FPGA基础知识|芯片设计基础知识
FPGA 基础知识
可查看原文:FPGA基础知识
1、查找表 LUT 和编程方式第一部分: 查找表 LUT
FPGA 是在 PAL、GAL、EPLD、CPLD 等可编程器件的基础上进一步发展的产物。它是作为 ASIC 领域中的一种半定制电路而出现的,即解决了定制电路的不足,又克服了原有可编程器件门电路有限的缺点。
由于 FPGA 需要被反复烧写,它实现组合逻辑的基本结构不可能像 ASIC 那样通过固定的与非门来完成,而只能采用一种易于反复配置的结构。查找表可以很好 地满足这一要求,目前主流 FPGA 都采用了基于 SRAM 工艺的查找表结构,也有一些军品和宇航级 FPGA 采用 Flash 或者熔丝与反熔丝工艺的查找表结 构。通过烧写文件改变查找表内容的方法来实现对 FPGA 的重复配置。
根据数字电路的基本知识可以知道,对于一个 n 输入的逻辑运算,不管是与或非运算还是异或运算等等,最多只可能存在 2n 种结果。所以如果事先将相应的结果存放于一个存贮单元,就相当于实现了与非门电路的功能。FPGA 的原理也是如此,它通过烧写文件去配置查找表的内容,从而在相同的电路情况下实现了不同的逻辑功能。
查找表(Look-Up-Table)简称为 LUT,LUT 本质上就是一个 RAM。目前 FPGA 中多使用 4 输入的 LUT,所以每一个 LUT 可以看成一个有 4 位地址线的 的 RAM。当用户通过原理图或 HDL 语言描述了一个逻辑电路以后,PLD/FPGA 开发软件会自动计算逻辑电路的所有可能结果,并把真值表(即结果)事先写入 RAM,这样, 每输入一个信号进行逻辑运算就等于输入一个地址进行查表,找出地址对应的内容,然后输出即可。
下面给出一个 4 与门电路的例子来说明 LUT 实现逻辑功能的原理。例 1-1:给出一个使用 LUT 实现 4 输入与门电路的真值表。

从中可以看到,LUT 具有和逻辑电路相同的功能。实际上,LUT 具有更快的执行速度和更大的规模。
第二部分: 编程方式
由于基于LUT 的FPGA 具有很高的集成度,其器件密度从数万门到数千万门不等, 可以完成极其复杂的时序与逻辑组合逻辑电路功能,所以适用于高速、高密度 的高端数字逻辑电路设计领域。其组成部分主要有可编程输入/输出单元、基本可编程逻辑单元、内嵌 SRAM、丰富的布线资源、底层嵌入功能单元、内嵌专用单 元等,主要设计和生产厂家有 Xilinx、Altera、Lattice、Actel、Atmel 和 QuickLogic 等公司,其中最大的是 Xilinx、Altera、Lattice 三家。
FPGA 是由存放在片内的 RAM 来设置其工作状态的,因此工作时需要对片内 RAM 进行编程。用户可根据不同的配置模式,采用不同的编程方式。FPGA 有如下几种配置模式:
1、并行模式:并行 PROM、Flash 配置 FPGA;
2、主从模式:一片 PROM 配置多片 FPGA;
3、串行模式:串行 PROM 配置 FPGA;
4、外设模式:将 FPGA 作为微处理器的外设,由微处理器对其编程。
