计算机视觉实战----AlexNet网络及使用colab跑YoloV5代码
系列文章目录
文章目录
- 系列文章目录
- 前言
- 一、用colab薅羊毛
- 二、使用百度飞浆操作
- 三、AlexNet网络
- 总结
- 参考
前言
一、用colab薅羊毛
Colaboratory 简称“Colab”,是 Google Research 团队开发的一款产品。在 Colab 中,任何人都可以通过浏览器编写和执行任意 Python 代码。它尤其适合机器学习、数据分析和教育目的。从技术上说,Colab 是一种托管式 Jupyter 笔记本服务。用户无需进行设置,就可以直接使用,同时还能获得 GPU 等计算资源的免费使用权限。
Google Colab免费GPU 超详细使用教程
- 需要准备的东西
ibcn和谷歌账号
有了上面两个东西后便可跳转到:colab
加载谷歌driver
from google.colab import drive
drive.mount('/content/drive')
注意,colab操作与Linux系统下操作是一样的,所以一些命令也是共通的,因为colab本身就是在Linux系统上,通过网页来操作而已,可以通过命令查看显卡使用情况,需要加!号
!nvidia-smi
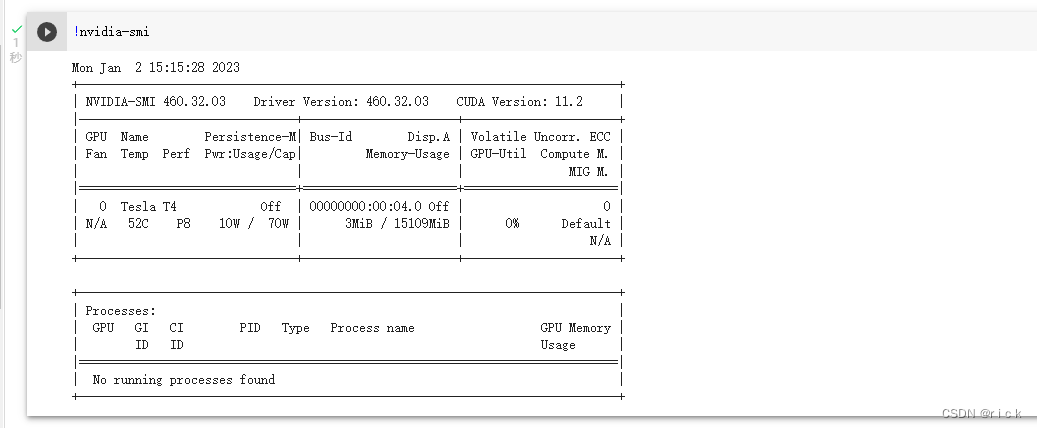
查看cuda版本及显卡型号

结果显示pytorch版本是1.13,cuda版本是11.6
显卡型号是:Tesla T4
- 使用colab跑Yolov5代码
Yolov4在github官方代码:ultralytics/yolov5
选择Open in colab,如箭头所示
- 首先连接官方GPU

- 步骤
- 步骤一:拷贝代码到当前目录下,并且配置环境
!git clone https://github.com/ultralytics/yolov5 # clone
%cd yolov5
%pip install -qr requirements.txt # install
import torch
import utils
display = utils.notebook_init() # checks

- 步骤二:下载训练好的模型并测试
!python detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images
# display.Image(filename='runs/detect/exp/zidane.jpg', width=600)
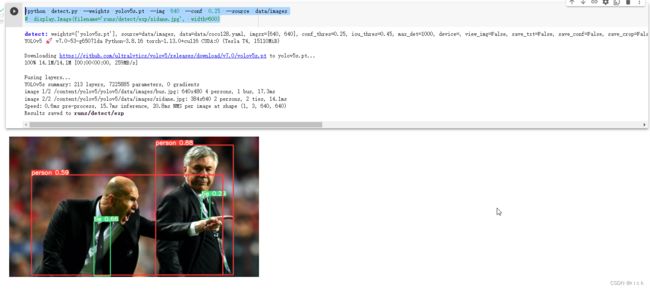
- 步骤三:下载coco验证集看模型的精度
coco数据集大概有80个类
# Download COCO val
torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip') # download (780M - 5000 images)
!unzip -q tmp.zip -d ../datasets && rm tmp.zip # unzip

可以看到网速能达到:10MB/s,速度还是客观的。
验证
# Validate YOLOv5s on COCO val
!python val.py --weights yolov5s.pt --data coco.yaml --img 640 --half

