catalogue
1. 特征工程是什么?有什么作用?
2. 特征获取方案 - 如何获取这些特征?
3. 特征观察 - 运用各种统计工具、图标等工具帮助我们从直观和精确层面认识特征中的概率分布
4. 特征处理 - 特征清洗
5. 特征护理 - 特征预处理
6. 特征处理 - 特征选择
7. 特征监控
1. 特征工程是什么?有什么作用?
从某种程度上来说,数据和特征决定了机器学习的上限,而模型和算法能做的只是逼近这个上限。特征工程本质上是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用
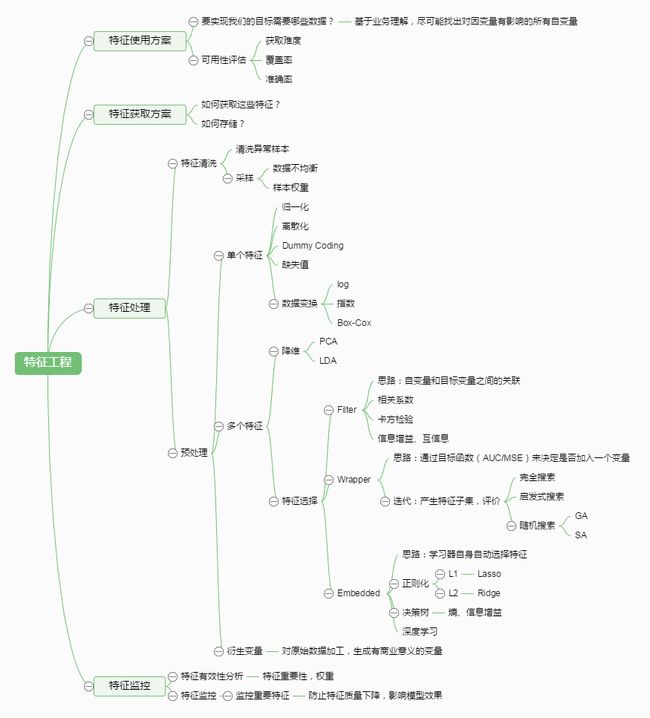
我们本章围绕该xmin思维导图展开讨论
Relevant Link:
http://www.cnblogs.com/jasonfreak/p/5448385.html
http://weibo.com/ttarticle/p/show?id=2309403973170330790744
2. 特征获取方案 - 如何获取这些特征?
0x1: 结合具体业务场景从原始日志中提取特征 - 结合业务!业务!业务!
在大部分时候我们从产品中得到的原始日志都不能直接进行数据挖掘,我们需要进行特征提取,但特征提取也不能简单的直接就粗暴地分为数字型/文本型/序列型等等,这一步的思考非常重要,我们需要明确我们的业务场景细节,以及业务目标
以暴力破解识别为具体场景我们展开讨论:
1. 我们的日志从哪里来?是什么形式的?
对于网络层面的数据,我们的原始日志常常是Gateway网络采集的原始五元组数据,包含
session_time: '会话发生时间'
src_ip: '源IP'
src_port: '源端口'
dst_ip: '目的IP'
dst_port: '目的端口'
样本的形式是字符串型的,但是要注意到的五元组单条日志本身是不包含"异常特征"规律的,也即规律不在原始日志本身,而在于多条原始日志内的统计分布规律,只有将原始日志进行良好的聚合才能将包含爆破特征的规律暴露出来
2. 从攻防业务角度初步观测暴力破解的规律特征是怎样的?
