OpenAI GPT
1.OpenAI GPT
OpenAI 在论文《Improving Language Understanding by Generative Pre-Training》中提出了 GPT 模型,后面又在论文《Language Models are Unsupervised Multitask Learners》提出了 GPT2 模型。GPT2 与 GPT 的模型结构差别不大,但是采用了更大的数据集进行实验。
GPT采用的训练方法分为两步,第一步利用没有标签的文本数据集训练语言模型,第二步更加具体的下游任务,例如QA,文本分类等对模型进行微调,BERT也沿用了这一训练方法。
预训练
GPT预训练的方式和传统的语言模型一样,通过上文,预测下一个单词;GPT预训练的方式是使用Mask LM,只能通过上文预测单词,例如给定一个句子 [u1, u2, ..., un],GPT 在预测单词 ui 的时候只会利用 [u1, u2, ..., u(i-1)] 的信息,而 BERT 会同时利用 [u1, u2, ..., u(i-1), u(i+1), ..., un] 的信息。如下图所示。
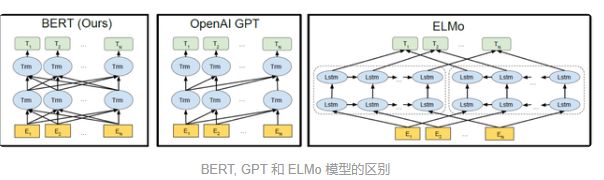
模型效果
GPT因为采用了传统的语言模型所有更加适合用于自然语言生成类的任务(NLG),因为这些任务通常是根据当前信息生成下一时刻的信息。而BERT更适合用于自然语言理解任务(NLU)。
模型结构
GPT采用了Transformer的Decoder,而BERT采用了Transformer的Encoder。GPT使用了Decoder中的Mask Multi-Head Attention结构,在使用{u1,u2,.....u(i-1)}预测单词ui时,会将ui之后的单词全部mask掉。
2.GPT模型结构
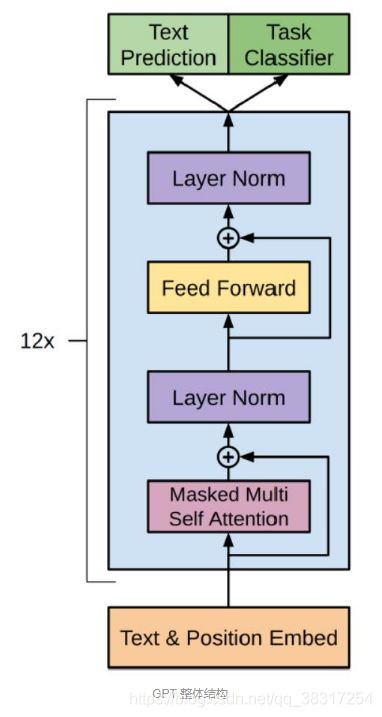
GPT使用Transformer的Decoder结构,并对Transformer进行了一些修改,原本的Decoder包含两个Multi-Head Attention结构,GPT只保留了Mask Multi-Head Attention,如下图所示。

GPT使用句子序列预测下一个单词,因此要采用Mask Multi-Head Attention对单词的下文进行遮挡,防止信息泄露。例如给定一个句子包含4个单词 [A, B, C, D],GPT 需要利用 A 预测 B,利用 [A, B] 预测 C,利用 [A, B, C] 预测 D。则预测 B 的时候,需要将 [B, C, D] Mask 起来。
Mask操作是在Self-Attention进行Softmax之前进行的,具体的做法是将要Mask的位置用一个无穷下的数替换-inf,然后在Softmax;
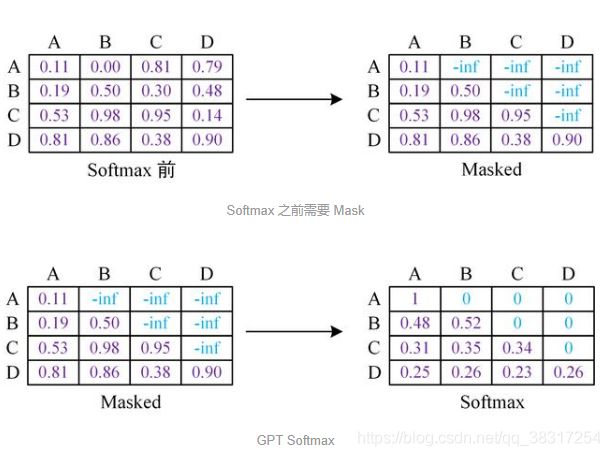
可以看到,经过 Mask 和 Softmax 之后,当 GPT 根据单词 A 预测单词 B 时,只能使用单词 A 的信息,根据 [A, B] 预测单词 C 时只能使用单词 A, B 的信息。这样就可以防止信息泄露。
下图是GPT整体模型图,包含12个Decoder
3.GPT训练过程
GPT训练过程分为两个部分:
- 无监督预训练语言模型
- 有监督的下游任务fine-tuning
3.1预训练语言模型
给定句子U=[u1,u2,.....,un],GPT训练语言模型是需要最大化下面的似然函数:
可以看出GPT是一个单向的模型,GPT的输入用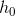 表示,的计算公式如下:
表示,的计算公式如下:
 是单词位置的Embedding,
是单词位置的Embedding,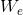 是单词的Embedding。用voc表示词汇表的大小,pos表示最长的句子长度,dim表示Embedding维度,则是一个pos*dim的矩阵,是一个voc*dim的矩阵。得到输入之后需要将依次传GPT的所有的Transformer Decoder中,最终得到
是单词的Embedding。用voc表示词汇表的大小,pos表示最长的句子长度,dim表示Embedding维度,则是一个pos*dim的矩阵,是一个voc*dim的矩阵。得到输入之后需要将依次传GPT的所有的Transformer Decoder中,最终得到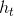
![]()
最后得到,在预测下一个单词的概率:
3.2下游任务
GPT经过训练之后,会针对具体的下游任务对模型进行微调。微调的过程采用的是有监督学习,训练样本包括 [x1, x2, ..., xm] 和 类标 y。GPT微调的过程中根据单词序列 [x1, x2, ..., xm] 预测类标 y。
![]()
其中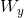 表示预测输出是的参数,微调的时候需要最大化以下函数:
表示预测输出是的参数,微调的时候需要最大化以下函数:
![]()
GPT在微调的时候也考虑预训练的损失函数,所以最终要优化的函数为:
![]()
4.GPT总结
GPT预训练时利用上文预测下一个单词,BERT是根据上下文预测单词,因此在很多NLU任务上,GPT的效果都比BERT要差。但是GPT更加适合用于文本生成的任务,因为文本生成通常都是基于当前已有的信息,生成下一个单词,