得到验证的结果
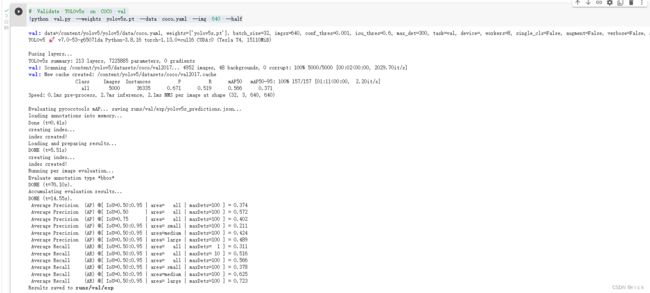

PR曲线
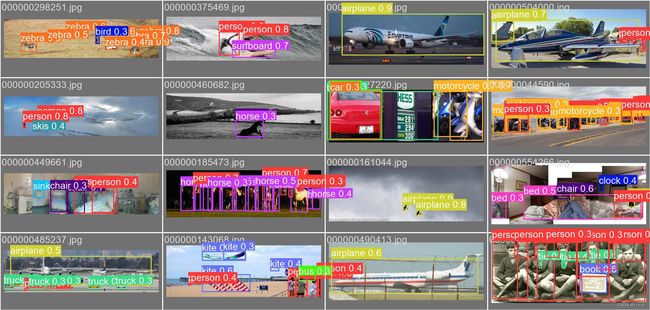
打的标签图片(val_batch0_label.jpg)

验证的图片(val_batch0_pred.jpg)
- 步骤四:选择tensorboard可视化结果
#@title Select YOLOv5 logger {run: 'auto'}
logger = 'TensorBoard' #@param ['TensorBoard', 'Comet', 'ClearML']
if logger == 'TensorBoard':
%load_ext tensorboard
%tensorboard --logdir runs/train
elif logger == 'Comet':
%pip install -q comet_ml
import comet_ml; comet_ml.init()
elif logger == 'ClearML':
%pip install -q clearml
import clearml; clearml.browser_login()
- 步骤五:run起来
# Train YOLOv5s on COCO128 for 3 epochs
!python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache

训练三轮后得到可视化结果
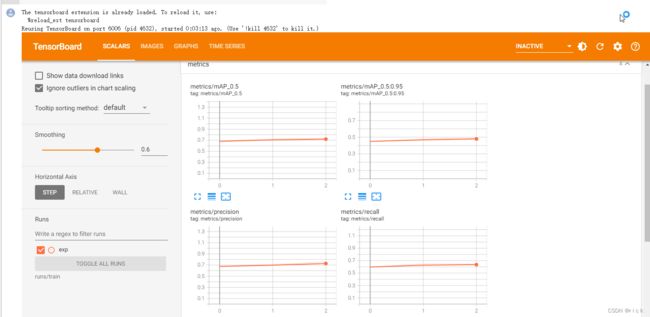
修改为训练3200轮试一下
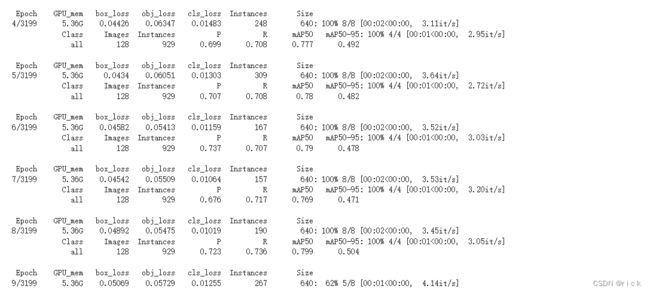
经过以上步骤训练完YoloV4,接下来将结果或代码复制到driver中

