手把手学习numpy库之 —— numpy进阶教程2
一、形状操作与生成函数
1. ndarray形状操作
(1)生成0~9的ndarray
arr0 = np.arange(10)
(2) 把arr0的形状转换为2行5列
arr0.reshape(2,5)
(3)在(1)的基础上在arr0的第一个维度前增加一个维度,变为(1,10)
arr1 = arr0[np.newaxis, :]
print(arr1)
print(arr1.shape)
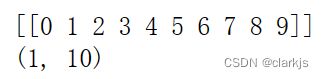
(4)把arr0的形状改为(10,1)
arr2 = arr0[:, np.newaxis]
print(arr2)
print(arr2.shape)
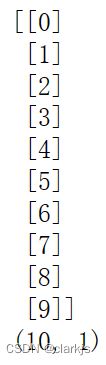
(5)把arr0的形状改为(10,1,1)
arr3 = arr0[:, np.newaxis, np.newaxis]
print(arr3)
print(arr3.shape)

(6)去掉ndarray无效的维度
arr4 = arr3.squeeze()
arr4.shape
执行后,shape由原来的(10,1,1)变为了(10,),删除了无效的维度
(7)拼接操作
a = np.array([[1,2,0],
[3,4,2]])
b = np.array([[6,7,4],
[8,0,7]])
# 别少括号,最外面括号是concatenate方法,里面的括号表示第一个参数是元组形式(axis默认值为0)
c = np.concatenate((a,b), axis = 0)
print('concat with axis 0: ', c)
d = np.concatenate((a,b), axis = 1)
print('concat with axis 1: ', d)

(8)拉伸成一个维度
a.flatten()
2. 数组生成函数
(1)生成0~9的ndarray
np.arange(10)
(2)生成2,4,6 ··· 18
np.arange(2,20,2)
(3)生成浮点数2,4,6 ··· 18
np.arange(2,20,2,dtype=np.float32)
(4)在A~B之间构造C个数
np.linspace(0,10,20)

np.logspace(0, 1, 5)
![]()
(5)构建行向量和列向量
print('行向量:',np.r_[0:10:1])
print('列向量:',np.c_[0:10:1])

(6)zeros, ones生成函数
例1:
arr1 = np.zeros(3)
print(arr1)
print(arr1.shape)

例2:
arr2 = np.ones(3)
print(arr2)
print(arr2.shape)

例3:
arr3 = np.zeros((3,3))
print(arr3)
print(arr3.shape)

(7)构造全为8的5*5矩阵
arr4 = np.ones((5,5))*8
print(arr4)
print(arr4.shape)

(8)构造全为浮点8的5*5矩阵
arr5 = np.ones((5,5),dtype=np.float32)*8
(9)zeros_like生成函数
b = np.array([1,2,3,4])
c = np.zeros_like(b)
print(c)
d = np.ones_like(b)
print(d)
注:zeros_like产生的ndarray的shape和原来的shape一致
(10)构建对角矩阵
e = np.identity(5)

二、四则运算与random模块
1. 四则运算
(1)multiply与dot
例1:
x = np.array([5, 5])
y = np.array([2, 2])
print('multiply: \n',np.multiply(x,y))
print('dot: \n',np.dot(x,y))
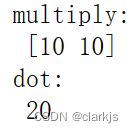
注:multiply是对应位置相乘,dot是矩阵运算(内积)。因此要求计算时x,y的维度相同
例2:
# 由于x,y维度不一样,dot会报错
x = np.array([5, 5])
x.shape=2,1
y = np.array([2, 2])
print('multiply: \n',np.multiply(x,y))
# print('dot: \n',np.dot(x,y))

例3:
x = np.array([5, 5])
x.shape=2, 1
y = np.array([2, 2])
y.shape=1, 2
print('multiply: \n',np.multiply(x,y))
print('dot(x,y): \n',np.dot(x,y))
print('dot(y,x): \n',np.dot(y,x))

