Alphapose论文代码详解
注:B站有相应视频,点击此链接即可跳转观看https://www.bilibili.com/video/BV1hb4y117mu/
第1节 人体姿态估计的基本概念
第2节:Alphapose
2.1Alphapose简介
Alphapose是由上海交大大学的卢策吾团队和腾讯优图提出的一种区域多人姿态估计框架,论文全称:RMPE: Regional Multi-Person Pose Estimation,于2018年2月4日发表于ICCV,在MPII数据集上达到76.7mAP。
Alphapose是多人姿态估计方法,比单人姿态估计难度大,更具有挑战性。目前多人姿态估计的方法分为两类:一种是自顶向下,另一种是自底向上。自顶向下检测方法是先检测图片中的每个人的边界框,再独立检测每个人体边界框中的姿态。这种方法的缺点是高度依赖人体边界框的检测质量,如果人体边界框定位不准确,就无法正确预测人体姿态。自底向上是先检测出图像中的所有关节点,然后拼接得到人体骨架,这种方法的缺点是当人体距离相近时,关节点的分组容易出现模棱两可的情况,肢体关节不知道如何匹配到相应的骨架。
2.1.1解决的问题
Alphapose采用的是自顶向下的方法,但目前这种方法还存在下面两个问题。
1.边界框定位错误
图 1-3是用Faster-RCNN(目标检测器)和SPPE(堆叠沙漏模型)进行人体姿态估计的结果,红色虚线框是人体真实位置,黄色虚线框是Faster-RCNN检测出的人体位置,黄色虚线框与红色虚线框的IoU>0.5(IoU指检测边界框和真实框的重叠面积),IoU>0.5说明黄色虚线框能够正确检测出人体。右边两张是经过SPPE进行估计出的关节点热图,热图中高亮区域表示有关节点的概率。由图2.2.1可知即使在IoU > 0.5认为边界框定位准确的情况下,黄色虚线框的关节点热图仍然不能检测出关节点位置,也就是说SPPE并没有预测出人体姿态,这是因为边界框的定位会影响SPPE的检测效果,如果想要正确检测出人体,就必须定位出更准确的人体边界框。

图1-3 边界框定位错误
2.冗余的姿态
图 1-4中左图显示了Faster-RCNN检测到的人体边界框,右图显示了估计的人体姿态。每个边界框经过SPPE都会产生一个姿态,因为每个边界框都是独立操作的,所以一个人会估计出多个姿态。但我们最后只需要一个姿态,其他的姿态都是多余的,并且会对最后估计姿态产生影响,因此需要删除多余姿态。

图 1-4 冗余的姿态
2.1.2 Alphapose网络结构
为了解决上面两个问题,Alphapose提出了一种区域多人姿态估计(RMPE)框架,如图1-5所示。(RMPE)框架改进了基于sppe的人体姿态估计算法的性能。为了从边界框中提取出高质量的单人区域,设计了一种附加在SPPE上的对称空间变换网络(SSTN),为了优化该网络又并联了一条SPPE支路。针对姿态冗余问题,提出了参数化姿态非最大抑制( Parametric Pose NMS),制定一个度量标准测量姿态间的相似度,从而消除冗余的姿态。最后,用姿态引导区域框生成器(PGPG)来增强训练样本,通过学习不同姿态人体检测器的输出分布,模拟人体边界框的生成,生成大量的训练样本。

图 1-5 区域多人姿态估计(RMPE)框架
2.2 SSTN对称空间变换网络
2.2.1含义
为了解决问题一:边界框定位错误,Alphapose提出了SSTN(对称空间变换网络),如图1-6所示。如果人体检测框定位不准确,可以通过SSTN对人体检测框进行空间变换(移动或剪裁)使人体处于人体检测框的中央。
SSTN包括两部分:STN(空间变换网络)和SDTN(反向空间变换网络)。
- STN利用移动、剪裁等空间变换使边人体处于检测框的中央;
- SDTN将SPPE估计出的人体姿态线和图片反向变换到输入图像中。
Parallel SPPE的作用:优化STN,Parallel SPPE先估计出人体姿态,然后判断人体姿态的中心点是否在人体检测框的中心,不在中心就返回较大误差,进而达到优化STN的目的,促使STN提取更精确的人体检测框。Parallel SPPE只在训练阶段使用,在测试阶段没有Parallel SPPE。

图 1-6 SSTN对称空间变换网络
2.2.2对称空间变换网络代码详解
用pycharm打开Alphapose里面的img.py,该工程的SSTN网络代码可见img.py的cropBox(),如代码清单2.2.2-1所示。cropBox()函数有五个参数:img是输入图像,ul是人体检测框左上角顶点的坐标,br是人体检测框右下角顶点的坐标,resH是输入图像的高,resW是输入图像的宽。
def cropBox(img, ul, br, resH, resW):
ul = ul.int()#对坐标点进行取整
br = (br - 1).int()
lenH = max((br[1] - ul[1]).item(), (br[0] - ul[0]).item() * resH / resW)#计算人体边界框的高
lenW = lenH * resW / resH#计算人体边界框的宽(边界框比例一定)
if img.dim() == 2:#如果img维数为2,则对img扩维
img = img[np.newaxis, :]
box_shape = [(br[1] - ul[1]).item(), (br[0] - ul[0]).item()]#检测框大小
pad_size = [(lenH - box_shape[0]) // 2, (lenW - box_shape[1]) // 2]#填充大小
#在人体边界框周围填充0点
if ul[1] > 0:
img[:, :ul[1], :] = 0
if ul[0] > 0:
img[:, :, :ul[0]] = 0
if br[1] < img.shape[1] - 1:
img[:, br[1] + 1:, :] = 0
if br[0] < img.shape[2] - 1:
img[:, :, br[0] + 1:] = 0
src = np.zeros((3, 2), dtype=np.float32)#定义三行两列数组,原始图像点坐标
dst = np.zeros((3, 2), dtype=np.float32)#变换后图点坐标
src[0, :] = np.array(
[ul[0] - pad_size[1], ul[1] - pad_size[0]], np.float32)
src[1, :] = np.array(
[br[0] + pad_size[1], br[1] + pad_size[0]], np.float32)
dst[0, :] = 0
dst[1, :] = np.array([resW - 1, resH - 1], np.float32)
src[2:, :] = get_3rd_point(src[0, :], src[1, :])
dst[2:, :] = get_3rd_point(dst[0, :], dst[1, :])
trans = cv2.getAffineTransform(np.float32(src), np.float32(dst))#getAffineTransform()图的仿射变换函数,得到变换矩阵trans
dst_img = cv2.warpAffine(torch_to_im(img), trans,(resW, resH), flags=cv2.INTER_LINEAR)#仿射变换,dst_img是变换后的图片
return im_to_torch(torch.Tensor(dst_img))
2.3 parametric pose NMS参数化非极大值抑制
2.3.1含义
图片经过检测器会生成的多个人体检测框,但在用SPPE进行人体姿态估计时,多余的人体检测框也会生成相应的人体姿态,这就导致了姿态冗余,会降低人体姿态估计的精度,为了消除冗余的姿态,之前的方法大都采用非极大值抑制(NMS)。
非极大值抑制(Non-Maximum Suppression),简称为NMS。其思想是搜素局部最大值,抑制非最大值。NMS算法在不同应用中的具体实现不太一样,但思想是一样的。非极大值抑制,在计算机视觉任务中得到了广泛的应用,例如边缘检测、人脸检测、目标检测(DPM,YOLO,SSD,Faster R-CNN)等。
非极大值抑制流程:
前提:人体检测框列表及其对应的置信度得分列表,设定IoU阈值(IoU是用两个检测框的交集部分除以它们的并集的值),阈值用来删除重叠较大的边界框。
1.根据置信度得分进行排序
2.选择置信度最高的比检测框添加到最终输出列表中,将其从检测框列表中删除
3.计算所有检测框的面积
4.计算置信度最高的检测框与其它候选框的IoU。
5.删除IoU大于阈值的检测框
6.重复上述过程,直至检测框列表为空
为了提高人体姿态估计的精度,必须消除冗余的姿态。因此Alphapose提出了parametric pose NMS参数化非极大值抑制,用这种方法可以有效的消除冗余的姿态。
参数化非极大值抑制由两种消除标准组成:置信度消除和距离消除,冗余姿态只要满足其中一个消除标准就会被消除。
置信度消除:消除置信度相似的关节点。

注:Pi和Pj:人体姿态
Bi:Pi检测框的1/10
ki和kj:Pi和Pj的关节点坐标
ci和cj:Pi和Pj关节点的置信度
置信度消除原理是统计两个姿态关节点置信度相似的总个数,原理如图1-7所示:
1.根据置信度得分进行排序。
2.首先选择置信度最高的姿态Pi作为参考姿态,判断姿态Pj是否需要被消除。
3.如果关节点kj在Bi范围内,且此时两个关节点的置信度分数相似,则函数值是1,不相似函数值为1。
4.如果关节点kj不在Bi范围内,函数值为0
5.重复步骤3和4,对比姿态的17个关节点后,统计相似关节点的总数,如果超过五个,姿态Pj就会被消除
6.重复上述过程,直至检测框列表为空。
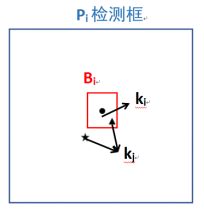
图 1-7 置信度消除
距离消除:消除位置相近的关节点。
下式用来计算两个姿态关节点的空间距离总和,选取置信度较高的姿态Pi,如果Pj姿态与Pi距离比较近,这说明两者重叠度较高,那么Pj就会被消除。

2.3.2parametric pose NMS参数化非极大值抑制代码详解
参数化非极大值抑制代码主要包含在pPose_NMS.py中。进行参数化非极大值抑制的函数pose_nms(),如代码清单2.3.2-1所示。
该函数有四个参数,它们的含义如下:
bboxes:检测框位置,大小为(n,4),n为图片中人体检测框个数,4=左上角(x,y)+右下角(x,y)。
bbox_scores:检测框置信度,(n,)。
pose_preds:姿态位置,(n,17,2),17表示人体的17个关节点。
pose_scores:关节点置信度,(n,17,1)。
def pose_nms(bboxes, bbox_scores, pose_preds, pose_scores):
pose_scores[pose_scores == 0] = 1e-5#如果姿态置信度为零,使姿态置信度相应位置值为1e-5,防止除数为零
final_result = []#用来存放最后结果
#复制原检测框置信度、姿态位置、关节点置信度