目前,FPGA 市场占有率最高的两大公司 Xilinx 和 Altera 生产的 FPGA 都是基于SRAM 工艺的,需要在使用 时外接一个片外存储器以保存程序。上电时,FPGA 将外部存储器中的数据读入片内 RAM,完成配置后,进入工作状态;掉电后 FPGA 恢复为白片,内部逻辑 消失。这样 FPGA 不仅能反复使用,还无需专门的 FPGA 编程器,只需通用的 EPROM、PROM 编程器即可。Actel、QuickLogic 等公司还 提供反熔丝技术的 FPGA,只能下载一次,具有抗辐射、耐高低温、低功耗和速度快等优点,在军品和航空航天领域中应用较多,但这种 FPGA 不能重复擦写, 开发初期比较麻烦,费用也比较昂贵。Lattice 是 ISP 技术的发明者,在小规模 PLD 应用上有一定的特色。早期的 Xilinx 产品一般不涉及军品和宇航级市场,但目前已经有 Q Pro-R 等多款产品进入该类领域。
2、FPGA 芯片结构
目前主流的 FPGA 仍是基于查找表技术的,已经远远超出了先前版本的基本性能, 并且整合了常用功能(如 RAM、时钟管理 和 DSP)的硬核(ASIC 型)模块。如图 1-1 所示(注:图 1-1 只是一个示意图,实际上每一个系列的 FPGA 都有其相应的内部结构),FPGA 芯片主 要由 6 部分完成,分别为:可编程输入输出单元、基本可编程逻辑单元、完整的时钟管理、嵌入块式 RAM、丰富的布线资源、内嵌的底层功能单元和内嵌专用硬件 模块。

每个模块的功能如下:
1.可编程输入输出单元(IOB)
可编程输入/输出单元简称 I/O 单元,是芯片与外界电路的接口部分,完成不同电气特性下对输入/输出信号的驱动与匹配要求,其示意结构如图 1-2 所示。FPGA 内的 I/O 按组分类,每组都能够独立地支持不同的 I/O 标准。通过软件的灵活配置,可适配不同的电气标准与 I/O 物理特性,可以调整驱动电流的大 小, 可以改变上、下拉电阻。目前,I/O 口的频率也越来越高,一些高端的 FPGA 通过 DDR 寄存器技术可以支持高达 2Gbps 的数据速率。
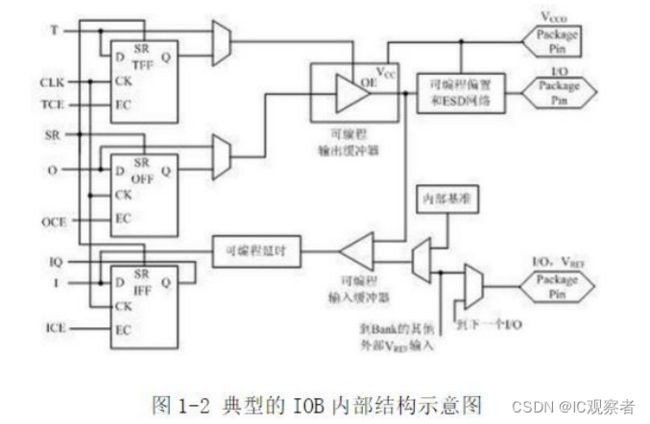
外部输入信号可以通过 IOB 模块的存储单元输入到 FPGA 的内部,也可以直接输入 FPGA 内部。当外部输入信号经过 IOB 模块的存储单元输入到 FPGA 内部时, 其保持时间(Hold Time)的要求可以降低,通常默认为 0。
为了便于管理和适应多种电器标准,FPGA 的 IOB 被划分为若干个组(bank), 每个 bank 的接口标准由其接口电压 VCCO 决定,一个 bank 只能有 一种 VCCO, 但不同 bank 的 VCCO 可以不同。只有相同电气标准的端口才能连接在一起,VCCO 电压相同是接口标准的基本条件。
2.可配置逻辑块(CLB)
