maskrcnn benchmark pytorch 训练+测试
项目网址:maskrcnn benchmark
文章目录
- 一、环境搭建
-
- 1.准备工作
- 出现的问题
- 解决方案
- 二、数据集准备
-
- 1.labelme2coco
- 三、训练测试
-
- 1.更改配置文件
- 2.训练
- 3.测试
- 总结
一、环境搭建
1.准备工作
我的基础环境:
系统:windows 10 ,Ubutun 18.01
Python环境:Anaconda3
conda: 4.5.4
pip : 20.2.2
Python :3.7.0
GPU :
NVIDIA GeForce RTX 2060 6G (windows)
Telsa v100 16G *8 (Ubutun)
pytorch :1.2
cuda:10.0
首先进入github网址,点击INSTALL.md
windows环境下和linux有所不同 ,严格安装他给的文档安装 不然后续会报错,这里以windows为例
#首先创建一个conda的虚拟环境并进入
open a cmd and change to desired installation directory
from now on will be refered as INSTALL_DIR
conda create --name maskrcnn_benchmark
conda activate maskrcnn_benchmark
#按照他给出的顺序安装
# this installs the right pip and dependencies for the fresh python
conda install ipython
# maskrcnn_benchmark and coco api dependencies
pip install ninja yacs cython matplotlib tqdm opencv-python
# follow PyTorch installation in https://pytorch.org/get-started/locally/
# we give the instructions for CUDA 9.0
## Important : check the cuda version installed on your computer by running the command in the cmd :
nvcc -- version
#这里他安装的cuda 9.0 实测20系列的显卡可能会与cuda9.0不匹配,我在安装9.0之后报错了,无法执行cudnn, 然后卸载重新装了10.0就解决了问题
conda install -c pytorch pytorch-nightly torchvision cudatoolkit=9.0
git clone https://github.com/cocodataset/cocoapi.git
#To prevent installation error do the following after commiting cocooapi :
#using file explorer naviagate to cocoapi\PythonAPI\setup.py and change line 14 from:
#extra_compile_args=['-Wno-cpp', '-Wno-unused-function', '-std=c99'],
#to
#extra_compile_args={'gcc': ['/Qstd=c99']},
#Based on https://github.com/cocodataset/cocoapi/issues/51
cd cocoapi/PythonAPI
python setup.py build_ext install
# navigate back to INSTALL_DIR
cd ..
cd ..
# install apex
git clone https://github.com/NVIDIA/apex.git
cd apex
python setup.py install --cuda_ext --cpp_ext
# navigate back to INSTALL_DIR
cd ..
# install PyTorch Detection
git clone https://github.com/Idolized22/maskrcnn-benchmark.git
cd maskrcnn-benchmark
# the following will install the lib with
# symbolic links, so that you can modify
# the files if you want and won't need to
# re-build it
python setup.py build develop
出现的问题
在 linux 下 执行 git clone https://github.com/NVIDIA/apex.git python setup.py install --cuda_ext --cpp_ext 出现 nvidia apex build error 以及 error: command 'gcc' failed with exit status 1解决方案
git checkout f3a960f80244cf9e80558ab30f7f7e8cbf03c0a0
二、数据集准备
1.labelme2coco
maskrcnn benchmark 需要的数据集格式为coco数据集格式。我是通过labelme来标注数据,然后在转换为coco格式。网上有很多转换的代码,很多都有问题。在linux下测试时出现如下问题:
AssertionError: tensor([398.9765, 403.2801, 415.9314, 402.9380])
解决方法:
import argparse
import json
import matplotlib.pyplot as plt
import skimage.io as io
import cv2
from labelme import utils
import numpy as np
import glob
import PIL.Image
REQUIRE_MASK = False
class labelme2coco(object):
