通过引用关系构建药物-症状-疾病三元组挖掘隐含的药物-疾病关系
概述
作者通过对PubMed上2011年初到2015年底收录的有关大肠癌的文章进行文本挖掘,采用了共现和引用两种方式构建了药物-症状-疾病三元组,从而挖掘出可能存在的药物-疾病关系,并通过CTD和KEGG两个医药领域数据库进行验证,分析出两种不同方法挖掘出的隐含关系的特征。
文章使用的医学领域知识库
UMLS
UMLS(Unified Medical Language System)是美国国立医学图书馆(著名的医学文献数据库Medline也是该图书馆负责管理的)维护建设的一套医学术语系统。该系统提供了受控词表(meta thesaurus)、语义网(semantic web)、信息来源图(information sources map)、医学类辞典(specialist lexicon)四种信息组织的形式,其中部分资源(如specialist lexicon)是开放获取的,部分资源需要在网站上申请一个UMLS license,约三个工作日之内会得到答复,是否申请成功,成功后即可下载全部资源,该资源提供了一个使用java开发的检索工具,下载完成后按步骤安装即可。
在文章中,作者使用自己研发PKDE4J的工具对文献当中的实体进行抽取,本次仅抽取疾病、药物、症状三个分类下的实体,并将这些实体和UMLS中的实体进行比对,留下真正存在的实体(因为实体抽取工具的结果不是完全准确)。
KEGG
KEGG(Kyoto Encyclopedia of Genes and Genomes)同样是大型的医学信息数据库,该数据库保存了大量基因层面地生物信息,同样也包括了一些已经经过验证的医学实体间的关系。
在文章中该数据库用于检查那些被发现的药物疾病关系是否是真实存在的
CTD
CTD(Comparative Toxicogenomics Database)数据库中存储了医学领域如基因、环境、化学药物、蛋白质之间的相互作用,其中包含了一些未经验证的的相互作用关系。在网站上可下载相应的实体和链接关系。
文章中将抽取的关系和CTD中的关系进行匹配,匹配结果和KEGG做对比,用于评估基于引用挖掘的药物-疾病关系是否可能存在
PubMed
PubMed 是一个提供生物医学方面的论文搜寻以及摘要,并且免费搜寻的数据库。它的数据库来源为MEDLINE。其核心主题为医学,但亦包括其他与医学相关的领域,像是护理学或者其他健康学科。
本次数据集的获取
论文中作者在PubMed上使用大肠癌作为检索词限制2010年1月-2015年12月,收集到79,811篇文献,这些文献信息经过xml规范化,这部分数据用于共现关系的挖掘工作。79811篇文献的参考文献部分具有PubMed ID,将该部分文献作为扩展文献,共有142734篇文献,这部分文献间的引用关系用来进行基于引用的关系挖掘。
