Object-Level Memory Allocation and Migration in Hybrid Memory Systems混合内存系统中对象级内存分配与迁移
文章目录
- 补充
-
- 缓存/TLB一致性
- 能量延迟积(energy-delay product)
- Instructions per Cycle (IPC) 每周期指令数
- 摘要
- 一、INTRODUCTION
- 二、 BACKGROUND AND MOTIVATION
-
- Observation 1.
- Observation 2.
- Observation 3.
- Observation 4.
- 三、DESIGN AND IMPLEMENTATION
-
- 3.1 System Overview
- 3.2 Object-Level Memory Access Profiling
- 3.3 Utility Model for Object Placement
- 3.4 Phase Identification and Object Classification
- 3.5 Initial Memory Allocation for Objects
- 3.6 Object Migration at Runtime
- 四、EVALUATION
-
- 4.1 Experimental Methodology
- 4.2 Effectiveness of Static Memory Allocation
- 4.3 Effectiveness of Online Object Migration
- 4.4 Comparison of OAM With Page Migration Schemes
- 4.5 Adaptability to Different Datasets and Scales
- 4.6 Sensitivity to Different NVM Performance Features
- 五、RELATED WORK
-
- 5.1 Memory Allocation in Hybrid Memory Systems
- 5.2 Data Migration in Hybrid Memory Systems
- 六、CONCLUSION
补充
缓存/TLB一致性
TLB一致性问题主要体现在当某个处理器核更新页表中的表项时(比如发生页从内存替换到磁盘或其他更低层次的存储器中),需要通知其他的核同时对TLB中该表项进行更新。某个处理器核修改页表后,将各个处理器核的TLB中储存的与内存中页表项不同的旧的页表项无效化的操作被称为TLB击落(TLB shootdown)。常用的维护TLB一致性的做法是软件层面的TLB击落,当一个处理器核修改了另一个处理器核正在使用的页表时,使用处理器间中断(IPI)通知其他的核。摘抄这篇文章第六节
能量延迟积(energy-delay product)
完成一个计算任务所耗费的能量与时间的乘积。是兼顾高性能和低功耗时采用的一个评价指标。
Instructions per Cycle (IPC) 每周期指令数
每个时钟周期平均执行完成的指令条数。是衡量处理器性能的一个指标。通过运行一组代码,计算完成运行代码所需的机器级指令的数量,然后使用高性能计时器计算在实际硬件上完成运行代码所需的时钟周期数,即可完成IPC的计算。
这篇翻译的不完整,翻译的也不是很好,后面会修改的
摘要
近年来,由新兴的非易失性存储器 (NVM) 和 DRAM 组成的混合存储器系统引起了越来越多的关注。为了充分利用 NVM 和 DRAM 的优势,主要目标是将应用程序数据正确放置在混合存储器上。以前的研究主要集中在页面迁移方案上,以实现更高的性能和能源效率。但是,这些方案都依赖于在线页面访问监控(成本高),并且由于DRAM带宽争用和缓存/TLB一致性的维护,页面粒度的数据迁移可能会导致额外开销。在本文中,我们介绍了混合内存系统的对象级内存分配和迁移 (OAM) 机制。OAM 利用分析工具来表征对象在应用程序不同执行阶段的内存访问模式,并应用性能/能量模型来指导 NVM 和 DRAM 之间的初始静态内存分配和运行时动态对象迁移。基于我们新开发的混合内存系统编程接口,应用源代码可以通过静态代码检测自动转换。我们在模拟混合内存系统上评估 OAM,实验结果表明,与页面交错数据放置方案相比,OAM 可以显着减少系统能量延迟积平均 61%。与最先进的页面迁移方案 CLOCK-DWF 和 2PP 相比,它还可以分别显着减少 83% 和 69% 的数据迁移开销,同时将应用程序性能提高多达 22% 和 10%。
一、INTRODUCTION
与DRAM相比,以字节为地址的非易失性存储器(NVM)技术有望实现高密度、接近零的静态能源消耗和低的每字节成本 。尽管NVM有这些优势,但由于其相对较高的写入延迟、写入能耗和有限的写入持久性,它目前还不能直接替代DRAM[1], [2], [3]。使用NVM的一个实际方法是将其与DRAM产品结合起来。然而,一个主要的挑战是如何设计智能数据放置策略,以充分利用两种内存技术的优势并且克服其缺点。
操作系统(OS)通常没有先验知识来指导混合内存系统中的初始数据放置。一个天真的策略可能会把热数据放在慢速内存上,从而导致应用性能不佳[4]。许多研究提出了页面迁移技术,以提高内存访问性能和能源效率[5]、[6]、 [7]、[8]、[9]、[10]。这些方案都依赖于页面访问的recency and frequency来决定数据在DRAM或NVM上的位置。不幸的是,今天的商品X86硬件不支持页面访问计数。先前的硬件辅助页迁移方案需要对当前的硬件架构进行重大修改[5], [6], [11]。其他一些工作则是利用操作系统来监控内存访问[12], [13]。一个由操作系统维护的典型的页表项(PTE)包含一个"访问"位。操作系统可以监控这个"访问"位,并知道一个页面被访问。然而,这个单一的位不足以识别这个页面是热的(频繁访问)还是冷的。因此,基于软件的内存访问监控方法通常会使TLB失效以跟踪每个内存引用(TLB根据虚拟地址查找cache)[12],[13]。这种页面访问计数机制通常会产生大量的性能开销。此外,页面迁移通常需要一段时间来检测热页,因此减少了页面迁移的好处。另外,预测的页面访问模式可能与未来的访问行为不一致,导致不必要的页面迁移。