def __init__(self,labelme_json=[],save_json_path='./new.json'):
'''
:param labelme_json: the list of all labelme json file paths
:param save_json_path: the path to save new json
'''
self.labelme_json=labelme_json
self.save_json_path=save_json_path
self.images=[]
self.categories=[]
self.annotations=[]
# self.data_coco = {}
self.label=[]
self.annID=1
self.height=0
self.width=0
self.require_mask = REQUIRE_MASK
self.save_json()
def data_transfer(self):
for num,json_file in enumerate(self.labelme_json):
if not json_file == self.save_json_path:
with open(json_file,'r') as fp:
data = json.load(fp)
self.images.append(self.image(data,num))
for shapes in data['shapes']:
print("label is ")
print(shapes['label'])
label=shapes['label']
# if label[1] not in self.label:
if label not in self.label:
print("find new category: ")
self.categories.append(self.categorie(label))
print(self.categories)
# self.label.append(label[1])
self.label.append(label)
points=shapes['points']
self.annotations.append(self.annotation(points,label,num))
self.annID+=1
def image(self,data,num):
image={}
img = utils.img_b64_to_arr(data['imageData'])
# img=io.imread(data['imagePath'])
# img = cv2.imread(data['imagePath'], 0)
height, width = img.shape[:2]
img = None
image['height']=height
image['width'] = width
image['id']=num+1
image['file_name'] = data['imagePath'].split('/')[-1]
self.height=height
self.width=width
return image
def categorie(self,label):
categorie={}
categorie['supercategory'] = label
# categorie['supercategory'] = label
categorie['id']=len(self.label)+1
categorie['name'] = label
# categorie['name'] = label[1]
return categorie
def annotation(self,points,label,num):
annotation={}
print(points)
x1 = points[0][0]
y1 = points[0][1]
x2 = points[1][0]
y2 = points[1][1]
contour = np.array([[x1, y1], [x2, y1], [x2, y2], [x1, y2]]) #points = [[x1, y1], [x2, y2]] for rectangle
contour = contour.astype(int)
area = cv2.contourArea(contour)
print("contour is ", contour, " area = ", area)
annotation['segmentation']= [list(np.asarray([[x1, y1], [x2, y1], [x2, y2], [x1, y2]]).flatten())]
#[list(np.asarray(contour).flatten())]
annotation['iscrowd'] = 0
annotation['area'] = area
annotation['image_id'] = num+1
if self.require_mask:
annotation['bbox'] = list(map(float,self.getbbox(points)))
else:
x1 = points[0][0]
y1 = points[0][1]
width = points[1][0] - x1
height = points[1][1] - y1
annotation['bbox']= list(np.asarray([x1, y1, width, height]).flatten())
annotation['category_id'] = self.getcatid(label)
annotation['id'] = self.annID
return annotation
def getcatid(self,label):
for categorie in self.categories:
# if label[1]==categorie['name']:
if label == categorie['name']:
return categorie['id']
return -1
def getbbox(self,points):
polygons = points
mask = self.polygons_to_mask([self.height,self.width], polygons)
return self.mask2box(mask)
