哈夫曼树详解及其应用(哈夫曼编码)
一,哈夫曼树的基本概念
路径:从树中一个结点到另一个结点之间的分支构成这两个结点间的路径
结点的路径长度:两结点之间路径上的分支数
树的路径长度:从树根到每一个结点的路径长度之和.记作:TL
权(weight):将树中结点赋给一个有着某种含义的数值,则这个数值秒针为该结点的权
结点的带权路径长度:从根结点到该结点之间的路径长度与该结点的权的乘积.
树的带权路径长度:树中所有叶子结点的带权路径长度之和.记作:WPL(Weighted Path Length)
哈夫曼树:最优树(带权路径长度(WPL)最短的树)
注:"带权路径长度最短"是在"度相同"的树中比较而得的结果,因此有最优二叉树,最优三叉树之称等等.
哈夫曼树:最优二叉树(带权路径长度最短的二叉树)
特点:
1满二叉树不一定是哈夫曼树.
2哈夫曼树中权越大的叶子离根越近.
3具有相同带权结点的哈夫曼树不惟一.
二,哈夫曼树的构造算法
因为哈夫曼树权越大的叶子离根越近的特点,所以,构造哈夫曼树时首先选择权值小的叶子结点.
哈夫曼算法(构造哈夫曼树的方法)
(1)根据n个给定的权值构成n棵二叉树的森林,森林中每一棵树只有一个带权的根结点(构造森林全是根)
(2)在森林中,选取两棵根结点的权值最小的树作为左右子树,构造一棵新的二叉树,且设置新的二叉树的根结点的权值为其左右子树上根结点的权值之和.(选用两小造新树)
(3)在森林中删除这两棵树,同时将新得到的二叉树加入到森林中.(删除两小添新人)
(4)重复(2)和(3),直到森林中只有一棵树为止,这棵树即为哈夫曼树.(重复2,3剩单根)
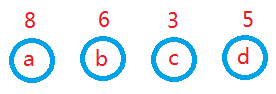
例:有4个结点a,b,c,d,权值分别人8,6,3,5,构造哈夫曼树
1,构造森林全是根
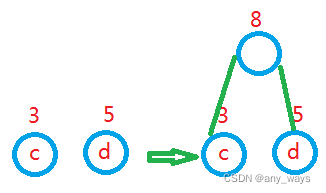
2,选用两小造新树
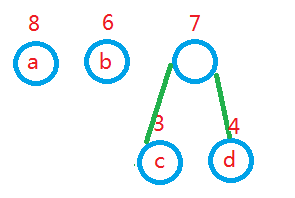
3,删除两小添新人
4,重复2,3剩单根
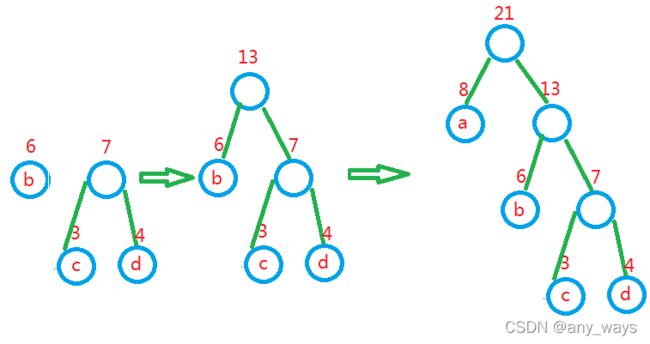
当最后森林只剩下一个根时,这棵树就是哈夫曼树
哈夫曼树当中:
1,只有度为0或2的结点,没有度为1的结点
2,包含n个叶子结点的哈夫曼树中共有2n-1个结点
三,哈夫曼树构造算法的实现
这里采用顺序存储结构---一维结构数组
结点类型定义:(包含4个成员的结构体)
typedef struct{
int weight;//权重
int parent,lch,rch;//双亲,左孩子,右孩子
}HTNode,*HuffmanTree;
| 哈夫曼树中结点下标i | weight | parent | lch | rch |
|---|---|---|---|---|
| 1 | ||||
| 2 | ||||
| 3 | ||||
| 4 | ||||
| ...... | ||||
| ...... | ||||
| 2n-1 |
有n个叶子结点的哈夫曼树中共有2n-1个结点,这里为了方便,不使用0下标,数组大小为2n
先定义一个数组HuffmanTree H(H是一个指针,也可以是一个数组)
具体的实现如下:
#include
#include
#define MAX_SIZE 5
typedef struct{
int weight;//权重
int parent,lch,rch;//双亲,左孩子,右孩子
}HTNode,*HuffmanTree;
int j = 0;
int k = 0;//设置两个全局变量j,k,用来接收两个最小权重在数组中的下标
int cmp(void* e1, void* e2)//配合qsort()函数的比较函数
{
if(*(int*)e1 - *(int*)e2 > 0)return 1;
else if(*(int*)e1 - *(int*)e2 < 0)return -1;
