解析逻辑回归模型
介绍
逻辑回归模型是业界运用最为广泛的模型,我们从下面几个方面讨论这个模型:
1. 在模型层面上,逻辑回归模型是被用来解决分类问题的。由于分类是一个非线性问题,所以建模的主要难点是如何将非线性问题转化为线性问题。主要从两方面入手:
- 从分解问题的角度入手:通过引入隐含变量(这里举一个例子,来解释什么是隐含变量:当人们在购买衣服的时候,能被其他人观察到的只有购买与否这个行为,而忽略了在这行为之前的内心博弈的过程。这个博弈的过程其实就是内心在比较购买带来的快乐多还是购买带来的烦恼多,是一个概率问题,在统计上,这个过程我们可以看成事件发生比,它表示的是该事件发生于不发生的比率)。将问题划分为两个层次,一个是线性的隐含变量模型,另一个是基于隐含变量模型结果的非线性的变换。

正态分布的累积分布函数几乎和逻辑分布的累积分布函数一样。其中虚线,呈S形状,因此也被称为S函数(sigmoid函数),它其实就是描述了某一方竞争胜出的概率。
- 从图像的角度入手:逻辑回归通过非线性的空间变换,将原空间内非线性的分类问题转换为新空间内的线性问题,再用线性模型去解决。
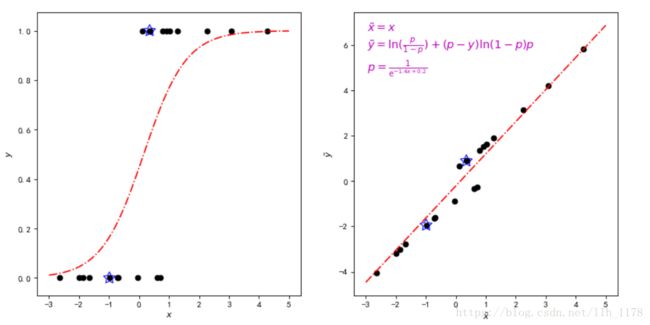
上图中右图表示原空间,左图表示变换后的空间。可以形象地把右图想象成橡皮泥,握住里面曲线的两头,用力将其拉成一条直线,就得到了左图,换句话说,在新的线性空间中,线性回归模型就可以很好的拟合数据了。
2. 在模型评估层面,对于分类问题的预测结果,可以定义相应的查准率和查全率,以及综合这两种效应的F1评分。对于基于概率的分类模型,还可以绘制他的ROC曲线,以及计算曲线下的AUC值。
3. 在数据分类不均衡层面,最常见的也是最方便的方法是修改损失函数里不同类别的权重。将它的损失函数改写成:
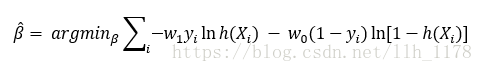
当类别1所占比例很少时,则增加w1,也就是增加模型对于类别1所承受的损失,反之亦然。在很多情况下,类别权重的选择原则是,类别权重等于类别所占比例的倒数。同时,对于不均衡的数据也可以使用重新采样的方法,将多的类别变少将少的类别变多。这里需要注意的是:在使用不均衡数据建模的时候,使用准确度进行模型评估会失真,而使用AUC(曲线下的面积)是可以保持稳定的,不会像准确度那样失真。
上手实践
结合具体的数据,搭建逻辑回归模型。我们使用的数据是美国个人收入的普查数据。
1. 读取数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
from sklearn.model_selection import train_test_split
%matplotlib inline
data = pd.read_table("E:/database/adult.data", sep=",")
data.head()
data.info()
这里为了专注于逻辑回归模型本身,先使用数值型变量加性别字符型变量,因为女性和男性之间没有什么关联,我们也考虑进去,所以使用年限、受教育年限、该年度投资收益、该年度投资损失和每个星期工作的时间。
2. 数据分析
查看数据的缺失值
data.isnull().sum()数据转换
# 将"female"用0表示,将"male"用1表示。
data["sex_code"] = pd.Categorical(data.sex).codes
# 将"<=50K"用0表示,将">50K"用1表示。
data["label_code"] = pd.Categorical(data.label).codes
cols = ["age", "education_num", "capital_gain", "capital_loss", "hours_per_week", "sex_code", "label_code"]可视化各个特征
# data[["age", "hours_per_week", "education_num", "label_code"]].hist()
fig = plt.figure(figsize=(10,6))
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(222)
ax3 = fig.add_subplot(223)
ax4 = fig.add_subplot(224)
sns.distplot(data.age, hist= False, ax=ax1)
