将梯度提升模型与 Prophet 相结合可以提升时间序列预测的效果

来源:Deephub Imba
本文约1200字,建议阅读5分钟
将Prophet的预测结果作为特征输入到 LightGBM 模型中进行时序的预测。
我们以前的关于使用机器学习进行时间序列预测的文章中,都是专注于解释如何使用基于机器学习的方法进行时间序列预测并取得良好结果。
但是在这篇文章将使用更高级的技术来预测时间序列,本文将使用 Prophet 来提取新的有意义的特征,例如季节性、置信区间、趋势等。
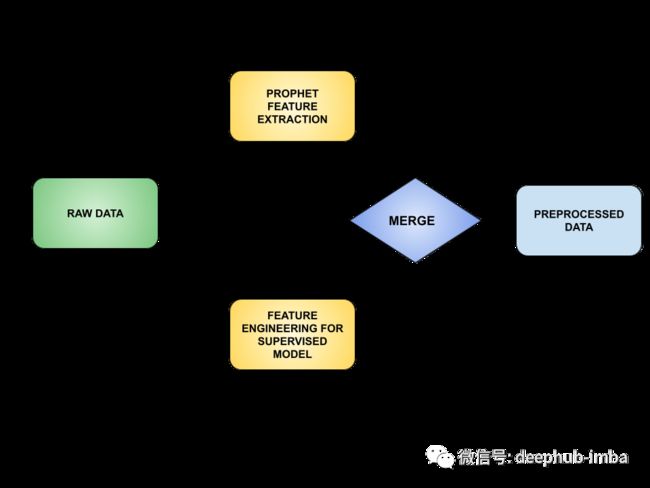
时间序列预测
一般情况下 LightGBM 模型都会使用一些lag的特征来预测未来的结果,这样做一般情况下能够取得很好的效果。本文介绍一种新的思路:使用 Prophet 从时间序列中提取新特征,然后使用LightGBM 进行训练,可以得到更好的效果。Prophet 模型的实际预测、置信区间的上限和下限、每日和每周的季节性和趋势等都可以作为我们的新特征。
对于其他类型的问题,Prophet 还可以帮助我们提取描述假日效果。
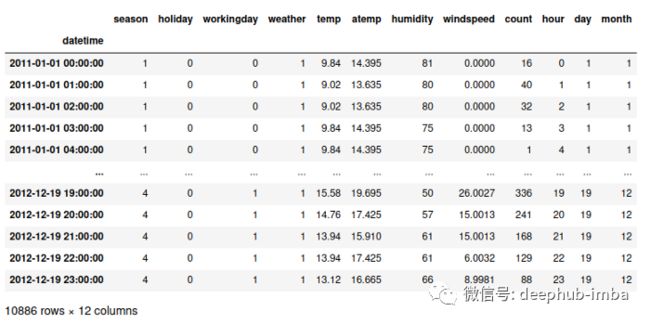
原始数据
我们的数据如下所示:
使用 Prophet 提取特征
我们特征工程的第一步非常简单。我们只需要使用Prophet 模型进行预测:
def prophet_features(df, horizon=24*7):
temp_df = df.reset_index()
temp_df = temp_df[['datetime', 'count']]
temp_df.rename(columns={'datetime': 'ds', 'count': 'y'}, inplace=True)
#take last week of the dataset for validation
train, test = temp_df.iloc[:-horizon,:], temp_df.iloc[-horizon:,:]
#define prophet model
m = Prophet(
growth='linear',
seasonality_mode='additive',
interval_width=0.95,
daily_seasonality=True,
weekly_seasonality=True,
yearly_seasonality=False
)
#train prophet model
m.fit(train)
#extract features from data using prophet to predict train set
predictions_train = m.predict(train.drop('y', axis=1))
#extract features from data using prophet to predict test set
predictions_test = m.predict(test.drop('y', axis=1))
#merge train and test predictions
predictions = pd.concat([predictions_train, predictions_test], axis=0)
return predictions上面的函数将返回一个给我们的 LightGBM 模型准备的新特征的DF:


使用 Prophet 特征训练 Autorregressive LightGBM
我们使用 Prophet 提取了新特征,下一步就是进行特征的合并和使用 LightGBM 进行预测:
def train_time_series_with_folds_autoreg_prophet_features(df, horizon=24*7, lags=[1, 2, 3, 4, 5]):
#create a dataframe with all the new features created with Prophet
new_prophet_features = prophet_features(df, horizon=horizon)
df.reset_index(inplace=True)
#merge the Prophet features dataframe with the our first dataframe
df = pd.merge(df, new_prophet_features, left_on=['datetime'], right_on=['ds'], how='inner')
df.drop('ds', axis=1, inplace=True)
df.set_index('datetime', inplace=True)
#create some lag variables using Prophet predictions (yhat column)
for lag in lags:
df[f'yhat_lag_{lag}'] = df['yhat'].shift(lag)
df.dropna(axis=0, how='any')
X = df.drop('count', axis=1)
y = df['count']
#take last week of the dataset for validation
X_train, X_test = X.iloc[:-horizon,:], X.iloc[-horizon:,:]
y_train, y_test = y.iloc[:-horizon], y.iloc[-horizon:]
#define LightGBM model, train it and make predictions
model = LGBMRegressor(random_state=42)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
#calculate MAE
mae = np.round(mean_absolute_error(y_test, predictions), 3)
#plot reality vs prediction for the last week of the dataset
fig = plt.figure(figsize=(16,6))
plt.title(f'Real vs Prediction - MAE {mae}', fontsize=20)
plt.plot(y_test, color='red')
plt.plot(pd.Series(predictions, index=y_test.index), color='green')
plt.xlabel('Hour', fontsize=16)
plt.ylabel('Number of Shared Bikes', fontsize=16)
plt.legend(labels=['Real', 'Prediction'], fontsize=16)
plt.grid()
plt.show()执行上述代码后,我们将合并特征df,创建滞后的lag值,训练 LightGBM 模型,然后用我们训练的模型进行预测,将我们的预测与实际结果进行比较。输出将如下所示:
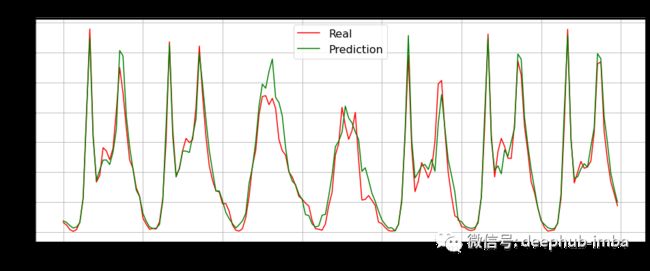
如果我们仔细观察结果我们的 MAE 为 28.665。这要比一般特征工程结果有很大的提高。
总结
将监督机器学习方法与 Prophet 等统计方法相结合,可以帮助我们取得令人印象深刻的结果。根据我在现实世界项目中的经验,很难在需求预测问题中获得比这些更好的结果。
编辑:于腾凯