!cp -r /content/yolov5/yolov5 /content/drive/Shareddrives/c006-38/algorithm
复制成功

二、使用百度飞浆操作
1.首先,进入百度飞浆官网注册账号。
2. 找到项目:无需Avatarify使用PaddleGAN一键生成多人版 「蚂蚁呀嘿」视频
3. 操作步骤如下:
- 步骤一:启动环境,选择基础版即可
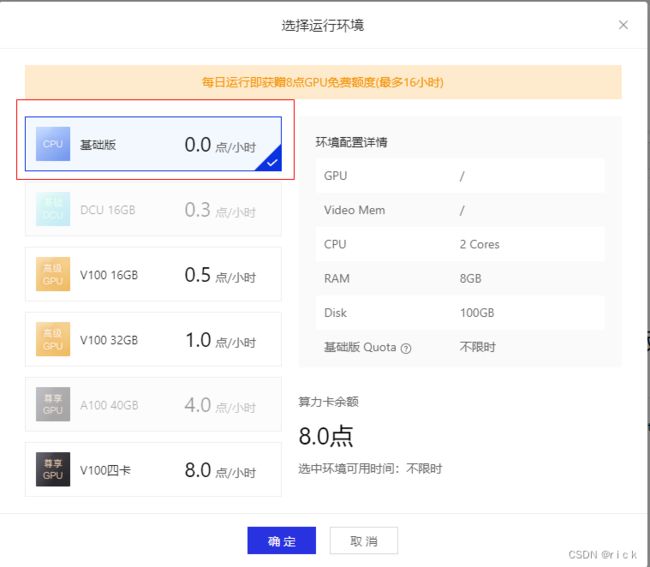
- 步骤二:安装paddlehub
首先我们需要安装PaddleHub,利用其中的face detection功能来定位照片中人脸。
安装方法如下:
!pip install paddlehub==1.6.0
- 步骤三:安装之后paddlehub之后,还需要安装一下人脸检测的模型,命令如下:
!hub install ultra_light_fast_generic_face_detector_1mb_640
- 步骤四:安装PaddleGAN
生成「蚂蚁呀嘿」视频需要用到PaddleGAN套件中的动作迁移功能,所以下一步需要安装PaddleGAN套件。因为我修改了PaddleGAN套件部分代码,这个代码已经保存在AI Studio环境中,直接安装就可以了。也可以从以下地址下载:https://gitee.com/txyugood/PaddleGAN.git
使用以下命令安装PaddleGAN。
%cd /home/aistudio/PaddleGAN/
!pip install -v -e .
-
步骤五:根据PaddleGAN的环境要求,安装合适的PaddlePaddle框架。

-
步骤六:运行脚本,得到结果
%cd /home/aistudio/PaddleGAN/applications/
!python -u tools/first-order-mayi.py \
--driving_video /home/aistudio/MaYiYaHei.mp4 \
--source_image /home/aistudio/10.jpg \
--audio_file /home/aistudio/MYYH.mp3 \
--relative --adapt_scale \
--output /home/aistudio/output \
--ratio 1.0
MaYiYaHei
三、AlexNet网络
- AlexNet网络paper

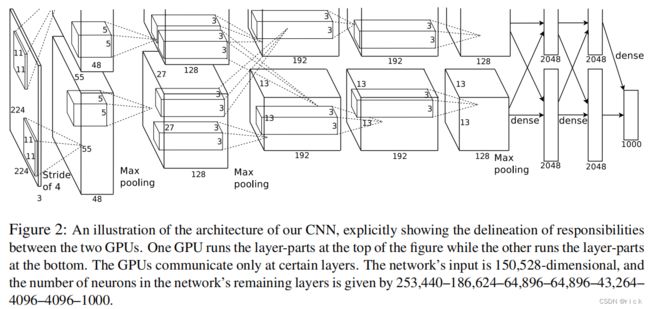
- 下载数据集
(1)在data_set文件夹下创建新文件夹"flower_data"
(2)点击链接下载花分类数据集
(3)解压数据集到flower_data文件夹下
(4)执行"split_data.py"脚本自动将数据集划分成训练集train和验证集val
├── flower_data
├── flower_photos(解压的数据集文件夹,3670个样本)
├── train(生成的训练集,3306个样本)
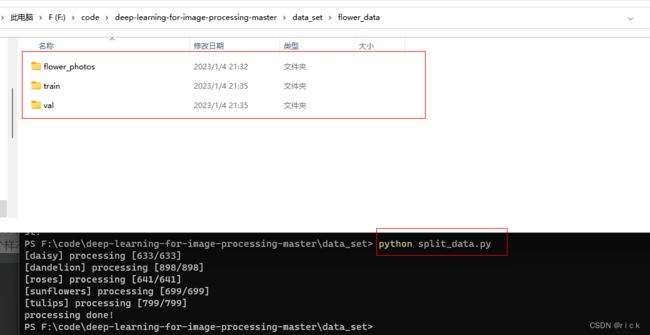
└── val(生成的验证集,364个样本) - 解压数据集后,放到data_set目录下的flower_data(自己创建)下,接下来使用脚本自动生成训练集和验证集
python split_data.py
4. 模型文件代码(model.py)
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential( #提取图像特征并打包,抛弃self....精简代码
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # 定义第一层卷积 N = (W − F + 2P ) / S + 1 input[3, 224, 224]
# output[48, 55, 55] 卷积核个数设置为原来(96)的一半
# F表示卷积核大小 N = (224 - 11 + 2*2)/4 +1 =55
# 3通道,48个卷积核,每个卷积核大小11,步长4,上下左右都补2列0
nn.ReLU(inplace=True), # 激活函数 inplace = True 增加计算量减少内存开销
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential( #分类器 将全连接层打包
nn.Dropout(p=0.5), #增加dropout函数,在正向传播过程中随机失活一部分神经元 默认是0.5
nn.Linear(128 * 6 * 6, 2048), #定义第一层全连接层 channel=128 6*6 2048个结点 上一层是Maxpool3[6,6,256]
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048), #定义第二层全连接层,上一层的输出是这一层的输入 2048 2048个结点
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes), #定义第三层全连接层,类别个数
)
if init_weights: #初始化权重
self._initialize_weights()
def forward(self, x): #正向传播
x = self.features(x)
x = torch.flatten(x, start_dim=1) #展平处理 从1这个维度(channel)开始,第0个维度是batch,一般不用管;之前是用的view函数
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():#继承父类modules()函数,返回一个迭代器
if isinstance(m, nn.Conv2d): #判断所属类型
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')#如果判定是卷积层,通过normal方法对权重初始化
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01) #通过正态分布 0是均值 0.01是方差
nn.init.constant_(m.bias, 0) #bias偏置为0
- 训练文件(train.py)
该部分代码基本上与LeNet训练代码一致