另一方面,操作系统通常很难利用应用层面的语义进行细粒度的数据迁移。一个页面可能包含大量的小型应用对象,而且每个对象可能有不同的访问模式。另外,一个热页可能只包含一小部分经常访问的对象,而其余的对象是冷的(见第2节的更多结果)。因此,以页为单位的数据迁移在适应单个对象的不同访问模式方面并不高效。此外,大页(huge page)已被越来越多地用于大数据应用和虚拟化平台[13], [14]。由于对DRAM容量和带宽的低效利用,粗粒度的页面迁移甚至会降低系统性能。
为了在混合内存系统中做出更好的数据,最近的一项工作采用了离线剖析工具,以应用对象的粒度来描述内存访问模式,然后指导它们在DRAM或NVM上的静态放置[15]。这个方案只考虑了内存访问行为的整体观点,而忽略了内存访问模式的潜在变化,即对象的访问频率(热度)可能在不同的执行阶段动态变化。为此,另一项工作将静态对象放置与选定页面的动态迁移相结合[16],以处理这些波动。然而,它仍然依赖于内存控制器的硬件扩展来执行在线页面访问监控和迁移。为了减少在线页面监控和迁移的性能开销,我们提出了混合内存系统的对象级内存分配和迁移(OAM )机制。与[15]、[16]的工作类似,OAM利用离线剖析方法来捕获对象级内存访问模式,并采用性能/能量模型来指导对象内存分配和迁移。与只使用剖析跟踪来生成对象访问行为的整体视图的研究[15]、[16]不同,我们进一步以更精细的方式来分析对象的访问统计。更具体地说,我们分析每个对象的细粒度时间段的内存痕迹,并采用我们的性能/能量模型来识别对象内存访问模式变化的不同执行阶段。我们在应用程序的源代码中找出未来执行阶段会发生变化的位置,并通过静态代码工具自动注入对象迁移指令。当修改后的程序运行时,它通过考虑DRAM的使用和数据迁移的净收益,自己执行对象迁移。
综上所述,我们做出了以下贡献。
- 我们提供了一个离线剖析工具来详细描述应用程序的内存访问模式,并提出了一个性能/能源模型来指导应用程序对象的初始内存分配和动态迁移,而不需要任何硬件修改和操作系统干预的在线内存监控。
- 我们扩展了Glibc库和Linux内核,为混合内存管理提供了新的应用编程接口( API)。 程序员可以明确地将DRAM或NVM分配给应用对象,并在DRAM和NVM之间迁移。
- 我们开发了一个静态代码工具,用于自动转换应用程序源代码中的对象级内存分配和迁移,而不会给应用程序的程序员带来负担。
- 我们在一个基于DRAM的混合内存模拟器中评估了OAM,其工作负载范围很广。我们的实验结果证明了对象级数据放置/迁移的可行性,以缩小NVM和DRAM之间的性能差距。OAM和纯DRAM之间的性能差异平均只有2%。OAM能够显著减少数据迁移的开销,并取得比最先进的页面迁移方案更好的性能。例如,与CLOCK-DWF[5]和2PP[16]相比,OAM减少了迁移开销,即平均为83%和69%,而应用性能的提高则高达22%和10%。
本文的其余部分组织如下 。第2节介绍了促使我们进行系统设计的背景和实验观察。第3节介绍了OAM机制的设计和实现。实验结果在第4节中提出。我们在第5节中回顾了相关工作,并在第6节中得出结论。
二、 BACKGROUND AND MOTIVATION
许多研究提出了在缓存/内存层次中组织DRAM和NVM[17],[18],然而,本文侧重于在平面寻址架构[6]中管理DRAM/NVM,其中DRAM和NVM被组织在一个(平面)地址空间,并由操作系统统一管理。扁平架构可以充分利用DRAM和NVM的容量,但要依靠更复杂的数据放置策略来提高混合主存储器的性能和能源效率。更具体地说,经常访问的数据应该放在DRAM中,因为NVM的访问会产生相对较高的延迟。在下文中,我们使用LLVM[19] 对SPEC CPU2006[20]和PBBS[21]中几个有代表性的应用程序进行剖析,并从数据访问频率(热度)、 应用程序对象大小和寿命方面研究内存访问统计。我们有以下的主要观察。
Observation 1.
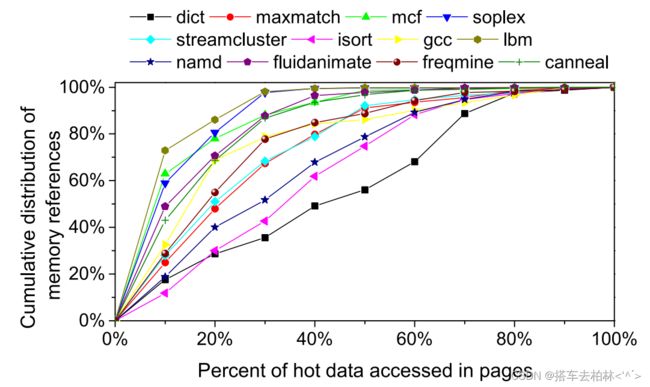
对于许多应用程序,每个页面中的热数据只占应用程序总内存足迹的一小部分,但却导致了应用程序总内存引用的很大比例。如图1所示,X轴显示了应用程序所有内存页中频繁访问的数据流量的百分比(按访问频率降序排列),Y轴显示了应用程序的总内存引用的累积分布。对于soplex来说,近35%的热数据占了总内存引用的98%。这意味着迁移soplex中的部分热数据(变量和对象)比迁移整个页面更有好处。然而,对于一些应用程序,如dict,内存访问均匀地分布在应用程序的地址空间中,因此从数据迁移中获益较少。
Observation 2.
很大一部分的应用程序的对象都比页小得多。这些应用程序的对象大小的分布函数。我们可以发现对于dict、isort、gcc和maxMatch来说,95%以上的对象都小于50字节。对于soplex,小对象的比例也超过85%。由于大多数应用层面的内存引用是对象和变量。程序员可以充分利用应用语义来优化对象粒度的数据放置/迁移。相反,一个页面可以包含许多对象,这些对象可能有不同的访问行为,合成的页面级访问统计可能变得复杂和不可预测。

Observation 3.
很大一部分应用程序的对象显示出较长的寿命。虽然以前的研究表明,许多程序的对象往往有一个相对较短的寿命[15],[22], [23], 我们发现,在某些情况下,仍然有很大一部分长寿命的对象。图3显示了一些应用程序的对象寿命的累积分布函数。我们发现在gcc、isort和soplex中几乎所有的对象都有超过1000秒的寿命。特别是,gcc中所有对象的寿命都等于应用程序的总执行时间。

Observation 4.
