PyTorch深度学习实践(十三)循环神经网络高级篇
用RNN做一个分类器,现在有一个数据集,数据集里有人名和对应的国家,我们需要训练一个模型,输入一个新的名字,模型能预测出是基于哪种语言的(18种不同的语言,18分类),
 在自然语言处理中,通常先把词或字编程一个one-hot向量,one-hot向量维度高,而且过于稀疏,所以
在自然语言处理中,通常先把词或字编程一个one-hot向量,one-hot向量维度高,而且过于稀疏,所以
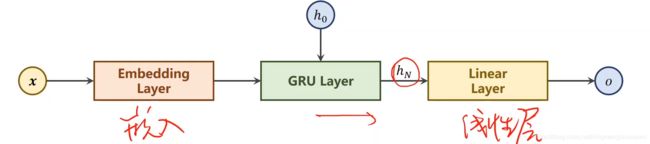
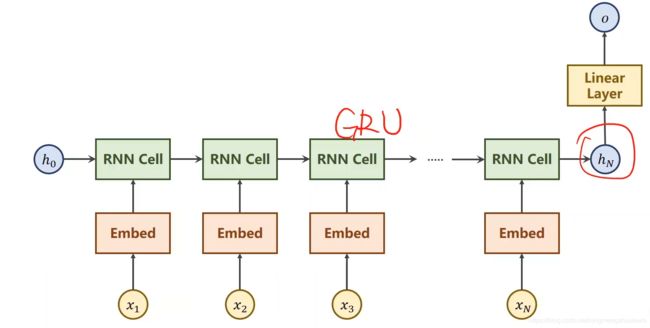
一般来说呀先通过嵌入层(Embed)把one-hot向量转化成低维的稠密向量,然后经过RNN,隐层的输出不一定和最终要求的目标一致,所以要用一个线性层把输出映射成和我们的要求一致,我们的需求是输出名字所属的语言分类,我们对01-05这些输出是没有要求的,即不需要对所有的隐层输出做线性变换,为了解决这个问题,我们可以把网络变得更简单,如下图
 输入向量经过嵌入层之后,输入到RNN,输出最终的隐层状态,最终的隐层状态经过一个线性层,我们分成18个类别,就可以实现名字分类的任务了
输入向量经过嵌入层之后,输入到RNN,输出最终的隐层状态,最终的隐层状态经过一个线性层,我们分成18个类别,就可以实现名字分类的任务了
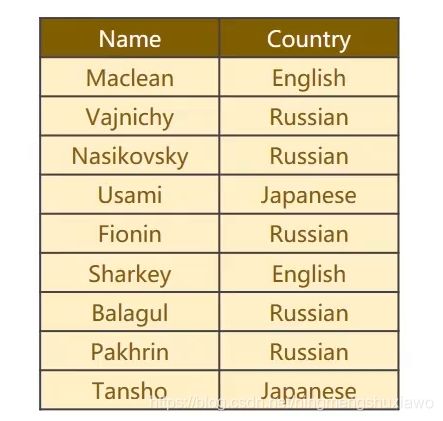 输入的每一个名字都是一个序列,序列的长短是不一样的
输入的每一个名字都是一个序列,序列的长短是不一样的
模型的处理过程
输入是数据集里面的名字,经过模型之后我们得到相应的国家
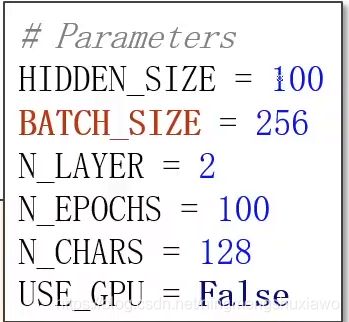
classifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER)
N_CHARS:字符数量(输入的是英文字母,每一个字符都要转变成独热向量,所以这是我们自己设置的字母表的大小)
HIDDEN_SIZE:隐层数量(GRU输出的隐层的维度)
N_COUNTRY:一共有多少个分类
N_LAYER:设置用基层的GRU
for epoch in range(1, N_EPOCHS + 1):
# Train cycle
trainModel()
acc = testModel()
acc_list.append(acc)
在每一个epoch做一次训练和测试,把测试的结果添加到 acc_list列表(可以用来绘图,可以看到训练的损失是如何变化的)
准备数据–定义模型–定义损失函数和优化器–写训练过程
准备数据
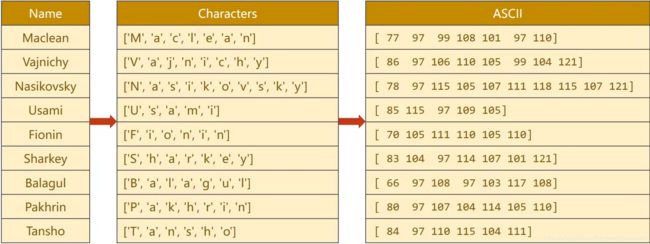
拿到的是字符串,先转变成序列,转成列表,列表里面的每一个数就是名字里面的每一个字符
 接下来做词典,可以用ASCII表,ASCII表是128个字符,我们把字典长度设置成128,求每一个字符对应的ASCII值,拼成我们想要的序列
接下来做词典,可以用ASCII表,ASCII表是128个字符,我们把字典长度设置成128,求每一个字符对应的ASCII值,拼成我们想要的序列
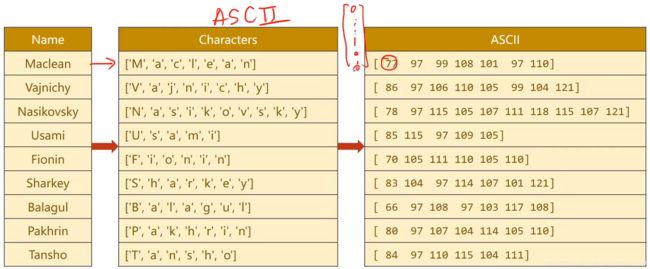 上图中的最右表中每一个数并不是一个数字,而是一个独热向量例如 77。就是一个128维的向量,第77个数的值为1,其他的值都是0.