CLB 是 FPGA 内的基本逻辑单元。CLB 的实际数量和特性会依器件的不同而不同, 但是每个 CLB 都包含一个可配置开关矩阵,此矩阵由 4 或 6 个输入、一些 选型 电路(多路复用器等)和触发器组成。 开关矩阵是高度灵活的,可以对其进行配置以便处理组合逻辑、移位寄存器或 RAM。在 Xilinx 公司的 FPGA 器件中,CLB 由多个(一般为 4 个或 2 个) 相同的 Slice 和附加逻辑构成,如图 1-3 所示。每个 CLB 模块不仅可以用于实现组合逻辑、时序逻辑,还可以配置为分布式 RAM 和分布式 ROM。
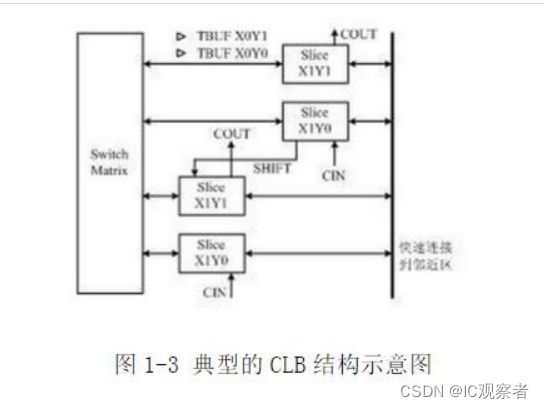
Slice 是 Xilinx 公司定义的基本逻辑单位,其内部结构如图 1-4 所示,一个 Slice 由两个 4 输入的函数、进位 逻辑、算术逻辑、存储逻辑和函数复用器组成。算术逻辑包括一个异或门(XORG)和一个专用与门(MULTAND),一个异或门可以使一个 Slice 实现 2bit 全加操作,专用与门用于提高乘法器的效率;进位逻辑由专用进位信号和函数复用器(MUXC)组成,用于实现快速的算术加减法操作; 4 输入函数发生 器用于实现 4 输入 LUT、分布式 RAM 或 16 比特移位寄存器
(Virtex-5 系列芯片的 Slice 中的两个输入函数为 6 输入,可以实现 6 输入 LUT 或 64 比特移位寄存器);进位逻辑包括两条快速进位链,用于提高 CLB 模块的处理速度

3.数字时钟管理模块(DCM)
业内大多数 FPGA 均提供数字时钟管理(Xilinx 的全部 FPGA 均具有这种特性)。Xilinx 推出最先进的 FPGA 提供数字时钟管理和相位环路锁定。相位环路锁定能够提供精确的时钟综合,且能够降低抖动,并实现过滤功能。
4.嵌入式块 RAM(BRAM)
大多数 FPGA 都具有内嵌的块 RAM,这大大拓展了 FPGA 的应用范围和灵活性。块RAM 可被配置为单端口 RAM、双端口 RAM、内容地址存储器 (CAM)以及 FIFO 等常用存储结构。RAM、FIFO 是比较普及的概念,在此就不冗述。CAM 存储器在其内部的每个存储单元中都有一个比较逻辑,写入 CAM 中的数据会和内部的每一个数据进行比较,并返回与端口数据相同的所有数据的地址,因而在路由的地址交换器中有广泛的应用。除了块 RAM,还可以将 FPGA 中的 LUT 灵活地配置成 RAM、 ROM 和 FIFO 等结构。在实际应用中,芯片内部块 RAM 的数量也是选择芯片的一个重要因素。
例如:单片块 RAM 的容量为 18k 比特,即位宽为 18 比特、深度为 1024,可以根据需要改变其位宽和深度,但要满足两个原则:首先,修改后的容量(位宽 深
度)不能大于 18k 比特;其次,位宽最大不能超过 36 比特。当然,可以将多片块 RAM 级联起来形成更大的 RAM,此时只受限于芯片内块 RAM 的数量,而 不再受上面两条原则约束
5.丰富的布线资源