sns.distplot(data.hours_per_week, hist= False, ax=ax2)
sns.distplot(data.education_num, hist= False, ax=ax3)
sns.distplot(data.label_code, kde= False, ax=ax4, bins=20)
plt.show(block=False)
受教育年限与收入的关系
使用交叉报表统计:
cross1 = pd.crosstab(pd.qcut(data.education_num, [0, .25, .5, .75, 1]), data.label)
cross1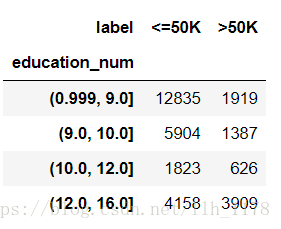
然后,接着可视化——马赛克图展示变化趋势:
from statsmodels.graphics.mosaicplot import mosaic
import matplotlib as mpl
plt.style.use("ggplot")
mpl.rcParams['xtick.labelsize'] = 16
mpl.rcParams['ytick.labelsize'] = 16
mpl.rcParams["axes.labelcolor"] = "k"
mpl.rcParams["axes.labelsize"] = 20
mpl.rcParams['font.size'] = 15
fig = plt.figure(figsize=(16,6))
ax = fig.add_subplot(111)
props = lambda key: {"color": "0.45"} if ' >50K' in key else {"color": "#C6E2FF"}
mosaic(cross1.stack(), ax=ax, properties=props)
plt.show(block=False)
接下来我们再看每周工作时间与收入的关系。
# 计算hours_per_week, label 交叉报表
cross2 = pd.crosstab(pd.cut(data.hours_per_week, 5), data.label)
# 标准化一下
cross2_norm = cross2.div(cross2.sum(1).astype(float), axis=0)
cross2_norm
可视化
cross2_norm.plot(kind="bar", color=["green", "red"], rot=45)
3. 搭建模型
首先整理数据
df = data[cols]
df.head()
将数据全部转化为数值型
首先,我使用Statsmodels库来搭建模型,从统计学的层面来观察模型。
# 切分数据成训练集和测试集
train_data, test_data = train_test_split(df, test_size=.2)
# 搭建模型
formula = "label_code ~ age + education_num + capital_gain + capital_loss + hours_per_week + sex_code"
model = sm.Logit.from_formula(formula=formula, data=train_data)
re = model.fit()
re.summary()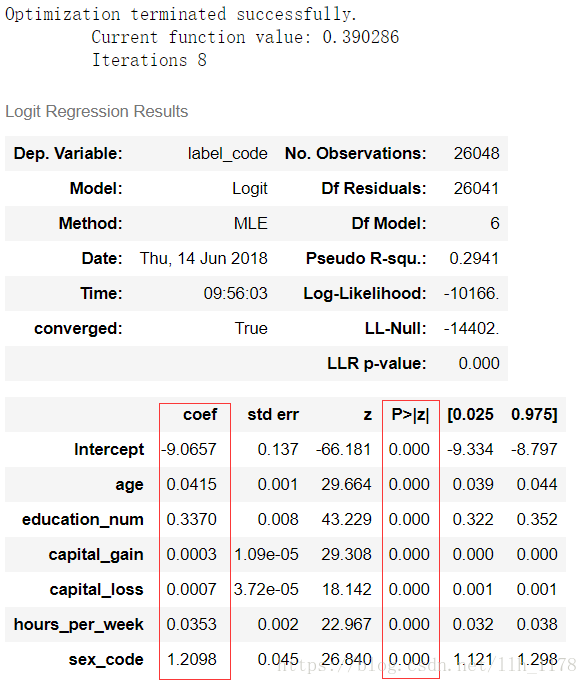
coef是代表各个变量的参数估计值,P>|Z| 代表参数是否显著。通过上图,我们可以清楚的看出各个变量都是与因变量收入成正相关的,且都是显著影响收入的。
同时,我们还可以对各个变量的参数进行T检验,看是否显著。
# 检验的假设为:变量education_num的系数等于0。
re.f_test("education_num=0")结果:

P-value小于0,拒绝education_num的系数等于0这个假设,即他的系数是显著的。
3. 模型评估
首先使用查准率和查全率以及F1评分。

那么可以得到公式:
Precision = TP / (TP + FP)
Recall = TP / (TP + FN)
而,f1则是综合了查准率和查全率这两个指标,是它们的加权调和平均数。
F1 = 2 x precision x recall / (precision + recall)
用代码表示:
test_data["prob"] = re.predict(test_data)