一部分应用对象在不同的执行阶段表现出高度突变的内存访问频率(热度)。 尽管许多对象在其整个生命周期中表现出相对一致的访问行为
(即所谓的不可改变的对象), 但仍有很大一部分对象在不同的执行阶段表现出高度突变的访问频率(即所谓的易变对象),如表1所示。这意味着仍有很大的空间可以通过运行时的对象迁移来优化数据放置。

总之,观察结果1和2清楚地表明,数据访问监控和内存分配/迁移应该是在对象上,而不是在页面上。观察结果3和4表明,在混合内存系统中需要对对象迁移进行仔细的设计。
三、DESIGN AND IMPLEMENTATION
在本节中,我们首先介绍了OAM的系统概况,然后介绍了离线内存分析、基于效用的性能/能源模型、对象分类和执行阶段识别、初始对象内存分配和运行时对象迁移机制的细节。
3.1 System Overview
图4显示了我们针对混合内存系统的对象级内存分配和迁移方案的概况。OAM主要包括两个模块。离线剖析和代码仪表(OPCI)和在线内存分配和迁移(OMAM ) 为了将对象适当地放置在DRAM或NVM上,OPCI利用离线应用剖析工具来分析对象粒度的内存访问模式,然后使用分析性的性能/能量模型来对对象的放置做出初步决定。这种最初的放置方式可以大大减少对不可改变的对象的不必要的数据迁移。此外,对于易变的对象,我们需要确定这些对象何时何地应该被迁移,以进一步优化运行时的数据放置。这需要更细化的内存访问分析,以准确识别应用程序的不同执行阶段。
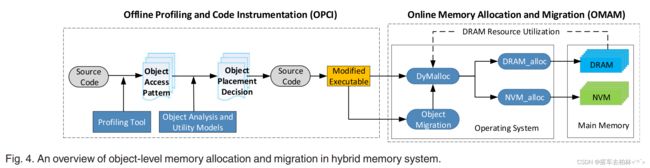
由于DRAM在混合内存 系统中通常是不够用的,所以在创建一个对象时,我们也应该考虑DRAM的资源利用率。尽管本实用新型建议一个对象最好被分配到DRAM中,但我们应该确保有足够的DRAM资源来容纳这个对象。因此,OMAM模块根据当前的DRAM资源利用率和对象的放置决定,适当地分配NVM或DRAM给一个对象。
如图4所述,我们为对象级的内存分配/迁移提供了几个应用编程接口( DRAM alloc, NVM alloc,DyMalloc和MigrateToX )。 DRAM alloc 和NVMalloc分别用于分配DRAM和NVM。DyMalloc考虑到了DRAM的资源利用率,以决定一个对象是否应该被放在DRAM或NVM上。MigrateToX ( X表示DRAM或NVM)是用来在DRAM和NVM之间迁移对象的。DyMalloc和MigrateToX的细节分别在3.5和3.6节中描述我们开发了一个静态代码仪表工具来修改应用程序的源代码与这些API,并自动生成修改后的可执行代码。通过这种方式,OMAM在运行时由应用程序自己在DRAM和NVM之间迁移可变对象,而无需修改硬件和操作系统。
3.2 Object-Level Memory Access Profiling
我们利用编译器基础设施LLVM-3.8.1来支持应用程序的内存引用文件。生成的跟踪文件记录每个对象的内存访
问信息,包括访问频率、寿命和大小。
首先,我们使用LLVM从源代码中生成中间代表(IR) 。为了计算对象级的内存引用,我们利用LLVM的PASS来遍历所有的加载/存储1分配/调用/映射指令,并在IR中插入探针。我们运行由修改后的IR生成的可执行文件,并通过LLVM PASS 自动收集所有对象的访问信息到一个跟踪文件中。一般来说,对具有较多LOC的应用程序进行剖析的成本较高。然而,如果一个LOCs较少的应用程序有更多的LOOP语句,其剖析
成本可能比LOCs较多的应用程序还要高。此外,跟踪的大小也取决于输入数据集。一个大的数据集通常会产生更多的内存跟踪。我们注意到,如果只有二进制代码可用,我们的分析方案仍然有效。由于OAM在LLVM IR的基础.上跟踪内存分配/访问,我们可以利用其他一些工具,如"llvm-mctoll "来静态地(提前编译)将二进制文件和可执行文件翻译为LLVM IR。
内存跟踪包含5个项目 , 包括"内存访问类型、虚拟地址、对象名称、对象类型和访问时间"。通过跟踪,我们很容易计算出对象的总内存引用和寿命。因为一个对象可能包含子对象,我们通过检查LLVM中GetElementPtr指令的参数来识别子对象。对于一个给定的对象,内存引用的数量是其所有子对象的内存访问计数的总和。
跟踪文件包含了所有的内存分配/访问指令,然而,只有一部分指令导致了对主内存的实际数据流量。原因是片上高速缓存可以过滤大量的内存访问热数据。为了评估高速缓存过滤对实际内存访问统计的影响,我们开发了一一个高速缓存模拟器,可以模拟不同的高速缓存结构[24], 包括层次结构、高速缓存大小、矢联性和替换策略。一般来说,高速缓存的大小和矢联性都对高速缓存的性能有很大的影响。一个具有较高矢联性的高速缓存通常可以减少高速缓存的失误,然而,它增加了功率、芯片面积和检查所访问的数据是否为"非"的延迟。
缓存集上的命中率。另一方面,一个更大尺寸的高速缓存可以提高高速缓存的命中率,但代价是更大的成本、功率、芯片面积和延迟。因为我们实验中的CPU有25MB的16路集合相联LLC,所以我们模拟了一个由伪LRU替换算法管理的16路集合矢联LLC。考虑到LLC的一部分容量可能被操作系统和系统软件占用,我们根据经验将分配给应用程序的LLC大小配置为16MB。在实践中,用户可以很容易地在我们的缓存
模拟器中配置缓存参数,如大小和矣联性。