def mask2box(self, mask):
# np.where(mask==1)
index = np.argwhere(mask == 1)
rows = index[:, 0]
clos = index[:, 1]
left_top_r = np.min(rows) # y
left_top_c = np.min(clos) # x
right_bottom_r = np.max(rows)
right_bottom_c = np.max(clos)
# return [(left_top_r,left_top_c),(right_bottom_r,right_bottom_c)]
# return [(left_top_c, left_top_r), (right_bottom_c, right_bottom_r)]
# return [left_top_c, left_top_r, right_bottom_c, right_bottom_r] # [x1,y1,x2,y2]
return [left_top_c, left_top_r, right_bottom_c-left_top_c, right_bottom_r-left_top_r]
def polygons_to_mask(self,img_shape, polygons):
mask = np.zeros(img_shape, dtype=np.uint8)
mask = PIL.Image.fromarray(mask)
xy = list(map(tuple, polygons))
PIL.ImageDraw.Draw(mask).polygon(xy=xy, outline=1, fill=1)
mask = np.array(mask, dtype=bool)
return mask
def data2coco(self):
data_coco={}
data_coco['images']=self.images
data_coco['categories']=self.categories
data_coco['annotations']=self.annotations
return data_coco
def save_json(self):
print("in save_json")
self.data_transfer()
self.data_coco = self.data2coco()
print(self.save_json_path)
json.dump(self.data_coco, open(self.save_json_path, 'w'), indent=4)
labelme_json=glob.glob('./*.json')
labelme2coco(labelme_json,'../annotations/instances_train2014.json')
通过上面的代码可以生成自己的json文件后,建立datasets文件,在建立coco文件(annotations(存放生成的json文件),其他存放训练测试验证数据集,如下图
├── ABSTRACTIONS.md
├── build
│ ├── lib.linux-x86_64-3.7
│ └── temp.linux-x86_64-3.7
├── CODE_OF_CONDUCT.md
├── configs
│ ├── caffe2
│ ├── cityscapes
│ ├── e2e_faster_rcnn_R_101_FPN_1x.yaml#训练和验证要用到的faster r-cnn模型配置文件
│ ├── e2e_faster_rcnn_R_50_C4_1x.yaml
│ ├── e2e_faster_rcnn_R_50_FPN_1x.yaml
│ ├── e2e_faster_rcnn_X_101_32x8d_FPN_1x.yaml
│ ├── e2e_mask_rcnn_R_101_FPN_1x.yaml#训练和验证要用到的mask r-cnn模型配置文件
│ ├── e2e_mask_rcnn_R_50_C4_1x.yaml
│ ├── e2e_mask_rcnn_R_50_FPN_1x.yaml
│ ├── e2e_mask_rcnn_X_101_32x8d_FPN_1x.yaml
│ ├── pascal_voc
│ └── quick_schedules
├── CONTRIBUTING.md
├── data
│ └── datasets1
├── datasets
│ ├── classes.txt
│ ├── coco1 #这是coco的标准数据集
│ ├── coco #训练的自己的数据集都放到这里
│ └── data
├── demo
│ ├── demo_e2e_mask_rcnn_R_50_FPN_1x.png
│ ├── demo_e2e_mask_rcnn_X_101_32x8d_FPN_1x.png
│ ├── demo.py
│ ├── Mask_R-CNN_demo.ipynb
│ ├── Mask_R-CNN_demo.py
│ ├── maskrcnn.sh
│ ├── predictor.py
│ ├── __pycache__
│ ├── README.md
│ ├── size.py
│ ├── video.py
│ ├── webcam1.py
│ └── webcam.py
├── docker
│ ├── Dockerfile
│ └── docker-jupyter
├── INSTALL.md
├── LICENSE
├── log.txt
├── maskrcnn_benchmark
│ ├── _C.cpython-37m-x86_64-linux-gnu.so
│ ├── config
│ ├── csrc
│ ├── data
│ ├── engine
│ ├── __init__.py
│ ├── layers
│ ├── modeling
│ ├── __pycache__
│ ├── solver
│ ├── structures
│ └── utils
├── maskrcnn_benchmark.egg-info
│ ├── dependency_links.txt
│ ├── PKG-INFO
│ ├── SOURCES.txt
│ └── top_level.txt
├── maskrcnn.sh
├── MODEL_ZOO.md
├── pretrained
