推荐算法炼丹笔记:推荐系统采样评估指标及线上线下一致性问题
本文对于推荐系统中的采样评估指标进行了讨论,内容略多, 还有一些数学推导, 有兴趣的可以去阅读文末给出的原始论文链接, 此处直接列出核心观点:
- 在评估推荐算法的效果时,能不采样就不采样!
- 除了AUC,Precision@K,Recall@K,Average Precision,NDCG都是不一致的,采样计算得到的结果和真实结果可能差很大!
- 现在随机采样计算得到的评估指标的分数具有高偏差,低方差的问题,很多情况和真实情况不符合,结论可能也都错了!
- 如果一定要进行采样计算评估指标的值, 建议采用本文提出的纠正的方案,虽然可能会有较大的方差,但是偏差大大降低,更加接近真实情况;
因为本文实在是有些干,所以不想读文章的朋友直接记住下面两张PPT的内容就可以了。


文章的框架是:
- 先介绍目前我们采样的评估指标的计算方法;
- 介绍我们目前常用的一些评估指标,包括AUC,Precision,Recall,AP,NDCG;
- 然后讨论怎么样才算是好的采样评估指标(一致性),之后开始举例讨论现有的诸多指标例如Recall,Precision,AP等存在不一致性,也就是说采样之后计算的指标是不能反映真实情况的;
- 为了能弥补现有的采样策略的问题,作者提出了三种不同的修正策略,并验证了其在采样评估的时候相较于原始采样策略的优势(更加接近于真实情况);
- 最后作者给出了一些实践建议&小结。
Item推荐的评估

这么做也就意味着我们对于某个用户所有的商品都是同等受欢迎的,当然在一些复杂的场景下,有些用户是重点用户,会有不同的权重,本篇文章重点讨论简化的情况。
一、 评估指标
此处我们介绍在推荐系统中常见的几种评估指标。以及它们对应的计算方法。
1.1 AUC
Area under ROC curve(AUC):

1.2 Precision & Recall
在位置K的Precision:衡量topK的预测商品的相关商品的比例。
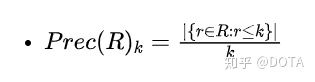
在位置K的Recall:衡量topK预测商品的recovered的比例。

1.3 Average Precision
在位置K的Average Precision用来衡量一个相关商品在所有ranks的精度。
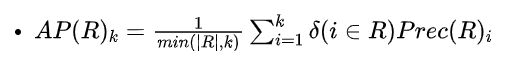
1.4 Normalized discounted cumulative gain(NDCG)
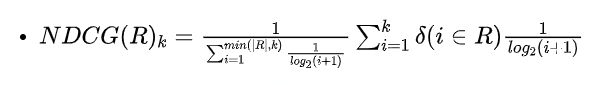

随着 r 的增长,各个指标的变化:

我们可以发现:
- AP是下降最快的;rank1的AP相较于rank2是2倍重要;rank1的NDCG是1.58倍重要与rank2;
- AUC几乎是线性下降的, 也就是说我们将商品从102位排到第101位和把商品从第2位排到第1位是类似的;
二、采样指标——采样的必要性 & 一致性
在实践中,尤其是很多大型的平台,用户和商品都是亿级别的,对这种级别的数据进行排序不仅会耗费大量的计算资源,而且还要等很久的时间,所以大家都会选择采样观察指标。很多时候大家会选择采样个无关的商品然后加上相关的商品再去计算指标,其实只需要保证采样之后计算得到的指标和我们的全量数据计算得到的指标是保证相对大小的,那么一般是没有任何问题的。
一致性:令评估数据D是固定的,如果任意两个推荐算法A和B在期望下能保证相对顺序,那么我们说在采样下指标M是保持一致的, 也就是说,对于A和B,我们有:

而如果是不一致的,那么评估M并不是一个M真实表现的好的indicator。
不一致性:上面我们知道了一致性的重要性,那么我们常用的那些指标AUC, Precision, Recall等等是否满足一致性呢?下面我们来看一些例子。
1. 全量情况下:
假设我们有三个推荐系统A,B,C,以及n=10000个商品,每个推荐系统将会在5个特殊实例上(例如五个用户)上面进行评估, 这些实例每个只对应一个相关的商品。而这三个推荐系统的结果为:
- A : 对五个实例, 将所有商品的推荐位置都排在了100;
- B : 将两个实例, 将商品的推荐位置排在了40;
- C : 将某个商品在某个评估实例中的排名在第2位,除此之外,其他四个实例的排名都不好;
最终我们的得分计算如下Table1,可以按照评估指标的公式直接进行计算。

2. 采样情况下:
现在假设我们随机采样了 m=99 个不相关的商品,然后我们重新计算 r 在采样的集合下的新的位置。上图中的Table2展示了采样1000次的重新采样的均值和标准差。通过观察Table1和Table2,我们发现:
- 在Table1中,C 的AP是 A 和 B 的10倍,但是在Table2中,的AP是最低的;
- Recall, NDCG在Table1和Table2中的相对顺序是没有保持一致的;
- AUC在两个Table中是唯一一个保持一致的指标。
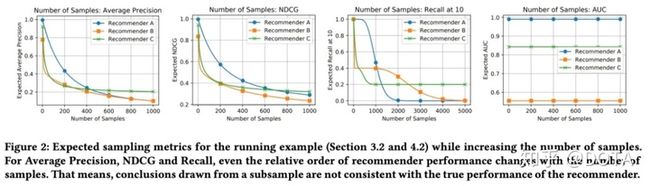
我们修改实验的采样个数重新实验,从Figure2中我们发现:随着我们采样的样本越来越多,我们发现三个推荐系统A ,B,C的相对大小都发生了很大的变化,例如:
- AP指标:当样本个数少于50的时候,系统A>C>B,当样本个数约为200的时候, A>B>C,当样本的个数约为500的时候C>A>B,对于更多的样本,C>A>B.
- NDCG指标:变化和AP指标类似;
- Recall指标:更加敏感;(变化最快)
- AUC维持不变;
三、采样下的rank分布
此处我们还是假设:


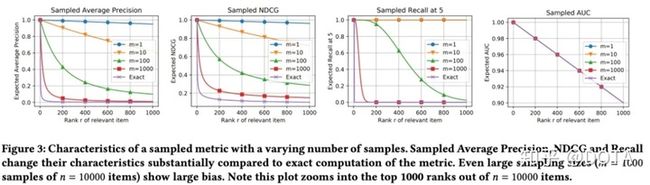
- AP和NDCG(不同的采样的次数m),在不同的 r 下开始时变化最大;(m越大越接近于真实的情况)
- AUC是不变的;
3.1 期望的Metrics
上面主要都是从试验的方面来验证采样之后重新计算的Metric和真实的Metric除了AUC之外基本都是不大置信的,此处我们计算每个Metric的期望。
3.2 AUC的期望
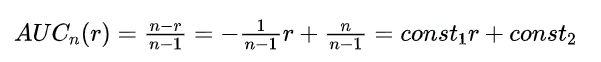
所以最终的期望为:
- 采样计算得到的AUC是真实AUC的无偏估计,所以AUC在采样下是能保证一致的。
3.3 Recall的期望
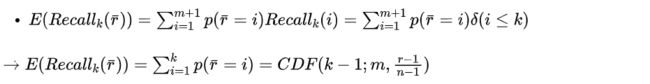
3.4 AP的期望