缓存模拟器将LLVM生成的跟踪文件作为输入,并过滤程序中所有在模拟缓存中被击中的虚拟地址。剩余的虚拟地址反映了高速缓存的缺失或高速缓存的驱逐操作,并导致对主内存的实际内存访问。图5显示了不同应用程序对高速缓存和主内存的所有数据访问的分布。我们发现,片.上高速缓存平均能够过滤68%的总内存引用。对于gcc,甚至87%的数据访问都被过滤掉了。因此,当考虑到缓存过滤的影响时,应用程序的内存访问模式可能会非常不同。一些非常热的数据可能总是在高速缓存中被命中,而只导致对主内存的极少量的数据访问。因此,没有必要将这些数据从NVM迁移到DRAM上。通过我们的缓存过滤器,我们可以在NVM上获得真实的内存访问统计,并避免在运行时进行不必要的对象迁移。
3.3 Utility Model for Object Placement
由于DRAM和NVM之间的性能和能源特征不对称,当我们决定将-一个对象放在DRAM或NVM上时,性能和能源消耗是两个主要关注点[9], [10], [15]。我们提出了一个效用函数来计算在给定的时间段 T i T_i Ti内将对象放在DRAM或NVM上的好处,如图所示

注模型这些公式就不按照原文翻译了。就直接按照我的理解说直白一点:
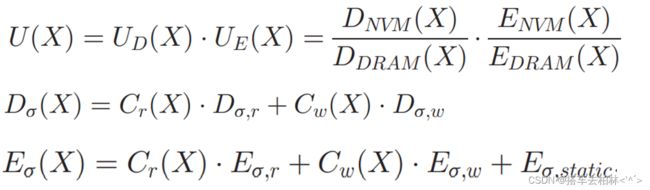
3.4 Phase Identification and Object Classification
一个应用程序通常包含许多对象,不同的对象可能呈现不同的内存访问方式。基本上,这些对象可以被划分为不可变和可变对象。不可变对象的内存访问频率可以被简单地视为一个常数。对于这些对象,我们只需要根据我们的实用函数把它们放在DRAM上或NVM上,而不需要考虑运行时的对象迁移。相比之下,内存访问可变对象的频率在不同的执行阶段是动态变化的,所以更好的对象放置也应该适应这种变化。因此,我们利用对象的迁移来实现这些可变对象的更好的能量-延迟-产品。
我们在下面描述应用程序执行阶段的识别和对象分类。首先,我们计算每个对象在固定时间段内的读/写操作。根据公式(1),我们计算每个时隙中对象的效用。基于阈值E,我们将对象的内存访问模式分为不同的阶段。如果对象在两个连续的时隙中的效用值大于E, 这两个时隙可以合并为一个执行阶段。然而,有些对象的效用值可能会在E附近急剧波动,而且确定的阶段的持续时间相当短,如图6中的对象D所示。在这些情况下,如果一个阶段的持续时间太短(例如,根据经验设定为物体寿命的二十分之一) , 我们将把这些短的阶段合并到其他长的阶段。最后,我们根据阶段的数量将所有对象划分为不可变和可变对象。例如,如果一个对象只有一个阶段,该对象无疑被归类为不可变的对象。否则,该对象就被归类为易变的对象。
图6说明 了一个相位识别和物体分类的例子。假设有四个对象A、B、C、D,效用函数的曲线如图6所示。对象A的效用值总是超过E,因此可以被归类为不可改变的对象。对于对象B,虽然它显示了一个非常短的阶段,其效用值小于E,但这个阶段可以合并到另一个阶段,跨越其大部分的生命周期。因此,对象B也被归类为不可变的对象。对象C是一个易变的.对象,因为根据我们的对象分类方案,它显示了两个不同的阶段。对于对象D,我们可以根据效用函数将其生命周期分为10个阶段。5个阶段(即T1-T2,T3-T4,T5-T6,T7-T8,T9-T10)的效用值大
于E。然而,3个阶段(T2-T3,T4-T5,T7-T8)的时间非常短,因此我们可以将它们合并到相邻的阶段。最后,对象D在相位合并操作后只有3个相位(T1- T6,T6- T9和T9- T10) 。当一个阶段发生变化时(即在T6和T9的时候), 我们对对象迁移的收益和成本进行权衡。如果净收益为正,我们就在相位变化的适当位置插入一个对象迁移语句。

最后,我们对对象的放置做一个初步的决定。对于不可变的对象,如果其平均效用大于E,这些对象将被放置在DRAM上。对于突变的对象,其第一阶段的平均效用决定了该对象应该被放置的位置,而对象的迁移应该在一个阶段发生变化时进行。在图6中,对象A、B和D首先应该被分配到DRAM.上。对象C一开始应该被分配在NVM上,然后应该被迁移到DRAM上。
3.5 Initial Memory Allocation for Objects
在混合内存系统中,我们假设昂贵的DRAM资源通常是有限的,而NVM总是足以满足所有工作负载。因此,DRAM资源的可用性是运行时成功分配DRAM的先决条件。在为一个对象分配内存时,我们应该考虑到DRAM资源的利用率。我们采用了一种内存储备机制来分配运行时的DRAM资源。其基本原则是,当一个对象被创建时,为近期内较热的对象保留足够的DRAM资源。
让UdOi表示对象Oi的效用,SdOi表示对象Oi的大小,DRAMavailable表示可用的DRAM资源,DRAMreserved表示为更多热对象保留的DRAM大小。让Uthreshold表示-一个对象应该被放在DRAM上的效用值的阈值。对于一个默认的阈值E,只有当UiOi P5E时,对象Oi才会被放在DRAM.上。让UtilizationDRAM表示DRAM资源的利用率,’ 表示当U8Oi P5E时,对象容易被放置在DRAM上的DRAM利用率的阈值。

算法1介绍了对象的内存分配( DyMalloc )的细节对于所有效用值小于默认阈值E的对象,它们应该绝对放在NVM上。对于其他对象( UHOi P5E), 如果当前的DRAM资源是足够的( 利用率DRAM < ‘), 我们将这些对象放在DRAM_上以提高DRAM的利用率。然而,当DRAM资源的利用率变得很高时(利用率pi)RAM5’),我们在下一个时隙找到一个效用U0Oj; P最大的对象Oj, 并为这个较热的对象保留DRAM资源。如果对象O;成功分配到了我们用当前对象的效用值U8Oip更新阈值Uthreshold,然后在未来只有效用值大得多的对象才能被分配到DRAM上。这种动态的效用阈值设置允许我们的系统在DRAM资源处于高压力时只为更热和更有益的对象分配DRAM。
