演化博弈、复制动态方程与仿真
本文只整理和总结一下我的理解,文末列出了可供参考的更详细完整的资料。建议先看参考资料[1](博弈论公开课)的博弈论课程,可以直接从第11讲开始看。参考链接[2]是关于演化博弈非常经典的一本书。参考链接[5]涵盖内容比较完整,关于演化博弈的各个方面都涉及到了。
概念
本文统一采用参考链接[2]的符号表示。
E ( A , B ) E(A,B) E(A,B)表示对手采用 B B B策略而自己采用 A A A的收益,简写作 A A A对 B B B的收益。
NE表示纳什均衡,ES表示演化稳定。
收益矩阵
(下面表格来自参考文献[6])
| C C C | D D D | |
|---|---|---|
| C C C | r r r | s s s |
| D D D | t t t | p p p |
| Cooperation | Defection | |
|---|---|---|
| Cooperation | Reward | Sucker |
| Defection | Temptation | Punishment |
其中 r = E ( C , C ) r=E(C,C) r=E(C,C)表示双方均采用C(合作)策略的收益, p = E ( D , D ) p=E(D,D) p=E(D,D)表示双方均采用D(背叛)策略的收益, s = E ( C , D ) s=E(C,D) s=E(C,D)表示对方采用D策略而己方采用C策略的收益, t = E ( D , C ) t=E(D,C) t=E(D,C)表示对方采用C策略而己方采用D策略的收益。收益矩阵还有一种表示法(参考链接[1][5]使用该表示法)
| C C C | D D D | |
|---|---|---|
| C C C | r , r r,r r,r | s , t s,t s,t |
| D D D | t , s t,s t,s | p , p p,p p,p |
演化稳定
(上面表格来自参考文献[6])下面两个定义出自参考链接[1]。
定义1(来自Maynard Smith的生物学定义)
在一个双参与人的对称博弈中,策略 S ^ \hat{S} S^是演化稳定策略当且仅当存在一个 ϵ ˉ > 0 \bar{\epsilon}>0 ϵˉ>0,
( 1 − ϵ ) E ( S ^ , S ^ ) + ϵ E ( S ^ , S ′ ) > ( 1 − ϵ ) E ( S ′ , S ^ ) + ϵ E ( S ′ , S ′ ) (1-\epsilon)E(\hat{S},\hat{S})+\epsilon E(\hat{S},S')> (1-\epsilon)E(S',\hat{S})+\epsilon E(S',S') (1−ϵ)E(S^,S^)+ϵE(S^,S′)>(1−ϵ)E(S′,S^)+ϵE(S′,S′)
对于任意偏离 S ^ \hat{S} S^的策略 S ′ S' S′都成立,且对任意 ϵ < ϵ ˉ \epsilon<\bar{\epsilon} ϵ<ϵˉ都成立。
上面式子的意思是, 1 − ϵ 1-\epsilon 1−ϵ的概率下对 S ^ \hat{S} S^策略采用 S ^ \hat{S} S^策略加上 ϵ \epsilon ϵ的概率下对 S ′ S' S′策略采用 S ^ \hat{S} S^的收益严格大于。。。的收益。
定义2(经济学定义)
(上面表格来自参考文献[6])在一个双参与人的对称博弈中,策略 S ^ \hat{S} S^是演化稳定策略需满足下面两个条件:
条件1: ( S ′ , S ′ ) (S',S') (S′,S′)是(对称)纳什均衡,即 E ( S ^ , S ^ ) ≥ E ( S ′ , S ^ ) E(\hat{S},\hat{S})\geq E(S',\hat{S}) E(S^,S^)≥E(S′,S^);
条件2:如果 E ( S ^ , S ^ ) = E ( S ′ , S ^ ) E(\hat{S},\hat{S})=E(S',\hat{S}) E(S^,S^)=E(S′,S^),那么 E ( S ^ , S ′ ) > E ( S ′ , S ′ ) E(\hat{S},S')>E(S',S') E(S^,S′)>E(S′,S′)。
两个定义的关系
(上面表格来自参考文献[6])参考链接[1]表示两个定义完全等价,定义1较为严谨,定义2更方便使用。
其它
对称博弈
直观理解就是收益跟玩家无关,即收益矩阵
| C C C | D D D | |
|---|---|---|