else return 0;
}
int Select(HuffmanTree HT, int n)//找出权重最小的二个根结点在HT数组中的位置
{
int i = 0;
int p = 0;//用于控制数组arr,按顺序存储数据
int arr[MAX_SIZE] = {0};//用于存储根结点的权重值,以便排序
int count = 0;//用来记录arr数组中,有几个值需要排序
for(i = 1; i <= n; i++)
{
if(HT[i].parent == 0&&HT[i].weight != 0)//必须是有权重值的根结点,才会被加入到arr数组当中
{
arr[++p-1] = HT[i].weight;
count++;//arr有效元素个数+1,arr数组中初始化的0,不算有效元素
}
}
qsort(arr, count, sizeof(int), cmp);//对arr数组中的权重值排序,而且只对有效元素排序,
for(i = 1; i <= n; i++)
{
if(HT[i].weight == arr[0])//arr[0]是最小元素
{
j = i;
break;
}
}
for(i = 1; i <= n; i++)
{
if(HT[i].weight == arr[1] && i != j)//arr[1]是第二小的元素,且要保证arr[0]=arr[1]时,选取的两个下标不相同
{
k = i;
break;
}
}
return 0;
}
void CreatHuffmanTree(HuffmanTree HT, int n)
{
int i = 0;
int m = 0;
if(n <= 1)return;
m = 2*n - 1;
HT = malloc(sizeof(HTNode)*(m+1));//有n个叶子,树就有2n-1个结点,0号位置不用,所以需要2n个结点大小
for(i = 1; i <= m+1; i++)//将2n-1个元素初始化,lch,rch,parent设置为0
{
HT[i].lch = 0;
HT[i].rch = 0;
HT[i].parent = 0;
HT[i].weight = 0;
}
for(i = 1; i <= n; i++)//设置叶子结点weight值(权重)
{
int input = 0;
printf("请输入每个元素的权重:>");
scanf("%d",&input);
HT[i].weight = input;
}
//开始创建哈夫曼树
for(i = 1; i < n; i++)//初始有n个根结点,就要新产生n-1个结点,循环一次产生一个
{
Select(HT, m+1);//得到权重最小的两个根结点在HT数组中的下标j,k
HT[n+i].lch = j;//HT数组中有n个根结点,那么新生成的根结点下标从n+1开始
HT[n+i].rch = k;//设置新根结点的孩子值
HT[n+i].weight = HT[j].weight + HT[k].weight;//设置新根结点的权重值为两孩子权重值之和
HT[j].parent = n+i;//新根结点的下标值为最小权值的两个结点的双亲
HT[k].parent = n+i;
}
}
int main()
{
HuffmanTree HT = 0;
CreatHuffmanTree(HT, MAX_SIZE);
return 0;
}
四,哈夫曼树的应用(哈夫曼编码)
前缀编码:要设计长度不等的编码,则必须使任一字符的编码都不是另一个字符的编码的前缀
什么样的前缀码能使得电文总长最短?-----哈夫曼编码
1,统计字符集中每个字符在电文中出现的平均概率(概率越大,要求编码越短).
2,利用哈夫曼树的特点:权越大的叶子离根越近;将每个字符的概率值作为权值,构造哈夫曼树.则概率越大的结点,路径越短.