布线资源连通 FPGA 内部的所有单元,而连线的长度和工艺决定着信号在连线上的驱动能力和传输速度。FPGA 芯片内部有着丰富的布线资源,根据工艺、长 度、宽度和分布位置的不同而划分为4类不同的类别。第一类是全局布线资源,用于芯片内部全局时钟和全局复位/置位的布线;第二类是长线资源,用以完成芯片Bank 间的高速信号和第二全局时钟信号的布线;第三类是短线资源,用于完成基本逻辑单元之间的逻辑互连和布线;第四类是分布式的布线资源,用于专有时钟、复位等控制信号线。
在实际中设计者不需要直接选择布线资源,布局布线器可自动地根据输入逻辑网表的拓扑结构和约束条件选择布线资源来连通各个模块单元。从本质上讲,布线资源的使用方法和设计的结果有密切、直接的关系。
6.底层内嵌功能单元
内嵌功能模块主要指 DLL(Delay Locked Loop)、PLL(Phase Locked Loop)、DSP 和 CPU 等软处理核(Soft Core)。现在越来越丰富的内嵌功能单元,使得单片 FPGA 成为了系统级的设计工具,使其具备了软硬件联合设计的能力,逐步向 SOC 平台过渡。
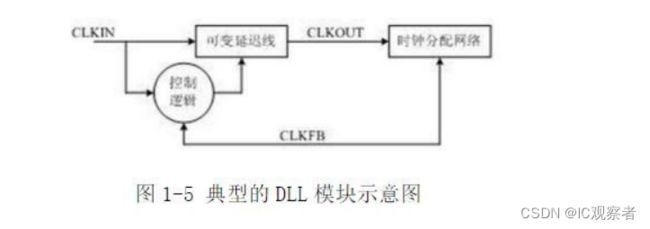
DLL 和 PLL 具有类似的功能,可以完成时钟高精度、低抖动的倍频和分频,以及占空比调整和移相等功能。Xilinx 公司生产的芯片上集成了 DLL,Altera 公司的芯片集成了 PLL,Lattice 公司的新型芯片上同时集成了 PLL 和 DLL。PLL 和DLL 可以通过 IP 核生成的工具方便地进行管理和配置。DLL 的结构如图 1-5 所示。
1.内嵌专用硬核
内嵌专用硬核是相对底层嵌入的软核而言的,指 FPGA 处理能力强大的硬核(Hard Core),等效于 ASIC 电路。为了提高 FPGA 性能,芯片生产商在芯片内部集成了一些专用的硬核。例如:为了提高 FPGA 的乘法速度,主流的 FPGA 中都集成了
专用乘法器;为了适用通信总线与接口标准,很多高端的 FPGA 内部都集成了串并收发器(SERDES),可以达到数十 Gbps 的收发速度。 Xilinx 公司的高端产品不仅集成了 Power PC 系列 CPU,还内嵌了 DSP Core 模块,其相应的系统级设计工具是 EDK 和 Platform Studio,并依此提出了片上系统(System on Chip) 的概念。通过 PowerPC、Miroblaze、Picoblaze 等平台,能够开发标准的 DSP 处理器及其相关应用,达到 SOC 的开发目 的。
(1)软核
软核在 EDA 设计领域指的是综合之前的寄存器传输级(RTL)模型;具体在 FPGA 设计中指的是对电路的硬件语言描述,包括逻辑描述、网表和帮助文档等。 软核只经过功能仿真,需要经过综合以及布局布线才能使用。其优点是灵活性高、可移植性强,允许用户自配置;缺点是对模块的预测性较低,在后续设计中存在发 生错误的可能性,有一定的设计风险。软核是 IP 核应用最广泛的形式。
(2)固核
固核在 EDA 设计领域指的是带有平面规划信息的网表;具体在 FPGA 设计中可以看做带有布局规划的软核,通常以 RTL 代码和对应具体工艺网表的混合形式提供。将 RTL 描述结合具体标准单元库进行综合优化设计,形成门级网表,再通过布局布线工具即可使用。和软核相比,固核的设计灵活性稍差,但在可靠性上有较 大提高。目前,固核也是 IP 核的主流形式之一。