测试图片
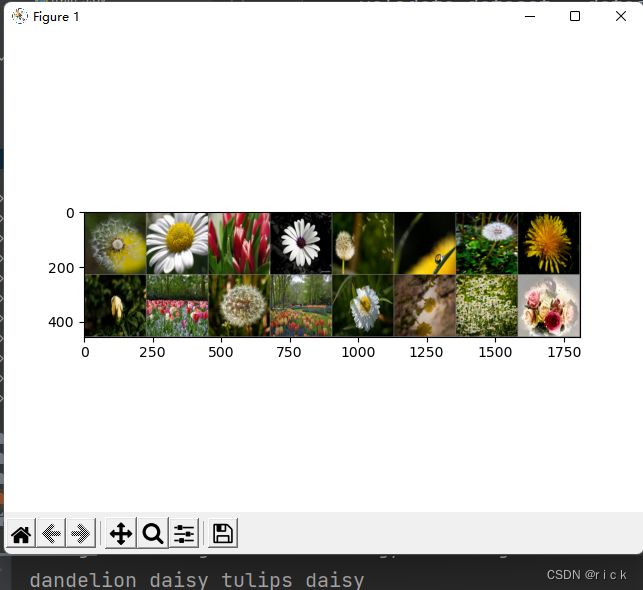
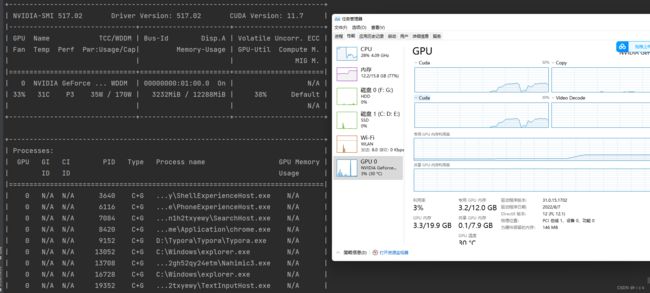
训练过程中可查看GPU/CPU使用情况
- 在终端用命令查看GPU情况
nvidia-smi -l 1
在任务管理器->性能里面,需要选择cuda查看,默认是3d,看不出来使用情况。
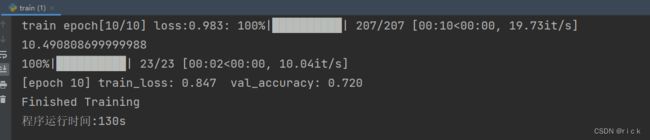
使用GPU训练10个epoch,用时130s,精度达到0.72
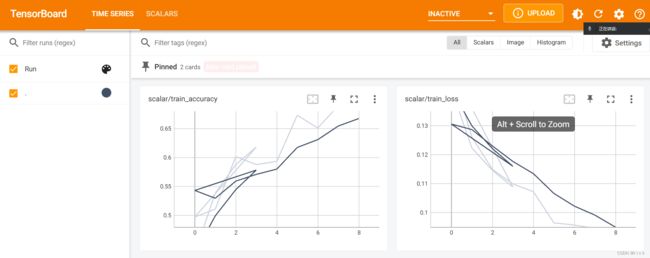
可以通过tensorboard实时查看训练情况,注意在终端输入命令的路径要与代码保持一致
tensorboard --logdir scalar
训练代码如下:
import os
import sys
import json
import time
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from tqdm import tqdm
from model import AlexNet
from tensorboardX import SummaryWriter#可视化
def main():
start_time = time.time() # 程序开始时间
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #指定训练设备 如果电脑有GPU,默认使用第一块,没有GPU则使用CPU
print("using {} device.".format(device))
data_transform = { #数据预处理
"train": transforms.Compose([transforms.RandomResizedCrop(224),#随机裁剪 224 x 224
transforms.RandomHorizontalFlip(),#随机翻转
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),#标准化处理
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path 获取数据集所在根目录
#os.getcwd()获取当前文件所在目录
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"]) #加载数据集 数据预处理
train_num = len(train_dataset) #训练集有多少张图片
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx #分类名称对应的索引
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4) #将字典转换为json格式
with open('class_indices.json', 'w') as json_file: #保存到json文件中 方便预测读取信息
json_file.write(json_str)
#batch_size = 32 #一次读32张图片
batch_size = 64
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset, #加载训练集
batch_size=batch_size, shuffle=True,
num_workers=1)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),#载入验证集
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset, #载入测试集
batch_size=batch_size, shuffle=True,
num_workers=1)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