我们注意到,应用程序的源代码应该调用APIDyMalloc来为每个对象分配内存。当程序开始执行时,DyMalloc会考虑到DRAM的资源利用率,最终为对象分配DRAM或NVM。我们扩展了Glibc库,为混合内存系统提供DRAM分配和NVM分配API。因此我们修改了Linux内核,在虚拟地址空间( VMA )中将NVM页与DRAM页区分开来。因此,我们在逻辑上将主内存分为两个区域。我们在VMA中标记NVM页,并为NVM分配提供一个新的分支NVM mmap。
3.6 Object Migration at Runtime
如第3.4节所述,可变对象的在线迁移是对初始对象内存分配的补充。它可以进一步提高对象内存访问的性能和能源效率。在我们的系统中,我们采用静态代码工具,在应用程序的源代码中添加对象迁移指令。在运行时,应用程序本身执行对象迁移,没有任何操作系统的干预。
要在应用程序的源代码中插入对象迁移指令,首要问题是如何找到源代码中的准确位置。我们观察到,大量密集的内存访问主要归因于循环状态[25]。因此,我们用循环作为断点,将源代码分成几个代码片段。首先,我们用LLVM跟踪对象的访问次数以及循环开始和结束时的时间戳。对于每个对象,我们在循环的执行过程中计算其效用值。循环开始和结束时效用值的突然变化意味着内存访问模式发生了变化,该对象应该在循环之前被迁移到另一种内存。我们用时间戳来定位这个特定的循环状态。最后,我们使用LLVM在循环的开头插入
对象迁移语句。
图7显示了一个混合内存分配和对象迁移的代码工具化的例子。我们根据LLVM中的抽象语法树( AST),以静态单一赋值( SSA )的形式遍历所有对象,并用DyMalloc改变源代码中的所有malloc。我们使用shared_ ptr创建对象,这是一个智能指针,通过指针保留对象的共享所有船。这允许几个shared_ ptr对象共享同一个对象的内存。shared_ ptr使用一个控制块来记录所有指向目标对象的指针和总引用的数量。例如,在
图8中,指向对象3的两个指针被记录在控制块中。只有当弓|用计数器变为零时,被管理对象才会被销毁。对于可改变的对象,我们使用MigrateToX API将对象复制到另一种内存中,然后所有存储的指向被管理对象的指针现在应该指向新的内存地址,如图8所示。对象迁移指令被插入到一个适当的地方( 很可能是在循环语句之前), 在那里对象的访问模式的变化。通过这种方式,我们在迁移后改变对象的虚拟地址,并在运行时更新对对象的所有引用。

对于比页面大得多的大型对象来说,粗粒度的迁移成本相对较高,甚至可能会损害应用程序的性能。为了解决这个问题,我们将大对象分割成多个小于一页的块。编译工具可以对每个块而不是整个对象的内存访问统计数据进行分析。基于基于分区的内存分析,上述的内存分配和迁移方案仍然适用于数据块。一个具有挑战性的问题是,shared_ ptr只记录了指向整个对象的所有指针,而不是分区的块。因此,我们扩展了智能指针的API,以支持运行时的细粒度内存弓|用跟踪和大对象的块级访问计数。
通过这种方式,我们的方法仍然可以优化大型对象的数据放置。由于新对象的内存分配、与旧对象相笑的片上缓存刷新和TLB击落[18]、复制对象数据、释放旧对象和页表更新,运行时的对象迁移会造成非同小可的性能开销。然而,通过将数据移动与应用程序的执行重叠,可以减轻开销。我们使用一个辅助线程,在执行阶段性变化之前迁移易变的对象。这种主动的对象迁移方案将数据移动从矢键路径上移开,而且不一定会使应用程序停滞。我们注意到,程序员不需要意识到硬件特性。他们仍然可以使用传统的malloc编写程序,然后利用我们的离线剖析和代码仪表工具,使代码适应混合内存系统。我们的工具隐藏了混合内存环境中的编程困难。此外,他们可以比程序员更好地决定对象的位置。另外,我们的OAM机制可以很容易地将许多传统的应用程序转变为混合内存系统。OAM增加的代码大小主要归因于对象迁移语句,记录所有指向对象的指针的控制块,以及数据移动的辅助线程。对于我们实验中的大多数应用,增加的代码大小小于1%。
四、EVALUATION
我们评估了静态内存分配和应用对象增量动态迁移的有效性。
4.1 Experimental Methodology
测试平台。由于商品NVM仍然不可用,我们使用混合内存模拟器( HME ) [26], [27]来评估提议的OAM机制,它使用一部分DRAM来模拟NVM的性能特征。HME利用商品英特尔CPU提供的DRAM热控制接口限制最大内存带宽,并定期注入额外的软件创建的延迟( NVM和DRAM延迟之间的差异)来模拟NVM访问延迟。另外,HME通过计算每个NVM读/写操作所产生的焦耳数来估计NVM的总能耗。由于应用是在真实硬件上执行的,HME可以非常快速地运行具有大内存足迹的工作负载。在我们的实验中,我们选择PCM作为代表性的NVM,因为它已经被广泛研究。PCM的时间和能量参数参考了以前的工作[1],[10]表2列出了系统配置的细节。
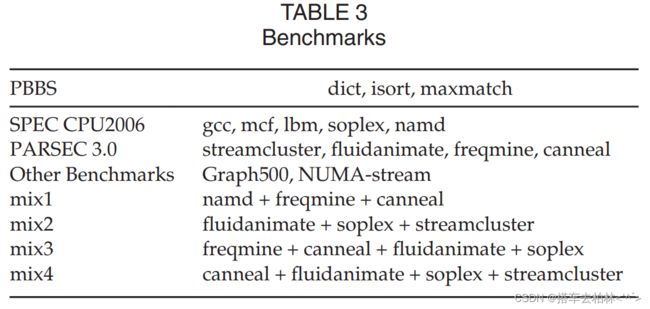
基准测试。基准选自基于问题的基准套件(PBBS) [21] 、SPEC CPU2006[20]、Parsec3.0[28],Graph500[29] ,和NUMA-stream[30] 。我们还使用一些多程序的工作负载来评估OAM,如表3所示
4.2 Effectiveness of Static Memory Allocation
首先,我们评估了不考虑对象迁移的静态内存分配,即"OAM w/o migration",所提高的应用性能。我们将其与页面交错进行比较,这是一种NUMA内存分配策略将页面交替放在DRAM和NVM上。我们也在纯DRAM内存系统中运行所有的应用程序,实验结果被作为混合内存系统的性能优化的上限参考。