(3)硬核
硬核在 EDA 设计领域指经过验证的设计版图;具体在 FPGA 设计中指布局和工艺固定、经过前端和后端验证的设计,设计人员不能对其修改。不能修改的原因有两个:首先是系统设计对各个模块的时序要求很严格,不允许打乱已有的物理版图;其次是保护知识产权的要求,不允许设计人员对其有任何改动。IP 硬核的不许 修改特点使其复用有一定的困难,因此只能用于某些特定应用,使用范围较窄。
3、比较 CPLD 和 FPGA
一.基于乘积项(Product-Term)的 PLD 结构
采用这种结构的 PLD 芯片有:Altera 的 MAX7000,MAX3000 系列(EEPROM 工 艺),Xilinx 的 XC9500 系列(Flash 工艺)和 Lattice,Cypress 的大部分产品
(EEPROM 工艺)
我们先看一下这种 PLD 的总体结构(以 MAX7000 为例,其他型号的结构与此都非常相似):
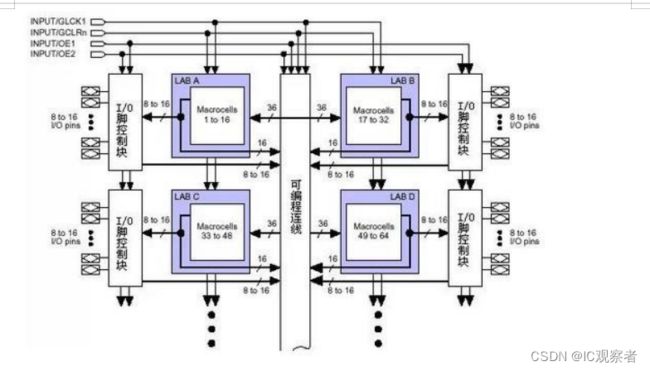
图 1 基于乘积项的 PLD 内部结构
这种 PLD 可分为三块结构:宏单元(Marocell),可编程连线 (PIA)和 I/O 控制块。 宏单元是 PLD 的基本结构,由它来实现基本的逻辑功能。图 1 中兰色部分是多个宏单元的集合(因为宏单元较多,没有一一画出)。可编程连线负责信号传递,连 接所有的宏单元。I/O 控制块负责输入输出的电气特性控制,比如可以设定集电极开路输出,摆率控制,三态输出等。 图 1 左上的 INPUT/GCLK1, INPUT/GCLRn,INPUT/OE1,INPUT/OE2 是全局时钟,清零和输出使能信号,这几个信号有专用连线与 PLD 中每个宏单元相连,信号到每个宏单元的延时相同并且延时最短。
宏单元的具体结构见下图:
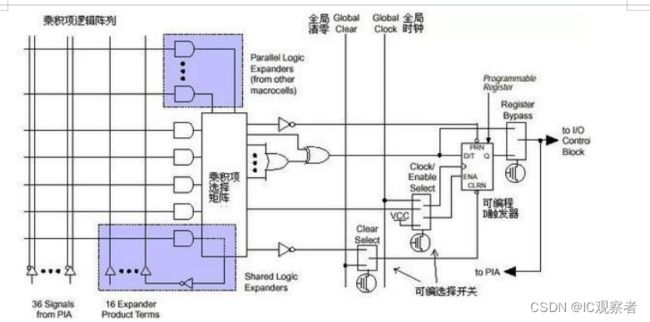
图 2 宏单元结构
左侧是乘积项阵列,实际就是一个与或阵列,每一个交叉点都是一个可编程 熔丝,如果导通就是实现“与”逻辑。后面的乘积项选择矩阵是一个“或”阵列。两者一起完成组合逻辑。图右侧是一个可编程 D 触发器,它的时钟,清零输入都可 以编程选择,可以使用专用的全局清零和全局时钟,也可以使用内部逻辑(乘积项阵列)产生的时钟和清零。如果不需要触发器,也可以将此触发器旁路,信号直接 输给 PIA 或输出到 I/O 脚。
二.乘积项结构 PLD 的逻辑实现原理
下面我们以一个简单的电路为例,具体说明 PLD 是如何利用以上结构实现逻辑的, 电路如下图:
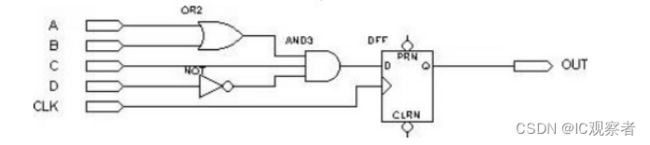
图 3
假设组合逻辑的输出(AND3 的输出)为 f,则 f=(A+B)C(!D)=AC!D + BC!D ( 我们以!D 表示 D 的“非”)
PLD 将以下面的方式来实现组合逻辑 f:

图 4
