生成对抗网络gan原理_GAN对抗生成神经网络--全面理解
目录
• 生成与判别
• 生成模型:贝叶斯、HMM到深度生成模型
• GAN对抗生成神经网络
• DCGAN
• ConditionalGAN
• InfoGan
• WassersteinGAN
非监督学习及GAN
• 非监督学习:训练集没有标注,学习的结果是数据的隐含规律,表现形式可以使数据按相似性分组、数据的分布、数据分量间的关联规则,最主要的是探讨非监督学习中的聚类问题。
• GAN 是Ian Goodfellow在2014年的经典之作,在许多地方作为非监督深度学习的代表作给予推广。 GAN解决了非监督学习中的著名问题:给定一批样本,训练一个系统,能够生成(generate)类似的新样本。
生成方法和判别方法
机器学习方法可以分为生成方法和判 别方法,所学到的模型分别称为生成式 模型和判别式模型。生成方法通过观测数据学习样本与标签的联合概率分布P(X, Y),训练好的模型能够生成符合样本分布的新数据,它可以用于有监督学习和无监督学习。判别方法由数据直接学习决策函数f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。
早期深层生成模型
深度产生式模型的深度信念网络(DBN )。DBN是由一组受限玻尔兹曼机 (RBMs)堆叠而成的深度生成式网络,它的核心部分是贪婪的、逐层学习的算法, 这种算法可以最优化深度置信网络的权重 。以无监督方式预训练的生成式模型(DBN)可以提供良好的初始点,然后通 过有监督的反向传播算法微调权值
GAN
生成对抗网络,由两个网络组成, 即生成器和判别器,生成器用来建立满足一定分布的随机噪声和目标分布的映射关系,判别器用来区别实际数据分布和生成器产生的数据分布。
GAN之前的非监督学习
• 根据训练集估计样本分布p(x),之后对p(x)进行采样, 可以生成“和训练集类似”的新样本。
• 对于低维样本,可以使用简单的,只有少量参数的概率模型(例如高斯)拟合p(x),但高维样本(例如图像 )就不好处理了。
RBM(Restricted Boltzmann Machine):构造一个无向图,图的能量和节点取值的概率有指数关系。利用训练集设定图中节点和边的系数,用来表述样本中单个元素和相连元素的关系。
DBN(Deep Belief Networks):用单个RBM和若干有向层构成网络。
上面的算法计算复杂。
AutoEncoder
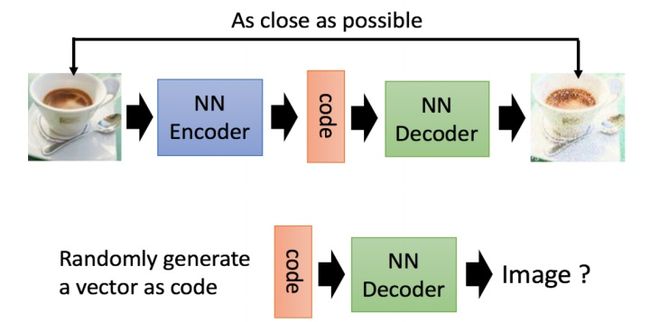
VAE

Encoder-Decoder

VAE存在的问题
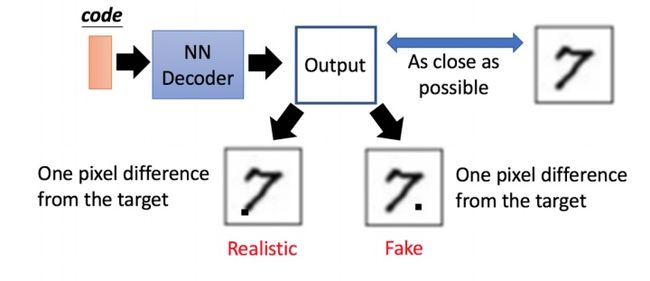
对抗网络:使用两个网络互相竞争,称之为对抗式 (adversarial)结构
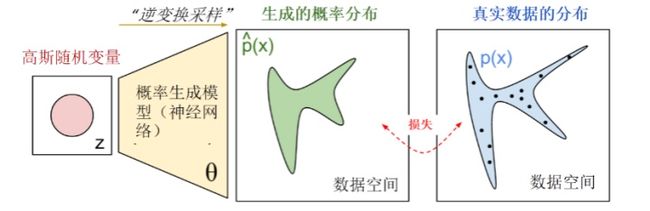
生成器G(Generator Network):通过一个参数化概率生成模型(通常用深度神经网络进行 参数化)进行概率分布的逆变换采 样,得到一个生成的概率分布。
判别器D(Discriminator Network):给定样本,判断(通常也是深度卷积神经网络)这个样本 来自真实数据还是伪造数据。

