时序数据库(Time Series Database)是用于存储和管理时间序列数据的专业化数据库,具备写多读少、冷热分明、高并发写入、无事务要求、海量数据持续写入等特点,可以基于时间区间聚合分析和高效检索,广泛应用在物联网、经济金融、环境监控、工业制造、农业生产、硬件和软件系统监控等场景。
随着技术的不断发展,时序数据库这个赛道里最近几年出现了很多的佼佼者,今天就来将这些时序数据库从性能到应用一起梳理对比下。
1 TDengine vs InfluxDB 性能PK
性能是用户在选择和使用时序数据库时非常关注的一个点。
1.1 数据库介绍
InfluxDB
是一个用Go语言编写的开源时序数据库。其核心是一个自定义构建的存储引擎,它针对时序数据进行了优化,是目前最为流行的时序数据库之一。
TDengine
是一款集成了消息队列,数据库,流式计算等功能的物联网大数据平台。该产品不依赖任何开源或第三方软件,拥有完全自主知识产权,具有高性能、高可靠、可伸缩、零管理、简单易学等技术特点。TDengine是当前时序数据库领域中一匹势头正劲的黑马,在国产时序数据库中算是No.1了。
“一言不合上数据”,接下来,我们正式进入测试环节。
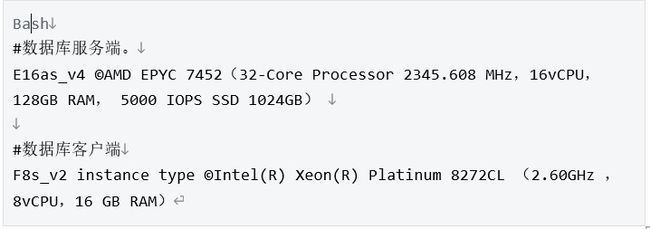
1.2 环境准备
为了方便大家复现,我们所有的测试都是运行在Ubuntu 20.10的两台azure虚拟机上进行的,配置如下:
1.3 测试方法与步骤
经过一系列安装软件及代码准备工作之后,我们开始进行脚本测试数据工作:
修改脚本:
需要将timeseriesdatabase-comparisons/build/tsdbcompare/write_to_server.sh,把add='tdvs',修改为你选用的数据库服务端hostname。
运行脚本测试:
timeseriesdatabasecomparisons/build/tsdbcompare/loop_scale_to_server.sh注意:如果遇到干扰因素导致写入失败,可以手动传入参数再次执行得到测试结果。
1.4 实际测量数据
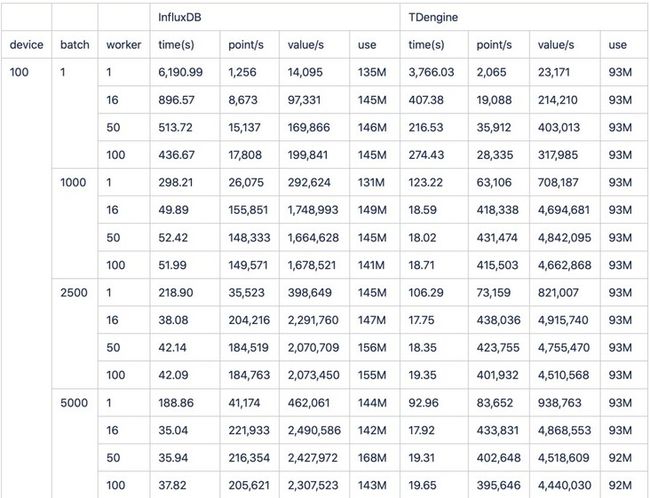
经过一番测试后,我们制作了这样一张表格。通过它我们可以清楚地看到:不论是单线程还是多线程,不论是小批次还是大批次,TDengine都一直稳稳保持着2倍左右的速度优势。
其中5000batch,16wokers的场景下(InfluxDB与Graphite的对比报告中的测试项),InfluxDB耗时35.04秒,而TDengine耗时仅17.92秒。
1.5 PK结论
当前的测试结果比较有力地说明了两点结论:
- 在InfluxDB发布的自己最优的条件下,TDengine的写入速度是它的两倍。
- 当设备数放大到1000的时候,TDengine的写入速度是InfluxDB的5倍左右。
我们使用该测试条件(5000batch size,16workers)作出两张以设备台数为横轴的折线图,因为这将极具代表性。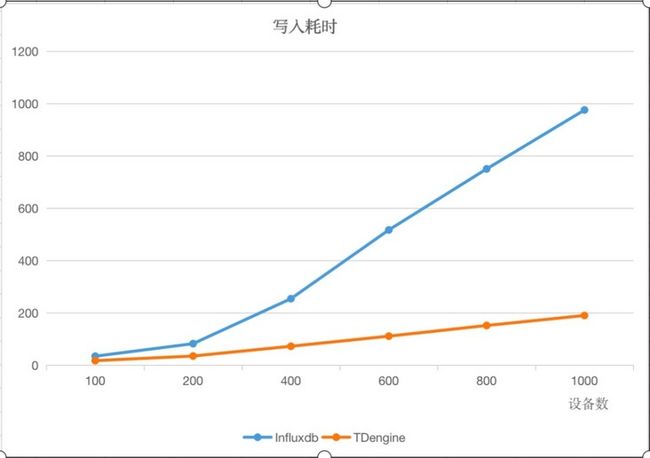
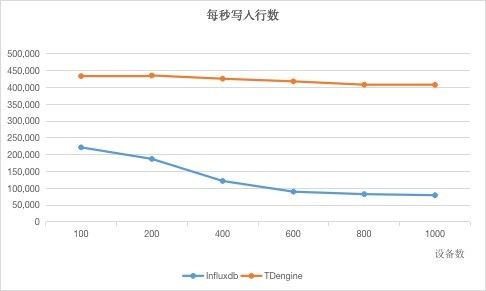
这两张图充分说明了一点:设备数越多,数据量越大,TDengine的优势就越明显。
而考虑到本次性能测试对比的接口类型并不一致,TDengine采用的是cgo接口而InfluxDB为rest,性能上会有少量浮动,绝不会从根本上改变结果。