上图中的最右表中每一个数并不是一个数字,而是一个独热向量例如 77。就是一个128维的向量,第77个数的值为1,其他的值都是0.
对于Embed(嵌入层)来说,只要告诉嵌入层第几个维度是1就行了,所以只需要把ASCII值放在这就行了。
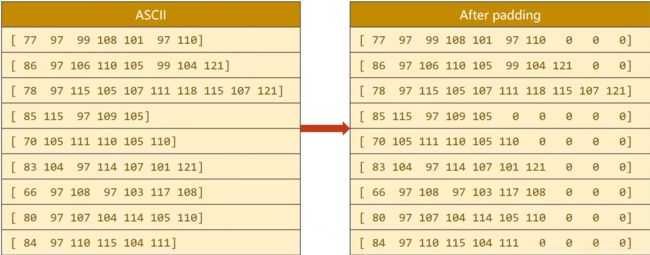
序列长短不一怎么解决?
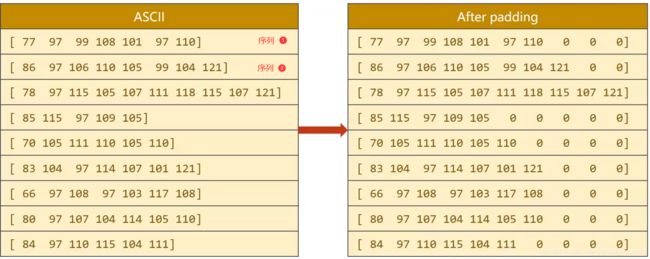 如上图左,每一行是一个序列,我们解决序列长短不一的方法是padding(因为张量必须保证所有的数据都贴满,不然就不是张量),如右图,就是在做一个batch的时候,我们看这一个batch里面哪一个字符串的长度最长,然后把其他字符串填充成和它一样的长度,就能保证可以构成一个张量,因为每个维度的数量不一样是没办法构成张量的
如上图左,每一行是一个序列,我们解决序列长短不一的方法是padding(因为张量必须保证所有的数据都贴满,不然就不是张量),如右图,就是在做一个batch的时候,我们看这一个batch里面哪一个字符串的长度最长,然后把其他字符串填充成和它一样的长度,就能保证可以构成一个张量,因为每个维度的数量不一样是没办法构成张量的
分类的处理
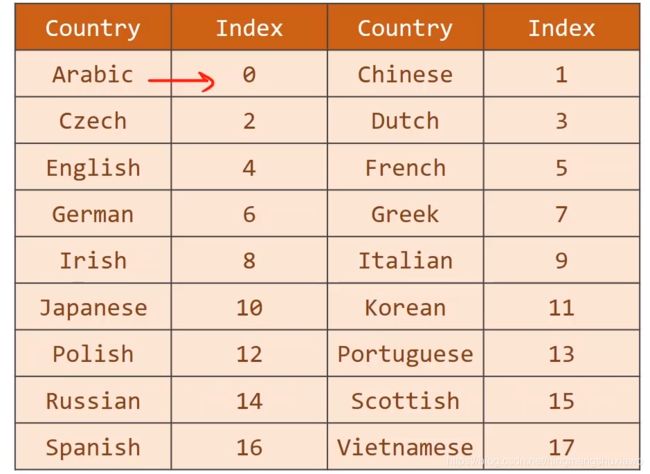
我们需要把各个分类(国家)转成一个分类索引,不嫩直接用字符串作为我们的分类标签
读取数据集
filename = 'data/names_train.csv.gz' if is_train_set else 'data/names_test.csv.gz' with gzip.open(filename, 'rt') as f:
reader = csv.reader(f)
rows = list(reader) #一个元组
Reading data from .gz file with package gzip and csv . gzip和csv这两个包可以帮我们读取gz文件
有很多种不同的方式可以访问数据集,比如有些数据集不是.gz,而是.pickle就可以用pickle包,还有HDFS,HD5得用HDFS的包读取,根据拿到的数据类型不一样,用相应的包把数据读出来。
我们读到的rows是一个元组,形式是(name,language)
self.names = [row[0] for row in rows] #先把名字都取出来
self.len = len(self.names) #记录样本数量
self.countries = [row[1] for row in rows]#把标签取出来
self.country_list = list(sorted(set(self.countries)))#set是先把列表变成集合,即去除重复的元素,
#这样每一个语言就只剩下一个实例,然后用sorted排序变成列表(如上图)
self.country_dict = self.getCountryDict() #根据列表,把列表转变成词典
def __getitem__(self, index):
return self.names[index], self.country_dict[self.countries[index]]
#__getitem__根据输入的名字找到对应国家的索引
#返回两项,一项是输入样本
