Transformer由来——A Tutorial of Transformers课程笔记
邱锡鹏老师在B站上的Transformer课程将Transformer的来历讲的非常清楚,可谓Transformer最佳答疑解惑。本篇记录下课程的一些笔记和思考,欢迎大家讨论。
参考资料:
1. Transformers课程:https://www.bilibili.com/video/BV1sU4y1G7CN/
2,论文: "Attention is all you need." https://arxiv.org/pdf/1706.03762
3, ”A Tutorial of Transformers“ 邱锡鹏. 复旦大学,
目录
一、NLP的一般结构
二、自注意力的发展历程
三、主流网络的复杂度分析
四、主流网络的优缺点对比
一、NLP的一般结构
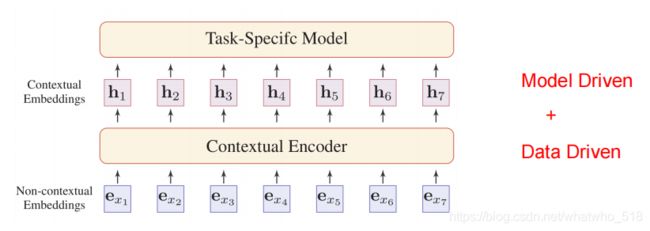
上图是NLP的一般结构,输入是没有上下文信息的单个词/字的embedding,经过上下文编码器(contextual encoder)得到含有上下文信息的单个词/字的embedding,继续输入下游任务的模型。
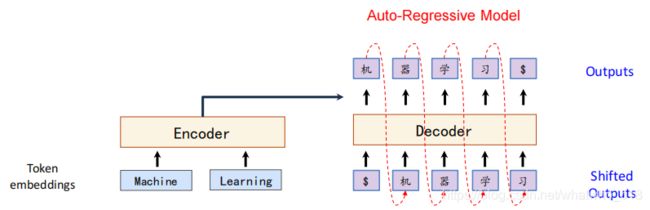
遵循上面的一般架构在nlp的机器翻译应用中的一般结构。一个最经典的模型如下seq2seq。
训练的时候输入实际上是"machine learning"和右移的"机器学习",然后让预测每个位置的输出。
解码器和编码器都是单独的网络模型,但是解码器设计有不同,因为不能看到后面的字 。 Transformer设计的主干结构和下面的一模一样。只不过encoder里面堆叠了若干自注意力层,decoder里面堆叠了若干自注意力层,
二、自注意力的发展历程