A,B,C,D 由 PLD 芯片的管脚输入后进入可编程连线阵列 (PIA),在内部会产生A,A 反,B,B 反,C,C 反,D,D 反 8 个输出。图中每一个叉表示相连(可编程熔丝导通),所以得到:f= f1 + f2 = (AC!D) + (BC!D) 。这样组合逻辑就实现了。 图 3 电路中 D 触发器的实现比较简单,直接利用宏单元中的可编程 D 触发器来实现。时钟信号 CLK 由 I/O 脚输入后进入芯片内部的全局时钟专用通道,直接连接 到可编程触发器的时钟端。可编程触发器的输出与 I/O 脚相连,把结果输出到芯片管脚。这样 PLD 就完成了图 3 所示电路的功能。(以上这些步骤都是由软件自 动完成的,不需要人为干预)
图 3 的电路是一个很简单的例子,只需要一个宏单元就可以完成。但对于一个复杂的电路,一个宏单元是不能实现的,这时就需要通过并联扩展项和共享扩展项将多个宏单元相连,宏单元的输出也可以连接到可编程连线阵列,再做为另一个宏单元的输入。这样 PLD 就可以实现更复杂逻辑。
这种基于乘积项的 PLD 基本都是由 EEPROM 和 Flash 工艺制造的,一上电就可以工作,无需其他芯片配合。
FPGA
FPGA 作为 ASIC 领域中的一种半定制电路而出现的,即解决了定制电路的不足, 又克服了原有可编程器件门电路有限的缺点。由于 FPGA 需要被反复烧写,它实现组合逻辑的基本结构不可能像 ASIC 那样通过固定的与非门来完成,而只能采用一种易于反复配置的结构。查找表可以很好地满足这一要求。通过烧写文件去配置查找表的内容,从而在相同的电路情况下实现了不同的逻辑功能。
查找表的原理与结构
查找表(Look-Up-Table)简称为 LUT,LUT 本质上就是一个 RAM。目前 FPGA 中多使用 4 输入的 LUT,所以每一个 LUT 可以看成一个有 4 位地址线的的 RAM。当用户通过原理图或 HDL 语言描述了一个逻辑电路以后,PLD/FPGA 开发软件会自动 计算逻辑电路的所有可能结果,并把真值表(即结果)事先写入 RAM,这样,每输入一个信号进行逻辑运算就等于输入一个地址进行查表,找出地址对应的内容, 然后输出即可。
下面给出一个四输入与非门电路的例子来说明 LUT 实现逻辑功能的原理。
表给出一个使用 LUT 实现四输入与门电路的真值表。
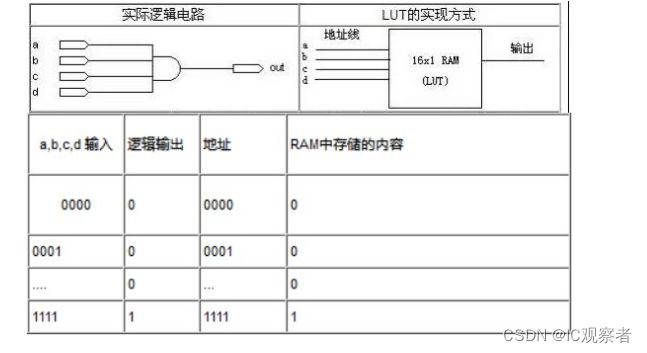
从中可以看到,LUT 具有和逻辑电路相同的功能。实际上,LUT 具有更快的执行速度和更大的规模。
查找表结构的 FPGA 逻辑实现原理我们还是以这个电路的为例:

图 四输入与门电路图
A,B,C,D 由 FPGA 芯片的管脚输入后进入可编程连线,然后作为地址线连到到LUT,LUT 中已经事先写入了所有可能的逻辑结果,通过地址查找到相应的数据然后输出,这样组合逻辑就实现了。该电路中 D 触发器是直接利用 LUT 后面 D 触发器来实现。时钟信号 CLK 由 I/O 脚输入后进入芯片内部的时钟专用通道,直接连接到触发器的时钟端。触发器的输出与 I/O 脚相连,把结果输出到芯片管脚。这样 PLD 就完成了图所示电路的功能。(以上这些步骤都是由软件自动完成的, 不需要人为干预)
