小白入门谱聚类算法原理与实现
小白入门谱聚类算法原理与实现
-
- 小白入门谱聚类算法原理与实现
- 1. 谱聚类是什么?
- 2.谱聚类步骤
-
- 2.1 谱聚类构图
- 2.2 谱聚类切图
-
- 2.2.1RatioCut
- 2.2.2Ncut
- 3谱聚类实现
小白入门谱聚类算法原理与实现
文章结构主要分为下面三个部分
①谱聚类是什么
②谱聚类怎么进行聚类
③谱聚类应用例子
1. 谱聚类是什么?
首先回顾一下聚类的概念:
-
聚类:对大量未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大而类别间的数据相似度较小
-
谱聚类:是一种基于图论的聚类方法,通过对样本数据的拉普拉斯矩阵的特征向量进行聚类,从而达到对样本数据聚类的目的。
直观的解释就是将聚类问题转化为一个无向图的多路划分问题,数据点看成无向图G(V,E)中的顶点V,加权边的集合E={Sij}表示基于某一点相似性度量的两点间的相似度,用S表示待聚类数据点之间的相似性矩阵,图G中把聚类问题转变为在图G上的图划分问题,即将图G(V,E)划分为K个互不相交的子集V1,V2,...Vk,划分后每个子集Vi和Vj之间的相似程度较低,每个子集内部相似度较高。
所以谱聚类的思想就是要转化为图分割的问题,因此下面从图的概念进行引入。
简单回顾一下图的基本概念

上图是一个无向图,且边上带有权重,所以是一个带权重的无向图G(V,E),V就是上图中的顶点,E就是点与点之间的边,由于无向图,可得点Vi和点Vj的权重关系为:Wij = Wji。
另外,度矩阵:根据每个顶点度的定义,得到一个对角矩阵D(6X6),在这里可得度矩阵D如下

邻接矩阵:任意两点之间的权重值Wij组成的矩阵。此时,Wij = Wji
在这里定义邻接矩阵W如下

拉普拉斯矩阵的定义很简单:L = D - W ,从前面可得,D是度矩阵、W是邻接矩阵。不过拉普拉斯有一些性质我们需要了解一下:
1.拉普拉斯是对称矩阵,(D和W也是对称矩阵)
2.由于拉普拉斯矩阵是对称矩阵,则它的所有特征值都是实数。
3.对于任意的向量f,都有
 4.拉普拉斯矩阵是半正定的,且对应的n个实数特征值都大于等于0,且最小的特征值是0。
4.拉普拉斯矩阵是半正定的,且对应的n个实数特征值都大于等于0,且最小的特征值是0。
2.谱聚类步骤
有了图的概念之后,下面进入谱聚类的步骤。
下面以简单的6个样本为例,如下图所示
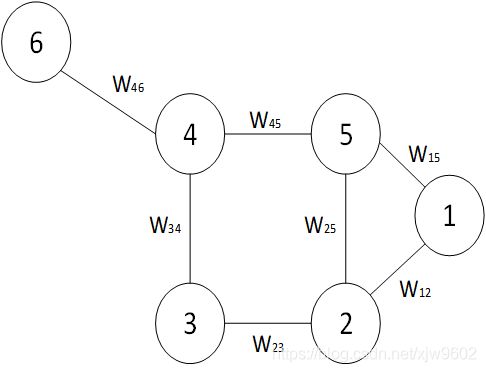
现在有6个样本(6个顶点),需要对这些样本进行聚类的话,我们应该怎么进行聚类呢?哪些样本应该聚在一起呢?哪些样本聚在一起的结果是最合理的呢?
2.1 谱聚类构图
首先,当我们拿到样本之后,我们必须思考的是怎么把顶点连接起来呢?
在谱聚类构图中,一般有三种构图方式:
1.ε-neighborhood
2. k-nearest neighborhood
3. fully connected
前两种可以构造出系数矩阵,适合大样本的项目,第三种则相反,在大样本中其迭代速度会受到影响制约。
ε -neighborhood 方法一般使用欧式距离:
 来构造矩阵S,称为相似矩阵。而邻接矩阵也就是Sij ≤ ε的顶点之间的Sij值,则邻接矩阵W:
来构造矩阵S,称为相似矩阵。而邻接矩阵也就是Sij ≤ ε的顶点之间的Sij值,则邻接矩阵W:
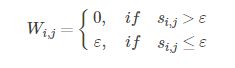 可以看出,样本之间的权重没有包含更多的信息了,所以一般不采用这种方法。
可以看出,样本之间的权重没有包含更多的信息了,所以一般不采用这种方法。
k-nearest neighborhood方法是利用KNN算法,但是这种方法会造成重构之后的邻接矩阵W非对称,所以一般采用两种方法之一:
- 只要点xi在xj的K个近邻中或者xj在xi的K个近邻中,则保留si,j,并对其做进一步处理W,此时 为:

- 是必须满足点 在 的K个近邻中且 在 的K个近邻中,才会保留si,j并做进一步变换,此时W为:

fully connected是第三种方法,一般使用的是高斯距离公式计算:

重构后的矩阵W与相似矩阵相同,即:Wi,j=Si,j。一般来说,第一第二种构图方式是基于欧式距离,而第三种构图方式是基于高斯距离,我们可以看到高斯距离计算中,对于∥xi−xj∥^2比较大的样本点,其得到的高斯距离反而值是比较小的,而这也正是S可以直接作为W的原因,主要是为了将距离近的点的边赋予高权重。
此时,得到邻接矩阵W后,需要计算度矩阵D:
 其中Wij为邻接矩阵W元素,在这里度矩阵每个顶点的值为该顶点所连接其他顶点的边的权重之和,可以知道,D为对角矩阵。
其中Wij为邻接矩阵W元素,在这里度矩阵每个顶点的值为该顶点所连接其他顶点的边的权重之和,可以知道,D为对角矩阵。
因此计算拉普拉斯矩阵L:L= D - W,到这里构图步骤完成,然后我们需要对构成的图进行子图划分。
2.2 谱聚类切图
谱聚类切图存在两种主流的方式:RatioCut和Ncut,下面对于切图步骤进行讲解。
对于无向图G的切图,目的是切成相互没有连接的k个子图,每个子图的集合是A1,A2,…,Ak,子图间没有交集且各子图之和为所有顶点。那么对于子集与子集之间连边的权重和为:
 公式的意思是对于每个点Ai,求得Ai与其他所有子集的连边(权重)的和,该和越小,说明子图与子图之间的联系越小,所以我们的目标函数表述为:
公式的意思是对于每个点Ai,求得Ai与其他所有子集的连边(权重)的和,该和越小,说明子图与子图之间的联系越小,所以我们的目标函数表述为:
![]() 看起来似乎可行,但是这种切图方式存在问题,
看起来似乎可行,但是这种切图方式存在问题,