四、小的采样比例

对于m=1,所有的metric在期望上都给出相同的定性度量,没有必要选择不同的评估指标.
五、纠正的评估指标

六、最小Bias估计器

七、实验验证

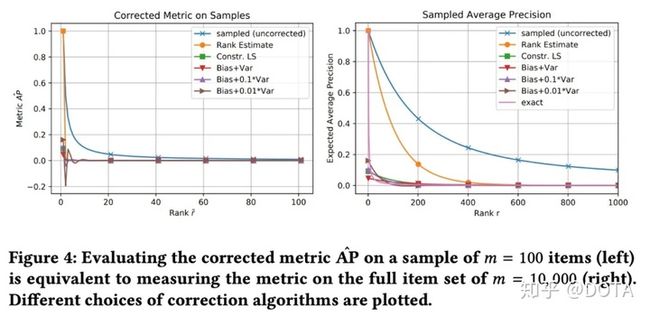
样本大小和数据集大小的影响
此处列出作者的一些核心观点:
- 增加样本的大小m可以减少采样的评估指标的bias;同时也可以降低纠正之后的评估指标;
- 增加数据集的大小,会带来负向的效果;
- 增加评估点的个数|D|,可以降低平均估计的方差,而这对于纠正之后的评估指标是更加友好的。因为没有进行纠正的指标即使最终拿到了0方差,但是会存在非常大的偏差;
7.1 实验
- 不同的推荐算法是否构建不同的排序分布;(例如有些推荐算法在顶部表现好,有些是整体好)
- 采样计算得到的指标的结果和真实的结果是否存在不一致?
- 纠正的评估指标是否可以帮助我们缓解2中的问题?
7.2 排序分布
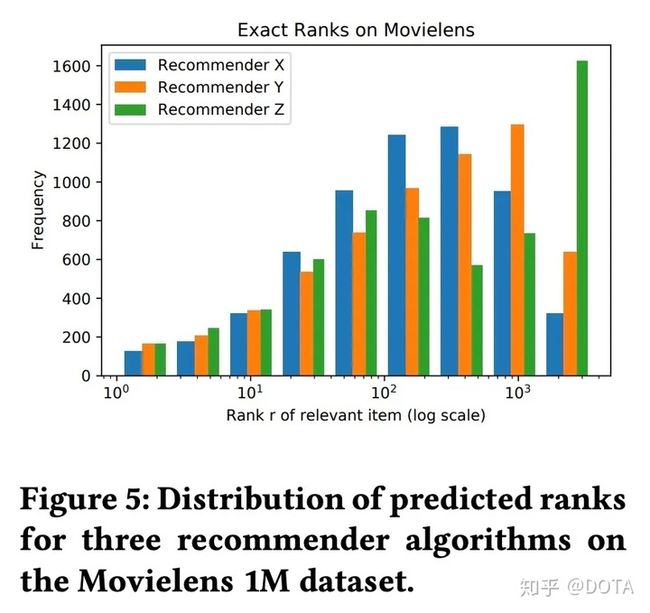
从上面的实验看出,
- Z算法在Top10中的表现是最好的;但是最终将超过1600个用户放到了最坏的bucket;
- X算法相对平衡,最坏的bucket中的商品最少;(低于300)
- Y算法在Top10中的表现优于X,但是整体看,会趋向于将相关的商品放到更差的rank.
7.3 采样指标
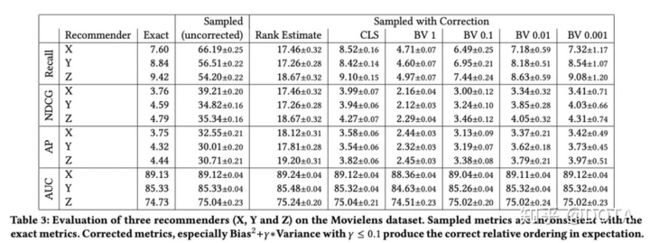
从上表中我们发现,
- Z算法在真实情况下载指标Recall,NDCG以及AP上都是最好的,但是采样之后的结果却和真实情况不一致;在采样指标计算得到的指标有时可能是效果最差的算法,例如X在采样上计算得到的分是最高的,但是实际情况是最低的。
- 这些指标的方差很小,所以不是方差的问题,而是采样带来的偏差。
- 在AUC指标上,所有的算法是保持一致的;
- 所以如果实验中最终的评估指标是采样的Recall,AP,NDCG等,那么很可能结论是错误的.
7.4 纠正的指标
此处作者对比了之前提出的三种不同的纠正方案,同样的从Table3中,我们发现:
- 纠正之后计算得到的指标和真实指标的Bias降低了.
那么纠正之后的指标和未纠正在样本下的影响是什么样的呢?
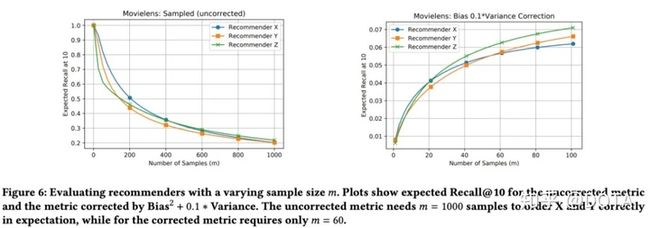
从上图中,我们发现,未进行纠正的采样指标需要超过1000的样本(1/3的样本),才能得到推荐算法Y比X好的结论,但是纠正之后的指标(BV的trade off + r=0.1 )只需要60个样本即可达到同样的效果;