#拿到输入样本之后,先把国家取出来,然后根据国家去查找对应的索引
def getCountryDict(self):
country_dict = dict()
for idx, country_name in enumerate(self.country_list, 0):
country_dict[country_name] = idx
return country_dict
数据准备
trainset = NameDataset(is_train_set=True)
trainloader = DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True)
testset = NameDataset(is_train_set=False)
testloader = DataLoader(testset, batch_size=BATCH_SIZE, shuffle=False)
N_COUNTRY = trainset.getCountriesNum()
模型设计
class RNNClassifier(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layers=1, bidirectional=True): super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.n_directions = 2 if bidirectional else 1
self.embedding = torch.nn.Embedding(input_size, hidden_size)
self.gru = torch.nn.GRU(hidden_size, hidden_size, n_layers, bidirectional=bidirectional) self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size)
def _init_hidden(self, batch_size):
hidden = torch.zeros(self.n_layers * self.n_directions, batch_size, self.hidden_size) return create_tensor(hidden)
__init__函数的参数
input_size用于构建嵌入层

双向循环神经网络
lstm gru rnn 都有双向的
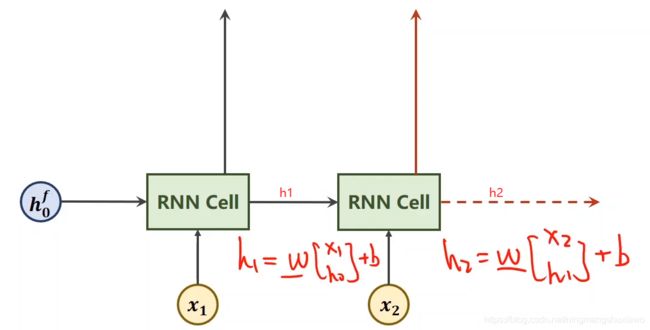
下图是单向的RNN,其中 RNN Cell共享权重和偏置,所以w和b是一样的,Xn-1的输出只包含它之前的序列的信息,即只考虑过去的信息,实际上在自然语言处理(NLP)我们还需要考虑来自未来的信息
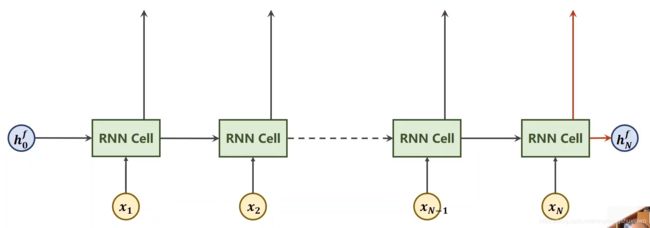 正向算完之后,再反向算一下,然后把算出来的隐层输出做拼接,如下图 hN是h(0,b)和h(N,f)拼接起来的,h(N-1)是把h(1,b)和h(N-1,f)拼接起来,这样的循环神经网络叫双向循环神经网络
正向算完之后,再反向算一下,然后把算出来的隐层输出做拼接,如下图 hN是h(0,b)和h(N,f)拼接起来的,h(N-1)是把h(1,b)和h(N-1,f)拼接起来,这样的循环神经网络叫双向循环神经网络