| C C C | r 1 , r 2 r_1,r_2 r1,r2 | s 1 , t 1 s_1,t_1 s1,t1 |
| D D D | t 2 , s 2 t_2,s_2 t2,s2 | p 1 , p 2 p_1,p_2 p1,p2 |
中,下标不同的收益不同。
(参考链接[1]公开课中第11集的1:05:30处老师犯了个错误,弹幕里提到了对称博弈我觉得也不对,不知道哪有问题)一个应该是非对称博弈的例子 为啥散户炒股票总赔钱? -bilibili 应该是零和博弈。
Bishop定理
该定理的进一步解释见参考链接[2]《演化与博弈论》。
如果 S ^ \hat{S} S^是一个由纯策略 A , B , C , ⋯ A,B,C,\cdots A,B,C,⋯组成的混合演化稳定策略,那么
E ( A , S ^ ) = E ( B , S ^ ) = E ( C , S ^ ) = ⋯ = E ( S ^ , S ^ ) E(A,\hat{S})=E(B,\hat{S})=E(C,\hat{S})=\cdots=E(\hat{S},\hat{S}) E(A,S^)=E(B,S^)=E(C,S^)=⋯=E(S^,S^)
懦夫博弈与混合策略
关于懦夫博弈更详细的说明见 懦夫博弈 -百度百科。
下面收益矩阵中的具体取值出自参考链接[1]。
| A | B | |
|---|---|---|
| A | 0 | 2 |
| B | 1 | 0 |
其中 A A A策略表示强势, B B B策略表示弱势, E ( A , A ) = 0 , E ( A , B ) = 2 , E ( B , A ) = 1 , E ( B , B ) = 0 E(A,A)=0,E(A,B)=2,E(B,A)=1,E(B,B)=0 E(A,A)=0,E(A,B)=2,E(B,A)=1,E(B,B)=0。根据定义2可得出,两个策略均不是演化稳定策略。演化稳定策略是一个混合策略,用 S ^ \hat{S} S^表示, S ^ = 2 3 A + 1 3 B \hat{S}=\frac{2}{3}A+\frac{1}{3}B S^=32A+31B。设突变策略 S ′ = k A + ( 1 − k ) B S'=kA+(1-k)B S′=kA+(1−k)B,列出收益矩阵计算收益(以 E ( S ′ , S ^ ) E(S',\hat{S}) E(S′,S^)为例)
| 2 3 A \frac{2}{3}A 32A | 1 3 B \frac{1}{3}B 31B | |
|---|---|---|
| k A kA kA | 0 | 2 |
| ( 1 − k ) B (1-k)B (1−k)B | 1 | 0 |
可计算出
E ( S ^ , S ^ ) = 2 ⋅ 2 3 ⋅ 1 3 + 1 ⋅ 1 3 ⋅ 2 3 = 2 3 E ( S ′ , S ^ ) = 2 ⋅ k ⋅ 1 3 + 1 ⋅ ( 1 − k ) ⋅ 2 3 = 2 3 E ( S ^ , S ′ ) = 2 ⋅ 2 3 ⋅ ( 1 − k ) + 1 ⋅ 1 3 ⋅ k = 4 3 − k E ( S ′ , S ′ ) = 2 ⋅ k ⋅ ( 1 − k ) + 1 ⋅ ( 1 − k ) ⋅ k = 3 k ( 1 − k ) \begin{aligned} &E(\hat{S},\hat{S})=2\cdot\frac{2}{3}\cdot\frac{1}{3} +1\cdot\frac{1}{3}\cdot\frac{2}{3}=\frac{2}{3} \\ &E(S',\hat{S})=2\cdot k\cdot\frac{1}{3} +1\cdot(1-k)\cdot\frac{2}{3}=\frac{2}{3} \\ &E(\hat{S},S')=2\cdot\frac{2}{3}\cdot(1-k) +1\cdot\frac{1}{3}\cdot k=\frac{4}{3}-k \\ &E(S',S')=2\cdot k\cdot(1-k) +1\cdot(1-k)\cdot k=3k(1-k) \\ \end{aligned} E(S^,S^)=2⋅32⋅31+1⋅31⋅32=32E(S′,S^)=2⋅k⋅31+1⋅(1−k)⋅32=32E(S^,S′)=2⋅32⋅(1−k)+1⋅31⋅k=34−kE(S′,S′)=2⋅k⋅(1−k)+1⋅(1−k)⋅k=3k(1−k)
最后得到两个策略 S ^ \hat{S} S^和 S ′ S' S′的收益矩阵为
| S ^ \hat{S} S^ | S ′ S' S′ | |
|---|---|---|