我们发现确实纠正之后的指标得到的Bias下降了,那么方差呢?
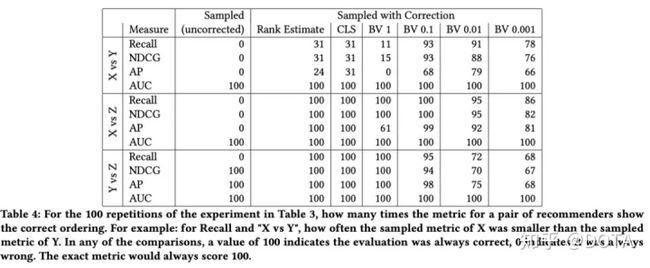
从上面的实验中,我们发现:
- BV 0.1看上去是最好,基本在100次比较中都有90次是对的;
- 几乎所有的纠正方案都可以获得比未进行纠正的指标更为合理的效果;
八、小结 & 建议
小结
本文的研究显示之前大多数论文采用采样计算最终指标的方案其实是错误的,大概率会和真实的情况存在偏差,得到错误的结论。所以如果可以的话,我们应该尽量避免在最终评估时对样本进行采样,如果无法避免的话,那么纠正之后的方案可以拿到更为合理的结果(但是会增加方差)。
建议
从上面的分析以及实验中,我们发现采样之后计算的指标会带来较大的偏差,使用纠正的策略,可以降低偏差,但是也会引入更高的方差。所以如果采样时不可避免,那么有下面几条建议:
- 使用本文中提出的纠正之后的指标并且使用不同的样本重新运行试验多次;
- 重复试验N此(不同数据集,N-fold的交叉验证),方差会由数据集的切分不同而被引入,也有可能会被推荐算法的初始化引入,对负样本采样的过程中,随机种子也会带来另外一种方差, 所以我们很难找到两个不同的推荐算法"statistically significant"差异;但即便如此,我们计算得到的评估指标仍然是一个非常强的indicator,显示我们算法在真实情况下的表现;偏差越小,indication就越强。
- 偏差只有在不采样的情况下才可以较好地消除。
参考文献
- On Sampled Metrics for Item Recommendation:https://dl.acm.org/doi/pdf/10.1145/3394486.3403226
- https://crossminds.ai/video/5f3375ac3a683f9107fc6bb8/
- KDD2020最佳论文: 关于个性化排序任务评价指标的大讨论:https://zhuanlan.zhihu.com/p/206823510
后续我们会筛选出在我们实践中带来提升或者启发的工作进行细致的解读与探讨,欢迎关注我们的公众号,也欢迎多交流,我是三品炼丹师: 一元。
作者:一元
公众号:炼丹笔记

炼丹笔记
推荐算法炼丹笔记:序列化推荐系统
推荐算法炼丹笔记:电商搜索推荐业务词汇表
推荐算法炼丹笔记:推荐系统采样评估指标及线上线下一致性问题
推荐算法炼丹笔记:CTR点击率预估系列入门手册
推荐算法炼丹笔记:科学调参在模型优化中的意义
推荐算法炼丹笔记:如何让你的推荐系统具有可解释性?
2020年推荐系统工程师炼丹手册