我们将发起暴力破解的机器设定为攻击者(不管是主动行为还是被入侵后沦为肉鸡的情况),从攻击者角度看暴力破解有2种方式:
1. 针对单点目标的深度破解;
2. 针对大范围(常常是B/C段)目标的广度破解;
思考清楚了这2点,可以指导我们在观测样本数据的时候抓住哪些重点,即观察发生爆破安全事件的时候,有哪些样本日志含有广度特征,有哪些样本日志含有深度特征。特征提取分析的第一步是要在了解业务场景的前提下观察样本数据的特征分布,这一步前期调研很重要,它可以帮助我们判断后续用什么模型进行抽象建模,用什么算法进行计算
我们以暴力破解广度扫描为例观测一组存在异常事件的服务器和一台不存在安全事件的服务器,在一天中按照30min为原子时间窗口进行切分, 在初始阶段,我们还不能非常好的定义我们的特征提取范围,根据业务的理解直觉,我们先尝试用最简单的【src_ip;dst_port;protocal(协议)】三元组进行时间窗口区间内的发包频率和攻击目标dst_ip的广度统计,来获取样本数据整体上的特征分布判断
src_ip,proto,dst_port,dst_ip_cn,send_cn,timeindex
106.14.xxx.xx,tcp,22,7012,7012,3
106.14.xxx.xx,udp,65500,8,8,3
106.14.xxx.xx,udp,65500,4,4,4
106.14.xxx.xx,tcp,80,1,1,0
106.14.xxx.xx,tcp,80,6,6,3
106.14.xxx.xx,tcp,80,82,82,4
106.14.xxx.xx,tcp,80,1,1,10
106.14.xxx.xx,tcp,80,1,1,14
106.14.xxx.xx,tcp,80,2,2,16
106.14.xxx.xx,tcp,80,1,1,18
106.14.xxx.xx,tcp,80,1,1,19
106.14.xxx.xx,tcp,80,1,1,31
106.14.xxx.xx,tcp,80,1,1,33
106.14.xxx.xx,tcp,80,1,1,34
106.14.xxx.xx,tcp,9183,1,1,42
这该ip的全天五元组日志中,我们已知该机器当前发生了:22端口暴力扫描行为,可以看到存在异常的样本聚合后,特征比较明显,即在较短的时间窗口内产生大量对外发包频率,以及对较多的dst_ip发起发包行为。而该服务器其他的正常通信行为则呈现出少且均匀的对外发包曲线
我们挑选一个不存在异常行为的服务器进行频次聚合统计
src_ip,proto,dst_port,dst_ip_cn,send_cn,timeindex
114.215.175.203,tcp,22,1,1,29
114.215.175.203,tcp,443,2,2,0
由此证实了我们的猜想,暴力破解的特征提取要从发包频次和攻击目标dst_ip广度重点入手
0x2: 定义特征模型,我们该从原始日志样本中抽取哪些特征?
对于这个问题,有一个专门的研究分支叫"feature selection(特征选择)",似乎可以先将所有能想到的特征都抽出来,然后用例如相关性分析、信息增益、互信息这些评价指标来选择对算法模型分类效果最好的一系列特征。但我个人认为,特征选择和提取的最好人选还是熟悉业务的人来完成,这个过程可以说是非常依赖经验的参与,我们要在理解业务背景的基础上,将人的判别经验沉淀为需要提取的特征
以暴力破解为例,我们来尝试定义出一组样本特征(对每30min时间区间内的所有原始日志按照不同的维度进行聚合)
广度暴力破解特征
1. proto:协议类型(tcp、udp):不同的网络协议可能导致我们之后要为每个协议单独建模,但是也有可能在一个模型中同学拟合2个协议样本集的特征
2. dst_port:目标端口,代表了目标主机的网络服务类型,从业务经验上看,对22这种sshd服务端口发起的密集发包行为比对一个非常用端口发起的密集发包更倾向于在暴力破解,我们抽取这个特征的目的是需要模型尽量学习到不同的dst_port目的端口(代表了不同的服务)对判断结果的权重是不一样的
3. count(相同 dst_port):在一个时间统计窗口内和当前连接具有相同服务(不管dst_ip是否相同)的发包频数,这个特征体现了暴力破解攻击的强度
4. count(distinct dst_ip 去重):在一个时间统计窗口内攻击的目标主机的个数,这个特征体现了广度暴力破解攻击的范围广度
5. max(session_time) - min(session_time):在一个时间统计窗口内和当前连接具有相同服务的攻击包,第一个发包时间和最后一个发包时间的间隔,该特征越接近于时间窗口大小,表明攻击的持续性越强
