正则表达式
目录
介绍:
常见匹配模式:
一,re.match()方法的使用
1,最常规的匹配
2.泛匹配
3.匹配目标--分组匹配
4.贪婪匹配
5.非贪婪匹配
6.匹配模式
7.转义
二.re.search()方法的使用
三.匹配演练
四, re.findall()
五,re.sub()
介绍:
1.正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特殊字符及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种逻辑过滤。
2.非python独有
3.python里面是使用re模块来实现的,不需要额外进行安装,是python内置模块
常见匹配模式:
| 模式 | 描述 |
| \w | 匹配字母数字及下划线 |
| \W | 匹配非字母数字下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]. |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9] |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符 |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符 |
| * | 匹配0个或多个的表达式。 |
| + | 匹配1个或多个的表达式。 |
| ? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| {n} | 精确匹配n个前面表达式 |
| {n,m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a|b | 匹配a或b |
| () | 匹配括号内的表达式,也表示一个组 |
| [...] |
用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
一,re.match()方法的使用
re.match() 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回None。
1,最常规的匹配
import re #导包
content = 'Hello 123 456789 World_This is a Regex Demo' # 准备好的待匹配字符串
res = re.match('^Hello\s\d\d\d\s\d{6}\s\w{10}.*Demo$', content)
print(res) # 返回的是一个匹配对象
print(res.group()) # .group()获取匹配内容
print(res.span()) # 查看匹配长度
print(len(content)) # len统计字符串数量
'''
Hello 123 456789 World_This is a Regex Demo
(0, 43)
43
''' 2.泛匹配
import re
content = 'Hello 123 4567 World_Thixs is a Regex'
result = re.match('He.*?Regex',content)
print(result.group()) # 获取匹配内容
print(result.span()) # 获取匹配长度
'''
Hello 123 4567 World_Thixs is a Regex
(0, 37)
'''3.匹配目标--分组匹配
为了匹配字符串中具体的目标,可以使用()进行分组匹配
import re
content = 'qwe Hello 1234567 World_This is a Regex Demo'
result = re.match('^qwe\s(\w+)\s(\d{7}).*Demo$',content)
print(result.group()) # 获取匹配内容
print(result.group(1)) # 提取第一组表达式内匹配到的字符
print(result.group(2)) # 提取第二组表达式内匹配的字符
'''
qwe Hello 1234567 World_This is a Regex Demo
Hello
1234567
'''4.贪婪匹配
尽可能多的去匹配
import re
# 匹配尽可能多的字符
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^He.*(\d+)\s.*Demo$', content)
print(result)
print(result.group(1))
'''
7
''' 5.非贪婪匹配
尽可能少的去匹配
import re
# 匹配尽可能少的字符
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^He.*?(\d+).*Demo$', content)
print(result)
print(result.group(1))
6.匹配模式
import re
# re.S :匹配包括换行在内的所有字符
content = '''Hello 1234567 World_This
is a Regex Demo
'''
result = re.match('^He.*?(\d+).*Demo$', content,re.S)
print(result)
print(result.group(1))7.转义
import re
content = 'price is $5.00'
result = re.match('price\sis\s$5.00', content)
print(result)
'''
None
'''
import re
# \表示转义,加在特殊字符的前面,表示它不是正则里的匹配符号,而是普通文本
content = 'price is $5.00'
result = re.match('price\sis\s\$5\.00', content)
print(result)
print(result.group())总结:尽量使用泛匹配、使用括号得到匹配目标、尽量使用非贪婪模式、有换行符就用re.S
二.re.search()方法的使用
re.search() 扫描整个字符串并返回第一个成功的匹配。
import re
content = 'Extroa stings Hello 1234567 World_This is a 66666666 RDemogex Demo Extra stings'
result = re.search('He.*?(\d+).*?Wor.*?s$', content)
print(result)
print(result.group(1))三.匹配演练
html = ''''''
# 用正则匹配出 --- 齐秦 往事随风 唯一特性一定要用字符串匹配字符串
import re
r = re.search('(.*?)', html) # 在匹配目标值的时候一定要给定前后特征字符
print(r.group(1))
print(r.group(2))
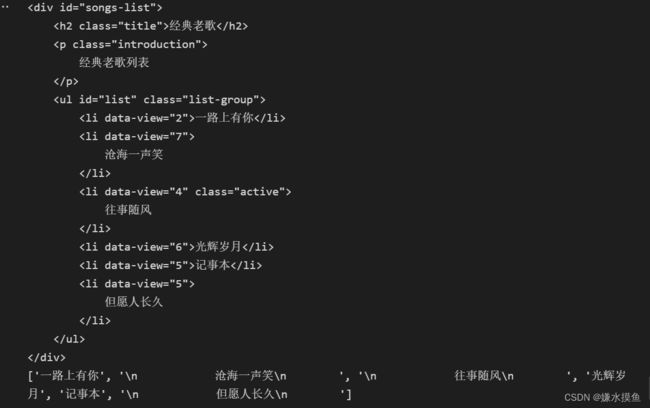
四, re.findall()
前面的match()以及search()都只能匹配到第一个
html = ''''''
# 拿到所有的链接,歌手和歌曲名
# 用正则匹配出 --- 所有的链接,歌手和歌手名
import re
r = re.findall('(.*?)',html,re.S)
print(r) 五,re.sub()
替换字符串中每一个匹配的字符
import re
content = 'Extra stings Hello 1234567 World_This is a Regex Demo Extra stings'
# 第一个参数 正则表达式
# 第二个参数 :要替换的新字符
# 第三个参数:原字符串
content = re.sub('s', '7', content)
print(content)
import re
content = 'Extra stings Hello 1234567 World_This is a Regex Demo Extra stings'
content = re.sub('\d+', '666', content)
print(content)
import re
content = 'Extra stings Hello 1234567 World_This is a Regex Demo Extra stings'
# 要替换的内容是在包含原字符串的本身后面去追加,要加括号
# \1表示保留原字符串,r表示追加, 空格后面为要追加的内容
content = re.sub('(\d+)',r'\1 3333', content)
print(content)
import re
html = ''''''
# | 表示或
html = re.sub('|','', html)
print(html) # a标签都被替换掉了
r = re.findall('(.*?)',html,re.S)
print(r)