test_data["pred"] = test_data.apply(lambda x: 1 if x["prob"] > 0.5 else 0, axis=1)
bins = np.array([0, 0.5, 1])
label = test_data["label_code"]
pred = test_data["pred"]
tp, fp, fn, tn = np.histogram2d(label, pred, bins=bins)[0].flatten()
precision = tp / (tp + fp)
recall = tp / (tp + fn)
f1 = 2 * precision * recall / (precision + recall)
print("查准率:%3f, 查全率:%3f, f1:%3f" % (precision, recall, f1))结果:
查准率:0.935549, 查全率:0.844853, f1:0.887891
接下来使用ROC曲线评估模型
其实,如果我们仔细体会查全率的定义:TP / (TP + FN),公式中的分母为实际上年收入大于5万的居民数,而查准率:****TP / (TP + FP),公式中的分母为预测结果中年收入大于5万的居民数。也就是说分子和分母都是受模型的影响,因此当查准率变化时,很难说清是哪一部分在变化,继而不能有效的进行下一步分析。
为了解决这个问题,引入了两个新指标:真阳性率(TPR)和伪阳性率(FPR)。
TPR = TP / (TP + FN)
FPR = FP / (FP + TN)
我们可以将这两个指标放在同一和空间内对数据模型进行评估,这就有了ROC空间。它是以伪阳性率为横轴,以真阳性率为纵轴画一个长度为1的正方形。在这个空间中越离左上角近的点预测的准确率越高,同时正方形的对角线表示随机分类的预测结果,这说明要高于这个对角线才算模型正常,不然,这个模型的准确性比随机概率0.5还低了,就不行了。
下面用代码演示(使用sklearn库):
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
features = ["age", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
labels = "label_code"
trainSet, testSet = train_test_split(data, test_size=0.2, random_state=2310)
model = LogisticRegression()
model.fit(data[features], data[labels])
# 得到预测的概率
preds = model.predict_proba(testSet[features])[:,1]
# 得到False positive rate和True positive rate
fpr, tpr, _ = metrics.roc_curve(testSet[labels], preds)
# 得到AUC
auc = metrics.auc(fpr, tpr) # 0.83可视化:
plt.rcParams["font.sans-serif"]=["SimHei"]
# 创建一个图形框
fig = plt.figure(figsize=(6, 6), dpi=80)
# 在图形框里只画一幅图
ax = fig.add_subplot(1, 1, 1)
# 在Matplotlib中显示中文,需要使用unicode
ax.set_title("%s" % u"ROC曲线")
ax.set_xlabel("伪阳性率(False positive rate)")
ax.set_ylabel("真阳性率(True positive rate)")
ax.plot([0, 1], [0, 1], "r--")
ax.set_xlim([0, 1])
ax.set_ylim([0, 1])
ax.plot(fpr, tpr, "k", label="%s; %s = %0.2f" % (u"ROC曲线",
u"曲线下面积(AUC)", auc))
ax.fill_between(fpr, tpr, color="grey", alpha=0.6)
legend = plt.legend(shadow=True)
plt.show()
可以看出AUC值与查全率查准率不同,它不依赖与模型所定阈值,而是完全取决于模型本身。因此,它也被看出是评估模型更加全面的指标了。