深度暴力破解特征
1. proto:协议类型(tcp、udp):不同的网络协议可能导致我们之后要为每个协议单独建模,但是也有可能在一个模型中同学拟合2个协议样本集的特征
2. count(相同 dst_ip):在一个时间统计窗口内和当前连接具有相同目标主机(不论dst_port是否相同)的发包频数,这个特征体现了暴力破解攻击的强度
3. count(distinct dst_port 去重):在一个时间统计窗口内攻击同一个目标主机的服务端口的个数,这个特征体现了深度暴力破解攻击的范围
4. max(session_time) - min(session_time):在一个时间统计窗口内和当前连接具有相同目标主机的攻击包,第一个发包时间和最后一个发包时间的间隔,该特征越接近于时间窗口大小,表明攻击的持续性越强
关于聚合的time windows的长度,读者也需要根据具体的业务场景仔细思考,对于暴力破解来说,爆破事件的特征规律是包含在一个时间窗口内的频率统计特征,但是对每个安全事件而言,攻击的持续时间是不同的,这就导致每个样本的length是变长的,我们需要对日级别的时间区间统计特征进行定长的切分,例如:按照30min为一个原子时间窗口,将样本集中在这个time windows内的所有原始日志聚合成单条特征向量(具体情况视原始数据采样能力和算法模型而定)
Relevant Link:
https://mp.weixin.qq.com/s?__biz=MzA5NzkxMzg1Nw==&mid=2653159305&idx=1&sn=077410cb7d95af0c343a13dbbd4e53fc&mpshare=1&scene=1&srcid=0510gYeDGwNdlniGYhamMGjn#wechat_redirect
3. 特征观察 - 运用各种统计工具、图标等工具帮助我们从直观和精确层面认识特征中的概率分布
拿到样本特征之后,我们可能需要做的是观察样本的特征概率分布、是否包含异常/离群点、空间分布上大致分为几个族群等
0x1: 直方图统计法
直方图是在图像处理上很常见也很有效的方法,它可以认为是图像灰度密度函数的近似。直方图虽然不能直接反映出图像内容,但对它进行分析可以得出图像的一些有用特征,这些特征能反映出图像的特点。例如:当图像对比度较小时,它的灰度直方图只在灰度轴上较小的一段区间上非零
1. 较暗的图像由于较多的像素灰度值低,因此它的直方图的主体出现在低值灰度区间上,其在高值灰度区间上的幅度较小或为零
2. 而较亮的图像情况正好相反
为使图像变清晰,可以通过变换使图像的灰度动态范围变大,并且让灰度频率较小的灰度级经变换后,其频率变得大一些,使变换后的图像灰度直方图在较大的动态范围内趋于均化。同样,区分度(对比度)这个概念也同样适用于非图像分类领域,在直方图上低频区间和高频区间的间隔越大,对于分类器的训练越容易
下面是kdd99的特征直方图

从直方图上我们可以得出一个大致的判断,特征选取(feature selection)要尽量选择在直方图区间上分布较离散的特征(在分类问题场景中)
0x2: 经验概率密度图
经典统计推断主要的思想就是用样本来推断总体的状态,因为总体是未知的(即真实的规律是未知的),我们只能通过多次试验的样本(即实际值)来推断总体。经验分布函数是在这一思想下的一种方法,通过样本分布函数来估计总体的分布函数。
若已知概率分布函数F(x)或概率密度函数p(x),便能解决大部分统计推断的问题,但问题是概率分布函数F(x)未知,这本身就是我们希望通过算法推断出来的结果
为了解决这个问题,依泛函空间的大数定律得出:可通过该未知分布函数下的样本集{xi}构造的经验分布函数 依概率收敛去逼近F(x)。然后,通过积分方程: 的求解,得出概率密度函数p(x);
需要特别注意的,该积分方程的求解是一个不适定计算问题,需使用正则化技术才能较好处理。也就是最大似然估计中的 经验风险和 结构化风险
下面以KDD99样本集为例

可以看到,在这个特征的经验分布中,不同类型的样本集还是大致可分的,同时,在左边的mascan和netpture存在一个混淆区,在个该维度上基本不可分了,这会带来一定误报;同时在右边guess_passwd出现了一个小的波峰(peak mode),它可能代表了一些异常点样本点,可能暗示我们在进行后续的特征处理环节需要进行离群点过滤
0x3: 统计样本特征各个离散值的离散度、gini指数、信息增益
gini指数、信息增益都来自于香浓信息论中的混乱度的概念,值越大,体现当前样本的混乱度越大(区分度也越大)