关系抽取的步骤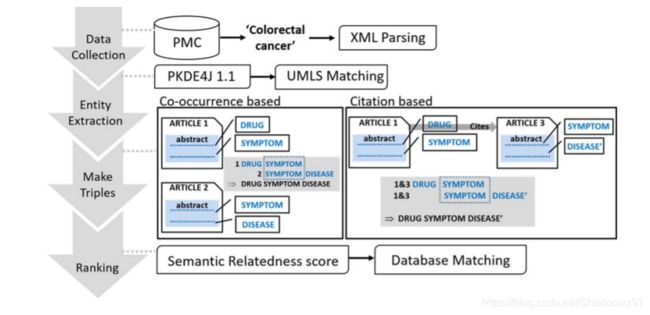
图1
图1展示了实验当中的具体步骤,第一步从PubMed中获取到相关文献的XML文件并进行解析;第二步进行实体的抽取并在UMLS中进行匹配;第三步进行隐含关系的抽取,基于共现关系的抽取原则是文献a出现药物x-症状y组合,文献b出现症状y-疾病z组合即抽取出一个药物x-症状y-疾病z三元组(如果两个组合出现在同一篇文献当中,则立刻生成这样一个三元组)。基于引用关系的抽取规则是,文献a引用了文献b,且文献a中存在了药物x-症状y,文献b存在症状y-疾病z的关系,则抽取出一个药物x-症状y-疾病z的关系。从这样的三元组中即可挖掘出药物x-疾病z的关系;第四步计算挖掘出的药物-症状关系的语义相似度,该语义相似度应该是基于UMLS提供的语义网中两个实体间隔的节点数和最短路径的。
结论
1.基于引用关系挖掘的关系更为广泛
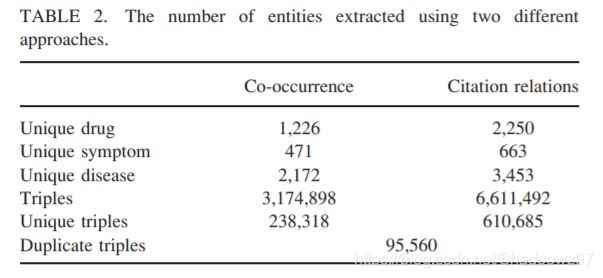
图二展示了基于共现和引用关系抽取的医学实体即三元组的数量,在各个维度上都表明基于引用的抽取方式能抽取出更多种类的实体,其中基于引用关系抽取出的三元组为610685个,是共现关系抽取结果238318的两倍。
作者将抽取结果按频次进行排序,选取了前15000条作为实验的研究对象,原因是频次排名在15000后的实体间关系已经不显著了。
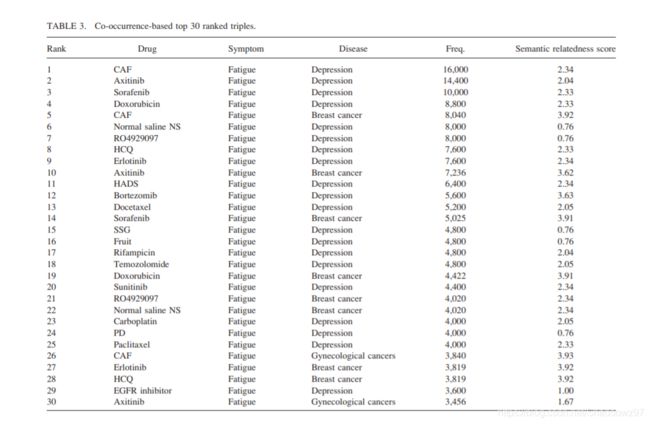
另一个证明引用关系能够挖掘更为广泛的实体联系的数据是在频次排名的前30组关系中,基于共现抽取出的关系中的疾病实体仅有抑郁、妇科癌症和乳腺癌三种,而连接疾病和药物的症状,则仅有疲乏一种。而通过被引抽取的关系就复杂得多。

2.基于共现的关系具有较高的语义相似度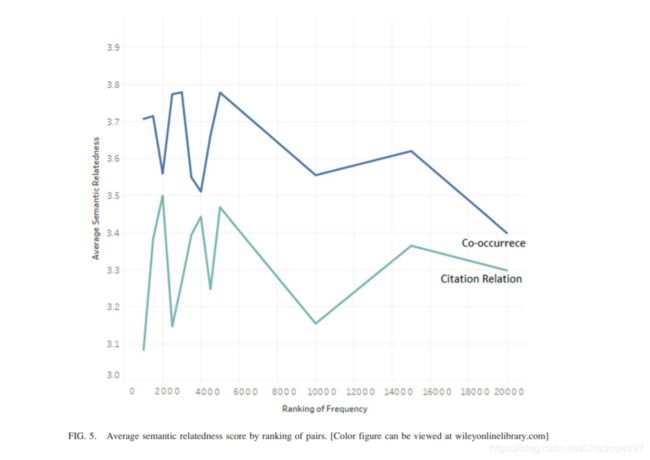
图5
图五展示了两种方式抽取的关系的语义相似度随排名的变化过程,可以看出,基于共现关系的抽取结果的语义相似度在同样的频次排名下总是高于基于引用抽取的。
语义的相似度是通过在UMLS的语义网中实体间的节点数和最短路径数决定的。对于语义相似度的大小个人认为应当分为两个方面来理解,首先如果抽取出的实体间联系的语义相似度较高,则说明两者相关的可能性越大,即可能更为可靠,同时也更可能是已经被证实的联系;语义相似度小虽然说明在如今的知识储备中两者的联系较小,但却可能说明了两者间存在我们未发掘的联系,这也是进行实体联系挖掘的目的。
如果一组关系在抽取时具有较高的频次,但是计算后仅有很小的语义联系,那么它可能是一种未被发掘的关系;如果一组关系具有较高的频次和语义相似度,那么它有可能作为一种已被证实的关系;而假设频次和语义相似度均较小那么可能是一种不存在的关系。
