【Python】sklearn机器学习之层次聚类算法AgglomerativeClustering
文章目录
-
- 基本原理
- 绘图层次
- 定义距离
基本原理
和Birch聚类相似,层次聚类也是一种依赖树结构实现的聚类方法,其核心概念是相似度。根据相似度,可以将所有样本组织起来,从而构建一棵层次聚类树。
其中Birch算法的核心,叫做聚类特征树(Clustering Feature Tree),简称CF树。CF树由CF构成,每个CF都是三元组,表示为(N, LS, SS),其中N表示点数;LS表示点的向量和;SS表示CF各分量的平方和。
相比之下,层次聚类更加直接,为了说明层次聚类的特点,可以尝试绘制一下分层聚类树,其中绘图函数使用scipy中的dendrogram函数,其参数生成函数定义如下(可以不用管这个)
import numpy as np
from matplotlib import pyplot as plt
from scipy.cluster.hierarchy import dendrogram
def getLinkageMat(model):
children = model.children_
cs = np.zeros(len(children))
N = len(model.labels_)
for i,child in enumerate(children):
count = 0
for idx in child:
count += 1 if idx < N else cs[idx - N]
cs[i] = count
return np.column_stack([children, model.distances_, cs])
然后对AgglomerativeClustering算法进行测试
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=50)
model = AgglomerativeClustering(distance_threshold=0, n_clusters=None)
model = model.fit(X)
mat = getLinkageMat(model)
test = dendrogram(mat)
plt.show()
其中,distance_threshold表示距离阈值,n_clusters为聚类个数,在这里均表示自动处理,最终得到的结果如下
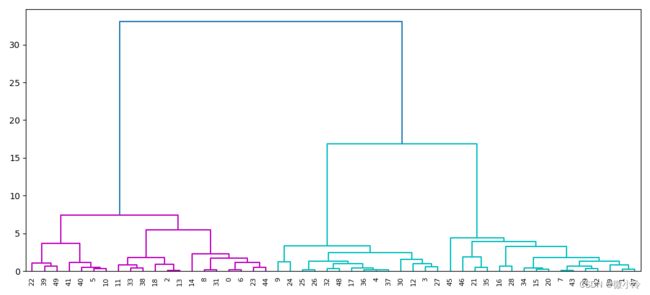
这个图横坐标表示簇的序号,纵坐标表示两个簇之间的距离。如果从上往下看,粉色的和蓝色的被明显分为两类,而后蓝色内部又被分为两类。如果以距离6为阈值,那么距离大于6的簇可分为三组。
绘图层次
通过调控dendrogram中的truncate_mode,可以修改绘图层次
test = dendrogram(mat, truncate_mode='level', p=3)
plt.show()
如下图所示,用括号括起来的横坐标表示被兼并的样本个数。

定义距离
距离越近,则越相似,则越可以被归为一类。所以,如何定义距离在层次聚类中显得十分重要,AgglomerativeClustering的构造函数中比较重要的参数如下
AgglomerativeClustering(n_clusters=2, *, affinity='deprecated',linkage='ward')
其中affinity起到定义距离的作用,下面逐一演示不同距离时的聚类情况
distances = ["euclidean", "l1", "l2", "manhattan", "cosine"]
fig = plt.figure()
for i,d in enumerate(distances):
model = AgglomerativeClustering(affinity=d,
linkage='average',
distance_threshold=0, n_clusters=None)
model = model.fit(X)
mat = getLinkageMat(model)
ax = fig.add_subplot(2,3,i+1)
plt.title(d)
test = dendrogram(mat, ax=ax, truncate_mode='level', p=3)
plt.show()

从结果来看,除了余弦距离有些诡异之外,其他情况都还可以。而且曼哈顿距离与L1,欧氏距离和L2都有极强的相似性。
此外linkage 参数有4个选项:
ward:簇的方差最小average:簇间的平均距离最小complete:簇间的平均距离最大single:单簇之间的距离最小