图9显示了使用"OAM w/o migration" 、"2PP w/o migration "和"DRAM-only "策略的16个应用程序的执行时间和内存能耗,这些策略都被归类为页面交错策略。"OAM w/o migration "方案可以将应用程序的执行时间和内存能耗分别平均减少33%和35%。"2PP w/o migration"比“OAM w/o migration”多减少了一点执行时间和内存能耗,因为2PP利用全局内存访问统计数据进行初始数据放置。相比之下,OAM执行了一个细粒度的剖析方案,将内存访问模式的动态变化定性为不同的执行阶段,并根据其第一个执行阶段的效用将可变对象放在DRAM或NVM上。当DRAM足以存储所有经常访问的对象时,2PP的初始放置策略实现了比OAM高一点的性能。然而,2PP不能识别一些从全局来看被认为是冷门的频繁访问对象的短阶段,因此失去了许多将这些短期热门对象迁移到快速DRAM上的机会,正如后面第4.3节所说明的。
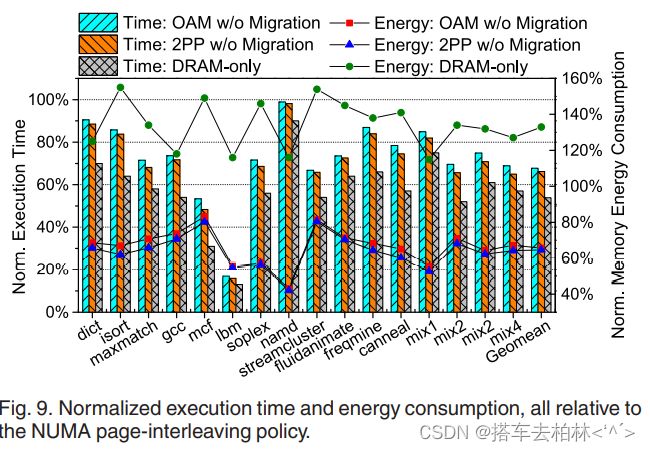
我们发现 ,"OAM w/o migration "和纯DRAM策略之间有大约13%的性能差距,因为很大一部分冷数据仍然放在NVM上以节省能源消耗。与只使用DRAM的系统相比,"OAM w/o migration "能够平均减少51%的内存能量消耗。这些结果表明,我们最初的OAM数据放置策略对提高混合内存系统的性能和能源效率是有效的。Ibm的执行时间。因为它们都是内存密集型的应用,并且热对象被放置在带有OAM的快速DRAM上,所以MCF被大大降低了83%和46%。与此相反,页面交错策略将大约一半的热数据放在慢速的NVM上,因此大大降低了应用性能。由于namd是一个受CPU约束的应用,而且在执行过程中有少量的内存访问,静态内存分配方案带来的性能改善非常有限,但却减少了56%的内存能耗。对于页面交错策略,我们发现namd执行的NVM写操作比lbm多得多,如图10所示。因为NVM写的能量消耗是DRAM写的40倍,namd可以通过从NVM向DRAM提供更多的内存写操作来达到比lbm更节能的目的。对于dict和isort来说,"OAM w/o migration “带来的性能改善非常有限,因为它们显示了随机的内存访问模式,而且热对象非常少。一般来说,我们的实用模型指导下的数据放置方案可以显著提高具有良好数据局部性的内存密集型应用程序的性能,也可以通过将冷数据放置在NVM上来降低应用程序的内存能耗。
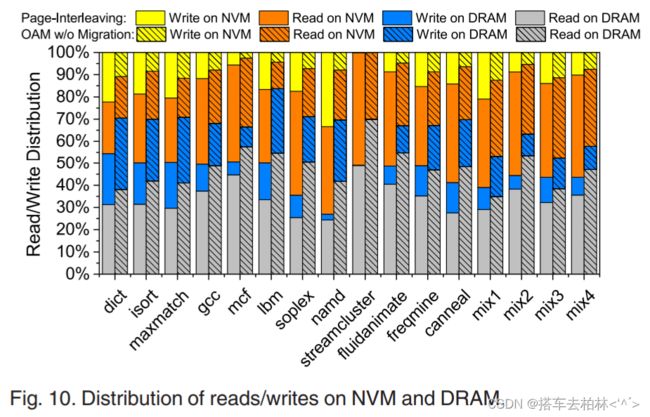
为了更好地理解我们的内存分配方案的性能增益,图10显示了每个应用在DRAM和NVM上的读/写指令的分布。对于页面交错策略,内存访问几乎均匀地分布在DRAM和NVM.上,因为页面是交错在两个内存节点上的。然而,我们发现Ibm总执行时间的80%以上是用于访问NVM,因为NVM的速度比DRAM慢几倍。对于"OAM w/o migration”,由于热对象被放在DRAM_上,几乎70%的内存读/写操作都分布在DRAM上。因此,"OAM w/o migration "实现了更好的应用性能和更低的能源消耗。
4.3 Effectiveness of Online Object Migration
在下文中,我们进一步评估了在线对象迁移对可变对象的有效性。由于C语言不是一种面向对象的编程语言,而我们的机制只为用C++编写的应用程序提供对象级迁移接口,因此我们只评估了6个用C++编写的应用程序和4个多程序工作负载。

图11显示了这些工作负载使用带有对象迁移的OAM的执行时间,所有这些时间都被归一化为没有OAM的执行时间。对象迁移。与静态内存分配方案相比,对象迁移可以进一步提高应用性能,平均提高11%。我们的基于效用的对象放置模型使用能量延迟积(energy-delay product)作为衡量标准来决定哪种内存对象应该被放置在上面。如图12所示,没有迁移的OAM平均可以实现51%的EDP减少,而有迁移的OAM平均可以进一步减少10%的EDP,所有这些都是相对于页面交错策略而言的。这意味着在最初的内存分配过程中,许多热对象已经被放在了DRAM上。然而,易变的对象仍然可以从运行时的对象迁移中获益更多。

4.4 Comparison of OAM With Page Migration Schemes
为了评估对象粒度数据迁移的效率,我们将OAM与两个最先进的页面迁移方案——CLOCK-DWF[5]和2PP[16]进行比较。CLOCK-DWF是一种用于混合内存架构的写时序感知的页面替换算法[5]。2PP是一个内存管理系统,它结合了静态对象放置和动态页面迁移[16]。我们也将纯DRAM系统称为应用性能的上界。我们在混合内存模拟器-NVMain与快速x86-64模拟器-zsim[18]中实现CLOCK-DWF和2PP。我们注意到,2PP利用内部的硬件/软件协调平台-HMTT来收集应用程序的内存跟踪[16]。相反,我们使用LLVM作为HMTT的替代品来进行离线内存剖析。
这些系统都使用4KB页面进行迁移。因为CLOCK-DWF和2PP都依赖于架构模拟器来模拟混合内存管理,在模拟器中从头到尾运行程序的成本非常高。相反,我们只运行具有固定指令数的程序( 4 ∗ 1 0 10 4*10^{10} 4∗1010) ,然后报告每周期指令数(IPC)的性能指标。通过这种方式,我们可以比较所有来自模拟器的结果( CLOCK-DWF和IPC)。2PP和实际系统( OAM和DRAM-only )使用相同的指标。我们用第4.1节中描述的相同配置来评估CLOCK-DWF和2PP。

