Pandas快速入门---------常用方法函数总结。
文章目录
- 一、数据文件的读取和查看
- 二、Pandas里的数据结构
- 三、查询数据的方法
- 四、新增、修改、删除数据方法
- 五、统计类函数
- 六、排序
- 七、字符串的处理
- 八、merge函数、Conat函数
-
- merge
- concat
- 九、groupby 分组
pandas官方文档: https://pandas.pydata.org/pandas-docs/stable/reference
panda和numpy有很多相通的地方,可以看一下我前一阵整理的numpy笔记。
- numpy常用方法总结
- numpy练习题+解析
一、数据文件的读取和查看
读取CSV文件:
CSV文件里的数据 都是用逗号分割每个值。
res = pd.read_csv(path,sep='!',header=None,names=['a','b','c'])
res就保存了文件的内容
其中:
- path是文件路径
- sep告诉系统你的数据文件以什么为分隔符
- header表明你所用的文件是否有抬头字段
- names是如果没有抬头字段,你要添加什么字段名
比如现有数据文件:
1!2!3
运行上面的代码后:
a b c
0 1 2 3
最左边的0表示索引值,可以看到按照!分割开了,并且加入abc的字段名(列名)。
该函数也可以用于读取 txt文件和tsv(用tab分割的数据)文件。
读Excel文件:
res = pd.read_excel(path)
读Mysql数据库文件:
conn = pymysql.connect(host ='127,0,0,1',
user = 'root',
password = 123,
database='test',
charst='utf8'
)
res = pd.read_sql("select * from student",con=conn)
俩参数第一个是sql语句,第二个数据库连接、
查看前几行的数据:
可以在括号里面写int数字,写几就是显示前几行,默认前五行。
print(res.head())
查看数据的形状(几行几列):
print(res.shape)
查看列名:
或者说查看字段名
print(res.columns)
查看每列(字段)的数据类型:
print(res.dtypes)
二、Pandas里的数据结构
就跟Numpy里的.ndarray类型一样,Pandas里也有专属的数据类型。
一个是Series 另一个是DataFrame。
Series
表示二维数组中的以为数组,可以理解为一行或者一列。
下面这张图是一张表格,就是一个二维数组,整体为DataFrame,其中的一行或者一列就是 Series。
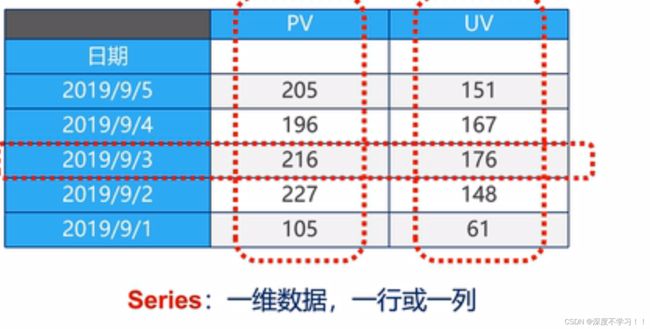
创建Series的三种方法
方法一:
a = pd.Series([1,2,3])
print(a)
输出:
0 1
1 2
2 3
dtype: int64
左边是从0开始的索引,右边是对应的值,这个索引是可以改变的。
指定索引:
a = pd.Series([1,2,3],index = (['a','b','c']))
print(a)
输出:
a 1
b 2
c 3
dtype: int64
方法二:
使用python字典来创建Series。
key变成索引,val变成值。
a = {"a":1,"b":2,"c":3}
s = pd.Series(a)
print(s)
输出:
a 1
b 2
c 3
dtype: int64
Series的查询方式和python里的字典是一样的。
DataFrame
代表整个表格,相当于二维数组。
DataFrame的创建方式也可以直接用python的字典。key为字段名(列名)。
a = {'a':[1,2,3,4,5,6],
'b':[7,8,9,10,11,12],
'c':[13,14,15,16,17,18]}
res = pd.DataFrame(a)
print(res)
输出:
a b c
0 1 7 13
1 2 8 14
2 3 9 15
3 4 10 16
4 5 11 17
5 6 12 18
或者使用numpy和pandas组合:
res= pd.DataFrame(np.arange(12).reshape(3,4),columns=['a','b','c','d'])
print(res)
输出:
a b c d
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
不过在使用DataFrame的时候几乎不会这样创建,一般都是从数据文件中创建DataFrame。
三、查询数据的方法
假设已有数据:
a b c
0 1 7 13
1 2 8 14
2 3 9 15
3 4 a 16
查询某一行
print(res.loc[1])
输出:
a 2
b 8
c 14
loc[索引值]
因为他输出的一行数据,所以类型是series。
使用索引或切片
loc也可以使用切片操作,比如loc[1:3]。此时显然要返回两行,因为两行就是二维数组了,所以类型就变成DataFrame.