2、TDengine vs Prometheus 架构设计PK
通过对比能加深对这两个系统的理解,方便后续架构选型时作出正确决定。他们的设计思路有很多值得借鉴的地方,虽然目前工作中需要用到这些设计思路的地方不多,但是了解他们的设计能极大满足我的好奇心。
2.1 架构、实现方案不同之处
Prometheus 架构设计
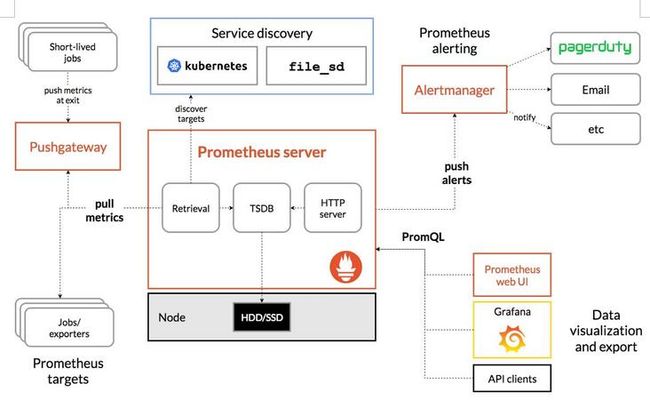
通过prometheus的架构图可以看出,prometheus提供了本地存储,即tsdb时序数据库。本地存储的优势就是运维简单,缺点就是无法海量的metrics持久化和数据存在丢失的风险,我们在实际使用过程中,出现过几次wal文件损坏,无法再写入的问题。
当然prometheus2.0以后压缩数据能力得到了很大的提升。为了解决单节点存储的限制,prometheus没有自己实现集群存储,而是提供了远程读写的接口,让用户自己选择合适的时序数据库来实现prometheus的扩展性。
TDengine 分布式系统架构设计
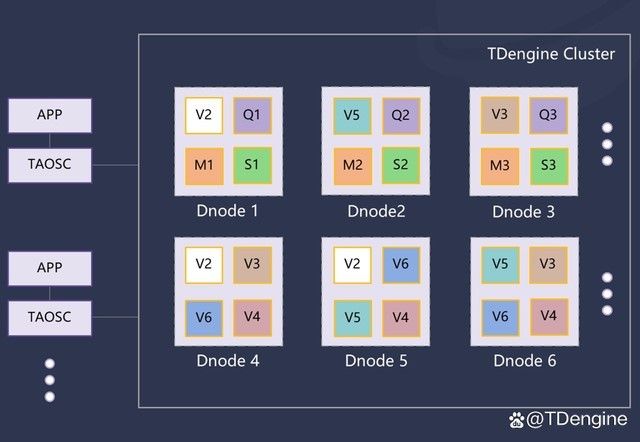
如上图所示,在数据节点(Dnode)、虚拟节点(Vnode)、管理节点(Mnode)之上,TDengine 3.0 集群新增了弹性计算节点(Qnode)和流计算节点(Snode)。其中 Qnode 主要在运行查询计算任务中起作用,当一个查询执行时,依赖执行计划,调度器会安排一个或多个 Qnode;Snode 主要负责运行流计算任务,可以同时执行多个。
2.2 应用差异点
面向场景不同
• Prometheus
Prometheus 专注于运维需要的指标数据,特点是存储的就是一个数值,数据附带了很多维度信息,作为标签。
# 如:cpu_total_seconds:
{timestamp=2020-09-05-21-27, host="192.168.1.10", type="idle"}=3551341;Prometheus专注于单机性能,用于存储最近一段时间数据,没有长期持久化的考虑,弱化分布式集群功能,由其他组件(如Thanos)来完成高可用。
• TDengine
TDengine 用于存储工业中某类传感器设备采集的指标,所以数据类型多样,如浮点,字符串等。
TDengine 面向工业物联网时序场景,数据具备量大、写操作为主读操作为辅、更新删除操作较少等特点,TDengine从这些数据特点出发设计了存储、查询、写入的功能特色,为了减少系统架构的冗杂,TDengine 还自带了数据订阅、流式计算等功能。
TDengine 希望通过分布式集群来提供可扩展性、高可靠和高性能,避免单点故障,收费版就是提供集群能力,有持久化多级存储在不同设备上的能力。
使用方式不同
• Prometheus
Prometheus不需要提前建表,而 TDengine 是关系型数据库模型,需要提前定义好表结构。写入的数据需要自带描述,包含很多不同维度的标签(lable),这些都是动态的。
• TDengine
TDengine 一个采集点一张表,所以一张表不会并发写入。而 Promtheus 为了避免存储的采样数据产生很多小文件,是以块为单位存储指标的。
总而言之,作为时序数据库中的一匹“黑马” ,TDengine还是较为可圈可点的,如果你也有时序数据处理的难题待解,也可以尝试调研一下。TDengine开源地址:https://github.com/taosdata/T...