《Python数据分析与挖掘》实战项目 - Python程序设计(期末大作业、课程设计、毕业设计)2012-2021近十年考研英语一真题词汇词频统计与可视化(附代码)
《Python数据分析与挖掘》 - 2012-2021近十年考研英语一真题词汇词频统计与可视化
正版链接:
https://blog.csdn.net/meenr/article/details/119039354
目录
- 《Python数据分析与挖掘》 - 2012-2021近十年考研英语一真题词汇词频统计与可视化
-
- 最新版本更新
- 前言
-
- 开发环境
- 赞助网站(爬虫)
- 历年真题数据获取(本文以2012年为例)
-
- 爬取网页内容
- 提取数据
- 初步预处理
- 数据持久化
- 变形单词处理(-s/-ed/-ing)
- 词频统计
- 数据可视化
- ==代码等资料获取==
-
- 途径一
- 途径二
最新版本更新
鉴于很多使用者反馈上一版本的代码冗余、文件结构复杂,对新人不友好等问题,2贰进制于2022年5月对上一版本代码进行了整合优化。<\r>
将原来约20个python代码文件,整合到4个文件中,功能无变化,包括:2012-2021年10年间考研英语一试卷的爬取、整合,数据持久化、数据预处理、词频统计和可视化等功能。
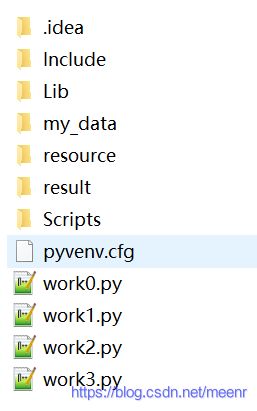
现最新代码文件结构如下图所示:
前言
用Python 语言爬取近十年(2012-2021)考研英语一真题,完成数据持久化、数据预处理,提取英文词汇,去除变形词汇以及词频统计等内容。
开发环境
Windows10、Python3.7、PyCharm、GoogleChrome(谷歌浏览器);
赞助网站(爬虫)
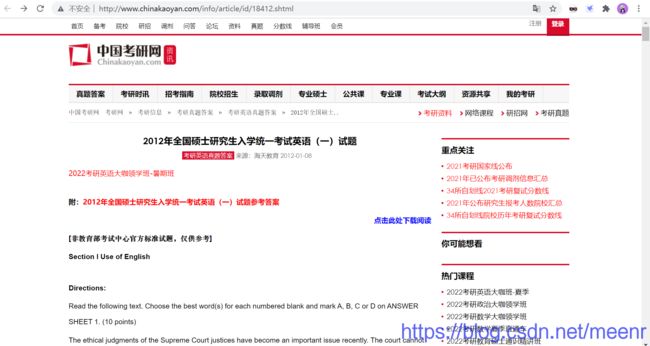
爬取近十年考研英语一的真题试卷,感谢中国考研网的“支持”,网站地址:http://www.chinakaoyan.com/
历年真题数据获取(本文以2012年为例)
爬取网页内容
# -*- coding: utf-8 -*-
"""==============================
#@Project : 考研英语词汇分析
#@File : English_2012
#@Software: PyCharm
#@Date : 2021/7/19 0:58
#@Desc :
=============================="""
import os
import re
import parsel
import requests
# 12年试卷网址
url = 'http://www.chinakaoyan.com/info/article/id/18412.shtml'
headers = {
'Host': 'www.chinakaoyan.com',
'User-Agent': '你的浏览器user-agent'
}
response = requests.get(url=url, headers=headers)
print(response.status_code)
response.encoding = response.apparent_encoding
html_data = response.text
print(html_data)
提取数据
selector = parsel.Selector(html_data)
div = selector.xpath('//div[@class="cont"]')
p = div.xpath('//div[@class="cont"]/p/font/text()')
p_data = str(p.getall()).replace(''
, '').replace(r'', '').replace(r'\r\n', '').replace(r'\xa0', '')
print(p_data)
初步预处理
english_data = ''.join(filter(lambda c: ord(c) < 256, p_data))
# 正则表达式
cop = re.compile("[^a-zA-Z]")
english_data1 = cop.sub(' ', english_data)
print(english_data1)
数据持久化
if not os.path.exists(r'txt2012_2021'):
os.makedirs(r'txt2012_2021')
with open(r'txt2012_2021/2012.txt', mode='w', encoding='utf-8') as f:
f.write(english_data1)
f.close()
可在十年词汇都获取到后进行以下步骤,本文仅以2012年为例,文末提供全部代码的获取方式。
变形单词处理(-s/-ed/-ing)
英文词汇存在变形的特点,去除:复数形式+s或+es、过去式+ed以及进行时+ing等变形词汇,可提高词频分析的完整性和准确性。
def get_word():