这个电路是一个很简单的例子,只需要一个 LUT 加上一个触发器就可以完成。对于一个 LUT 无法完成的的电路,就需要通过进位逻辑将多个单元相连,这样 FPGA 就可以实现复杂的逻辑。
因为基于LUT 的FPGA 具有很高的集成度,其器件密度从数万门到数千万门不等, 可以完成极其复杂的时序与逻辑组合逻辑电路功能,所以适用于高速、高密度的高端数字逻辑电路设计领域。其组成部分主要有可编程输入/输出单元、基本可编程逻辑单元、内嵌 SRAM、丰富的布线资源、底层嵌入功能单元、内嵌专用单元等,主要设计和生产厂家有 Xilinx、Altera、Lattice、Actel、Atmel 和QuickLogic 等公司,其中最大的是 Xilinx、Altera、Lattice 三家。
4、比较 Xilinx 和 Altera
要比较 Xilinx 和 Altera 的 FPGA,就要清楚两个大厂 FPGA 的结构,由于各自设计的不同,两家的 FPGA 结构各不相同,参数也各不相同,但可以统一到LUT(Look-Up-Table)查找表上。
下图就是 A 家的 Cyclone IV 系列片子的参数:

可以看到,A 家的片子,用的是 LE 这个术语。而下图是 X 家的 Spartan-6 片子资料:

X 家用的是 CLB 这个术语作为基本单元。再看看两家的基本单元有何不同:
A 家的 LE 如下图:

就是一个 4 输入 LUT+FF 构成而 X 家的 CLB 如下:
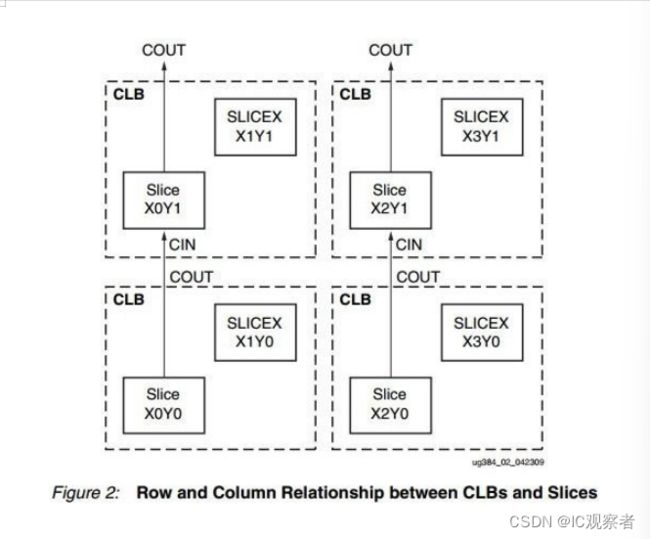
一个 CLB 由 2 个 SLICE 构成,一个 SLICE 含有 4 个 6 输入 LUT,所以 LUT=8*CLB。

这样的话,可以较比一下。EP4CE6 基本就和 XC6SLX9 一个级别。。。。当然 A 家的片子是 4 输入 LUT 远比不上X 家的 6 输入 LUT。而 X 家的S-6 片子,一个 Slice 内部有 4 个 lut,8 个 FF。简而言之,一个 Slice=四个 LE。要注意的是 A 家 C5 以下的片子是 4 输入 LUT 而 X 家的是 6 输入 LUT,差别也较大。如果不考虑 FF, 那么一个X 家的slice=4 个A 家的LE。例如XC6SLX16 含有2278 个slices=EP4CE10
(9000LE)的样子。当然,S-6 的 FF 多一倍,达到了 18224 个。
在 Virtex-5 中(我们的设计大部分是 Virtex,V5V6V7),一个 Slice 包含了 4 个 LUT 和 4 个 FF。所以单纯从逻辑资源来看,S-6 一个 Slice 比 V-5 的 Slice 强。当然 V5 的 GTPGTX 等等还有 IO 数量是 S-6 赶不上的。当然,A 家的 Cyclone V 系列的片子,内部和前几代完全不同,采用了从高端的 Stratix 系列下放的技术.
更多内容查看:https://ic.coachip.cn/resource/detail/99