机器学习+模式识别学习总结(三)——逻辑回归
出于对逻辑回归提出背景的好奇,特地去了解了一下:逻辑回归里的“Logistic”函数是数学家维尔赫斯特在研究人口数量增长问题的过程中提出来的,人口预测问题所使用的logistic模型可以用来描述包括人类在内几乎所有物种在资源约束下的增长规律,当然很多社会、经济现象都可以借助于来解释。而至于为什么取名为“Logistic”,维尔赫斯特没有说明缘由,据后人猜测是效仿Arithmetic(算术), Geometric(几何)这两个单词,同时也是为了和 Logarithmic(对数的)做对比,当然后来还是经过了一系列的发展,才广为认知。逻辑回归中的“Logit”模型是伯克森提出来的。归根结底还是源于数学问题。(详情可戳 https://zhuanlan.zhihu.com/p/146206709 )
一、关于逻辑回归定义的两种理解
本人一直对逻辑回归的定义很不解,比如为什么在讲解逻辑回归之前突然就要介绍“Logistic”函数?为什么可以用来分类呢,有什么理论支撑吗?...诸如此类的疑问。我翻了统计机器学习和西瓜书,结合上网搜索其他网友们的解释。总结了一下,我个人比较信服以下两种解释:
(1)基于线性回归的“传承”:通过在线性回归模型中引入Sigmoid函数,这样线性回归输出值就可以映射到(0,1)范围内,将线性回归模型的预测值与真实标记联系起来。
(2)基于贝叶斯的“变形”:我们知道在已知样本特征x时,可以通过贝叶斯公式得出其类别。对贝叶斯公式进行变形便可以得到Logistic函数。
二、损失函数
1、公式引入及推导
几率:事情发生的概率与不发生的概率的比值,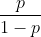 (令
(令 为事件发生的概率)。
为事件发生的概率)。
对数几率:几率的对数函数,
![]() ,
,![]()
对数几率函数:是Sigmoid函数,通过此函数来输出类别概率,
![]() ,
,![]()
(1)基于“构造”损失函数的推导
令代表样本被视为正样本的概率,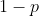 代表被视为负样本的可能性,最终预测的类别取概率值大的类别,那么就存在如下两种情况:
代表被视为负样本的可能性,最终预测的类别取概率值大的类别,那么就存在如下两种情况:
①若真实类别y=1,则当估计出来的概率p越小时,则预测错误,损失函数越大:![]()
②若真实类别y=0,则当估计出来的概率p越大(1-p越小)时,损失函数越大:![]()
通过设置控制系数 ,再取对数的方式将上述两个情况合并成一个:
,再取对数的方式将上述两个情况合并成一个:
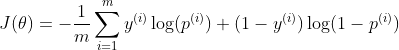 ,
,![]()
(2)基于最大似然估计的推导
由似然函数公式:
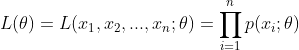 ,可得:
,可得:
 ,两边取对数可得:
,两边取对数可得:
 ,
,
由于逻辑回归是监督学习,是有训练标签的,就是有已知结果的,从已知结果入手去推导能获得最大概率的结果参数,只要我们得出了这个参数,那我们的模型就自然可以很准确的预测未知的数据了,因此我们希望这个似然函数的值越大越好,也就是说对于给定样本数量m,希望![]() 越小越好,于是得到损失函数:
越小越好,于是得到损失函数:
可见,逻辑回归的损失函数和似然函数存在很大关联,也可以说逻辑回归的损失函数不是凭空“构造”出来的,而是根据最大似然估计推导出来的。(参考:https://zhuanlan.zhihu.com/p/103459570?ivk_sa=1024320u)
三、参数估计
1、通过极大化似然函数方法,运用梯度下降来求解参数。可能有人问既然逻辑回归时采用极大似然估计求解参数,为什么不能令导数为0来求解该最优化问题呢?因为对于逻辑回归而言,用这个令导数为0的方式会面临诸多问题,比如很难写出求导后的参数的表达式等,因此采用梯度下降法,通过不断迭代的方式来求解函数的最优解。(参考解释:https://zhuanlan.zhihu.com/p/364338184)
2、感知机、线性回归、逻辑回归的参数估计/求解方法总结:
感知机:随机梯度下降
线性回归:梯度下降/正规方程
逻辑回归:极大似然估计参数,梯度下降求解参数
四、逻辑回归和线性回归的区别和联系:
1、逻辑回归用于分类,线性回归用于回归。
2、逻辑回归用最大似然估计参数,线性回归用最小二乘法。
3、线性回归求参数时可以对损失函数(最小二乘那个表达式,偏差的平方和)的参数 偏导令为0求解,而逻辑回归得用迭代求解。
偏导令为0求解,而逻辑回归得用迭代求解。
4、逻辑回归分析因变量取某个值的概率与自变量的关系,线性回归直接分析因变量与自变量的关系。
5、逻辑回归因变量离散,线性回归因变量连续。
五、逻辑回归与支持向量机的异同:
(一)同:
1、都是分类算法。
2、若不考虑支持向量机的核函数,两者都是分类算法,即他们的决策面都是线性的。对于逻辑回归而言,(2)式子值为0.5是,两类概率相等,此时决策面 ,为线性决策面(线性:关于参数是线性的)。所以逻辑回归是线性模型,因为决策边界是线性的。(判断一个模型是否是线性,是通过分界面是否是线性来判断的。)(参考:https://blog.csdn.net/zxyhhjs2017/article/details/78842528)
,为线性决策面(线性:关于参数是线性的)。所以逻辑回归是线性模型,因为决策边界是线性的。(判断一个模型是否是线性,是通过分界面是否是线性来判断的。)(参考:https://blog.csdn.net/zxyhhjs2017/article/details/78842528)
(二)异:
1、损失函数不同。逻辑回归基于概率理论,通过极大似然估计求参数的值,支持向量机基于几何间隔最大理论原则,认为存在最大几何间隔的分类为最优分类。
2、支持向量机只考虑局部边界线附近的点,逻辑回归考虑全局。(支持向量机不直接依赖数据的分布,分类平面不受一类点的影响,逻辑回归受所有数据点的影响。)
3、支持向量机依赖数据表达的距离测度,数值的大小对结果有影响,所以要做归一化,逻辑回归不依赖数据的数值大小,因为其依赖概率。
4、支持向量机自带正则化项,这也是其结构风险(经验风险后加一个正则项便是结构风险)最小化的原因,逻辑回归需要在损失函数后面加上正则项。
5、解决数据的非线性问题时,支持向量机引入核函数,逻辑回归不采用核函数,因为逻辑回归训练模型的过程就是计算决策面的过程。