图13显示了使用CLOCK-DWF、2PP和OAM的数据迁移流量,所有这些工作负载的足迹都被规范化。与CLOCK-DWF和2PP相比,OAM可以显著减少迁移流量,平均分别为42%和22%。对于NVM页面的每个写操作,CLOCK-DWF会首先将NVM页面迁移到DRAM上。因此,CLOCK-DWF总是保证每个写请求都由DRAM中的一个页面来响应。这种机制引入了许多页面迁移操作,其成本甚至可能大于获得的好处。由于2PP利用离线分析方案为对象做出更好的初始定位,它能够将页面迁移的数据流量平均减少26%。然而,2PP仍然在页的粒度上进行数据迁移,这比对象的粒度更粗。相比之下,OAM只在内存访问模式改变时迁移易变对象,因此可以进一步减少迁移流量,平均为22%。

图14显示 ,与CLOCK-DWF和2PP相比,OAM还可以将应用程序的IPC平均提高9%和4%。所有的结果都是以只使用DRAM的系统为标准的。我们发现,OAM和仅使用DRAM的系统之间的性能差距平均只有5%。这意味着大多数数据在适当的时候被放置在正确的内存介质上,而对象迁移的性能开销远远小于5%。对于CPU密集型的应用,如namd、streamcluster 和fluidanimate,这些方案的正常化IPC是相似的,因为这些应用显示出非常好的数据局部性。对于freqmine、canneal和其他多程序工作负载,OAM取得了比CLOCK-DWF和2PP高得多的性能改进。OAM比CLOCK-DWF和2PP的性能高达22%和10%。因为这些工作负载的足迹非常大,更多的热数据应该被迁移到DRAM中。OAM提供的对象迁移比页面迁移要轻得多,因此引入的性能开销比CLOCK-DWF和2PP少。

图15 显示了由CLOCK-DWF、2PP和OAM引起的"纯‘数据迁移开销,所有这些都被归一到应用程序总执行时间。由于OAM在离线分析阶段分析了对象级的内存访问模式,为了进行公平的比较,CLOCK-DWF和2PP的页面访问计数和热页识别的运行时间成本不包括在结果中。开销包括新对象的内存分配,与旧对象有关的片上缓存刷新和TLB击落,复制对象数据,释放旧对象,以及页表更新。由于CLOCK-DWF和2PP在页粒度上引入了更多的数据迁移操作,与CLOCK-DWF和2PP相比, OAM可以大大减少数据迁移的开销,平均为83%和69%。
4.5 Adaptability to Different Datasets and Scales
在下文中,我们使用Graph500和NUMA-STREAM作为案例研究,评估OAM对不同的数据集和问题规模的适应性。Graph500反映了非常差的时间/空间数据局部性因此可以利用它来评估内存访问延时。NUMA-stream基准是一个多线程程序, 特别设计用于评估高性能计算机的内存带宽。
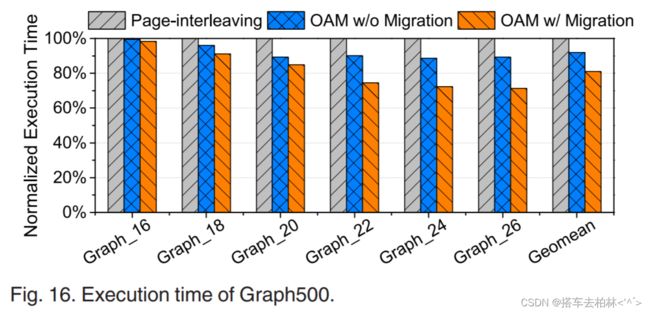
首先,我们使用不同的数据集评估OAM的适应性。我们用不同的输入来运行Graph500,使用由一个非常小的数据集产生的数据放置和迁移决定。图16显示了Graph500在不同输入下的执行时间,都是相对于页间方案而言的。输入"Graph_n "表示一个有 2 n 2^n 2n个顶点的图。特别是,"Graph_26 "包含大约64百万个顶点和16GB的原始数据。随着数据集大小的增加,OAM显示出更多的执行时间的减少。因为更大的输入可以成倍地增加内存引用,更多的数据访问可以相应地从我们的内存分配和对象迁移方案中受益。与页面交错方案相比,带迁移的OAM可以将应用性能提高29%。这意味着我们基于分析的OAM方案对不同的数据集和规模也是有效的。

其次, 我们研究OAM对于不同规模的问题是否可扩展。图17显示了随着线程的增加,多线程NUMA流的归一化执行时间。对于NUMA流,更多的线程意味着更大的内存带宽消耗。然而,NUMA流中的所有线程在不同的输入下显示出相对稳定的性能。这意味着,当问题规模发生变化时,OAM方案也是有效的。
4.6 Sensitivity to Different NVM Performance Features
最近,英特尔宣布了唯一可商业化的NVM设备——英特尔Optane DC持久性内存模块。它的读取延迟约为169-305ns,比DRAM ( 81ns)高约2-3倍。令人惊讶的是,OptaneDC的写延迟被测量为94ns,而DRAM为86ns[31]。它的读写带宽约为2.4-3.5倍。每个DIMM分别为7.6 GB/s和0.5-2.3 GB/s。在这一节中我们根据英特尔Optane DIMMs的性能特点,通过设置NVM读/写延迟和带宽,探索OAM对真实NVM设备的敏感性。

图18显示了不同的NVM访问延迟设置是如何影响应用性能的。由于英特尔Optane内存的写延迟几乎与DRAM相似,根据我们的实用模型,OAM不会将写密集型对象迁移到快速DRAM上。因此,在"Optane+DRAM"混合内存系统中,迁移流量主要是由读密集型对象引起的。如图19所示,使用英特尔.Optane DIMMs作为PCM的替代品,迁移流量明显减少。然而OAM为两种内存系统实现了类似的应用性能,因为它可以适应NVM设备的不同性能特征,以识别热对象并将其置于适当的内存介质上。
五、RELATED WORK
我们将相关工作总结为两类。
5.1 Memory Allocation in Hybrid Memory Systems