GAN基本原理
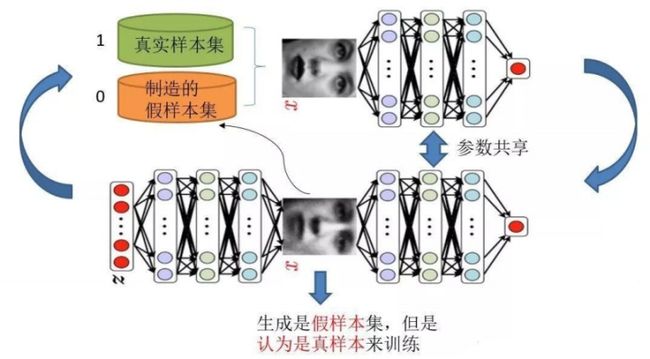

GAN训练过程
The evolution of generation

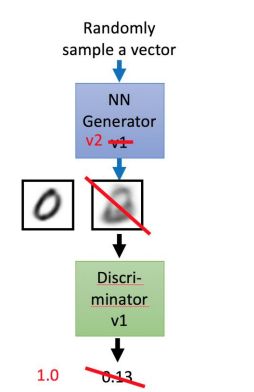
GAN - Discriminator

GAN - Generator

生成式对抗网络--如何定义损失
怎样定义损失(优化目标) ? >寻找生成模型与判别模型之间的纳什均衡
通过优化目标,使得我们可以调节概率生成模型的参数,从而使得生成的概率分布和真实数据分布尽量接近。但是这里的分布参数不再与传统概率统计一样,这些参数保存在一个黑盒中:最后所学到的一个数据分布Pg(G) ,没有显示的表达式。
GAN损失函数
这个Loss其实就是交叉熵。对于判别器D,它的任务是最小化 -L(G,D) ,即
如果采用零和博弈,生成器G的目标是最小化L(G,D),而实际操作发现零和 博弈训练效果并不好,G的目标一般采用最小化
一般来说,更新D是,G是固定的;更新G时,D是固定的。
生成式对抗网络--GAN的训练方法
优化函数的目标函数
D(x)表示判别器认为x是真实样本的概率,而1-D(G(z))则是判别器认为合成样本为假的概率 。 训练GAN的时候,判别器希望目标函数最大化,也就是使判别器判断真实样本为“真”,判断合成样本为 “假”的概率最大化;与之相反,生成器希望该目标函数最小化, 也就是降低判别器对数据来源判断正确的概率。
- 生成模型:要最小化判别模型D的判别准确率。
- 判别模型:要尽量最大化自己的判别准确率
在训练的过程中固定一方,更新另一方的网络权重,交替迭代,在这个过程中,双方都极力优化自己的网络,从而形成竞争对抗,直到双方达到一个动态的平衡(纳什均衡),此时生成模型 G 恢复了训练数据的分布(造出了和真实数据一模一样的样本),判别模型再也判别不出来结果,准确率为 50%,约等于乱猜。
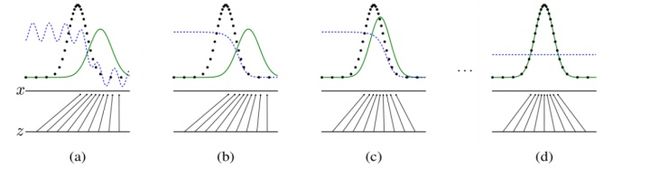
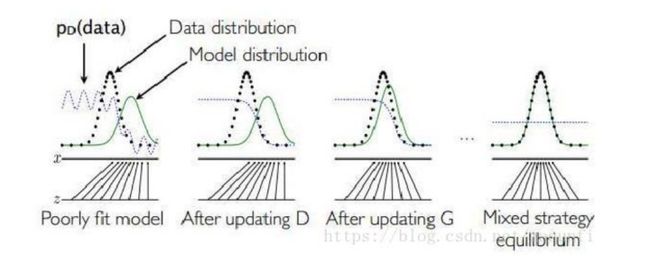
图的说明:
黑色大点虚线P(X)是真实的数据分布。
绿线G(z)是通过生成模型产生的数据分布(输入是均匀分布变量z,输出是绿色的线).
蓝色的小点虚线D(X)代表判别函数
较低的水平线是z采样的区域,在这种情况下,上面的水平线是X域的一部分。向上箭头显示映射x=g(Z)如何将非均匀分布的pg强加于转换后的样本上。g在高密度区域收缩,在pg低密度区域扩展。
过程说明:
(a)Pg和Pdata 相似,D是部分精确的分类器
(b)D被训练以区分样本和数据,并收敛到
(c)在更新g之后,d的梯度引导g(Z) 流向更有可能被归类为数据的区域 。