但是和切片有一点区别就是 python的切片是 左闭区间右开区间,而pandas里loc的切片是左闭右闭。
loc里的方式和numpy里的一样,也可以这样使用:loc[行,列]
如:
print(res.loc[0,'b']) # 表示取 第0行 字段 ‘b’列的值
print(res.loc[:,'a']) # 表示取 第 ‘a’ 列的所有值
print(res.loc[1,:]) # 表示取 第 1 行所有的值
print(res.loc[1,'a':'b']) # 表示取 第1行的 a-b列的值,包含a和b。
输出:
7
0 1
1 2
2 3
3 4
Name: a, dtype: int64
a 2
b 8
c 14
Name: 1, dtype: object
a 2
b 8
Name: 1, dtype: object
使用判别表达式:
print(res.loc[res['a']>2,:]) # 查询a这一列中所有大于2的数据(所有列中)
print(res.loc[res['a']>2,:'a']) # 查询a这一列中所有大于2的数据 (仅在a列中)
输出:
a b c
2 3 9 15
3 4 1 16
a
2 3
3 4
这里其实和numpy一样,内部都是False和True。
这里面也可以使用匿名函数lamdba。
四、新增、修改、删除数据方法
假设已有数据:
a = {'a':[1,2,3,4],
'b':[7,8,9,1],
'c':[13,14,15,16]}
res = pd.DataFrame(a)
输出:
a b c
0 1 7 13
1 2 8 14
2 3 9 15
3 4 a 16
直接赋值、修改法:
res.loc[0,'a'] = 'x' # 修改第0行 第‘a’列数据 为‘x’。
print(res)
res.loc[:,'bb'] = res['b'] * 2 # 新增了‘bb’列,值为‘b'列的两倍。
print(res)
输出:
a b c
0 x 7 13
1 2 8 14
2 3 9 15
3 4 1 16
a b c bb
0 1 7 13 14
1 2 8 14 16
2 3 9 15 18
3 4 1 16 2
从这个例子里也可以看出来loc的好处是,有这个数据就用,没有这个数据就新建。
使用apply函数
# 定义一个函数
def fun(s):
return s['b']
res.loc[:,'新增列和b相同'] = res.apply(fun,axis=1)
print(res)
输出:
a b c 新增列和b相同
0 1 7 13 7
1 2 8 14 8
2 3 9 15 9
3 4 1 16 1
这里可以写匿名函数。注意这里的传值,apply函数参数第一个是函数,第二个是轴的反向。axis=1是行方向,就是新增的列的每一行上操作。
且这里函数的传参s传入的是整个表格。
apply还有map函数和applymap函数。
- map:只用于Series,实现对每个值的映射。
- apply:用于Series 对每个值处理,用于DataFrame对每个轴也就是Series处理。
- applymap:只用于DataFrame,对每个元素逐一处理。
assign方法
该方法和apply一样,但是apply每次只增加一列,这个函数可以一次增加多个列。
ss = res.assign(
新增列和b相同 = lambda x:x['b'],
新增列和c相同 = lambda x:x['c']
)
print(ss)
输出:
a b c 新增列和b相同 新增列和c相同
0 1 7 13 7 13
1 2 8 14 8 14
2 3 9 15 9 15
3 4 1 16 1 16
assign方法会返回一个新的对象,不会对原来的数据产生影响,这点和apply不同。
按条件赋值、修改
res['我是新列'] = '' # 创建一个空的新列
res.loc[res['a']>2,'我是新列'] = '你大' # ’a‘列大于2的行,在新列中复制 ’你大‘
print(res)
输出:
a b c 我是新列
0 1 7 13
1 2 8 14
2 3 9 15 你大
3 4 1 16 你大
删除某一行或列
使用drop()函数,删除后返回一个新的对象,对原来的数据不做修改。
原有数据:
a b c
0 1 7 13
1 2 8 14
2 3 9 15
3 4 1 16
s = res.drop('a',axis=1)
删除后输出:
b c
0 7 13
1 8 14
2 9 15
3 1 16
五、统计类函数
现有数据:
a b c
0 1 7 13
1 2 8 14
2 3 9 15
3 4 1 16
存放在res中。
各种数据汇总统计
describe() 函数,统计输出每列的计数,平均值最大最小值,各类别所占百分比等。
res.describe()
输出:
a b c
count 4.000000 4.000000 4.000000
mean 2.500000 6.250000 14.500000
std 1.290994 3.593976 1.290994
min 1.000000 1.000000 13.000000
25% 1.750000 5.500000 13.750000
50% 2.500000 7.500000 14.500000
75% 3.250000 8.250000 15.250000
max 4.000000 9.000000 16.000000
也可以直接操作某个字段,比如res.['字段名'].max
unique函数
去重函数,可以看到某个字段下所有类型的值,一般使用在非数字字符上。比如:res['字段名'].unique()
value_counts
按值记数函数,查看某个字段下面的各个类型所有的个数,比如res['字段名'].value_counts()
相关系数和协方差
- 协方差:衡量同向反向的程度,如果协方差为正,则说明x,y同向变化,协方差越大说明同向程度越高;若协方差为负,说明x,y反向运动,协方差越小说明反向程度越高。
- 相关系数:衡量相似程度,当他们相关系数为1时,说明两个变量变化的正向相似度最大,当相关系数为-1时,说明两个变量变化的反向相似度最大。
res.cov() # 协方差矩阵
res.corr() # 相关系数矩阵
res["A"].corr(res["B"]) # 查看A和B的相关系数
res["A"].corr(res["B"]-res["C"]) # 查看A和b-c的差的相关系数
六、排序
Series的排序
pd.Series.sort_values(ascending=True,inplace=False)
- ascending 参数:默认为True 升序,为False降序
- inplace参数 :是否修改原数据
DataFrame的排序
pd.DataFrame.sort_values(by,ascending=True,inplace=False)
- by 参数:指定列名(axis=0或’index’)或索引值(axis=1或’columns’)
可以合并指定某些字段升序某些字段降序:res.sort_values(by=['a','b'],ascending=[True,False]) (数据在res里,字段a升序,字段b降序)
七、字符串的处理
- 先获取Series的str属性,然后再使用str的函数
- 数字列上不能用
- DataFrame上没有str属性处理和方法,也就是说从DataFrame上取出来某一行或者某一列再用str方法
- Series.str并不是原生的python的str方法,而是有自己的一套,只不过和python的比较相似。
- Series.str 默认开启正则表达式模式,可以用正则。
比如:print(res['a'].str.replace('1','2')
将a列中的字符‘1’替换成‘2’,如果a列中有数字,则即使没有操作该数字字符,输出的时候也会变成Nan。
其他的和python基本一样,并且支持链式操作。
链式操作示例
使用链式操作的时候,应该是这样的: res['a'].str.replace.str.slice() 不能忽略每一个函数前面的str。
正则操作示例
res['c'].str.replce("[ABC]"," ") 将字段c中的A或B或C字符替换成空值。
八、merge函数、Conat函数
merge
merge是个用于合并的函数,和mysql里的join左右连接相似。
函数格式:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,left_index=False, right_index=False, sort=True,suffixes=('_x', '_y'), copy=True)
- left/right 两个不同的 DataFrame 对象。
- on 指定用于连接的键(即列标签的名字),该键必须同时存在于左右两个 DataFrame 中,如果没有指定,并且其他参数也未指定, 那么将会以两个 DataFrame 的列名交集做为连接键。