3,在哈夫曼树的每个分支上标上0或1:结点的左分支标0,右分支标1.把从根到每个叶子的路径上的标号连接起来,作为该叶子代表的字符的编码.
例:要传输的字符集S={D,I,C,T,;}
字符出现频率 W={2,4,2,3,3}
那么构造出来的哈夫曼树就是:
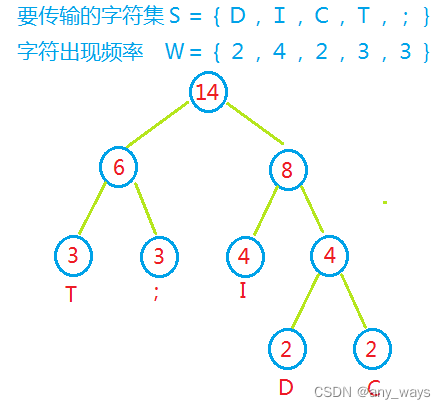
然后在哈夫曼树的每个分支上标上0或1,结点的左分支标0,右分支标1
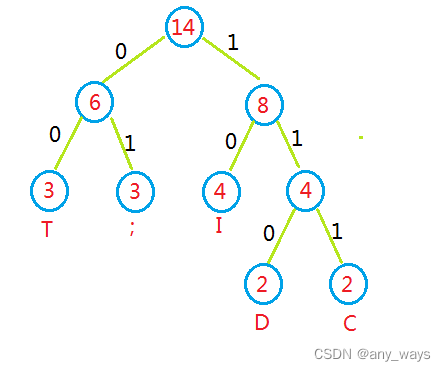
把从根到每个叶子的路径上的标号连接起来,作为该叶子代表的字符的编码.
那么T的编码为:00,;的编码为01,I的编码为10,D的编码为110,C的编码为111
如果这个字符集中有一段电文是{DIT;DIC;TDI;}那么它的编码就可以写成:
1101000011101011101001101001
相反,如果收到的编码是100011001,那么翻译过来就是ITD;
哈夫曼编码能够保证是前缀码,即每个编码都不是另一个编码的前缀
哈夫曼编码能够保证字符编码总长最短
所以,哈夫曼编码的性质有:
1,哈夫曼编码是前缀码
2,哈夫曼编码是最优前缀码
五,哈夫曼编码的算法实现
1,字符串翻译成哈夫曼编码
(1)首先以字符集对应的字符权重,创建哈夫曼树
(2)依次从每个叶子结点,往上回溯,如果有双亲,判断该叶子结点是双亲的左孩子还是右孩子,如果是左孩子,记录0,如果是右孩子,记录1,直到回溯到根结点,这些组合起来的0和1就是哈夫曼的编码,我们用一个指针数组存储每个叶子结点的哈夫曼编码
例:已知{a,b,o,u,t}对应的出现频率为{3,4,5,6,7}
那么a,b,o,u,t分别对应的哈夫曼编码是多少?
"aoutbabtoutbaotubatobatu"对应的哈夫曼编码是多少?