ori_bbox_scores = bbox_scores.clone()
ori_pose_preds = pose_preds.clone()
ori_pose_scores = pose_scores.clone()
#bboxes是两个点的坐标,左上角和右下角
xmax = bboxes[:, 2]
xmin = bboxes[:, 0]
ymax = bboxes[:, 3]
ymin = bboxes[:, 1]
widths = xmax - xmin#检测框宽
heights = ymax - ymin#检测框高
ref_dists = alpha * np.maximum(widths, heights)#高和宽进行比较,选择最大值,然后乘上0.1,是检测框的十分之一,ref_dists也就是Bi。
nsamples = bboxes.shape[0]#图片中有多少个人体检测框
human_scores = pose_scores.mean(dim=1)#将每个姿态中17个关节点的置信度取平均,就是该姿态的平均分
human_ids = np.arange(nsamples)#创建了一个列表,用来存放置信度最高分的索引
#开始进行参数化非极大值抑制
pick = []
merge_ids = []
while(human_scores.shape[0] != 0):
#选择置信度最高的姿态
pick_id = torch.argmax(human_scores)
pick.append(human_ids[pick_id])
ref_dist = ref_dists[human_ids[pick_id]]
simi = get_parametric_distance(pick_id, pose_preds, pose_scores, ref_dist)#两个姿态关键点的空间距离,相似度越大,值越小
num_match_keypoints = PCK_match(pose_preds[pick_id], pose_preds, ref_dist)#两个姿态关节点置信度相似的总数。
#清除冗余姿态
delete_ids = torch.from_numpy(np.arange(human_scores.shape[0]))[(simi > gamma) | (num_match_keypoints >= matchThreds)]
if delete_ids.shape[0] == 0:#如果要删除的id为空,则将原表中最高分的关节点删除
delete_ids = pick_id
merge_ids.append(human_ids[delete_ids])#将要删除的id存放在merge_ids.append
pose_preds = np.delete(pose_preds, delete_ids, axis=0)#删除冗余姿态,按行删除
pose_scores = np.delete(pose_scores, delete_ids, axis=0)
human_ids = np.delete(human_ids, delete_ids)
human_scores = np.delete(human_scores, delete_ids, axis=0)
bbox_scores = np.delete(bbox_scores, delete_ids, axis=0)
#如果选出的姿态和要删除的姿态一样,那就将原始信息保留
assert len(merge_ids) == len(pick)
preds_pick = ori_pose_preds[pick]
scores_pick = ori_pose_scores[pick]
bbox_scores_pick = ori_bbox_scores[pick]
for j in range(len(pick)):
ids = np.arange(17)
max_score = torch.max(scores_pick[j, ids, 0])
if max_score < scoreThreds:#分数小于阈值不做处理
continue
#合并姿态
merge_id = merge_ids[j]
merge_pose, merge_score = p_merge_fast(preds_pick[j], ori_pose_preds[merge_id], ori_pose_scores[merge_id], ref_dists[pick[j]])
max_score = torch.max(merge_score[ids])
if max_score < scoreThreds:
continue
xmax = max(merge_pose[:, 0])
xmin = min(merge_pose[:, 0])
ymax = max(merge_pose[:, 1])
ymin = min(merge_pose[:, 1])
if (1.5 ** 2 * (xmax - xmin) * (ymax - ymin) < areaThres):
continue
final_result.append({
'keypoints': merge_pose - 0.3,
'kp_score': merge_score,
'proposal_score': torch.mean(merge_score) + bbox_scores_pick[j] + 1.25 * max(merge_score)
})
return final_result
2.4:PGPG姿态引导区域框生成器
2.4.1含义