关于混合内存系统的内存分配,已经有很多研究。Youngwoo等人[32]提出了一个基于程序内存段访问模式的混合内存的页面分配器。它简单地假设堆和栈段中的所有数据都是经常访问的(热),因此将堆和栈段中的页分配在DRAM上,而其他段中的数据则分配在NVM上。WAlloc[33]是一个磨损感知的内存分配器,用于减少对NVM的写操作。HEAPO[34]和Makalu[35]都为具有数据一致性保证的NVM分配提供了编程接口。所有这些研究都是与OAM正交的。它们只提供了NVM的编程接口,而把数据放置的决策权留给了程序员。OAM不仅为混合内存系统提供了编程接口,而且还提供了一个分析工具和一个指导对象内存分配/迁移的实用模型。
一些研究提出了离线剖析方案来指导混合内存系统中的初始数据放置[15],[36] 。Hassan等人[15]利用一个离线剖析工具来指导混合内存上的对象内存分配。这项工作主要针对嵌入式系统和应用。Dulloor等人开发了一个离线分析工具,将内存访问模式分为顺序访问、随机访问和指针访问,并提出了一个名为X-Mem[36]的数据放置运行时,将对象映射到不同的数据结构中,这些结构被放置在不同的内存区域。Wu等人利用在线分析和性能模型来描述对象的访问模式,并开发了一个名为Unimem的运行时系统[4],将数据对象放置在混合存储器上。然而,Unimem只适用于基于MPI的HPC应用,可以很容易地根据MPI操作分解成不同的阶段。相比之下,OAM适用于所有用C++编写的通用应用程序。Tahoe[37]基于机器学习和分析模型来描述任务并行程序的内存访问模式,并在混合内存系统中做出最佳数据放置决策。这些研究提出的对象放置方案只基于对象的全局访问特性。他们并没有考虑到对象的访问模式在运行时的细粒度执行阶段的动态变化。2PP[16]是一个用于混合内存系统中对象放置的软/硬件合作框架。2PP也利用了离线剖析来指导初始的对象放置。然而,页面粒度的运行时数据迁移比对象粒度相对较粗,并且仍然依赖于页面级访问监控的硬件扩展。此外,2PP只考虑应用程序的全局内存读写比例和初始数据放置的可用DRAM容量。如果一个对象最好放在DRAM中,但在运行时没有足够的内存空间,那么它最初仍然被放在NVM中,但被标记为分歧,以便在运行时有可用的DRAM时,它可以被迁移到DRAM中。
5.2 Data Migration in Hybrid Memory Systems
页面访问计数。页面迁移依赖于页面访问监控来识别热(冷)页面。大量的工作都依赖于页面访问计数的硬件扩展。Gaurav等人[6]在内存控制器中提出了一个小的缓存来记录所选页面的写数,并将写数超过给定阈值的页面从NVM迁移到DRAM。Luiz等人[8]提出了硬件辅助的基于等级的页面放置(RaPP),根据页面访问频率和写入强度对页面进行排名,并将排名靠前的页面迁移到快速DRAM中。Meswani等人[38]在TLB中提出了一个硬件计数器,协助操作系统识别混合内存架构中的热门门页面进行迁移。这些研究都需要修改/扩展页面访问监控的硬件。
页面迁移算法。Soyoon等人[5]认为在预测未来的内存写入时,内存写入的频率比时间上的局部性要好,并提出了一种名为CLOCK-DWF的页面替换算法。Reza等人[9]考虑了内存的写入和读取来模拟页面迁移的好处,并使用两个最近最少使用(LRU )队列分别为DRAM和NVM选择目标页面(victim pages)。还有一些其他基于LRU的页面替换算法,如LRU-WPAM[39]、MHR-LRU[7]。Yoon等人[40]提出将经常错过的数据放在DRAM的行缓冲区中,以加快数据访问速度。Yang等人[10]将页面访问频率、行缓冲区的定位和在混合内存系统中,考虑到内存级别的并行性,并提出了一个基于页面效用的性能模型来指导页面迁移。Khouzani等人[11]将程序段和DRAM冲突都考虑在内,在混合内存系统中分配/迁移页面。上述页面迁移方法的一个关键限制是,它们都依赖于大量的硬件修改来监测内存访问统计。这些研究还忽略了应用层面的语义,并根据时间上的内存访问模式来迁移页面,这可能导致不必要的页面迁移。相比之下,我们的建议避免了任何硬件和操作系统层面的修改,并在对象颗粒度上提供了全局性的数据放置优化。
在操作系统中只实现了少数的页迁移工作。现代操作系统如Linux只支持非统一内存访问( NUMA )架构中的一些页面迁移原语[41]。Zhang等人[42]利用一个操作系统级的页迁移方案来提高NVM的写入性能和持久性。Memos[43]介绍了一个操作系统级的页面访问分析模块和页面迁移引擎,以优化混合内存系统中的数据放置。Memif[44]是一个受保护的操作系统服务,用于混合内存系统中异步的、DMA加速的页面迁移。HeteroOS[45]在虚拟环境中提供了一个操作系统管理的混合内存迁移解决方案。这些研究都需要检修操作系统的内核机制来支持页迁移,而且软硬件的开销通常相当高。相比之下,OAM提供了一个离线剖析工具来分析对象的内存访问模式,以及一个静态代码工具来修改应用程序的源代码,而不需要任何操作系统和硬件的干预。OAM也避免了在运行时监控内存的性能问题。
六、CONCLUSION
为了减轻混合内存系统中在线页面访问监控的开销和页面迁移的成本,我们提出了对象级内存分配和迁移机制。OAM利用离线剖析技术来收集应用程序的内存访问统计数据,并根据内存访问模式将对象分类为稳定和可变对象。我们提出了一个考虑到内存访问性能和能耗的实用模型,以指导对象在NVM或DRAM上的放置。对于稳定的对象,由模型指导的初始内存分配已经足够好了。对于可变的对象,由于它们的内存访问模式可能在不同的执行阶段发生变化,OAM识别不同阶段的变化,并相应地将对象迁移到另一种内存上。实验结果表明,与最先进的页面迁移方案CLOCK-DWF和2PP相比,OAM可以显著减少数据迁移的开销,分别为83%和69%,同时提供更高的应用性能。
目前先翻译这么多,一边读一边改罢了。