One_hot和Word2Vec两种词向量方法的原理及比较
对于文本处理,首要的任务是要对非结构化数据进行结构化处理,由此诞生了词向量表示的方法,再众多词向量表示方法中,尤其以One_hot和word2vec两种方法最常用,下面也针对这俩方法进行阐述
One_hot方法
One_hot方法是最简单的一种方法,也是出现最早的一种方法,其原理就比如一个语料有M各词,其中每一个词的One_hot表示方式为当前词用1表示,其余用0表示,也就是说语料有多少词,那么词向量的维度就是多少,而且词向量形式如[0,0,......,1,0,0,......],其中第i个词为1,其余为0。
从One_hot的原理不难发现,当语料中添加新的词,那么每个词的词向量就会发生变化,而且向量中充斥着大量的0,使得过于稀疏,除此之外,语料有多大,词向量的维度就有多大,使得最终的矩阵变得过于庞大,不利于存储及计算。尤其是One_hot不能表示词语之间的关系,比如猫,老鼠,直观上很容易理解的到猫和老鼠 有比较强的关系,如果用One_hot来表示,结果就是
“猫”:[0,0,0,1,0,0,0]
“老鼠”:[0,0,1,0,0,0,0]
那么两个向量做内积,就很容易发现[0,0,0,1,0,0,0] x[0,0,1,0,0,0,0] = 0,最后的结果就是毫无关系,这显然不太符合实际,所以再现在One_hot方法较少的被用到实际项目中了。
针对One_hot存在的问题,Hinton提出了分布式表示方法,很好的解决了One_hot的缺陷。其中最具代表的就是word2vec
Word2Vec方法
Word2Vec通过Embedding层将One-Hot Encoder转化为低维度的连续值(稠密向量),并且其中意思相近的词将被映射到向量空间中相近的位置。 从而解决了One-Hot Encoder词汇鸿沟和维度灾难的问题。
1. E m b e d d i n g 层 1.Embedding层 1.Embedding层
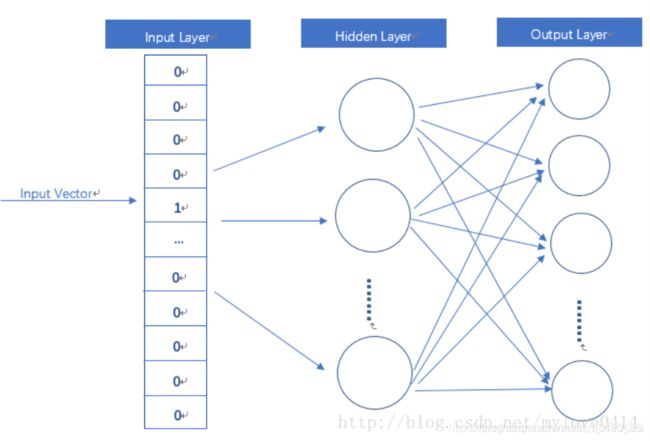
Embedding层(输入层到隐藏层)是以one hot为输入、中间层节点数为词向量维数的全连接层,这个全连接层的参数就是我们要获取的词向量表!

2. W o r d 2 v e c 模 型 概 述 2.Word2vec模型概述 2.Word2vec模型概述
word2vec其实就是简化版的NN,它事实上训练了一个语言模型,通过语言模型来获取词向量。所谓语言模型,就是通过前n个字预测下一个字的概率,就是一个多分类器而已,我们输入one hot,然后连接一个全连接层,然后再连接若干个层,最后接一个softmax分类器,就可以得到语言模型了,然后将大批量文本输入训练就行了,最后得到第一个全连接层的参数,就是词向量表。
记词典大小为V
输入层:one-hot vector,V个节点
隐藏层:无激活函数,D个节点(D
输出层:softmax回归输出输入词的邻近词的概率分布,V个节点