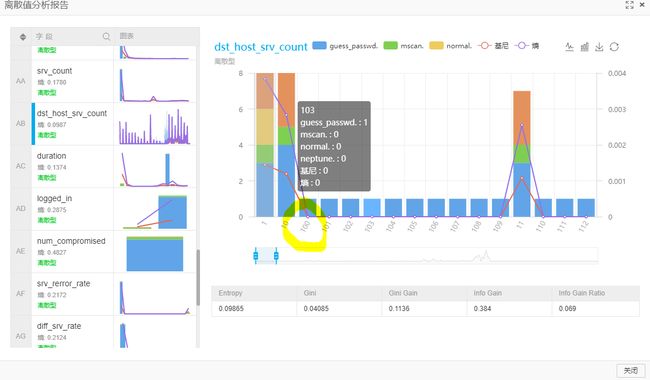
从图上可以看到,该特征离散值从0到100区间,gini指数逐渐下降,即指示如果用决策树或者其他分类器,分界线设定在这个区间内才能获得有效的信息增益
同时在100到109区间中,样本在这个区间内只有一个单一的类别,分界线不应该选取在这个区间中,因为不能进行任何有效分类
在109到101区间,样本在这个区间有有了不同的类别,即有一定的混乱度,特征分界面可以考虑在这个区间选取
0x4: Measures of Shape: Skewness and Kurtosis
Skewness 是描述数据分布是否对称的指标。越对称的分布,skewness越小。该指标可以暗示我们是否要进行特征标准化处理
Kurtosis 是用来描述数据是否heavy tail,如果一个分布异常点很多或者很长尾,那么其kurtosis也越大。该指标可以用于评估在该特征维度上离群样本的密度 结合直方图,可以很好解释这两个指标的意义


Relevant Link:
https://brownmath.com/stat/shape.htm
4. 特征处理 - 特征清洗
通过理解业务场景,深入观察样本数据后,我们建立了初步的特征模型,并据此抽取出了一些训练样本,但此时还不能盲目直接进入算法建模,我们还需要继续深入观察样本,思考其中是否包含了异常离群数据、是否需要进行无量纲化处理?
0x1: 清洗异常样本
日志数据中可能存在对挖掘无用的噪音数据或者由于系统异常出现的异常样本数据,这需要我们结合业务情况和专家领域知识进行清洗过滤
除了结合业务经验之外,还可以采用异常点检测算法对样本进行分析,常用的异常点检测算法包括
1. 偏差检测:例如
1) 聚类
2) 最近邻等
2. 基于统计的异常点检测算法:这种方法适合于挖掘单变量的数值型数据,常用的方法有
1) 极差(又称全距(Range)):是用来表示统计资料中的变异量数(measures of variation) ,其最大值与最小值之间的差距
2) 四分位数间距:四分位距通常是用来构建箱形图,以及对概率分布的简要图表概述
3) 均差
4) 标准差等
3. 基于距离的异常点检测算法,主要通过距离方法来检测异常点,将数据集中与大多数点之间距离大于某个阈值的点视为异常点,主要使用的距离度量方法有
1) 绝对距离(曼哈顿距离)
2) 欧氏距离
3) 马氏距离等方法。
4. 基于密度的异常点检测算法,考察当前点周围密度,可以发现局部异常点,例如LOF算法
暴力破解场景中不存在本身是正常程序却发起对外密集发包的情况,所以不需要进行异常样本清洗
0x2: 特征采样
机器学习模型要求正负样本数量相差不多,而安全事件场景中发生暴力破解的情况毕竟是极少的几个,所以还要对负样本进行采样。不然会导致负样本(正常情况样本)主导了参数调优过程,而忽略核心的正样本的判别效果。
当正样本数量远少于负样本的时候,即使训练和测试精确率到了99.99%,也可能是因为正样本被分错了正好在那0.01%内,而导致整个模型面对真实线上样本的时候表现非常差
Relevant Link:
https://www.zhihu.com/question/28641663
5. 特征护理 - 特征预处理
通过特征提取,我们能得到未经处理的特征,这时的特征可能有以下问题:
1. 不属于同一量纲:即特征的取值范围不一样,不能够放在一起比较。无量纲化可以解决这一问题
2. 信息冗余:对于某些定量特征,其包含的有效信息为区间划分,例如学习成绩,假若只关心“及格”或不“及格”,那么需要将定量的考分,转换成“1”和“0”表示及格和未及格。二值化可以解决这一问题
3. 定性特征不能直接使用:某些机器学习算法和模型只能接受定量特征的输入,那么需要将定性特征转换为定量特征。最简单的方式是为每一种定性值指定一个定量值,但是这种方式过于灵活,增加了调参的工作。通常使用哑编码的方式(即one-hot编码思路)将定性特征转换为定量特征
1) 假设有N种定性值,则将这一个特征扩展为N种特征,当原始特征值为第i种定性值时,第i个扩展特征赋值为1,其他扩展特征赋值为0
2) 哑编码的方式相比直接指定的方式,不用增加调参的工作,对于线性模型来说,使用哑编码后的特征可达到非线性的效果
4. 存在缺失值:缺失值需要补充
5. 信息利用率低:不同的机器学习算法和模型对数据中信息的利用是不同的,例如在线性模型中,使用对定性特征哑编码可以达到非线性的效果。类似地,对定量变量多项式化,或者进行其他的转换,都能达到非线性的效果
我们使用sklearn中的preproccessing库来进行数据预处理,可以覆盖以上问题的解决方案。我们来逐一讨论下,然后再讨论本例中的暴力破解要如何进行特征预处理