(d)产生的绿色分布和真实数据分布已经完全重合。这时,判别函数对所有的数据(无论真实的还是生成的数据),输出都是一样的值,已经不能正确进行分类。G成功学习到了数据分布,这样就达到了 GAN的训练和学习目的。Pg = Pdata ,判别器无法区分这两个分布,此时D(X)=1/2
生成式对抗网络--全局最优解和收敛性
全局最优解和收敛性
GAN是存在全局最优解的
首先,如果固定G,那么D的最优解就是一个贝叶斯分类器 。将这个最优解形式带入,可以得到关于G的优化函数。 简单的计算可以证明,当产生的数据分布与真实数据分布完全一致时,这个优化函数达到全局最小值。Pg=Pdata 生成模型G隐式地定义了一个概率分布Pg,我们希望Pg 收敛到数据真实分布Pdata。论文证明了这个极小化极大博弈当且仅当Pg = Pdata时存在最优解,即达到纳什均衡, 此时生成模型G恢复了训练数据的分布,判别模型D的准确率等于50%。
GAN的收敛性
如果G和D的学习能力足够强,两个模型可以收敛。
但是GAN模型的收敛性和均衡点存在性需要新的理论突破,模型结构和训练稳定性需要进一步提高。
GAN的收敛是很困难的。第一,就是梯度消失的问题,当优化的时候,对于公式里生成器、判别器的损失函数会存在梯度消失的问题, 那么我们需要设计一些更好的损失函数,使得梯度消失问题得到解决。第二个就是模式发现问题,也就是说我们的生成器可能生成同样的数据而不是多样的数据。
GAN缺点
在原始GAN的(近似)最优判别器下,第一种生成器loss面临梯度消失问题,第二种生成器loss面临优化目标荒谬、梯度不稳定、对多样性与准确性惩罚不平衡导致缺乏多样性的问题。
原始GAN问题的根源可以归结为两点,一是等价优化的距离衡量(JS散度、KL散度)不合理,二是生成器随机初始化后的生成分布很难与真实分布有不可忽略的重叠。
JS散度、KL散度:衡量两个分部的相似程度
2015年的DCGAN把类似的理念应用到人脸图像上。通过对编码(输入的随机向量)进行代数运算,控制生成人脸图像的属性。

生成式对抗网络--衍生模型 DCGAN
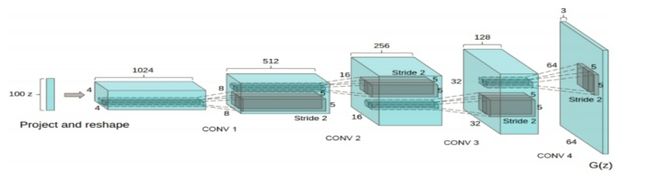
把有监督学习的CNN与无监督学习的GAN整合到一起提出了Deep Convolutional Generative Adversarial Networks - DCGANs,是生成器和判别器分别学到对输入图像层次化的表示。
1.使用DCGANs从大量的无标记数据(图像、语音)学习到有用的特征,相当于利用无标记数据初始化DCGANs的生成器和判别器的参数,在用于有监督场景.
2.表示学习representation learning的工作:尝试理解和可视化GAN是如何工作的.
3.稳定训练DCGANs
Facebook AI Research



