Tensorflow keras 激活函数
激活函数的作用
激活函数是神经网络的重要组成部分。通过激活函数,可以让神经网络很好的解决非线性问题。在最初的阶段,使用的激活函数是sigmoid函数。但是此激活函数存在严重的梯度消失问题,在近期经常使用的是relu激活函数,而且出现了很多的变种relu函数。本文主要介绍tensorflow中keras部分的激活函数。
keras中的激活函数
keras中定义了多种的激活函数,几乎涵盖了所有的激活函数:
| 激活函数 | 描述 |
|---|---|
| relu | relu激活函数(修正线性单元) |
| elu | elu激活函数 |
| selu | selu激活函数 |
| softmax | converts a real vector to a vector of categorical probabilities |
| sigmoid | Sigmoid 激活函数 |
| hard_sigmoid | Hard sigmoid activation function |
| tanh | Hyperbolic tangent activation function |
| softsign | Softsign activation function, softsign(x) = x / (abs(x) + 1). |
| linear | 线性激活函数 |
| exponential | 指数激活函数 |
| softplus | Softplus activation function, softplus(x) = log(exp(x) + 1) |
线性激活
线性激活函数主要是relu类型的激活函数。线性激活函数是非饱和的激活函数,就是激活函数的输出是没有上限的。这一点与sigmoid激活函数不同。这样的激活函数可以解决梯度消失的问题。
relu是一组激活函数,在relu的基础上有elu、gelu等等。这些激励函数的相同点是f(x)在x>0的时候,都取值x。而在x<0的时候,稍有不同。
relu函数解决了梯度消失的问题,提高了收敛速度。relu激励函数:
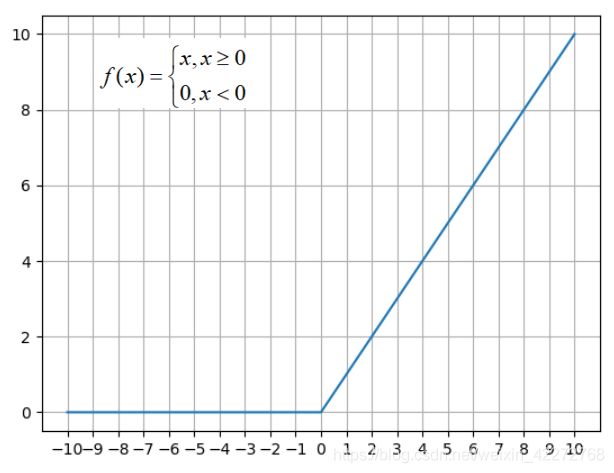
在后来的研究中,发现单纯的将x<0等情况都取值为0不是很好,改进的方法是让x<0的时候取一个很小的值。这就是leaky_relu:
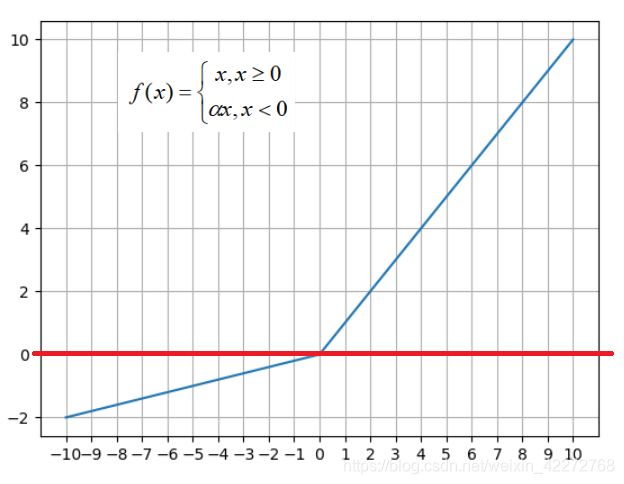
leaky_relu解决了Relu函数进入负值区间后,神经元不学习的问题。在此基础上,有衍生了PReLU。与leaky_relu不同,PReLU的a取值是变化的,不再是一个固定不变的数值。
TensorFlow也提供了linear线性激活函数,此函数的表达式是f(x)=x。不过在实际的应用中,很少会使用。