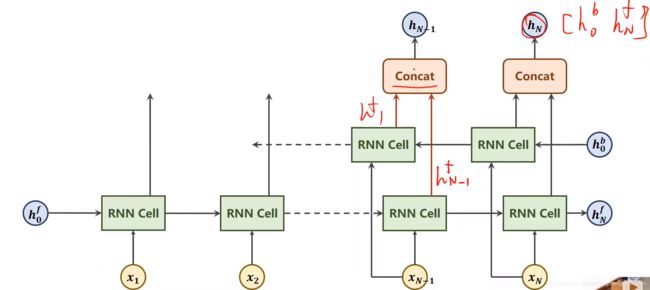 最终,反向得到一个h(N,b)
最终,反向得到一个h(N,b)
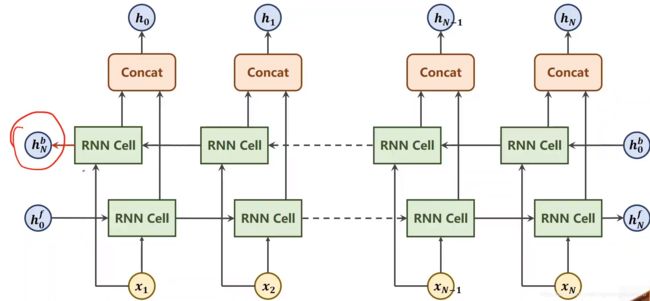
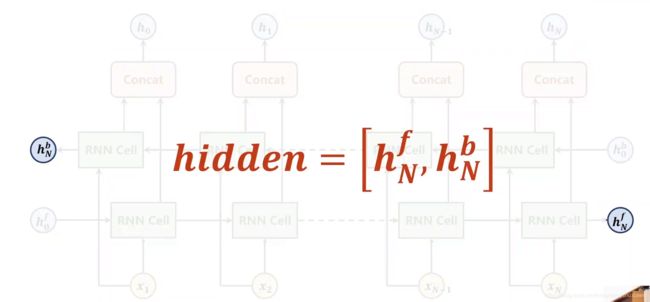
每一次调用GRU会输出out和hidden两个项,其中hidden包含的项如下
self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size)
%在线性层的时候要把hidden_size转换成输出的维度,所以要乘以一个self.n_directions,
%双向RNN的self.n_directions是2,单向RNN是1
def _init_hidden(self, batch_size):
hidden = torch.zeros(self.n_layers * self.n_directions, batch_size, self.hidden_size)
return create_tensor(hidden)
%_init_hidden的作用是创建一个全0的初始隐层,根据输入的batch_size构建全0的张量,
张量的第一个维度是n_layers * self.n_directions,第二个维度是 batch_size,第三个维度是self.hidden_size
%这是一个工具函数,训练的时候可以调用
双向循环神经网络的forward过程
def forward(self, input, seq_lengths):
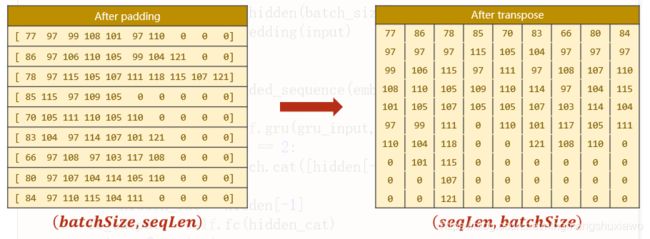
# input shape : B x S - > S x B(S:sequential(序列),B:batch)
input = input.t() %矩阵转置input shape : B x S - > S x B
batch_size = input.size(1) %保存batch_size用来构建最初始的隐层
hidden = self._init_hidden(batch_size) %创建隐层
embedding = self.embedding(input) %把input扔到嵌入层里面,做嵌入
%嵌入之后,输入的维度就变成了(,ℎ,ℎ)
# pack them up
gru_input = pack_padded_sequence(embedding, seq_lengths)
output, hidden = self.gru(gru_input, hidden) %第二个hidden是初始的隐层,
%我们想要得到的是第一个hidden的值
if self.n_directions == 2:
hidden_cat = torch.cat([hidden[-1], hidden[-2]], dim=1)
%如果是双向的循环神经网络,会有两个hidden,需要把他们拼接起来
else:
hidden_cat = hidden[-1] %如果是单向的循环神经网络,就只有1个hidden
fc_output = self.fc(hidden_cat) %把最后的隐层输出经过全连接层变换成我们想要的维度做分类
return fc_output