# 测试
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
#
# def imshow(img):
# img = img / 2 + 0.5 # unnormalize
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
#
# print(' '.join('%5s' % cla_dict[test_label[j].item()] for j in range(4)))
# imshow(utils.make_grid(test_image))
net = AlexNet(num_classes=5, init_weights=True) #实例化模型,传入类别为5,初始化权重
net.to(device) #指定训练类型 GPU/CPU
loss_function = nn.CrossEntropyLoss() #损失函数 交叉熵函数,针对多类别
# pata = list(net.parameters())
optimizer = optim.Adam(net.parameters(), lr=0.0002)#定义Adam优化器 学习率为0.0002 优化对象是网络中所有参数 调大或小都会影响精度
epochs = 50
save_path = './AlexNet.pth'
best_acc = 0.0 #最佳准确率
train_steps = len(train_loader)
writer = SummaryWriter(log_dir='scalar')
#开始训练
for epoch in range(epochs):#迭代10次
# train
net.train() #启动dropout方法,而在验证时不需要启动dropout方法
running_loss = 0.0 #统计训练过程中的平均损失
t1 = time.perf_counter()#统计每一次迭代使用时间
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):#遍历数据集
images, labels = data #将数据分为图像和标签
optimizer.zero_grad() #清空梯度信息
outputs = net(images.to(device)) #正向传播 指定设备
loss = loss_function(outputs, labels.to(device))#计算损失 预测值和真实值的损失
loss.backward() #将损失反向传播到每个节点中
optimizer.step() #更新每个节点的参数
# print statistics
running_loss += loss.item()
#打印训练进度
rate = (step+1)/len(train_loader) #len(train_loder)得到一轮所需要的步数
a = "*" * int(rate*50)
b = "." * int((1-rate)*50)
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,epochs,loss)
print(time.perf_counter()-t1)#输出每一轮训练时间
# validate 进行验证
net.eval()#没有调用dropout函数,不需要随机失活
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad(): #确保验证过程中不会计算损失梯度
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:#遍历验证集
val_images, val_labels = val_data #得到图片和标签
outputs = net(val_images.to(device)) #正向传播得到输出
predict_y = torch.max(outputs, dim=1)[1] #得到预测的最大值
#acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
writer.add_scalar('scalar/train_accuracy',val_accurate, epoch)
writer.add_scalar('scalar/train_loss', running_loss / 500, epoch)
print('Finished Training')
# function() 运行的程序
end_time = time.time() # 程序结束时间
run_time = end_time - start_time # 程序的运行时间,单位为秒
print("程序运行时间:%ds" % int(run_time))
if __name__ == '__main__':
main()
- 测试
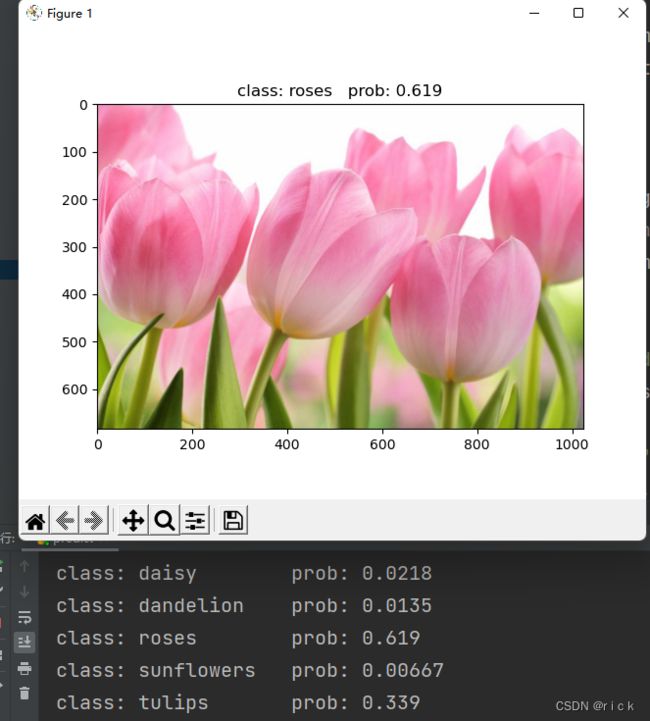
第一次训练的结果不是很好,可能是因为我在训练一个epoch后将程序关掉了,出现误识别,将郁金香识别为玫瑰
第二次训练结果比较满意:
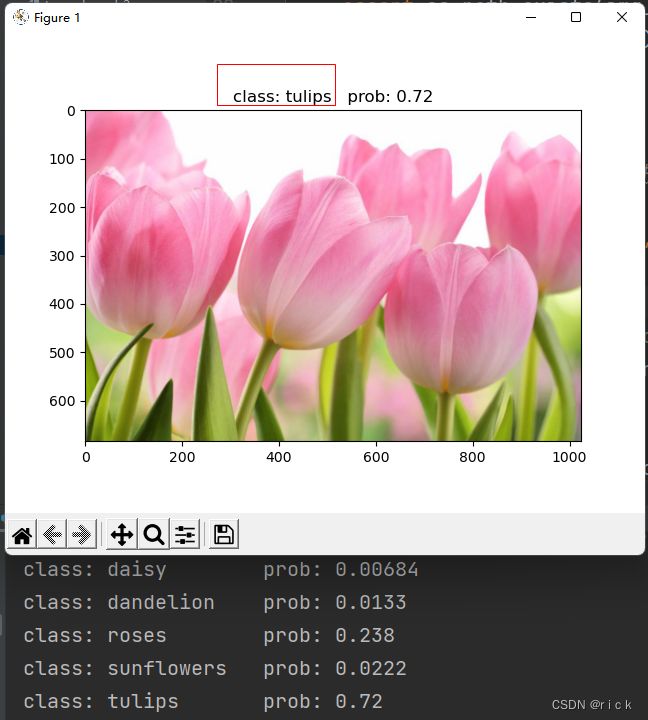
预测代码如下:
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import AlexNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(#预处理 将图片缩放到224*224大小
[transforms.Resize((224, 224)),
transforms.ToTensor(), #转换为tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])#标准化处理
# load image
img_path = "tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)#图片预处理
# expand batch dimension
img = torch.unsqueeze(img, dim=0)#扩充维度 因为读入图片后只有高度 宽度 通道 没有batch
# read class_indict
json_path = './class_indices.json' #索引对应的类别名称
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f) #解码操作,得到需要的字典
# create model
model = AlexNet(num_classes=5).to(device)#初始化网络
# load model weights
weights_path = "./AlexNet.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path))#载入网络模型
model.eval()#验证方法,不启动dropout
with torch.no_grad():#不跟踪损失梯度
# predict class
output = torch.squeeze(model(img.to(device))).cpu()#将batch维度压缩掉
predict = torch.softmax(output, dim=0)#得到概率分布
predict_cla = torch.argmax(predict).numpy()#得到概率最大的索引值
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()
总结
- 讲解了如何使用Colab,跑了YoloV5的代码。
- 讲解了AlexNet网络,并且代码实现,训练及预测了。
参考
- 3.2 使用pytorch搭建AlexNet并训练花分类数据集
- Google Colab免费GPU 超详细使用教程
- 无需Avatarify使用PaddleGAN一键生成多人版 「蚂蚁呀嘿」视频
- AlexNet网络paper