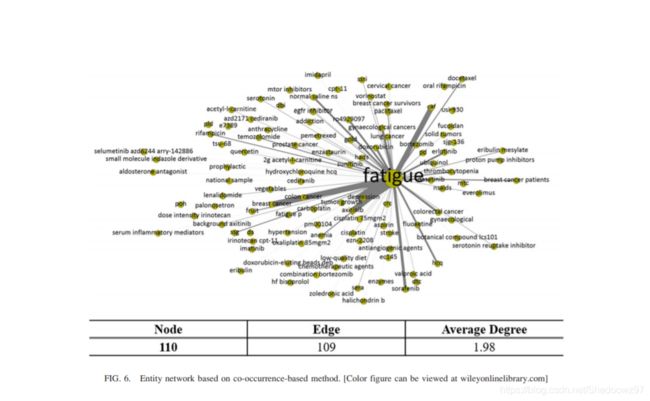
3.使用可视化的图进行展示
论文中将药物-症状关系和症状-疾病关系使用绘图软件绘制出来。
图6和图7分别展示了基于共现和引用抽取的实体关系图,从图中可以看到基于被引抽取的关系相较于基于共现抽取的关系明显覆盖了更为广阔的领域。
作者在原文中并没有提到过按照何种规则进行节点颜色的渲染的,很可能是依靠某种基于拓扑的聚类算法(如fast-unfolding),在图的聚类算法当中,一般来讲希望类别内部节点间的连边更为紧密,而类别间的节点连边较为稀疏。图7所展示的基于被引抽取的关系图的社团结构(在网络的相关研究中类别的一个替换是community,网络中的社团发现算法可以看作是一种聚类算法)还是十分明显的,作者在文中也对图中展现的5个类别的社团的含义做了解释。

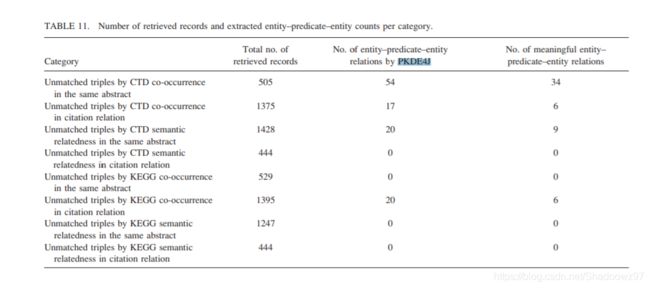
4. 抽取结果与KEGG和CTD的匹配情况
在文章中作者按抽取关系的频次排序,统计了TopN两种抽取方式的结果在两个数据库中匹配成功的数量。
总体上来看,在KEGG中能够匹配到基于共现抽取到的关系数量多于基于被引抽取到的关系数量,而在CTD中则刚好相反。
前面介绍过,KEGG存储的是已被证明的关系,CTD存储的包含一部分未被证明的信息,从该角度来看,基于共现的抽取方式倾向于找到已被证明的关系(KEGG),基于引用的抽取方式倾向于找到可能存在但未明确的关系(CTD)。
作者观察了按频次排名靠前的且能在CTD/KEGG中查找到的三元组,CTD总是找到一些并发症相关的关系,而在KEGG中倾向于找到原生疾病相关的关系。
在该部分作者将两种方式抽取到的关系按照语义相似度排序统计Top N中能在CTD和KEGG中找到的个数,得到的结论与基于频次的结论相同,但是两者的差距不再那么明显了。所以作者在这里的出结论,基于引用的抽取方法确实能够发现可能存在的关系。
5.校验关系是否真实存在
为了考量抽取的关系是否真实存在,使用那些抽取出的但在KEGG和CTD中无法查找到的药物-疾病在PubMed中进行检索,得到的结果使用 PKDE4J发现实体关系,让专业人士对这些关系进行审查,评价这些关系是否是真实存在的。
在这部分实验当中当检索条件是那些未在CTD中出现的关系时,专家评估的结果显示基于共现的抽取效果可能要由于基于引用抽取的效果要好。但是当审查那些在KEGG中未找到的关系时,专家选择的可能存在的关系却只来自那些基于引用抽取到的关系。
6.讨论和结论