#include
#include
#include
#define MAX_SIZE 5
typedef struct{
int weight;//权重
int parent,lch,rch;//双亲,左孩子,右孩子
}HTNode,*HuffmanTree;
int j = 0;
int k = 0;//设置两个全局变量j,k,用来接收两个最小权重在数组中的下标
int cmp(void* e1, void* e2)//配合qsort()函数的比较函数
{
if(*(int*)e1 - *(int*)e2 > 0)return 1;
else if(*(int*)e1 - *(int*)e2 < 0)return -1;
else return 0;
}
int Select(HuffmanTree* HT, int n)//找出权重最小的二个根结点在HT数组中的位置
{
int i = 0;
int p = 0;//用于控制数组arr,按顺序存储数据
int arr[MAX_SIZE] = {0};//用于存储根结点的权重值,以便排序
int count = 0;//用来记录arr数组中,有几个值需要排序
for(i = 1; i <= n; i++)
{
if((*HT)[i].parent == 0&&(*HT)[i].weight != 0)//必须是有权重值的根结点,才会被加入到arr数组当中
{
arr[++p-1] = (*HT)[i].weight;
count++;//arr有效元素个数+1,arr数组中初始化的0,不算有效元素
}
}
qsort(arr, count, sizeof(int), cmp);//对arr数组中的权重值排序,而且只对有效元素排序,
for(i = 1; i <= n; i++)
{
if((*HT)[i].weight == arr[0])//arr[0]是最小元素
{
j = i;
break;
}
}
for(i = 1; i <= n; i++)
{
if((*HT)[i].weight == arr[1] && i != j)//arr[1]是第二小的元素,且要保证arr[0]=arr[1]时,选取的两个下标不相同
{
k = i;
break;
}
}
return 0;
}
void CreatHuffmanTree(HuffmanTree* HT, int n, int*arr)
{
int i = 0;
int m = 0;
if(n <= 1)return;
m = 2*n - 1;
*HT = malloc(sizeof(HTNode)*(m+1));//有n个叶子,树就有2n-1个结点,0号位置不用,所以需要2n个结点大小
for(i = 1; i <= m; i++)//将2n-1个元素初始化,lch,rch,parent设置为0
{
(*HT)[i].lch = 0;
(*HT)[i].rch = 0;
(*HT)[i].parent = 0;
(*HT)[i].weight = 0;
}
for(i = 1; i <= n; i++)//设置叶子结点weight值(权重)
{
(*HT)[i].weight = arr[i-1];
}
//开始创建哈夫曼树
for(i = 1; i < n; i++)//初始有n个根结点,就要新产生n-1个结点,循环一次产生一个
{
Select(HT, m+1);//得到权重最小的两个根在数组中的下标j,k
(*HT)[n+i].lch = j;//HT数组中有n个根结点,那么新生成的根结点下标从n+1开始
(*HT)[n+i].rch = k;//设置新根结点的孩子值
(*HT)[n+i].weight = (*HT)[j].weight + (*HT)[k].weight;//设置新根结点的权重值为两孩子权重值之和
(*HT)[j].parent = n+i;//新根结点的下标值为最小权值的两个结点的双亲
(*HT)[k].parent = n+i;
}
}
void GetHC(HuffmanTree HT, int n, char** HC[])//获取每个叶子节点的哈夫曼编码
{
char* TempArr = (char*)malloc(n);//创建一个临时数组,来存放一个叶子节点的哈夫曼编码
TempArr[n-1] = '\0';//把临时数组最后一位设置为'\0'
*HC = malloc(sizeof(char*)*n);//给传进来的二维数组申请空间,并把这个空间的地址赋给HC
int i = 0;
for(i = 1; i <= n; i++)//从1到5循环,为了方便下标0不用,也为了对应上面的哈夫曼树
{
int m = 1;//m是用来记录临时数组中,放进了几个字符.后面就知道用多大的空间来接收了.还可以控制临时数组存放第一个字符的起始位置
int a = i;//a用来控制当前循环的结点
while(HT[a].parent)//如果该结点有双亲就执行
{
if(HT[HT[a].parent].lch == a)//如果该结点是其双亲的左孩子
TempArr[n-1-m++] = '0';//记录字符0
if(HT[HT[a].parent].rch == a)//如果该结点是其双亲的右孩子
TempArr[n-1-m++] = '1';//记录字符1
a = HT[a].parent;//再定位在该结点的双亲,用于下次循环
}