1,主流的神经网络
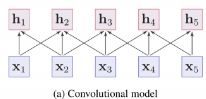
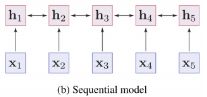
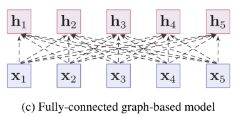
上图是三种主流的神经网络,a是卷积网络,拥有局部关系建模能力;b是序列模型,也拥有局部关系建模能力;C是全连接模型,拥有全局关系建模能力。
2,语言模型的自注意力结构如下(参照全连接模型):
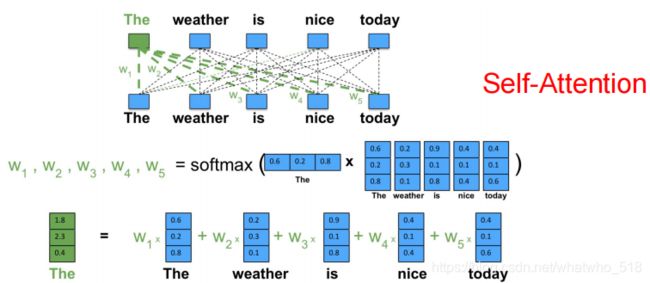
【无参】nlp中的注意力机制举例!但是上面的注意力机制有局限性,参数太少,注意力的泛化能力有限。
3,QKV模型(针对上面结构的改进有QKV模型)如下: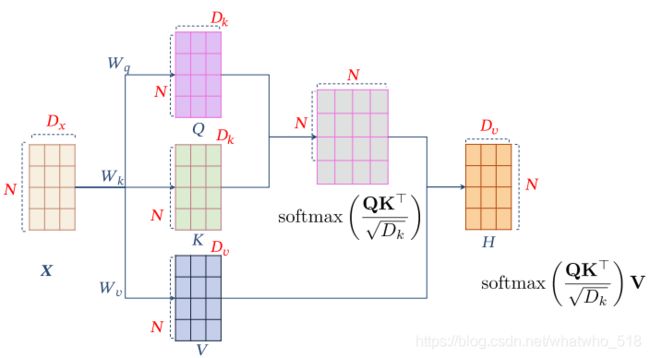
【有参】经典的QKV结构,比起上面简单的注意力机制,多了些参数,有了更强的表征能力!
4,多头自注意力模型如下:
【有更多的参数】多头QKV结构,多个head具有更多样化的表征能力,每个head可以表示不同域的信息,比如第一个多头可以注意问文本中的动宾短语结构,第二个多头可以更注意介词短语结构等。
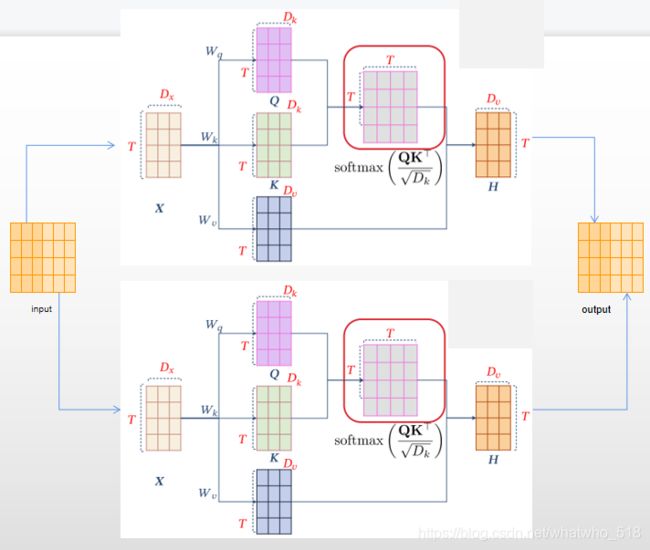
5,多层自注意力
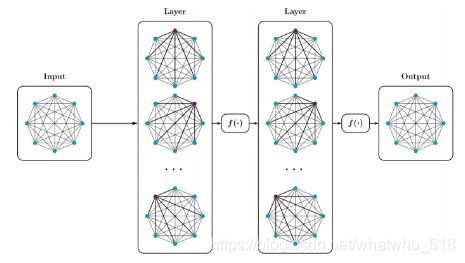
【有更多的参数】深浅不同层次的能力,堆叠的self-attention层
6,Transformer
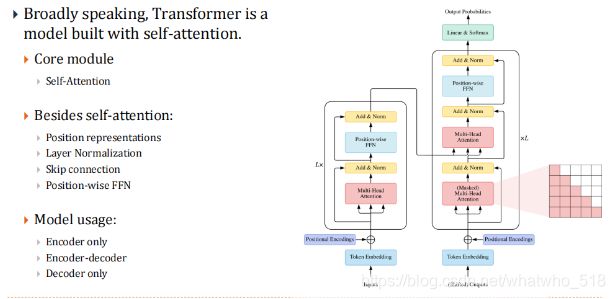
【深浅层,多头参数】Transformer诞生!
三、主流网络的复杂度分析

上图T是序列长度,D是序列维度,K是卷积核的大小。图中第二列(Complexity per layer)是网络每层的复杂度;第三列(sequential operations)是序列操作的复杂度,表示该架构是否适合并行处理;第四列(maximum path length)是最大路径长度,表示一段文本中最远的两个词需要多少次操作可以建立关系
网络结构的复杂度方面:自注意力网络和全连接网络对于长文本复杂度都过高(注:是![]() 的关系)。
的关系)。
序列操作的复杂度方面:除了循环网络还是都挺适合并行化处理的。
最大路径长度方面:自注意力网络和全连接网络该值是最小的,这是因为文本中最远的两个词全连接一条线就可以连接,所以是O(1);卷积网络由于有大小为K的卷积核存在所以是O(![]() );而循环网络是最慢的,每个词都需要上一个词作为输入。
);而循环网络是最慢的,每个词都需要上一个词作为输入。
四、主流网络的优缺点对比

卷积网络:平移不变性(因为空间位置共享kernel),局部关系建模能力(kernel大小有限)
循环网络:时序不变性(在时间轴上共享),局部关系建模能力(马尔可夫链)
Transformer:没有结构先验(小体量的数据集极易过拟合),排列同变性(由于没有位置关系所以需要位置编码)
Transformer vs 图神经网络: Transformer 可以看成全连接的图网络