│ ├── e2e_faster_rcnn_R_101_FPN_1x.pth
│ ├── e2e_faster_rcnn_R_50_C4_1x.pth
│ ├── e2e_faster_rcnn_R_50_FPN_1x.pth
│ ├── e2e_faster_rcnn_X_101_32x8d_FPN_1x.pth
│ └── e2e_mask_rcnn_R_101_FPN_1x.pth
├── README.md
├── setup.py
├── tests
│ ├── checkpoint.py
│ ├── test_data_samplers.py
│ └── test_metric_logger.py
├── tools
│ ├── cityscapes
│ ├── test_net.py
│ └── train_net.py
├── train1.sh#训练shall文件
├── train.sh#训练shall文件
└── TROUBLESHOOTING.md
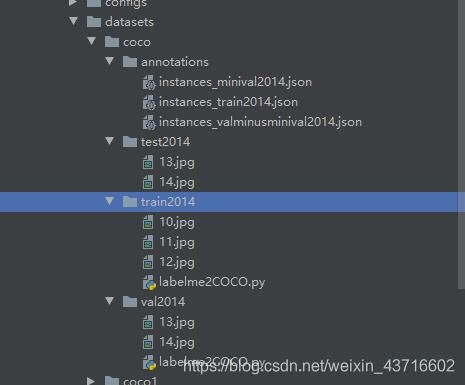
json文件名字为配置文件中的默认文件名 如果不更改配置文件,则必须使用这个名字
三、训练测试
1.更改配置文件
3个配置文件:
1.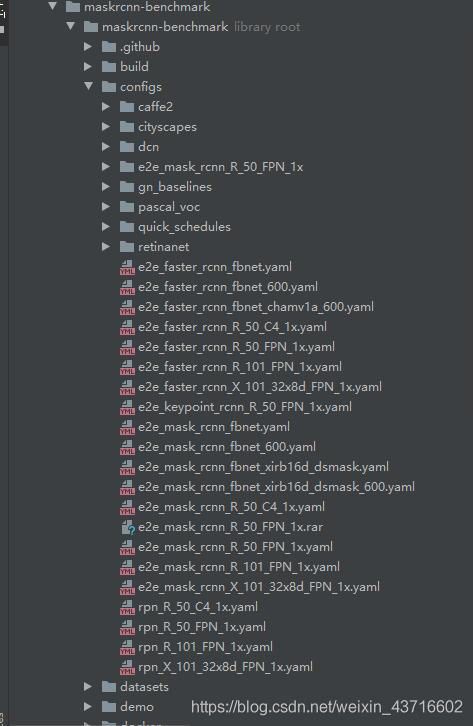
选择config文件下e2e_mask_rcnn_R_50_FPN_1x.yaml
MODEL:
META_ARCHITECTURE: "GeneralizedRCNN"
WEIGHT: "catalog://ImageNetPretrained/MSRA/R-50"#预训练权重,后续可以更改路径,改成自己训练好的模型文件路径用来推断
BACKBONE:
CONV_BODY: "R-50-FPN"
RESNETS:
BACKBONE_OUT_CHANNELS: 256
RPN:
USE_FPN: True
ANCHOR_STRIDE: (4, 8, 16, 32, 64)
PRE_NMS_TOP_N_TRAIN: 2000
PRE_NMS_TOP_N_TEST: 1000
POST_NMS_TOP_N_TEST: 1000
FPN_POST_NMS_TOP_N_TEST: 1000
ROI_HEADS:
USE_FPN: True
ROI_BOX_HEAD:
POOLER_RESOLUTION: 7
POOLER_SCALES: (0.25, 0.125, 0.0625, 0.03125)
POOLER_SAMPLING_RATIO: 2
FEATURE_EXTRACTOR: "FPN2MLPFeatureExtractor"
PREDICTOR: "FPNPredictor"
ROI_MASK_HEAD:
POOLER_SCALES: (0.25, 0.125, 0.0625, 0.03125)
FEATURE_EXTRACTOR: "MaskRCNNFPNFeatureExtractor"
PREDICTOR: "MaskRCNNC4Predictor"
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 2
RESOLUTION: 28
SHARE_BOX_FEATURE_EXTRACTOR: False
MASK_ON: True
DATASETS:
TRAIN: ("coco_2014_train", "coco_2014_valminusminival") #数据文件路径 ,名称改成和此一致
TEST: ("coco_2014_minival",)
DATALOADER:
SIZE_DIVISIBILITY: 32
SOLVER:
BASE_LR: 0.001 # 学习率
WEIGHT_DECAY: 0.0001
STEPS: (60000, 80000)
MAX_ITER: 90000 #迭代次数
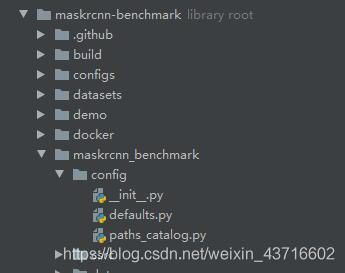
选择maskrcnn_benchmark/config/defaults.py
更改_C.MODEL.ROI_BOX_HEAD.NUM_CLASSES = 你自己的类别数+1(背景)
3.maskrcnn_benchmark/config/path_catalog.py
这里面是存放数据集的,因为直接使用了coco2014,没有建立自己的类别 ,所以不用更改这个文件
2.训练
windows下 进入项目文件maskrcnn-benchmark目录下,训练执行
python tools/train_net.py --config-file "configs/e2e_mask_rcnn_R_50_FPN_1x.yaml"
linux下执行训练:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -m torch.distributed.launch --nproc_per_node=8 tools/train_net.py --config-file "configs/e2e_mask_rcnn_R_50_FPN_1x.yaml"
出现的问题:
1.在windows下会出现编码错误,进入自己的anaconda文件夹下,\anaconda\envs\maskrcnn_benchmark\Lib\site-packages\torch\utils ,找到collect_env.py,更改文件
# This script outputs relevant system environment info
# Run it with `python collect_env.py`.
from __future__ import absolute_import, division, print_function, unicode_literals
import locale
import re
import subprocess
import sys
import os
from collections import namedtuple
try:
import torch
TORCH_AVAILABLE = True
except (ImportError, NameError, AttributeError):
TORCH_AVAILABLE = False
PY3 = sys.version_info >= (3, 0)
# System Environment Information
SystemEnv = namedtuple('SystemEnv', [