(*HC)[i] = malloc(m);//根据m的值,可以知道临时数组中有几个字符,然后准确的申请相应的空间
strcpy((*HC)[i], &TempArr[n-m]);//MAX_SIZE-m,为该数组第一个字符的位置,把临时数组中的字符串,复制到目标数组
}
free(TempArr);//释放临时空间
}
int main()
{
HuffmanTree HT;
char** HC;//创建一个指针数组
int arr1[5] = {3,4,5,6,7};
char arr2[5] = {'a','b','o','u','t'};
char* arr3 = "aoutbabtoutbaotubatobatu";
int len_arr3 = strlen(arr3);
int nums = sizeof(arr1)/sizeof(arr1[0]);//字符集个数
CreatHuffmanTree(&HT, nums, arr1);//根据权值创建哈夫曼树
GetHC(HT, nums, &HC);//Get Huffman Code 获取哈夫曼编码
int i = 1;
for(i = 1; i<=nums; i++)
{
printf("%c的哈夫曼编码为%s\n",arr2[i-1],HC[i]);
}
printf("aoutbabtoutbaotubatobatu字符串的编码为:\n");
for(i = 0; i < len_arr3; i++)
{
if(arr3[i] == 'a')printf("%s",HC[1]);
else if(arr3[i] == 'b')printf("%s",HC[2]);
else if(arr3[i] == 'o')printf("%s",HC[3]);
else if(arr3[i] == 'u')printf("%s",HC[4]);
else if(arr3[i] == 't')printf("%s",HC[5]);
else return;
}
return 0;
}
2,哈夫曼编码翻译成字符串
(1)首先以字符集对应的字符权重,创建哈夫曼树
(2)从根结点开始,对应着编码,如果编码是0,则指向根结点的左孩子,如果编码是1,则指向根结点的右孩子,然后把左孩子或右孩子当成根结点,根据提供的哈夫曼编码继续向下推,直到找到的结点没有左右孩子,为叶子的时候,就可以得到该结点的权值和字符.
注意:哈夫曼树对应的数组HT中,叶子结点是在数组最前面下标1开始,依次排列.根结点在数组的最后也就是下标为2n(n个叶子结点,下标从1开始)
例:以上面例子,继续
已知{a,b,o,u,t}对应的出现频率为{3,4,5,6,7}
那么110000110111000110111110001001111110对应的字符串是什么?
#include
#include
#include
#define MAX_SIZE 5
typedef struct{
int weight;//权重
int parent,lch,rch;//双亲,左孩子,右孩子
}HTNode,*HuffmanTree;
int j = 0;
int k = 0;//设置两个全局变量j,k,用来接收两个最小权重在数组中的下标
int cmp(void* e1, void* e2)//配合qsort()函数的比较函数
{
if(*(int*)e1 - *(int*)e2 > 0)return 1;
else if(*(int*)e1 - *(int*)e2 < 0)return -1;
else return 0;
}
int Select(HuffmanTree* HT, int n)//找出权重最小的二个根结点在HT数组中的位置
{
int i = 0;
int p = 0;//用于控制数组arr,按顺序存储数据
int arr[MAX_SIZE] = {0};//用于存储根结点的权重值,以便排序
int count = 0;//用来记录arr数组中,有几个值需要排序
for(i = 1; i <= n; i++)
{
if((*HT)[i].parent == 0&&(*HT)[i].weight != 0)//必须是有权重值的根结点,才会被加入到arr数组当中
{
arr[++p-1] = (*HT)[i].weight;
count++;//arr有效元素个数+1,arr数组中初始化的0,不算有效元素
}
}
qsort(arr, count, sizeof(int), cmp);//对arr数组中的权重值排序,而且只对有效元素排序,
for(i = 1; i <= n; i++)
{
if((*HT)[i].weight == arr[0])//arr[0]是最小元素
{
j = i;
break;
}
}
for(i = 1; i <= n; i++)
{
if((*HT)[i].weight == arr[1] && i != j)//arr[1]是第二小的元素,且要保证arr[0]=arr[1]时,选取的两个下标不相同
{
k = i;
break;
}
}
return 0;
}
void CreatHuffmanTree(HuffmanTree* HT, int n, int*arr)
{
int i = 0;
int m = 0;
if(n <= 1)return;
m = 2*n - 1;
*HT = malloc(sizeof(HTNode)*(m+1));//有n个叶子,树就有2n-1个结点,0号位置不用,所以需要2n个结点大小