对于Alphapose,适当的数据增强有助于训练SSTN+SPPE模块,一种增强方法是在训练阶段使用检测出来的人体检测框,但是由于在进行目标检测只能生成一个人体检测框,所以STN+SPPE模块得不到充分训练,因此需要PGPG进行数据增强。
数据集图片中的每个人都有一个标签检测框,这些图片经过目标检测器,每个人都会产生一个预测框,我们的目的是尽可能让预测框和标签框重合,但实际情况是预测框总会或多或少的偏离标签框,我们的SSTN+SPPE模块就是针对偏移较大的预测框进行矫正,如果想训练SSTN+SPPE模块,我们就需要大量的预测框,我们可以模拟预测框的偏移生成大量的预测框,这样就可以训练SSTN+SPPE模块。但是不同姿态的检测框和标签检测框之间的偏移量分布是不同的,例如躺着和站着是两种姿态,它们的偏移量分布是不同的。Alphapose用P(δB|atom§)表示原子姿态P的偏移量分布,atom§是原子姿态(代表一个种类的姿态,通过聚类获得),原子姿态的含义可以这样理解,在一张图片里有两个人都是站立的姿态,但一个是大人,一个是小朋友,他们两者的高度和宽度有很大区别,但他们的原子姿态是一样的(都是站立姿态)。
计算每个原子姿态预测框的偏移量,将这些偏移量与标签框进行归一化处理后,原子姿态偏移量会形成一个频率分布,将频率分布拟合成高斯混合分布。就得到了不同原子姿态的高斯混合分布。根据这些高斯分布,生成大量预测框,就可以训练SSTN+SPPE模块。
2.4.2 PGPG姿态引导区域框生成器代码详解
PGPG姿态引导区域框生成器代码主要包含在train_sppe\src\utils\dataset\coco.py中,生成预测框的函数,如代码清单2.4.2-1所示。
generateSampleBox()的参数:
img_path:图片路径
bndbox:检测框
part:关节
nJoints:节点数
imgset:图片集合
scale_factor:转换因子
dataset:数据集
train=True:训练集
nJoints_coco=17:coco数据集关节点为17个
def generateSampleBox(img_path, bndbox, part, nJoints, imgset, scale_factor, dataset, train=True, nJoints_coco=17):
img = load_image(img_path)#加载图片
if train:
img[0].mul_(random.uniform(0.7, 1.3)).clamp_(0, 1)
img[1].mul_(random.uniform(0.7, 1.3)).clamp_(0, 1)
img[2].mul_(random.uniform(0.7, 1.3)).clamp_(0, 1)
img[0].add_(-0.406)
img[1].add_(-0.457)
img[2].add_(-0.480)
#生成检测框的左上角和右下角坐标
upLeft = torch.Tensor((int(bndbox[0][0]), int(bndbox[0][1])))
bottomRight = torch.Tensor((int(bndbox[0][2]), int(bndbox[0][3])))
#检测框的高和宽
ht = bottomRight[1] - upLeft[1]
width = bottomRight[0] - upLeft[0]
#图像的高和宽
imght = img.shape[1]
imgwidth = img.shape[2]
scaleRate = random.uniform(*scale_factor)
#对预测框进行偏移
upLeft[0] = max(0, upLeft[0] - width * scaleRate / 2)
upLeft[1] = max(0, upLeft[1] - ht * scaleRate / 2)
bottomRight[0] = min(imgwidth - 1, bottomRight[0] + width * scaleRate / 2)
bottomRight[1] = min(imght - 1, bottomRight[1] + ht * scaleRate / 2)
#利用姿态引导区域框生成器随机生成预测框
if opt.addDPG:
PatchScale = random.uniform(0, 1)#PatchScale是0到1的随机数
if PatchScale > 0.85:#根据PatchScale判断是否执行下面的代码
ratio = ht / width
if (width < ht):
patchWidth = PatchScale * width
patchHt = patchWidth * ratio
else:
patchHt = PatchScale * ht
patchWidth = patchHt / ratio
#利用刚才生成的偏移量生成新的预测框
xmin = upLeft[0] + random.uniform(0, 1) * (width - patchWidth)
ymin = upLeft[1] + random.uniform(0, 1) * (ht - patchHt)
xmax = xmin + patchWidth + 1
ymax = ymin + patchHt + 1
else:
xmin = max(
1, min(upLeft[0] + np.random.normal(-0.0142, 0.1158) * width, imgwidth - 3))
ymin = max(