| S ^ \hat{S} S^ | 2 3 \frac{2}{3} 32 | 4 3 − k \frac{4}{3}-k 34−k |
| S ′ S' S′ | 2 3 \frac{2}{3} 32 | 3 k ( 1 − k ) 3k(1-k) 3k(1−k) |
由演化稳定定义2, E ( S ^ , S ^ ) = E ( S ′ , S ^ ) E(\hat{S},\hat{S})=E(S',\hat{S}) E(S^,S^)=E(S′,S^),但可以计算出, E ( S ^ , S ′ ) > E ( S ′ , S ′ ) E(\hat{S},S')>E(S',S') E(S^,S′)>E(S′,S′),所以 E ( S ^ E(\hat{S} E(S^是演化稳定策略。
最后,由Bishop定理可求出(验证)演化稳定策略 S ^ \hat{S} S^中的 k k k值:
E ( A , S ^ ) = 2 ( 1 − k ) E ( B , S ^ ) = k 2 ( 1 − k ) = k , k = 2 3 \begin{aligned} &E(A,\hat{S})=2(1-k) \\ &E(B,\hat{S})=k \\ &2(1-k)=k,k=\frac{2}{3} \end{aligned} E(A,S^)=2(1−k)E(B,S^)=k2(1−k)=k,k=32
鹰鸽博弈
假设同一物种的两个竞争对手在某个价值为 G G G的资源位置相遇,有两个纯策略:
- 鹰策略:你总是升级冲突,直到对方退出,或者你受到严重伤害。
- 鸽策略:你保持姿态直到对方退出,但如果对方升级冲突或看起来太强,你就退出。
(此处更详细的说明见 鹰派与鸽派的博弈 -豆瓣)
收益矩阵
| H | D | |
|---|---|---|
| H | V − C 2 \frac{V-C}{2} 2V−C | V |
| D | 0 | V 2 \frac{V}{2} 2V |
其中需要满足 V < C V
E ( H , S ^ ) = V − C 2 k + ( 1 − k ) V E ( D , S ^ ) = ( 1 − k ) V 2 \begin{aligned} E(H,\hat{S}) =& \frac{V-C}{2}k+(1-k)V \\ E(D,\hat{S}) =& (1-k)\frac{V}{2} \\ \end{aligned} E(H,S^)=E(D,S^)=2V−Ck+(1−k)V(1−k)2V
令 E ( H , S ^ ) = E ( D , S ^ ) E(H,\hat{S})=E(D,\hat{S}) E(H,S^)=E(D,S^),可解得 k = V C k=\frac{V}{C} k=CV,代入得
E ( H , S ^ ) = E ( D , S ^ ) = V ( C − V ) 2 C E ( S ^ , S ^ ) = k 2 V − C 2 + k ( 1 − k ) V + ( 1 − k ) 2 V 2 = V ( C − V ) 2 C E(H,\hat{S})=E(D,\hat{S})=\frac{V(C-V)}{2C} \\ E(\hat{S},\hat{S})=k^2\frac{V-C}{2}+k(1-k)V+(1-k)^2\frac{V}{2} =\frac{V(C-V)}{2C} \\ E(H,S^)=E(D,S^)=2CV(C−V)E(S^,S^)=k22V−C+k(1−k)V+(1−k)22V=2CV(C−V)
复制动态方程
关于复制动态方程的进一步解释见参考链接[5]。[2]中的解释不太清晰,虽然用的是[2]中的符号表示。
定义两个策略的适应度 W H W_H WH和 W D W_D WD和种群的平均适应度 W ˉ \bar{W} Wˉ分别为
W H = W 0 + p E ( H , H ) + ( 1 − p ) E ( H , D ) W D = W 0 + p E ( D , H ) + ( 1 − p ) E ( D , D ) W ˉ = p W H + ( 1 − p ) W D W_H=W_0+pE(H,H)+(1-p)E(H,D) \\ W_D=W_0+pE(D,H)+(1-p)E(D,D) \\ \bar{W}=pW_H+(1-p)W_D \\ WH=W0+pE(H,H)+(1−p)E(H,D)WD=W0+pE(D,H)+(1−p)E(D,D)Wˉ=pWH+(1−p)WD