如上图所示,用这种方法且会造成将V切成很多歌单点离散的图,显然这样是最快且最能满足最小化操作的,但是明显不是想要的结果,所以下面引出了RatioCut和Ncut两种优化的切图方式。
2.2.1RatioCut
Ratio切图考虑了子图的大小,避免了单个样本点作为一个簇的情况发生,平衡了各子图的大小,即
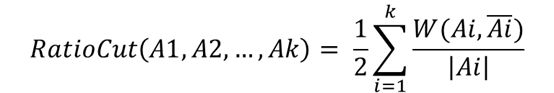
其中|Ai|是Ai子集中顶点的个数,对上述极小化问题做一下转化,引入{A1,A2,…,Ak}的指示向量,hj={h1,h2,⋯,hi,⋯,hk},j=1,2,⋯,k. 其中i表示样本下标,j表示子集下标, 表示样本i对子集j的指示,具体为: 可以理解为,每个子集Aj对应一个指示向量hj,而每个hj里有N个元素,分别代表N个样本点的指示结果,如果在原始数据中第i个样本被分割到子集Aj里,则hj的第i个元素为1除以第j个子集样本个数再开根号,否则为0。
可以理解为,每个子集Aj对应一个指示向量hj,而每个hj里有N个元素,分别代表N个样本点的指示结果,如果在原始数据中第i个样本被分割到子集Aj里,则hj的第i个元素为1除以第j个子集样本个数再开根号,否则为0。
然后经过转化(此处数学推导)把求解目标转化为:
![]() 对于上式中,由于L矩阵是容易得到的,所以目标是求满足条件的H矩阵。要求条件下的H,首先需要得到组成H的每个指示向量hi,而每个hi是Nx1的向量,但找到满足上面优化目标的H是一个NP难的问题。这时候,根据论文(A short theory of the Rayleigh-Ritz method)推导,我们求解这个优化目标H只需要求得L矩阵的K个最小特征值对应的特征向量即可组成目标H。
对于上式中,由于L矩阵是容易得到的,所以目标是求满足条件的H矩阵。要求条件下的H,首先需要得到组成H的每个指示向量hi,而每个hi是Nx1的向量,但找到满足上面优化目标的H是一个NP难的问题。这时候,根据论文(A short theory of the Rayleigh-Ritz method)推导,我们求解这个优化目标H只需要求得L矩阵的K个最小特征值对应的特征向量即可组成目标H。
这时候H矩阵也求得,接下来就是对样本进行聚类,我们将H中每一行作为输入进行kmeans聚类,最后输出各个簇类。
2.2.2Ncut
Ncut切图方式和RatioCut切图非常相似,但Ncut的分母是vol(Ai),由于子图样本的个数多,并不一定权重就大,我们切图时基于权重更符合我们的目标,因此一般来说采用Ncut方式比较多。
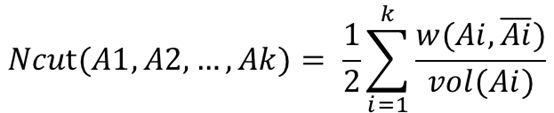
下面先引入{A1,A2,…,Ak}的指示变量hj={h1,h2,⋯,hi,⋯,hk},j=1,2,⋯,k,同样,其中i表示样本下标,j表示子集下标,hj,i表示样本i对子集j的指示,不同的是,其具体为:

如果在原始数据中第i个样本被分割到子集Aj里,则hj的第i个元素为1/Ai子集中每个顶点权重之和开根,否则为0。
然后经过转化(此处数学推导)把求解目标转化为:
![]() 同理,F矩阵的求解可通过求D−1/2LD−1/2的前K个特征向量组成,最后对F的行进行kmeans聚类。
同理,F矩阵的求解可通过求D−1/2LD−1/2的前K个特征向量组成,最后对F的行进行kmeans聚类。
总体流程而言,谱聚类算法的步骤如下:
3谱聚类实现
本次代码实现使用的是Python,谱聚类方法是调用sklearn机器学习函数库,数据样本为:
#数据集
datasets.make_circles(n_samples, factor=0.5, noise=0.05)
#调用模型
model = SpectralClustering(n_clusters=2, gamma)
最终实现结果为:

聚类如上图所示,左边为谱聚类,右边是Kmeans聚类,显然谱聚类效果更好。
从理解而言,整体来说,谱聚类算法要做的就是先求出相似性矩阵,然后对该矩阵归一化运算,之后求前个特征向量,最后运用K-means算法分类。 实际上,谱聚类要做的事情其实就是将高维度的数据,以特征向量的形式简洁表达,属于一种降维的过程。本来高维度用k-means不好分的点,在经过线性变换以及降维之后,十分容易求解。
- 谱聚类优点:
①对数据结构并没有太多的假设要求,如kmeans则要求数据为凸集。
②可以构造稀疏similarity graph,使得对于更大的数据集相对来说也能有较好的计算速度
③由于谱聚类是对图切割处理,不会像kmesns聚类时将离散的小簇聚合在一起的情况。 - 缺点:
①对于选择不同的构图方式比较敏感
②求解过程主要时间在与矩阵的转换上,同时也需要较大的内存空间
参考资料
【论文】A Short Theory of the Rayleigh–Ritz Method
【博客】https://blog.csdn.net/yc_1993/article/details/52997074
【博客】https://blog.csdn.net/songbinxu/article/details/80838865
【博客】https://blog.csdn.net/pr310762957/article/details/53103709
【博客】https://www.cnblogs.com/pinard/p/6221564.html
【博客】https://www.cnblogs.com/pinard/p/6235920.html