(2)*运算
a = np.array([1, 1, 1])
b = np.array([[1, 2, 3],
[4, 5, 6]])
print('a*b=',a*b)
注:这里自动进行了广播操作,将a的形状reshape成适当的shape
2. random模块
(1)产生10个0~1之间的随机数
np.random.rand(10)
(2)从0~10之间取5*4个整数 && 从0~9之间随机取20个整数
bb = np.random.randint(10, size=(5,4))
print(bb)
cc = np.random.randint(0, 10, 20)
print(cc)

(3)只随机产生一个0~1之间的数
np.random.rand()
(4)构造随机序列,使得这个序列满足高斯分布(超参数自己指定)
例1:
miu = 0
sigma = 1
np.random.normal(miu,sigma,10)

例2:
# 可以人为设定保留小数的精度
np.set_printoptions(precision=2)
miu = 0
sigma = 1
np.random.normal(miu,sigma,10)

(5)shuffle操作
# 洗牌(每次shuffle的结果是不同的)
ddd = np.arange(10)
print(ddd)
np.random.shuffle(ddd)
print('after shuffle: ',ddd)
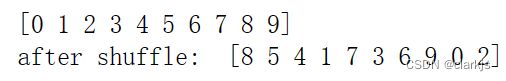
可以通过指定随机数种子来固定shuffle,使得每次shuffle结果相同
np.random.seed(1)
np.random.randint(0,10,20)
![]()
三、文件读写与数组保存
(1)建立test_doc.txt并写入两行数据
%%writefile test_doc.txt
1 2 3 4 6
5 8 3 2 9
(2)使用python手撕逐行读取过程
# 使用python逐行读取
data = []
with open('test_doc.txt') as f:
for content in f:
tmp = content.split()
cur_data = [float(x) for x in tmp]
data.append(cur_data)
data = np.array(data)
print(data)

(3)使用numpy读取文件更加方便
data1 = np.loadtxt('test_doc.txt')
print(data1)
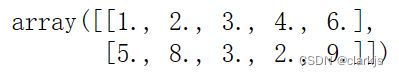
(4)指定分隔符
loadtxt默认逗号为分隔符,因此如果文件分隔符为其他,需要在参数中指定
%%writefile test_doc2.txt
1,2,3,4,6
5,8,3,2,9
data2 = np.loadtxt('test_doc2.txt', delimiter = ',')
print(data2)
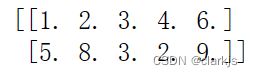
(5)对文件删除(某行)
%%writefile test_doc2.txt
x,y,s,f,g
1,2,3,4,6
5,8,3,2,9
# skiprows表示去掉前几行,不是第几行(usecol函数略)
data3 = np.loadtxt('test_doc2.txt', delimiter = ',',skiprows=1)
print(data3)
(6)其他常用参数
# 自己写一个ndarray,保存成txt,指定分隔符,小数点(注意:下面这两个delimiter要一致)
ldk = np.array([[1,2,3],
[4,5,6]])
np.savetxt('test_doc2.txt',ldk,fmt='%.2f',delimiter=',')
tmp = np.loadtxt('test_doc2.txt',delimiter = ',')
tmp
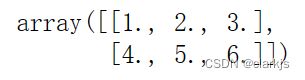
(7)npy格式
# 自己写一个ndarray,保存成npy,然后读出来
ldk = np.array([[1,2,3],
[4,5,6]])
np.save('test1.npy',ldk)
data_content = np.load('test1.npy')
data_content
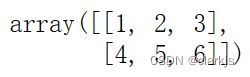
(8)npz格式
# 自己写一个ndarray,保存成npz,然后读出来
a = np.array([[1,2,3],
[4,5,6]])
b = np.arange(5)
np.savez('ldk.npz',cc = a, dd = b)
data = np.load('ldk.npz')
print(data.keys())
print('\n\n\n')
print(data['cc'])
print('\n\n\n')
print(data['dd'])