path1 = r'txt2012_2021/2012.txt'
with open(path1, mode='r', encoding='utf-8') as f:
data = f.read()
f.close()
split1 = data.split()
exchange = data.lower()
original_list = exchange.split()
words_list = []
chant = enchant.Dict("en_US")
for i in original_list:
if chant.check(i):
words_list.append(i)
return words_list
words_list = get_word()
nos_list2 = words_list.copy()
ss_list = []
eds_list = []
for word in nos_list1:
if word[-1] == 's' or word[-3:] == 'ies' or word[-3:] == 'hes':
ss_list.append(word)
nos_list2.remove(word)
nos_list2.append(word[:-1])
if word[-2:] == 'ed':
eds_list.append(word)
nos_list2.remove(word)
nos_list2.append(word[:-1])
pass
pass
词频统计
dic1 = {}
for i in word_list:
count = word_list.count(i)
dic1[i] = count
print('dic1:', len(dic1))
word = {
'a', 'an', 'above', 'b', 'c','d', 'e', 'f', 'h', 'm', 'n', 't', 'the',
'and', 'or', 'but', 'because', 'so', 'while', 'if', 'though', 'however', 'whether', 'once', 'no', 'not',
'none',
'in', 'by', 'on', 'from', 'for', 'of', 'to', 'at', 'about', 'before', 'down', 'up', 'into', 'over',
'between', 'through', 'during', 'with', 'without', 'since', 'among', 'under', 'off',
'also', 'ago', 'likely', 'then', 'even', 'well', 'around', 'after', 'yet', 'just', 'already', 'very',
'i', 'we', 'our', 'you', 'your', 'he', 'she', 'her', 'it', 'these', 'that',
'here', 'there', 'those', 'them', 'they', 'their', 'other', 'another', 'any', 'own',
'are', 'were', 'be', 'being', 'been',
'should', 'will', 'would', 'could', 'can', 'might', 'may', 'need', 'do', 'doing', 'did',
'have', 'had', 'must',
'like', 'which', 'what', 'who', 'when', 'how', 'why', 'where',
}
for i in word:
del (dic1[i])
dic2 = sorted(dic1.items(), key=lambda d: d[1], reverse=True)
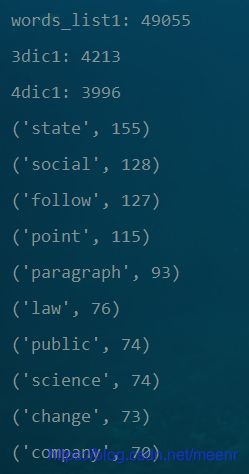
for i in range(50):
print(dic2[i])
打印结果:
数据可视化
# 字典生成词云
bimg = imageio.imread('p3.jpg')
for color in range(len(bimg)):
bimg[color] = list(map(transform_format, bimg[color]))
plt.imshow(wc)
plt.axis('off')
plt.show()

2贰进制–Echo 2021年7月
如果您已阅读至此,请点赞+评论+收藏,要是关注那更是对我极大地支持了,您的支持便是我前进的动力!
如果本文对你有所帮助,解决了您的困扰,那就请我吃包辣条吧:
代码等资料获取
篇幅原因不在具体赘述所有代码,感兴趣的读者如需要本文相关代码等资料,可通过以下两种方式获取:
途径一
关注“ 2贰进制 ” 公 主 号,回复:“ 考研词汇分析
途径二
加入2贰进制社区(480558240)QQ群,群文件自行下载或者联系管理员获取
此致
感谢您的阅读、点赞、评论、收藏与打赏。