'torch_version',
'is_debug_build',
'cuda_compiled_version',
'gcc_version',
'cmake_version',
'os',
'python_version',
'is_cuda_available',
'cuda_runtime_version',
'nvidia_driver_version',
'nvidia_gpu_models',
'cudnn_version',
'pip_version', # 'pip' or 'pip3'
'pip_packages',
'conda_packages',
])
def run(command):
"""Returns (return-code, stdout, stderr)"""
p = subprocess.Popen(command, stdout=subprocess.PIPE,
stderr=subprocess.PIPE, shell=True)
output, err = p.communicate()
rc = p.returncode
if PY3:
output = output.decode("gb2312")
err = err.decode("gb2312")
return rc, output.strip(), err.strip()
def run_and_read_all(run_lambda, command):
"""Runs command using run_lambda; reads and returns entire output if rc is 0"""
rc, out, _ = run_lambda(command)
if rc != 0:
return None
return out
def run_and_parse_first_match(run_lambda, command, regex):
"""Runs command using run_lambda, returns the first regex match if it exists"""
rc, out, _ = run_lambda(command)
if rc != 0:
return None
match = re.search(regex, out)
if match is None:
return None
return match.group(1)
def get_conda_packages(run_lambda):
if get_platform() == 'win32':
grep_cmd = r'findstr /R "torch soumith mkl magma"'
else:
grep_cmd = r'grep "torch\|soumith\|mkl\|magma"'
conda = os.environ.get('CONDA_EXE', 'conda')
out = run_and_read_all(run_lambda, conda + ' list | ' + grep_cmd)
if out is None:
return out
# Comment starting at beginning of line
comment_regex = re.compile(r'^#.*\n')
return re.sub(comment_regex, '', out)
def get_gcc_version(run_lambda):
return run_and_parse_first_match(run_lambda, 'gcc --version', r'gcc (.*)')
def get_cmake_version(run_lambda):
return run_and_parse_first_match(run_lambda, 'cmake --version', r'cmake (.*)')
def get_nvidia_driver_version(run_lambda):
if get_platform() == 'darwin':
cmd = 'kextstat | grep -i cuda'
return run_and_parse_first_match(run_lambda, cmd,
r'com[.]nvidia[.]CUDA [(](.*?)[)]')
smi = get_nvidia_smi()
return run_and_parse_first_match(run_lambda, smi, r'Driver Version: (.*?) ')
def get_gpu_info(run_lambda):
if get_platform() == 'darwin':
if TORCH_AVAILABLE and torch.cuda.is_available():
return torch.cuda.get_device_name(None)
return None
smi = get_nvidia_smi()
uuid_regex = re.compile(r' \(UUID: .+?\)')
rc, out, _ = run_lambda(smi + ' -L')
if rc != 0:
return None
# Anonymize GPUs by removing their UUID
return re.sub(uuid_regex, '', out)
def get_running_cuda_version(run_lambda):
return run_and_parse_first_match(run_lambda, 'nvcc --version', r'V(.*)$')
def get_cudnn_version(run_lambda):
"""This will return a list of libcudnn.so; it's hard to tell which one is being used"""
if get_platform() == 'win32':
cudnn_cmd = 'where /R "%CUDA_PATH%\\bin" cudnn*.dll'
elif get_platform() == 'darwin':