进行无量钢化处理有一点要特别注意,一定要仔细区分“异常点”和“无量钢化”问题,如果是因为观测采样造成的异常点,是不能简单地进行无量钢化处理的,否则会影响到样本本身的概率分布
0x1: sklearn进行特征预处理的编程方法
1. 无量纲化
对于量纲不一致会影响模型训练效率和效果的问题,可以参阅这篇文章的第一章
无量纲化使不同规格的数据转换到同一规格,下面我们逐一介绍常用的无量纲化方法
标准化(z-score 标准化(zero-mean normalization))
标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。标准化需要计算特征的均值和标准差,公式表达为:
使用preproccessing库的StandardScaler类对数据进行标准化的代码如下:
from sklearn.preprocessing import StandardScaler
#标准化,返回值为标准化后的数据
StandardScaler().fit_transform(iris.data)
z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况
我们的目的是根据样本训练分类器,并不是具体关心样本内某一个属性的绝对值,而是关注不同样本之间的相对值区别,因此z-score标准化不会影响到最后分类器的效果
区间缩放法(归一化)(min-max标准化(Min-max normalization))
区间缩放法利用了边界值信息,将特征的取值区间缩放到某个特点的范围,例如[0, 1]等。区间缩放法的思路有多种,常见的一种为利用两个最值进行缩放,公式表达为:
使用preproccessing库的MinMaxScaler类对数据进行区间缩放的代码如下:
from sklearn.preprocessing import MinMaxScaler
#区间缩放,返回值为缩放到[0, 1]区间的数据
MinMaxScaler().fit_transform(iris.data)
正则化(Normalization)
正则化的过程是将每个样本缩放到单位范数(每个样本的范数为1),如果后面要使用如二次型(点积)或者其它核方法计算两个样本之间的相似性这个方法会很有用。Normalization主要思想是对每个样本计算其p-范数,然后对该样本中每个元素除以该范数,这样处理的结果是使得每个处理后样本的p-范数等于1。
p-范数的计算公式:||X||p=(|x1|^p+|x2|^p+...+|xn|^p)^1/p
该方法主要应用于文本分类和聚类中。例如,对于两个TF-IDF向量的l2-norm进行点积,就可以得到这两个向量的余弦相似性
>>> X = [[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]]
>>> X_normalized = preprocessing.normalize(X, norm='l2')
>>> X_normalized
array([[ 0.40…, -0.40…, 0.81…],
[ 1. …, 0. …, 0. …],
[ 0. …, 0.70…, -0.70…]])
2. 数据变换
常见的数据变换有基于多项式的、基于指数函数的、基于对数函数的
Logistic/Softmax变换(尺度变化函数)
常用于逻辑斯蒂回归和深度神经网络中,用于将输出层结果压缩到[0,1]的概率区间范围内。这本质上是一种特征数值压缩方法
3. 连续特征离散化
对定量特征二值化
定量特征二值化的核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0,公式表达如下: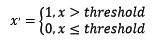
使用preproccessing库的Binarizer类对数据进行二值化的代码如下:
from sklearn.preprocessing import Binarizer
#二值化,阈值设置为3,返回值为二值化后的数据
Binarizer(threshold=3).fit_transform(iris.data)
4. 缺失值处理
缺失值计算
在一般情况下,在一个采集机制良好的系统中,样本集中不会存在缺失值,缺失值的发生可能在于我们对原始数据进行了一些聚合的join处理后,左/右表出现的缺失值;或者是在cnn图像处理时在边缘出现缺失值。这个时候我们需要根据业务场景具体需求补充缺失值,或者采集通用做法补零
0x2: 对于暴力破解识别场景来说需要做哪些特征处理?
