AlphaPose人体姿态识别之json文件解读
AlphaPose的json文件解读
本文记录下res的json文件坐标系以及一些参数的意思,有不足之处望指正。
待解读例子:
例如有如下json文件
[{"image_id": "1.jpg",
"category_id": 1,
"keypoints": [
654.6572265625, 88.31778717041016, 0.9614965915679932,
659.4932861328125, 78.64559173583984,0.9357421398162842,
644.9849853515625, 78.64559173583984, 0.9556339383125305,
674.0015869140625, 93.15389251708984, 0.949504554271698,
630.4766845703125, 88.31778717041016, 0.9443892240524292,
688.5099487304688, 51.18710327148438, 0.9699893593788147,
606.2962036132812, 146.3509979248047, 0.9314674735069275,
698.18212890625, 223.72862243652344, 0.9512142539024353,
591.7879028320312, 223.72862243652344, 244388937950134,
698.18212890625, 286.5979309082031, 0.9363806247711182,
586.9517822265625, 291.4340515136719, 0.9267269968986511,
664.3294067382812, 296.2701416015625, 0.8407283425331116,
611.13232421875, 296.2701416015625, 0.8530831933021545,
654.6572265625, 397.8282775878906, 0.9324217438697815,
615.9683837890625, 392.9921569824219, 0.8931402564048767,
644.9849853515625, 489.7142028808594, 0.891362190246582,
620.8045043945312, 489.7142028808594, 0.8250412940979004],
"score": 3.1222591400146484,
"box": [568.2610473632812, 41.407630920410156, 148.61181640625, 495.2166976928711],
"idx": [0.0]},
解读结果:
python代码
"image_id" : int, # 该对象所在图片的id
"category_id" : int, # 类别id,每个对象对应一个类别
"keypoints" : [x1,y1,v1,...], #keypoints是一个长度为3*k的数组,其中k是category中keypoints的总数量
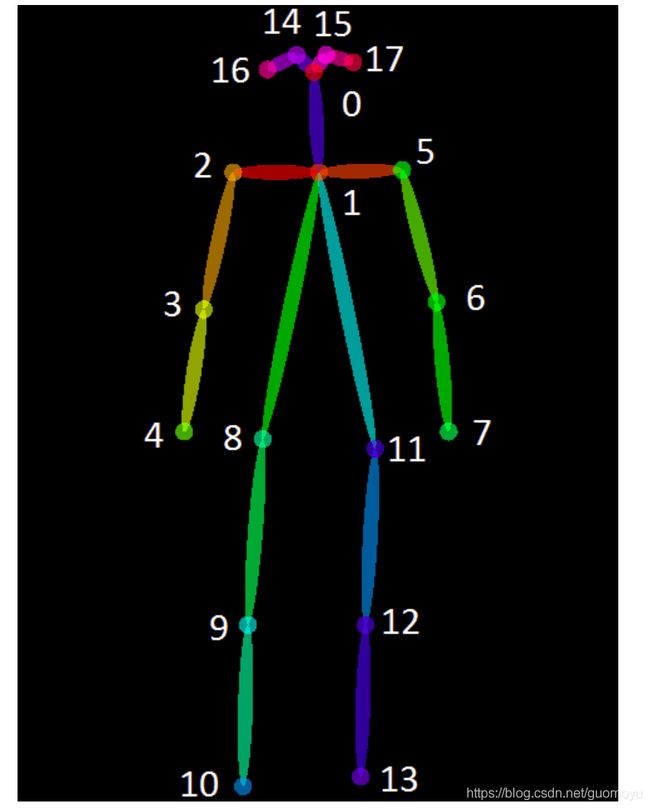
(也就是说k是类别定义的关键点总数,如图我们实验的人体姿态关键点的k为17,所以获得的keypoints总数为51)。
每一个keypoint是一个长度为3的数组,第一和第二个元素分别是x和y坐标值,第三个元素是个标志位v。
"score" : int,# 置信度 (一改)
"box" : [x,y,width,height], # x,y为左上角坐标,width,height为框的宽高
"idx" : [0.0]
##打印关键点编号:
cv2.circle(img, (cor_x, cor_y), 3, p_color[n], -1)
#cv2.circle()用于在任何图像上绘制圆。
#ima:所选的绘制圆的图像。
#(cor_x, cor_y):圆的中心坐标。坐标表示为两个值的元组,即(X坐标值,Y坐标值)。
#radius:3是圆的半径。
#p_color[n]:绘制的圆的边界线的颜色。对于BGR,我们通过一个元组。例如:(255,0,0)为蓝色。
#thickness:圆边界线的粗细像素。厚度-1像素将以指定的颜色填充矩形形状。
cv2.putText(img, f'{n}', (cor_x+5, cor_y+5), cv2.FONT_HERSHEY_PLAIN, 2, (255, 0, 0), thickness=1)
#cv2.putText()用于在任何图像上添加文字。
#上述参数分别对应:图片,添加的文字,左上角坐标,字体,字体大小,颜色,字体粗细
关键点分布图(一改):