input = input.t()%矩阵转置input shape : B x S - > S x B
%功能如下图
embedding = self.embedding(input) %把input扔到嵌入层里面,做嵌入
%嵌入之后,输入的维度就变成了(,ℎ,ℎ)
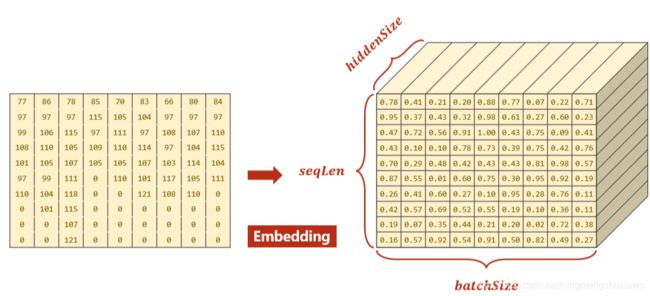 为了提高运行效率,GRU支持一种提速,尤其是面对序列长短不一的时候,在pyTorch中, pack_padded_sequence的功能如下
为了提高运行效率,GRU支持一种提速,尤其是面对序列长短不一的时候,在pyTorch中, pack_padded_sequence的功能如下
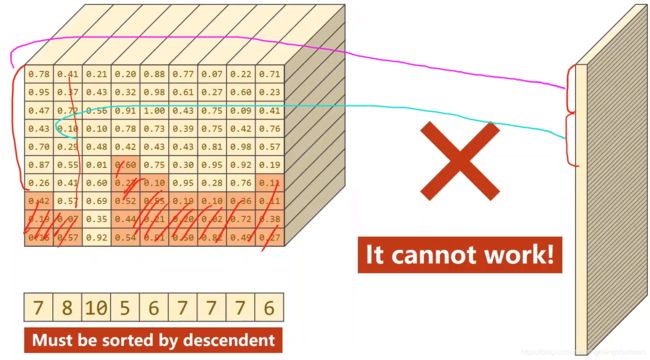 先根据长度排序
先根据长度排序
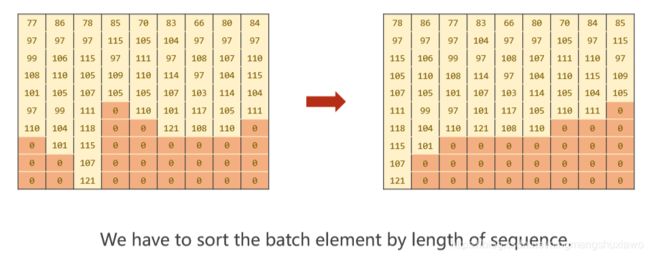 排好序之后,再经过嵌入层
排好序之后,再经过嵌入层
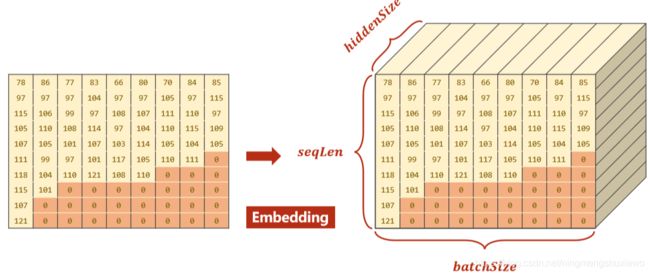 使用pack_padded_sequence做成下面这样的数据,GRU的运算效率更高哦(即把没有计算意义的padding 0去掉)
使用pack_padded_sequence做成下面这样的数据,GRU的运算效率更高哦(即把没有计算意义的padding 0去掉)
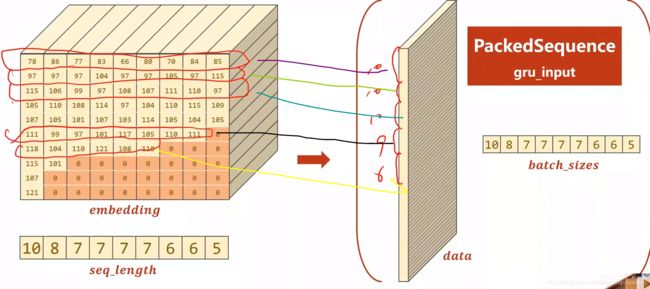 所以pack_padded_sequenceh函数需要输入数据的长度 seq_lengths
所以pack_padded_sequenceh函数需要输入数据的长度 seq_lengths
gru_input = pack_padded_sequence(embedding, seq_lengths)
GRU根据上图的batch_sizes就决定每一时刻取多少行,GRU的工作效率就提高了
由名字转换成Tensor的过程
 过程如下:
过程如下:
1:字符串—>字符—>相应的ASCII值
 然后做padding填充
然后做padding填充
 填充之后转置
填充之后转置
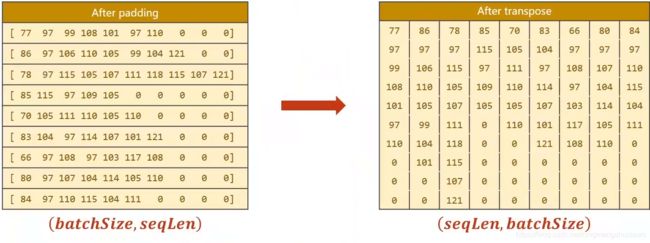 转置之后排序
转置之后排序

def make_tensors(names, countries):
sequences_and_lengths = [name2list(name) for name in names]
%name2list(name)把每一个名字都变成一个ASCII列表
name_sequences = [sl[0] for sl in sequences_and_lengths]
%单独拿出列表
seq_lengths = torch.LongTensor([sl[1] for sl in sequences_and_lengths])
%单独拿出列表长度,并转换成LongTensor
countries = countries.long()
%countries本身就是一个整数,我们再转换成long张量
# make tensor of name, BatchSize x SeqLen
seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long()