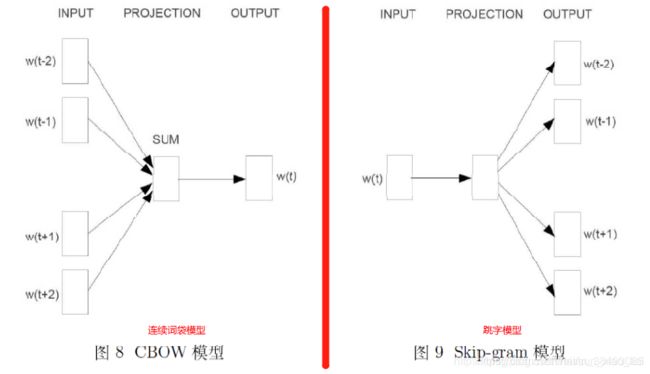
对同样一个句子:Hangzhou is a nice city。我们要构造一个语境与目标词汇的映射关系,其实就是input与label的关系。 假设滑窗尺寸为1 ,那么
CBOW的样本形式为:[Hangzhou,a]—>is,[is,nice]—>a,[a,city]—>nice
Skip-Gram的样本形式为:(is,Hangzhou),(is,a),(a,is), (a,nice),(nice,a),(nice,city)
3. 模 型 求 解 : 负 采 样 方 法 3.模型求解:负采样方法 3.模型求解:负采样方法
本文我们只对负采样方法negative sampling展开介绍
3.1 NCE Loss提出背景
Softmax是用来实现多类分类问题常见的损失函数。但如果类别特别多,softmax的效率就是个问题了。比如在word2vec里,每个词都是一个类别,在这种情况下可能有100万类。那么每次都得预测一个样本在100万类上属于每个类的概率,这个效率是非常低的。
3.2 NCE的主要思想
对于每一个样本,除了他自己的label,同时采样出N个其他的label
从而我们只需要计算样本在这N+1个label上的概率,而不用计算样本在所有label上的概率
而样本在每个label上的概率最终用了Logistic的损失函数
NCE本质上是把多分类问题转化为2分类问题
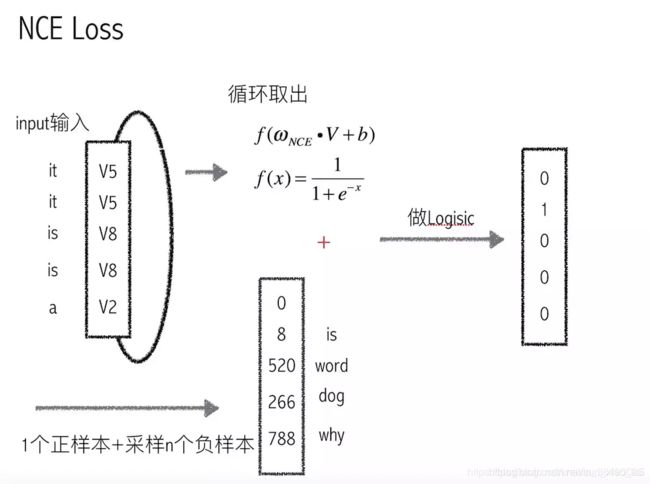
3.3 NCE负采样策略
带权采样:高频词选为负样本的概率大,低频词概率小
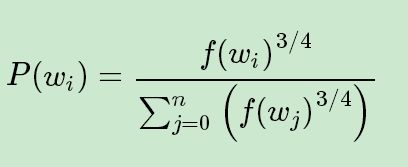
4. w o r d 2 v e c 之 连 续 词 袋 模 型 C B O W 4.word2vec之连续词袋模型CBOW 4.word2vec之连续词袋模型CBOW
根据当前词的上下文环境来预测当前词


5. w o r d 2 v e c 之 跳 字 模 型 s k i p − g r a m 5.word2vec之跳字模型skip-gram 5.word2vec之跳字模型skip−gram
根据当前词预测上下文
可以理解为是将CBOW模型中的context(w)拆成一个个来考虑

6. 基 于 w o r d 2 v e c 简 单 实 战 6.基于word2vec简单实战 6.基于word2vec简单实战
import jieba
import jieba.analyse
from gensim.test.utils import common_texts, get_tmpfile
from gensim.models import Word2Vec
#文件位置需要改为自己的存放路径
#将文本分词
with open('C:\\Users\Administrator\Desktop\\in_the_name_of_people\in_the_name_of_people.txt',encoding='utf-8') as f:
document = f.read()
document_cut = jieba.cut(document)
result = ' '.join(document_cut)
with open('./in_the_name_of_people_segment.txt', 'w',encoding="utf-8") as f2:
f2.write(result)
#加载语料
sentences = word2vec.LineSentence('./in_the_name_of_people_segment.txt')
#训练语料
path = get_tmpfile("word2vec.model") #创建临时文件
model = word2vec.Word2Vec(sentences, hs=1,min_count=1,window=10,size=100)
# model.save("word2vec.model")
# model = Word2Vec.load("word2vec.model")
#输入与“贪污”相近的100个词
for key in model.wv.similar_by_word('贪污', topn =100):
print(key)
#输出了100个,示例前几个
('地皮', 0.9542419910430908)
('高昂', 0.934522807598114)
('证', 0.9154356122016907)
('上强', 0.9113685488700867)
('一抹', 0.9097814559936523)
('得罪', 0.9082552790641785)
('屁股', 0.9072068929672241)
('能伸能屈', 0.9049990177154541)
('二十五万', 0.9045952558517456)
参考作者:传送门