# CUDA libraries and drivers can be found in /usr/local/cuda/. See
# https://docs.nvidia.com/cuda/cuda-installation-guide-mac-os-x/index.html#install
# https://docs.nvidia.com/deeplearning/sdk/cudnn-install/index.html#installmac
# Use CUDNN_LIBRARY when cudnn library is installed elsewhere.
cudnn_cmd = 'ls /usr/local/cuda/lib/libcudnn*'
else:
cudnn_cmd = 'ldconfig -p | grep libcudnn | rev | cut -d" " -f1 | rev'
rc, out, _ = run_lambda(cudnn_cmd)
# find will return 1 if there are permission errors or if not found
if len(out) == 0 or (rc != 1 and rc != 0):
l = os.environ.get('CUDNN_LIBRARY')
if l is not None and os.path.isfile(l):
return os.path.realpath(l)
return None
files = set()
for fn in out.split('\n'):
fn = os.path.realpath(fn) # eliminate symbolic links
if os.path.isfile(fn):
files.add(fn)
if not files:
return None
# Alphabetize the result because the order is non-deterministic otherwise
files = list(sorted(files))
if len(files) == 1:
return files[0]
result = '\n'.join(files)
return 'Probably one of the following:\n{}'.format(result)
def get_nvidia_smi():
# Note: nvidia-smi is currently available only on Windows and Linux
smi = 'nvidia-smi'
if get_platform() == 'win32':
smi = '"C:\\Program Files\\NVIDIA Corporation\\NVSMI\\%s"' % smi
return smi
def get_platform():
if sys.platform.startswith('linux'):
return 'linux'
elif sys.platform.startswith('win32'):
return 'win32'
elif sys.platform.startswith('cygwin'):
return 'cygwin'
elif sys.platform.startswith('darwin'):
return 'darwin'
else:
return sys.platform
def get_mac_version(run_lambda):
return run_and_parse_first_match(run_lambda, 'sw_vers -productVersion', r'(.*)')
def get_windows_version(run_lambda):
return run_and_read_all(run_lambda, 'wmic os get Caption | findstr /v Caption')
def get_lsb_version(run_lambda):
return run_and_parse_first_match(run_lambda, 'lsb_release -a', r'Description:\t(.*)')
def check_release_file(run_lambda):
return run_and_parse_first_match(run_lambda, 'cat /etc/*-release',
r'PRETTY_NAME="(.*)"')
def get_os(run_lambda):
platform = get_platform()
if platform == 'win32' or platform == 'cygwin':
return get_windows_version(run_lambda)
if platform == 'darwin':
version = get_mac_version(run_lambda)
if version is None:
return None
return 'Mac OSX {}'.format(version)
if platform == 'linux':
# Ubuntu/Debian based
desc = get_lsb_version(run_lambda)
if desc is not None:
return desc
# Try reading /etc/*-release
desc = check_release_file(run_lambda)
if desc is not None:
return desc
return platform
# Unknown platform
return platform
def get_pip_packages(run_lambda):
# People generally have `pip` as `pip` or `pip3`
def run_with_pip(pip):
if get_platform() == 'win32':
grep_cmd = r'findstr /R "numpy torch"'
else:
grep_cmd = r'grep "torch\|numpy"'
return run_and_read_all(run_lambda, pip + ' list --format=freeze | ' + grep_cmd)
if not PY3:
return 'pip', run_with_pip('pip')