for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_lengths), 0):
seq_tensor[idx, :seq_len] = torch.LongTensor(seq)
# sort by length to use pack_padded_sequence
seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True)
seq_tensor = seq_tensor[perm_idx]
countries = countries[perm_idx]
return create_tensor(seq_tensor), \
create_tensor(seq_lengths),\
create_tensor(countries)
def name2list(name):
arr = [ord(c) for c in name]
return arr, len(arr)
%name2list返回两个,一个是元组,代表列表本身,一个是列表的长度
name_sequences = [sl[0] for sl in sequences_and_lengths]
%单独拿出列表
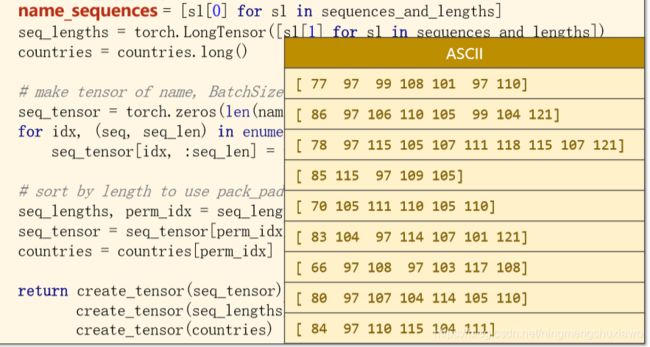
# make tensor of name, BatchSize x SeqLen
seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long()
for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_lengths), 0):
seq_tensor[idx, :seq_len] = torch.LongTensor(seq)
我们是先构建了一个全0的张量,然后把值复制进去

# sort by length to use pack_padded_sequence
seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True)
seq_tensor = seq_tensor[perm_idx]
countries = countries[perm_idx]
按照序列的长度进行排序,pyTorch的sort函数返回两个值,一个是排完序后的序列,另一个是么排完序之后对应元素的id(索引),我们可以根据这个索引,对序列的张量以及国家标签进行排序

return create_tensor(seq_tensor), \
create_tensor(seq_lengths),\
create_tensor(countries)
def create_tensor(tensor):
if USE_GPU:
device = torch.device("cuda:0")
tensor = tensor.to(device)
return tensor
接下来把需要的序列的张量,每一个序列的长度,标签都转化成一个Tensor
create_tensor主要是判定是否需要使用GPU,要用GPU的haul就把Tensor放到Cuda上,否则就不做任何操作
训练过程
训练:1 前向:计算模型输出-----计算损失–梯度清零—反向传播—更新梯度
测试模型:测试模型是不需要求梯度的
with torch.no_grad():