对暴力破解场景来说,需要进行特征的问题可能有如下几个
1. 问题3,在广播破解模型中,dst_port目标端口这个特征是一个数字,也许需要通过one-hot的思路将其扩展成一定数量的特征,每个特征代表了一个服务类型,例如如果dst_port = 22,即在ssh特征置一,其他置零。但这里问题是目标端口服务可能不可枚举,会有越来越多的服务加入进来,对建模来说存在困难。这步可以放到模型调优阶段去考虑
2. 在一个时间区间内的频数从十几到几千不等,这里需要进行z-score标准化处理,将频数压缩到标准正态分布
3. 用于标识使用协议的"tcp"、"udp"需要数值化为1(tcp)和2(udp)
Relevant Link:
http://blog.csdn.net/pipisorry/article/details/52247379
http://www.cnblogs.com/chaosimple/p/4153167.html
6. 特征处理 - 特征选择
数据预处理完后第一步为分析数据,对数据整体结构有一个大致的把握,每种类型数据有自己特定的分析方式,这里我们将数据分为:
1. 类别型:输出饼图,观察样本数据分布,做频繁项分析
2. 连续型(暴力破解频数也属于连续型,离散频数也属于连续的一种特例):输出直方图、KDE图、CDF图,做回归分析
3. 日期型
4. 单词型:输出词频
5. 文本型
这里以暴力破解为例,打印频数特征的散点分布图来观察样本特征的空间距离分布,重点考察标准化后样本数据是否含有一定的正态分布特性
z-score标准化前:
z-score标准化后:
当对数据有一个大致理解后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。通常来说,从两个方面考虑来选择特征:
1. 特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么贡献
2. 特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择
特征选择的目标是寻找最优特征子集。特征选择能剔除不相关(irrelevant)或冗余(redundant )的特征,从而达到减少特征个数,提高模型精确度,减少运行时间的目的。另一方面,选取出真正相关的特征简化模型,协助理解数据产生的过程。特征选择的一般过程如下图所示:

下面讨论特征选择-产生过程和生成特征子集方法
0x1: Filter过滤法 - 与具体模型无关,而只关注自变量和因变量之间的关联
按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征
1. 方差/标准差 - 体现发散性的数学评价标准
我们知道,如果一个特征对应的样本取值发散度越大,说明这个特征在不同样本间的差异性越明显,根据该特征训练得到的分类器效果也越好
使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。使用feature_selection库的VarianceThreshold类来选择特征的代码如下
from sklearn.feature_selection import VarianceThreshold
from sklearn.datasets import load_iris
if name == ‘main’:
iris = load_iris()
print "iris.data: ", iris.data[:5]
# 方差选择法,返回值为特征选择后的数据
# 参数threshold为方差的阈值
res = VarianceThreshold(threshold=3).fit_transform(iris.data)
print "VarianceThreshold: ", res[:5]
iris.data: [[ 5.1 3.5 1.4 0.2]
[ 4.9 3. 1.4 0.2]
[ 4.7 3.2 1.3 0.2]
[ 4.6 3.1 1.5 0.2]
[ 5. 3.6 1.4 0.2]]
VarianceThreshold: [[ 1.4]
[ 1.4]
[ 1.3]
[ 1.5]
[ 1.4]]
可以看到,设定了方差为3后,鸢尾花的样本特征中的第三个特征被filter出来,表明第三列这个特征的离散方差最大
2. 相关系数法
使用相关系数法,先要计算各个特征对目标值的相关系数以及相关系数的P值。用feature_selection库的SelectKBest类结合相关系数来选择特征的代码如下
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from scipy.stats import pearsonr
from numpy import *
if name == ‘main’:
iris = load_iris()
print "iris.data: ", iris.data[:5]
# 选择K个最好的特征,返回选择特征后的数据
# 第一个参数为计算评估特征是否好的函数,该函数输入特征矩阵和目标向量,输出二元组(评分,P值)的数组,数组第i项为第i个特征的评分和P值。在此定义为计算相关系数
# 参数k为选择的特征个数
res = SelectKBest(lambda X, Y: tuple(map(tuple,array(list(map(lambda x:pearsonr(x, Y), X.T))).T)), k=2).fit_transform(iris.data, iris.target)