1, min(upLeft[1] + np.random.normal(0.0043, 0.068) * ht, imght - 3))
xmax = min(max(
xmin + 2, bottomRight[0] + np.random.normal(0.0154, 0.1337) * width), imgwidth - 3)
ymax = min(
max(ymin + 2, bottomRight[1] + np.random.normal(-0.0013, 0.0711) * ht), imght - 3)
upLeft[0] = xmin
upLeft[1] = ymin
bottomRight[0] = xmax
bottomRight[1] = ymax
# 计算关节点数量
jointNum = 0
if imgset == 'coco':
for i in range(17):
if part[i][0] > 0 and part[i][0] > upLeft[0] and part[i][1] > upLeft[1] \
and part[i][0] < bottomRight[0] and part[i][1] < bottomRight[1]:
jointNum += 1
#随机裁剪
if opt.addDPG:
if jointNum > 13 and train:
switch = random.uniform(0, 1)
if switch > 0.96:
bottomRight[0] = (upLeft[0] + bottomRight[0]) / 2
bottomRight[1] = (upLeft[1] + bottomRight[1]) / 2
elif switch > 0.92:
upLeft[0] = (upLeft[0] + bottomRight[0]) / 2
bottomRight[1] = (upLeft[1] + bottomRight[1]) / 2
elif switch > 0.88:
upLeft[1] = (upLeft[1] + bottomRight[1]) / 2
bottomRight[0] = (upLeft[0] + bottomRight[0]) / 2
elif switch > 0.84:
upLeft[0] = (upLeft[0] + bottomRight[0]) / 2
upLeft[1] = (upLeft[1] + bottomRight[1]) / 2
elif switch > 0.80:
bottomRight[0] = (upLeft[0] + bottomRight[0]) / 2
elif switch > 0.76:
upLeft[0] = (upLeft[0] + bottomRight[0]) / 2
elif switch > 0.72:
bottomRight[1] = (upLeft[1] + bottomRight[1]) / 2
elif switch > 0.68:
upLeft[1] = (upLeft[1] + bottomRight[1]) / 2
inputResH, inputResW = opt.inputResH, opt.inputResW#输入图片大小320*256
outputResH, outputResW = opt.outputResH, opt.outputResW#输出图片大小80*64
inp = cropBox(img, upLeft, bottomRight, inputResH, inputResW)#对图片进行裁剪
if jointNum == 0:
inp = torch.zeros(3, inputResH, inputResW)
out = torch.zeros(nJoints, outputResH, outputResW)
setMask = torch.zeros(nJoints, outputResH, outputResW)
# Draw Label
if imgset == 'coco':
for i in range(nJoints_coco):
if part[i][0] > 0 and part[i][0] > upLeft[0] and part[i][1] > upLeft[1] \
and part[i][0] < bottomRight[0] and part[i][1] < bottomRight[1]:
hm_part = transformBox(
part[i], upLeft, bottomRight, inputResH, inputResW, outputResH, outputResW)#改变检测框位置
out[i] = drawGaussian(out[i], hm_part, opt.hmGauss)#画出热图
setMask[i].add_(1)
if train:
# Flip
if random.uniform(0, 1) < 0.5:
inp = flip(inp)
out = shuffleLR(flip(out), dataset)
#旋转
r = rnd(opt.rotate)
if random.uniform(0, 1) < 0.6:
r = 0
if r != 0:
inp = cv_rotate(inp, r, opt.inputResW, opt.inputResH)
out = cv_rotate(out, r, opt.outputResW, opt.outputResH)
return inp, out, setMask