其中 W 0 W_0 W0代表个体在博弈之前的基础适应度(?)。可以看出 p E ( H , H ) + ( 1 − p ) E ( H , D ) = E ( H , S ) pE(H,H)+(1-p)E(H,D)=E(H,S) pE(H,H)+(1−p)E(H,D)=E(H,S),其中 S = p H + ( 1 − p ) D S=pH+(1-p)D S=pH+(1−p)D是混合策略(不知道 E ( H , S ) E(H,S) E(H,S)和 W H W_H WH之间有什么关系)。下一代中采取 H H H策略的比例为
p n + 1 = p n W H W ˉ p_{n+1}=p_n\frac{W_H}{\bar{W}} pn+1=pnWˉWH
若定义 q = ( 1 − p ) q=(1-p) q=(1−p),且
q n + 1 = q n W D W ˉ q_{n+1}=q_n\frac{W_D}{\bar{W}} qn+1=qnWˉWD
可验证
p n + 1 + q n + 1 = p n W H + q n W D W ˉ = 1 p_{n+1}+q_{n+1}=\frac{p_nW_H+q_nW_D}{\bar{W}}=1 pn+1+qn+1=WˉpnWH+qnWD=1
由递推关系推导出复制动态方程
d p d t = p n + 1 − p n = p W H − W ˉ W ˉ = p W H − ( p W H + ( 1 − p ) W D ) p W H + ( 1 − p ) W D = p ( 1 − p ) ( W H − W D ) W H − ( 1 − p ) ( W H − W D ) \begin{aligned} \frac{\text{d}p}{\text{d}t} =& p_{n+1}-p_n = p\frac{W_H-\bar{W}}{\bar{W}} \\ =& p\frac{W_H-(pW_H+(1-p)W_D)}{pW_H+(1-p)W_D} \\ =& \frac{p(1-p)(W_H-W_D)}{W_H-(1-p)(W_H-W_D)} \\ \end{aligned} dtdp===pn+1−pn=pWˉWH−WˉppWH+(1−p)WDWH−(pWH+(1−p)WD)WH−(1−p)(WH−WD)p(1−p)(WH−WD)
这里不知道推导过程哪里有问题,正确的复制动态方程应该是
d p d t = p ( W H − W ˉ ) \frac{\text{d}p}{\text{d}t} = p(W_H-\bar{W}) dtdp=p(WH−Wˉ)
仿真
取 W 0 = 0 W_0=0 W0=0, C = 6 C=6 C=6, V = 3 V=3 V=3,仿真结果如图所示。
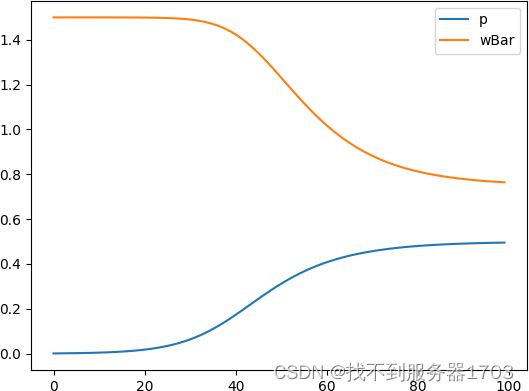
另外仿真可得 W 0 W_0 W0对结果几乎没有影响,复制动态方程中的分母 W ˉ \bar{W} Wˉ只影响曲线收敛的速度。
参考
- 【公开课】耶鲁大学:博弈论(中英双语字幕)-bilibili
- 约翰·梅纳德·史密斯(John Maynard Smith).《演化与博弈论》(Evolution and the Theory of Games)
- 鹰派与鸽派的博弈 -豆瓣
- https://www.cs.rug.nl/~michael/teaching/gametheorysheets.pdf
- Evolutionary Game Theory -Stanford Encyclopedia of Philosophy
- 李巧宇.基于演化博弈理论的自组织任务分配动力学研究[D].南开大学.2019.
- 懦夫博弈 -百度百科
- https://www.cs.cmu.edu/~sandholm/cs15-892F13/algorithmic-game-theory.pdf
附代码
import matplotlib.pyplot as plt
import numpy as np
V = 3
C = 6
W0 = 0
EHH = (V-C)/2.0
EHD = V
EDH = 0
EDD = V/2.0
p = 1e-3
pvec = []
WBarvec = []
for n in range(100):
wH = W0 + p*EHH + (1-p)*EHD
wD = W0 + p*EDH + (1-p)*EDD
WBar = p*wH + (1-p)*wD
p += 0.1 * p*(wH - WBar)
pvec.append(p)
WBarvec.append(WBar)
plt.plot(pvec)
plt.plot(WBarvec)
plt.legend(['p', 'wBar'])
plt.show()