print res[:5]
iris.data: [[ 5.1 3.5 1.4 0.2]
[ 4.9 3. 1.4 0.2]
[ 4.7 3.2 1.3 0.2]
[ 4.6 3.1 1.5 0.2]
[ 5. 3.6 1.4 0.2]]
[[ 1.4 0.2]
[ 1.4 0.2]
[ 1.3 0.2]
[ 1.5 0.2]
[ 1.4 0.2]]
3. 卡方检验
经典的卡方检验是检验定性自变量对定性因变量的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量: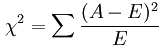
这个统计量的含义简而言之就是自变量对因变量的相关性。用feature_selection库的SelectKBest类结合卡方检验来选择特征的代码如下:
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from numpy import *
if name == ‘main’:
iris = load_iris()
print "iris.data: ", iris.data[:5]
# 选择K个最好的特征,返回选择特征后的数据
res = SelectKBest(chi2, k=2).fit_transform(iris.data, iris.target)
print "SelectKBest: ", res[:5]
iris.data: [[ 5.1 3.5 1.4 0.2]
[ 4.9 3. 1.4 0.2]
[ 4.7 3.2 1.3 0.2]
[ 4.6 3.1 1.5 0.2]
[ 5. 3.6 1.4 0.2]]
SelectKBest: [[ 1.4 0.2]
[ 1.4 0.2]
[ 1.3 0.2]
[ 1.5 0.2]
[ 1.4 0.2]]
可以看到,卡方检验得出特征3、4的相关性最大,这和我们用线性模型分析相关R指数的结果一致
4. 互信息法(信息增益)- 信息熵原理
经典的互信息也是评价定性自变量对定性因变量的相关性的,互信息计算公式如下:
为了处理定量数据,最大信息系数法被提出,使用feature_selection库的SelectKBest类结合最大信息系数法来选择特征的代码如下
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from minepy import MINE
from numpy import *
#由于MINE的设计不是函数式的,定义mic方法将其为函数式的,返回一个二元组,二元组的第2项设置成固定的P值0.5
def mic(x, y):
m = MINE()
m.compute_score(x, y)
return (m.mic(), 0.5)
if name == ‘main’:
iris = load_iris()
print "iris.data: ", iris.data[:5]
# 选择K个最好的特征,返回特征选择后的数据
res = SelectKBest(lambda X, Y: array(map(lambda x: mic(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
print "SelectKBest: ", res[:5]
0x2: Wrapper包装法 - 依赖具体模型,通过目标函数来决定是否加入一个特征
根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征,即
1. 序列前向选择( SFS , Sequential Forward Selection )
从空集开始,每次加入一个选最优。
2. 序列后向选择( SBS , Sequential Backward Selection )
从全集开始,每次减少一个选最优。
3. 增L去R选择算法 ( LRS , Plus-L Minus-R Selection )
从空集开始,每次加入L个,减去R个,选最优(L>R)或者从全集开始,每次减去R个,增加L个,选最优(L
关于特征的选取可以参阅这篇文章的回归变量的选择与逐步回归 - 建立多元线性回归模型前怎么去做特征工程部分的讨论
0x3: Embedded集成法 - 学习器自身自动选择特征
集成法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练模型之后来确定特征的优劣。深度神经网络的一个很重要的优势就是算法能在训练过程中自动选择特征
1. 基于L1/L2惩罚项的特征选择法
2. 基于树模型的特征选择法
树模型中GBDT也可用来作为基模型进行特征选择,使用feature_selection库的SelectFromModel类结合GBDT模型,来选择特征的代码如下:
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import GradientBoostingClassifier
from numpy import *