for(i = 1; i <= m; i++)//将2n-1个元素初始化,lch,rch,parent设置为0
{
(*HT)[i].lch = 0;
(*HT)[i].rch = 0;
(*HT)[i].parent = 0;
(*HT)[i].weight = 0;
}
for(i = 1; i <= n; i++)//设置叶子结点weight值(权重)
{
(*HT)[i].weight = arr[i-1];
}
//开始创建哈夫曼树
for(i = 1; i < n; i++)//初始有n个根结点,就要新产生n-1个结点,循环一次产生一个
{
Select(HT, m+1);//得到权重最小的两个根在数组中的下标j,k
(*HT)[n+i].lch = j;//HT数组中有n个根结点,那么新生成的根结点下标从n+1开始
(*HT)[n+i].rch = k;//设置新根结点的孩子值
(*HT)[n+i].weight = (*HT)[j].weight + (*HT)[k].weight;//设置新根结点的权重值为两孩子权重值之和
(*HT)[j].parent = n+i;//新根结点的下标值为最小权值的两个结点的双亲
(*HT)[k].parent = n+i;
}
}
void GetHC(HuffmanTree HT, int n, char** HC[])//获取每个叶子节点的哈夫曼编码
{
char* TempArr = (char*)malloc(n);//创建一个临时数组,来存放一个叶子节点的哈夫曼编码
TempArr[n-1] = '\0';//把临时数组最后一位设置为'\0'
*HC = malloc(sizeof(char*)*n);//给传进来的二维数组申请空间,并把这个空间的地址赋给HC
int i = 0;
for(i = 1; i <= n; i++)//从1到5循环,为了方便下标0不用,也为了对应上面的哈夫曼树
{
int m = 1;//m是用来记录临时数组中,放进了几个字符.后面就知道用多大的空间来接收了.还可以控制临时数组存放第一个字符的起始位置
int a = i;//a用来控制当前循环的结点
while(HT[a].parent)//如果该结点有双亲就执行
{
if(HT[HT[a].parent].lch == a)//如果该结点是其双亲的左孩子
TempArr[n-1-m++] = '0';//记录字符0
if(HT[HT[a].parent].rch == a)//如果该结点是其双亲的右孩子
TempArr[n-1-m++] = '1';//记录字符1
a = HT[a].parent;//再定位在该结点的双亲,用于下次循环
}
(*HC)[i] = malloc(m);//根据m的值,可以知道临时数组中有几个字符,然后准确的申请相应的空间
strcpy((*HC)[i], &TempArr[n-m]);//MAX_SIZE-m,为该数组第一个字符的位置,把临时数组中的字符串,复制到目标数组
}
free(TempArr);//释放临时空间
}
void GetStr(HuffmanTree HT, int nums, char* arr2, char* arr3)
{
int i = 0;
int n = 2*nums-1;//nums个叶子,就有2*nums-1个结点,根结点在HT数组中的下标为2*nums-1
int len = strlen(arr3);
for(i=0; i < len; i++)//循环依次读入整个arr3字符串
{
if(arr3[i] == '1')n = HT[n].rch;//读入的数据为1时,指向该结点的右孩子
else if(arr3[i] == '0')n = HT[n].lch;//读入的数据为1时,指向该结点的左孩子
else return;
switch(n)//判断此时,有没有到达叶子结点,当n=1,2,3,4,5时就到达了叶子结点,输出对应的值
{
case 1:
{
n = 2*nums -1;
printf("%c", arr2[0]);
break;
}
case 2:
{
n = 2*nums -1;
printf("%c", arr2[1]);
break;
}
case 3:
{
n = 2*nums -1;
printf("%c", arr2[2]);
break;
}
case 4:
{
n = 2*nums -1;
printf("%c", arr2[3]);
break;
}
case 5:
{
n = 2*nums -1;
printf("%c", arr2[4]);
break;
}
}
}
}
int main()
{
HuffmanTree HT;
char** HC;//创建一个指针数组
int arr1[5] = {3,4,5,6,7};
char arr2[5] = {'a','b','o','u','t'};
char* arr3 = "110000110111000110111110001001111110";
int nums = sizeof(arr1)/sizeof(arr1[0]);//字符集个数
CreatHuffmanTree(&HT, nums, arr1);//根据权值创建哈夫曼树
GetHC(HT, nums, &HC);//Get Huffman Code 获取哈夫曼编码
GetStr(HT, nums, arr2, arr3);//把哈夫曼编码翻译成字符串
return 0;
}