- left_on 指定左侧 DataFrame 中作连接键的列名。该参数在左、右列标签名不相同,但表达的含义相同时非常有用。
- right_on 指定左侧 DataFrame 中作连接键的列名。
- left_index 布尔参数,默认为 False。如果为 True 则使用左侧 DataFrame 的行索引作为连接键,若 DataFrame 具有多层
索引(MultiIndex),则层的数量必须与连接键的数量相等。 - right_index 布尔参数,默认为 False。如果为 True 则使用左侧 DataFrame 的行索引作为连接键。
- how 要执行的合并类型,从 {‘left’, ‘right’, ‘outer’, ‘inner’} 中取值,默认为“inner”内连接。
- sort 布尔值参数,默认为True,它会将合并后的数据进行排序;若设置为 False,则按照 how 给定的参数值进行排序。
- suffixes 字符串组成的元组。当左右 DataFrame 存在相同列名时,通过该参数可以在相同的列名后附加后缀名,默认为(‘_x’,‘_y’)。
- copy 默认为 True,表示对数据进行复制。
示例:
现有数据:
left:
id Name subject_id
0 1 Smith sub1
1 2 Maiki sub2
2 3 Hunter sub4
3 4 Hilen sub6
right:
id Name subject_id
0 1 William sub2
1 2 Albert sub4
2 3 Tony sub3
进行合并:
#通过on参数指定合并的键
print(pd.merge(left,right,on='id'))
输出:
id Name_x subject_id_x Name_y subject_id_y
0 1 Smith sub1 William sub2
1 2 Maiki sub2 Albert sub4
2 3 Hunter sub4 Tony sub3
3 4 Hilen sub6 Allen sub6
也可以指定多个合并的键:
print(pd.merge(left,right,on=['id','subject_id'])) # 指定id和 subject_id
输出:
id Name_x subject_id Name_y
0 4 Hilen sub6 Mike
在指定多个键进行合并的时候,只有相同的才能合并,在上面的例子里,left和right两个表格中,subject_id 只有在第四行 id为4的时候subject_id的值是相同的,都为sub6,所以才能合并,输出了这一行,如果将第一行都改成sub2,则这一行也会输出。
总结一下merge实际上就是下面几点:
- 一对一的关系 ,比如(学号,姓名) merge(学号,年龄),结果为 1 * 1
- 一对多的关系,左边唯一,右边不唯一。比如(学号,姓名) merge (学号,[数学分,语文分,英语分]),结果为 1 * N
- 多对多的关系,比如(学号,[语文分,数学分]) merge (学号,[篮球,排球]) 结果为 M * N
一对多关系演示:
现有数据:
left = pd.DataFrame({
'id':[11,12,13,14],
'Name': ['Smith', 'Maiki', 'Hunter', 'Hilen'],
})
right = pd.DataFrame({
'id':[11,11,11,12,12,13],
'grad': ['语文88', '数学99', '英语77', '语文11','数学44','英语77'],
})
输出:
id Name
0 11 Smith
1 12 Maiki
2 13 Hunter
3 14 Hilen id grad
0 11 语文88
1 11 数学99
2 11 英语77
3 12 语文11
4 12 数学44
5 13 英语77
合并:
print(pd.merge(left,right,on=['id']))
id Name grad
0 11 Smith 语文88
1 11 Smith 数学99
2 11 Smith 英语77
3 12 Maiki 语文11
4 12 Maiki 数学44
5 13 Hunter 英语77
可以看到一对多合并的过程,以右边为准,左边复制了好几条name。
多对多关系演示:
现有数据:
left = pd.DataFrame({
'id':[11,11,12,12,12],
'Name': ['篮球', '羽毛球', '乒乓球', '排球','水球'],
})
right = pd.DataFrame({