在讨论部分,作者补充了一个实验,选取了6个仅被基于引用方法抽取出的关系,这些关系在语义相似度上有很大的差异。利用BITOLA(一个基于共现的关系发现系统)使用药物名称进行检索,系统会返回所有的基于共现的抽取关系,并给出相应的频次,在这6组关系中,一些表现的较好,在所有相关关系中占的比率很高,并且在这些关系间发现了额外的连接关系。这个补充的实验下作者认为基于引用抽取的实体间在现存的专业语义网中可能又多个和主题相关的中介实体的连系起来(这也是导致一些关系间的语义相似度低的原因),所以语义相似度低并不能说明基于引用抽取的结果就是不可靠的。
7.总结
7.1 文献计量学与实体计量学
作者在文章中提到了实体计量学,借助引文关系探究文献当中包含实体间的关系的研究也并不少见。将引用关系推广到实体关系,实际上是从文献空间到实体空间的映射,大多数时候可以通过矩阵的运算完成。借助矩阵可以轻易的表达十分复杂的运算过程。作者在文章末尾也提到了可以进一步增加一个基因层讨论更加微观的内容。
7.2 基于引用的抽取方式保持了主题的一致性
当借助引用关系进行分析时,是否会因为被引文献和主题的低相似性,导致抽取出的关系发生类似“主题漂移”的现象。文章中专门提到了这一问题,实验证明了基于引用的抽取方式维持了主题的一致性,反而是基于共现的抽取的方式出现了主题的偏差,比如文章中提到的,在按照频次排序的triple中的前三十名,疾病实体有3种,均和大肠癌无直接关系。
接下来的部分其实和文章主题关系不是很大,是扩展的部分,只能说一些应用和原理有相似的地方,文章本身和这些内容关系不大
7.3 UMLS、CTD、KEGG
UMLS、CTD、KEGG都是十分优秀的医学领域知识库,而且最终基本上network都是它们对外提供服务的最高级形式。远在在谷歌知识图谱概念提出之前语义网的概念就被提出了,叙词表更是图书情报领域的“传统艺能”,近年来随着“图谱的时髦”,叙词表也重新收到了关注。
7.4 关系抽取的应用
实体关系的抽取实际上是十分热门的问题,目前比较热门的知识图谱和基于图的深度学习方向都需要进行实体关系的构建工作,如何从构建好的图中挖掘信息是一个方面,而第一步是如何构建实体间的关系,如何正确的构建实体关系图,让图能够正确反应实体间的关系,或者保留更多的原始信息。
7.5 实体的高阶关系
文章中提到之前利用引用或共现进行关系抽取时,均没有借助一个中介(如本文中是症状这一实体),而且文章并没注重对抽取的实体关系进行网络分析。虽然看上去文章的结论是关于一个二元关系的(药物-疾病),但实际上抽取的是一个三元关系(药物-症状-疾病),结论可以看作是一个三元关系在二元关系上的投影。通过这样一个triple去挖掘pair事实上是对关系做了进一步的限制,考量了隐藏在网络中更多的信息。前段时间我听的一个线上讲座刚好讲到了类似的问题
基于高阶选择偏好的常识知识图谱
当我们无法判断低阶实体关系的具体类型时,可以借助一个更高阶的关系去进行判断(比如无法确定一段话中A和B的主客体关系时,借助A-B-C这样一个更高阶的关系的统计特征去解决这一问题)。在实际应用当中,如何找到一个合适更高阶的关系,可能是类似问题的难点。