Wasserstein距离
Wasserstein距离又叫Earth-Mover(EM)距离,定义如下:
•
在所有可能的联合分布中能够对这个期望值取到的下界 ,就定义为 Wasserstein距离。
直观上可以把理解为在 γ 这个“路径规划”下把 Pr 这堆“沙土”挪到 Pg “位置”所需的“消耗”,而 W(Pr, Pg) 就是“最优路径规划”下的“最小消耗”,所以才叫Earth-Mover(推土机)距离。
Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。
Wasserstein距离定义中的没法直接求解,用了一个已有的定理把它变换为如下形式:
- Lipschitz连续:对于连续函数f,存在常数K大于等于0, 使得:对于定义域内任意x1,x2满足:
• 把 f 用一个带参数 w 的神经网络来表示,并对w进行限制
- 构造一个含参数 w、最后一层不是非线性激活层 的判别器网络,在限制 w 不超过某个范围的条件 下,使得
尽可能取到最大,此时 L 就会近似真实分布与生成分 布之间的Wasserstein距离(忽略常数倍数 K)。
原始GAN的判别器做的是真假二分类任务,所以最后一层是sigmoid,但是现在 WGAN中的判别器 做的是近似拟合Wasserstein距离,属于回归任务,所以要把最后一层的sigmoid拿掉
生成器要近似地最小化Wasserstein距离,可以最小化 L ,由于Wasserstein距离的优良性质,我们不需要担心生成器梯度消失的问题。再考虑到 L 的第一项与生成器无关,就得到了WGAN的两个loss
• 生成器损失函数:
• 判别器损失函数:
可以指示训练进程,其数值越小,表示真实分布与生成分布的Wasserstein距离越小,GAN训 练得越好。
WGAN

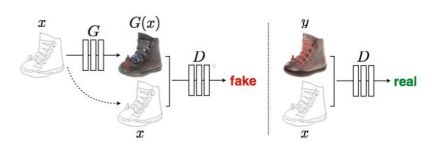
生成式对抗网络--衍生模型 CGAN

1.定义:通过将额外信息y输送给判别模型和生成模型,作为输入层的一部分,从而实现条件GAN
2.在生成模型中,先验输入噪声p(z)和条件信息y联合组成了联合隐层表征。条件GAN的目标函数是带有条件概率的二人极小极大值博弈(two-player minimax game )
生成式对抗网络--衍生模型 InfoGAN
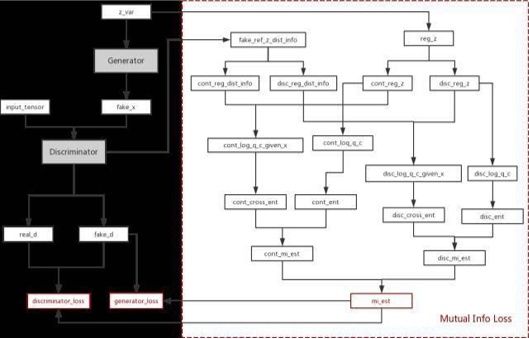
InfoGAN:挖掘GAN模型隐变量特点的模型 为了使输入包含可以解释,更有信息的意义,InfoGAN[7]的模型在z之外,又增加了一个输入c,称之为隐含输入(latent code),然 后通过约束c与生成数据之间的关系,使得c里面可以包含某些语义特征(semantic feature),比如对MNIST数据,c可以是digit(0-9) ,倾斜度,笔画厚度等。
生成式对抗网络--计算机视觉






生成式对抗网络--图像超分辨率

生成式对抗网络--图像去雨

GAN – 二次元人物頭像鍊成

代码和案例实践
• 图片生成
• 图片风格转换