# Try to figure out if the user is running pip or pip3.
out2 = run_with_pip('pip')
out3 = run_with_pip('pip3')
num_pips = len([x for x in [out2, out3] if x is not None])
if num_pips == 0:
return 'pip', out2
if num_pips == 1:
if out2 is not None:
return 'pip', out2
return 'pip3', out3
# num_pips is 2. Return pip3 by default b/c that most likely
# is the one associated with Python 3
return 'pip3', out3
def get_env_info():
run_lambda = run
pip_version, pip_list_output = get_pip_packages(run_lambda)
if TORCH_AVAILABLE:
version_str = torch.__version__
debug_mode_str = torch.version.debug
cuda_available_str = torch.cuda.is_available()
cuda_version_str = torch.version.cuda
else:
version_str = debug_mode_str = cuda_available_str = cuda_version_str = 'N/A'
return SystemEnv(
torch_version=version_str,
is_debug_build=debug_mode_str,
python_version='{}.{}'.format(sys.version_info[0], sys.version_info[1]),
is_cuda_available=cuda_available_str,
cuda_compiled_version=cuda_version_str,
cuda_runtime_version=get_running_cuda_version(run_lambda),
nvidia_gpu_models=get_gpu_info(run_lambda),
nvidia_driver_version=get_nvidia_driver_version(run_lambda),
cudnn_version=get_cudnn_version(run_lambda),
pip_version=pip_version,
pip_packages=pip_list_output,
conda_packages=get_conda_packages(run_lambda),
os=get_os(run_lambda),
gcc_version=get_gcc_version(run_lambda),
cmake_version=get_cmake_version(run_lambda),
)
env_info_fmt = """
PyTorch version: {torch_version}
Is debug build: {is_debug_build}
CUDA used to build PyTorch: {cuda_compiled_version}
OS: {os}
GCC version: {gcc_version}
CMake version: {cmake_version}
Python version: {python_version}
Is CUDA available: {is_cuda_available}
CUDA runtime version: {cuda_runtime_version}
GPU models and configuration: {nvidia_gpu_models}
Nvidia driver version: {nvidia_driver_version}
cuDNN version: {cudnn_version}
Versions of relevant libraries:
{pip_packages}
{conda_packages}
""".strip()
def pretty_str(envinfo):
def replace_nones(dct, replacement='Could not collect'):
for key in dct.keys():
if dct[key] is not None:
continue
dct[key] = replacement
return dct
def replace_bools(dct, true='Yes', false='No'):
for key in dct.keys():
if dct[key] is True:
dct[key] = true
elif dct[key] is False:
dct[key] = false
return dct
def prepend(text, tag='[prepend]'):
lines = text.split('\n')
updated_lines = [tag + line for line in lines]
return '\n'.join(updated_lines)
def replace_if_empty(text, replacement='No relevant packages'):
if text is not None and len(text) == 0:
return replacement
return text
def maybe_start_on_next_line(string):
