传统的LM融合方法更加快速,比如重打分和浅融合算法。传统的LM融合方法需要有多个自回归生成的预测序列,然后坐着的方法只需要一个非自回归的贪婪解码的预测序列。另外,PC-MLM本身也是以非自回归的方式进行错误纠正。在CSJ上,作者展示了他们的方法相比重打分、浅融合和知识蒸馏表现地更好。将来,他们会继续探索修复删除错误并进一步优化PC-MLM,同时保持快速地推理。