指数型激活函数
指数型激活函数使用的是指数函数。tf.keras.activations.exponential的函数表达式如下:
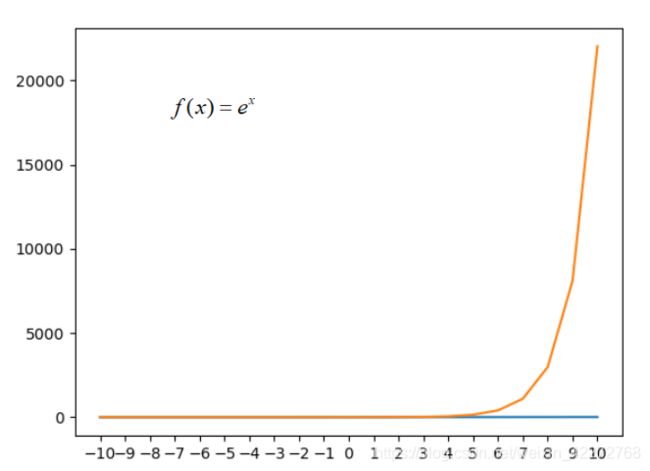
指数激活函数的输出比线性激活函数的输出还要增加的多,因此在此基础上提出了改进的指数函数:softplus。此函数对指数函数取自然对数,改进了激活函数。
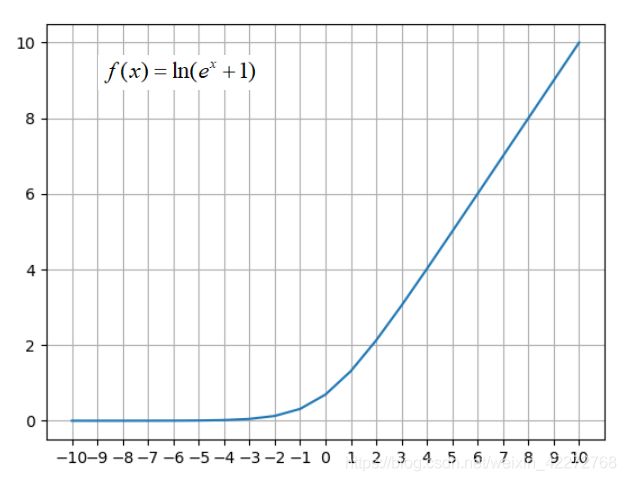
与relu比较可以发现,这两个函数非常类似。不过relu简单而且计算速度快,比softplus更快捷。
混合型
混合型在x为正数的区域使用线性函数,而在x为负值的区域取指数型激活函数。
ELU在负值区域使用的指数函数,不再是简单的线性的函数。也就是说,在负值区域如果出现很大的负值数据,也不会产生巨大的幅度调整。相当于在正值区域使用了非饱和激活函数,而在负值区域使用了饱和激活函数。此激活函数在通常的情况下,不如relu效果好。因为需要花费计算时间,而且一般情况下,训练数据不会出现巨大的奇异值。在计算的时候,都会采用预处理的方式将这些干扰数据去除。
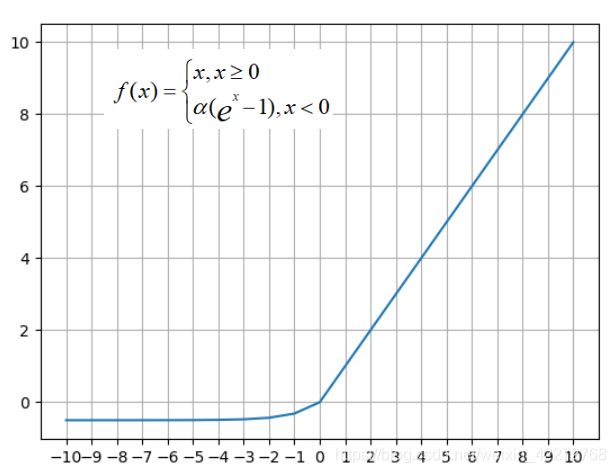
SELU是ELU的变体,他在ELU的基础上,乘以了固定的一个常数。在Tensorflow,此常数是:alpha=1.67326324 和 scale=1.05070098。
softmax
softmax激活函数用于多分类神经网络的输出。比如手写数字0-9的识别,输出是10个,就可以使用softmax激活函数。softmax的激活函数定义为:
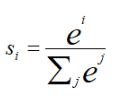
softmax的激活函数返回的是一个向量,向量中每一个元素的值在[0,1]之间,而且所有元素的和为1。所以softmax也是一种归一化函数。
需要注意的是,tf.keras中的softmax与tf.nn中softmax的实现稍有区别。
饱和激活函数
饱和激活函数的输出是有范围的。最常见的是sigmoid:
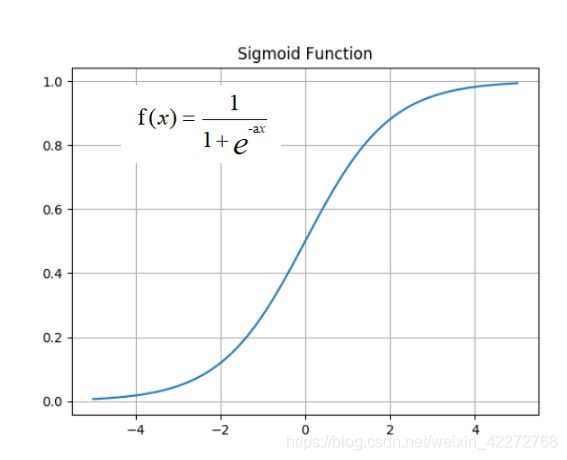
另一种激活函数与sigmoid类似,叫双曲正切激活函数(tanh),也叫双极型sigmoid激活函数。
与tanh类似的还有一种叫softsign。softsign=x/(abs(x)+1)
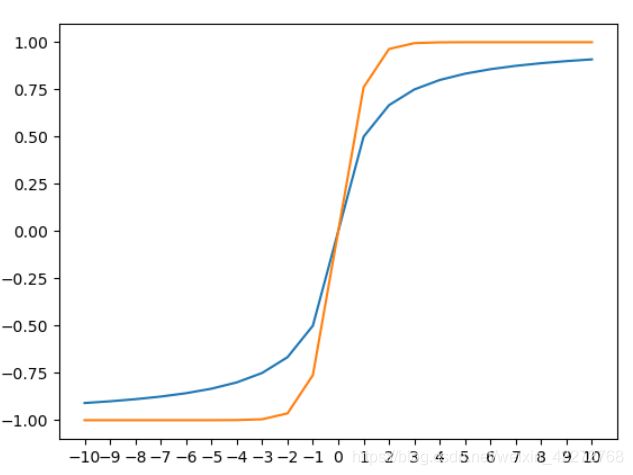
蓝颜色的是softsign,黄颜色的是tanh,可以发现他们非常类似。
阶跃型
这种函数相当于电路中的门电路,只有两个取值,0或者1。
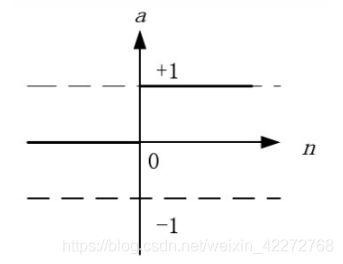
一般只在理论中会用到这种激活函数,现实中基本不用。