# If `string` is multiline, prepend a \n to it.
if string is not None and len(string.split('\n')) > 1:
return '\n{}\n'.format(string)
return string
mutable_dict = envinfo._asdict()
# If nvidia_gpu_models is multiline, start on the next line
mutable_dict['nvidia_gpu_models'] = \
maybe_start_on_next_line(envinfo.nvidia_gpu_models)
# If the machine doesn't have CUDA, report some fields as 'No CUDA'
dynamic_cuda_fields = [
'cuda_runtime_version',
'nvidia_gpu_models',
'nvidia_driver_version',
]
all_cuda_fields = dynamic_cuda_fields + ['cudnn_version']
all_dynamic_cuda_fields_missing = all(
mutable_dict[field] is None for field in dynamic_cuda_fields)
if TORCH_AVAILABLE and not torch.cuda.is_available() and all_dynamic_cuda_fields_missing:
for field in all_cuda_fields:
mutable_dict[field] = 'No CUDA'
if envinfo.cuda_compiled_version is None:
mutable_dict['cuda_compiled_version'] = 'None'
# Replace True with Yes, False with No
mutable_dict = replace_bools(mutable_dict)
# Replace all None objects with 'Could not collect'
mutable_dict = replace_nones(mutable_dict)
# If either of these are '', replace with 'No relevant packages'
mutable_dict['pip_packages'] = replace_if_empty(mutable_dict['pip_packages'])
mutable_dict['conda_packages'] = replace_if_empty(mutable_dict['conda_packages'])
# Tag conda and pip packages with a prefix
# If they were previously None, they'll show up as ie '[conda] Could not collect'
if mutable_dict['pip_packages']:
mutable_dict['pip_packages'] = prepend(mutable_dict['pip_packages'],
'[{}] '.format(envinfo.pip_version))
if mutable_dict['conda_packages']:
mutable_dict['conda_packages'] = prepend(mutable_dict['conda_packages'],
'[conda] ')
return env_info_fmt.format(**mutable_dict)
def get_pretty_env_info():
return pretty_str(get_env_info())
def main():
print("Collecting environment information...")
output = get_pretty_env_info()
print(output)
if __name__ == '__main__':
main()
遇到的问题:
2.pytorch版本问题
no model name "maskrcnn_benchmark"
卸载pytorch,重新安装,安装pytorch-nightly,推荐安装1.2版本,使用conda命令直接安装的话安装的torchvision版本是0.4.0,卸载torchvision=0.4.0,重新安装torchvision=0.2.1,不然会报错。安装pytorch的时候下载慢的话推荐离线下载。给一个linux版的离线下载:cuda10版本的pytroch1.2
3.预训练模型下载问题,可以从github上提前下载预训练权重文件R-50.pkl,然后将文件放到C:/User/.torch/model/下,就可以开始训练了
4.windows下单GPU训练会遇到内存问题
RuntimeError: CUDA out of memory. Tried to allocate 262.50 MiB (GPU 0; 5.92 GiB total capacity; 2.83 GiB already allocated; 323.88 MiB free; 162.96 MiB cached)
选择maskrcnn_benchmark/config/defaults.py,调小_C.SOLVER.IMS_PER_BATCH ,如果还报错,把进程数也改成1
3.测试
选择配置文件e2e_mask_rcnn_R_50_FPN_1x.yaml,将里面的weight改成你训练好的.pth模型文件,demo文件夹下更改predictor.py文件
class COCODemo(object):
# COCO categories for pretty print
CATEGORIES = [
"__background",
"ore",
]
将以前coco的类别更改为自己的类别,demo文件夹下创建一个新的Test.py
from maskrcnn_benchmark.config import cfg
from predictor import COCODemo
import cv2
import os
import time
time_start=time.time()
config_file = "../configs/e2e_mask_rcnn_R_50_FPN_1x.yaml"
# update the config options with the config file
cfg.merge_from_file(config_file)
# manual override some options
cfg.merge_from_list(["MODEL.DEVICE", "cuda"])
coco_demo = COCODemo(
cfg,
min_image_size=800,
confidence_threshold=0.7,
)
file_root = '../datasets/coco/test2014/'
file_list = os.listdir(file_root)
save_out = "../output/"
time_end=time.time()
print('totally cost',time_end-time_start)
for img_name in file_list:
img_path = file_root + img_name
image = cv2.imread(img_path)
predictions = coco_demo.run_on_opencv_image(image)
save_path = save_out + img_name
cv2.imwrite(save_path,predictions)
#cv2.namedWindow("img",cv2.WINDOW_NORMAL)
#cv2.imshow("img",predictions)
#cv2.waitKey(1)
执行test.py
遇到的问题:
重新训练模型要删除存储模型文件同级目录下的last_cheakpoint中的模型路径