'id':[11,11,11,12,12,13],
'grad': ['语文88', '数学99', '英语77', '语文11','数学44','英语77'],
})
id Name
0 11 篮球
1 11 羽毛球
2 12 乒乓球
3 12 排球
4 12 水球 id grad
0 11 语文88
1 11 数学99
2 11 英语77
3 12 语文11
4 12 数学44
5 13 英语77
多对多合并:
print(pd.merge(left,right,on=['id']))
输出:
id Name grad
0 11 篮球 语文88
1 11 篮球 数学99
2 11 篮球 英语77
3 11 羽毛球 语文88
4 11 羽毛球 数学99
5 11 羽毛球 英语77
6 12 乒乓球 语文11
7 12 乒乓球 数学44
8 12 排球 语文11
9 12 排球 数学44
10 12 水球 语文11
11 12 水球 数学44
关于 inner join、right join 、left join 、full outer
看下面的图就懂了,left join 就是以左边的数据为准,右边也有的话就补充,左边没有 ,右边有的数据就扔掉,其他的同理。
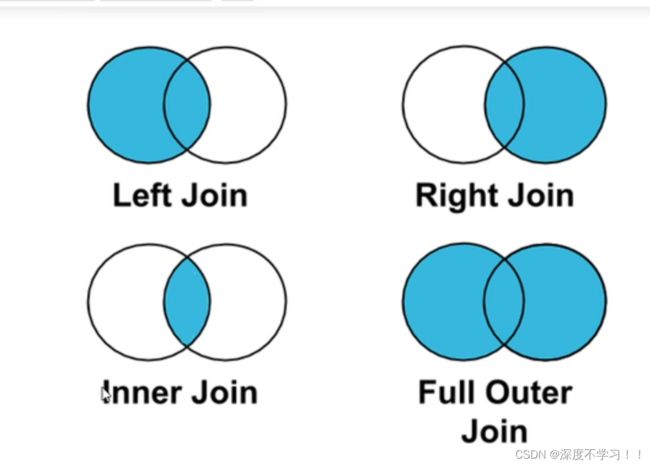
concat
连接函数
concat语法: pd.concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False)
- objs 一个序列或者是Series、DataFrame对象。
- axis 表示在哪个轴方向上(行或者列)进行连接操作,默认 axis=0 表示行方向。
- j oin 指定连接方式,取值为{“inner”,“outer”},默认为 outer 表示取并集,inner代表取交集。
- ignore_index 布尔值参数,默认为 False,如果为 True,表示不在连接的轴上使用索引。
join_axes 表示索引对象的列表。
这个比较简单直接看示例、
现有数据:
df1 = pd.DataFrame([['a', 1], ['b', 2]],
columns=['letter', 'number'])
df3 = pd.DataFrame([['c', 3, 'cat'], ['d', 4, 'dog']],
columns=['letter', 'number', 'animal'])
输出:
letter number
0 a 1
1 b 2
letter number animal
0 c 3 cat
1 d 4 dog
进行纵向合并:
print(pd.concat([df1, df3], axis=1,sort=False)) # axis=1指纵向合并
输出:
letter number animal
0 a 1 NaN
1 b 2 NaN
0 c 3 cat
1 d 4 dog
对于俩个格式不相同的数据,对于缺少的直接变成NaN,如果想只留下共有的,则加入参数 join=‘inner’。
九、groupby 分组
pandas里的分组和mysql里的分组相似,就用一个实例来看一下。
现有数据:
data1 data2 key1 key2
0 0.974685 -0.672494 a one
1 -0.214324 0.758372 b one
2 1.508838 0.392787 a two
3 0.522911 0.630814 b three
4 1.347359 -0.177858 a two
5 -0.264616 1.017155 b two
6 -0.624708 0.450885 a one
7 -1.019229 -1.143825 a three
进行分组:
# 分组运算
grouped1 = df_obj.groupby('key1') # 按照key1进行分组
print(grouped1.mean()) # 对分组后的每个组求平均
grouped2 = df_obj['data1'].groupby(df_obj['key1']) # dataframe的 data1 列根据 key1 进行分组
print(grouped2.mean())
输出:
data1 data2
key1
a 0.437389 -0.230101
b 0.014657 0.802114
key1
a 0.437389
b 0.014657
Name: data1, dtype: float64
对于分组同样也支持遍历 使用不同函数等操作。