if name == ‘main’:
iris = load_iris()
print "iris.data: ", iris.data[:5]
# GBDT作为基模型的特征选择
res = SelectFromModel(GradientBoostingClassifier()).fit_transform(iris.data, iris.target)
print "RFE: ", res[:5]
iris.data: [[ 5.1 3.5 1.4 0.2]
[ 4.9 3. 1.4 0.2]
[ 4.7 3.2 1.3 0.2]
[ 4.6 3.1 1.5 0.2]
[ 5. 3.6 1.4 0.2]]
RFE: [[ 1.4 0.2]
[ 1.4 0.2]
[ 1.3 0.2]
[ 1.5 0.2]
[ 1.4 0.2]]
0x4: 降维 - 获取一个和原始特征空间分类效果等价的子特征空间
在一些情况下,可能会出现由于特征矩阵过大,导致计算量大,训练时间长的问题,因此降低特征矩阵维度也是必不可少的。常见的降维方法有
1. 基于L1惩罚项的模型
2. 主成分分析法(PCA):PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法
3. 线性判别分析(LDA):线性判别分析本身也是一个分类模型。
PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。
1. 主成分分析法(PCA)
使用decomposition库的PCA类选择特征的代码如下
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
from numpy import *
if name == ‘main’:
iris = load_iris()
print "iris.data: ", iris.data[:5]
# 主成分分析法,返回降维后的数据
# 参数n_components为主成分数目
res = PCA(n_components=2).fit_transform(iris.data)
print res[:5]
iris.data: [[ 5.1 3.5 1.4 0.2]
[ 4.9 3. 1.4 0.2]
[ 4.7 3.2 1.3 0.2]
[ 4.6 3.1 1.5 0.2]
[ 5. 3.6 1.4 0.2]]
PCA: [[-2.68420713 0.32660731]
[-2.71539062 -0.16955685]
[-2.88981954 -0.13734561]
[-2.7464372 -0.31112432]
[-2.72859298 0.33392456]]
2. 线性判别分析法(LDA)
使用lda库的LDA类选择特征的代码如下:
from sklearn.datasets import load_iris
from sklearn.lda import LDA
from numpy import *
if name == ‘main’:
iris = load_iris()
print "iris.data: ", iris.data[:5]
# 线性判别分析法,返回降维后的数据
# 参数n_components为降维后的维数
res = LDA(n_components=2).fit_transform(iris.data, iris.target)
print "PCA: ", res[:5]
iris.data: [[ 5.1 3.5 1.4 0.2]
[ 4.9 3. 1.4 0.2]
[ 4.7 3.2 1.3 0.2]
[ 4.6 3.1 1.5 0.2]
[ 5. 3.6 1.4 0.2]]
PCA: [[-8.0849532 0.32845422]
[-7.1471629 -0.75547326]
[-7.51137789 -0.23807832]
[-6.83767561 -0.64288476]
[-8.15781367 0.54063935]]
对于暴力破解这个场景来说,我们提取出的特征数量较少,同时从业务理解上看都和判别有较好的因果关系,因此不需要进行特征选择步骤
Relevant Link:
https://www.zhihu.com/question/29316149
https://zhuanlan.zhihu.com/p/27076389
http://blog.csdn.net/onlyqi/article/details/50843541
http://blog.csdn.net/onlyqi/article/details/50844826
http://www.cnblogs.com/jasonfreak/p/5448385.html
7. 特征监控
在机器学习任务中,特征非常重要。对于重要的特征进行监控与有效性分析,了解模型所用的特征是否存在问题,当某个特别重要的特征出问题时,需要做好备案,防止灾难性结果。需要建立特征有效性的长效监控机制
Relevant Link:
https://tech.meituan.com/machinelearning-data-feature-process.html
Copyright (c) 2017 LittleHann All rights reserved
