【深度学习】李宏毅2021/2022春深度学习课程笔记 - (Multi-Head)Self-Attention (多头)自注意力机制 + Pytorch代码实现
文章目录
- 一、序列标注
- 二、全连接神经网络
- 三、Window
- 四、Self - Attention 自注意力机制
-
- 4.1 简介
- 4.2 运行原理
- 4.3 QKV
- 五、Multi-Head Self-Attention 多头注意力机制
-
- 5.1 运算原理
- 5.2 Positional Encoding
- 六、其他应用
-
- 6.1 语音识别
- 6.2 图像处理
- 6.3 CNN 与 Self-Attention的比较
- 6.4 RNN 与 Self-Attention 的比较
- 6.5 Self-Attention 应用于 Graph
- 七、Pytorch代码实现
-
- 7.1 Self-Attention
- 7.2 Multi-Head Self-Attention
自注意力机制(Self - Attention)实际上是想让机器注意到整个输入中不同部分之间的相关性
一、序列标注
序列标注(Sequence Labeling)是一种在NLP中很基础但是也很重要的任务。以POS词性标注为例,输入是一个句子,输出是每个单词的词性。即输入和输出长度相等的Seq2Seq问题。
二、全连接神经网络
那么如何解决序列标注问题呢?
最简单的想法是:直接将句子中的每个单词转化为向量,然后分别送入FC(全连接层),最后输出每个的单词的词性。
但是这样的做法有个问题:无法处理多词性的单词。
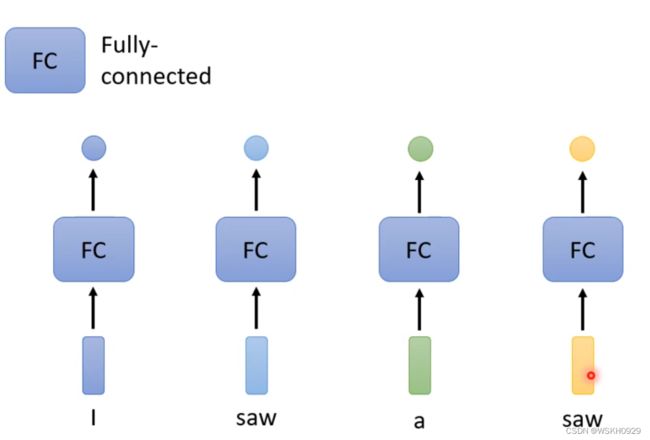
如下图所示,输入句子为“I saw a saw”,句子中第一个saw为动词,第二个saw为名词,而由于其单词一样,词向量也一样,所以经过FC之后的输出也必然一样,这就导致了采用Fully Connected Network形式的输出中两个saw词性必然相同。
所以,Fully Connected Network 全连接神经网络 无法处理多词性的单词。
三、Window
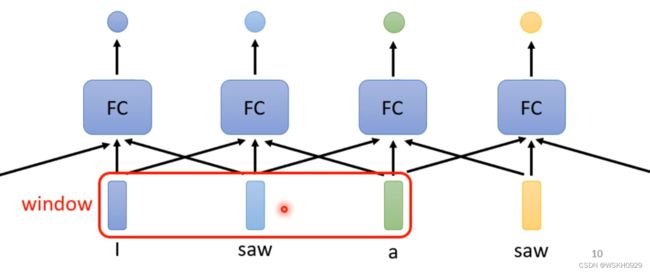
还有一个方法:利用滑动窗口,每个向量查看窗口中相邻的其他向量的性质。
但是我们输入句子的长度是变化的,而窗口大小是固定的,我们在实验时还需要根据数据找出最长序列,从而确定窗口长度,所以这个方法的问题在于:窗口的大小不好定。
四、Self - Attention 自注意力机制
4.1 简介
通过前面的分析,这就引出了 Self-attention 自注意力机制。
输入整个语句的向量到self-attention中,输出对应个数的向量,再将其结果输入到全连接网络,最后输出标签。如此一来,FC考虑的就是全文的数据,而非窗口内的数据或部分数据
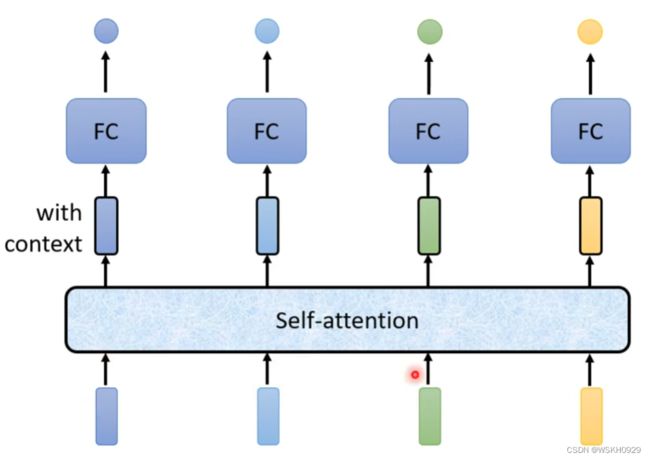
当然,以上过程可多次重复,如下图所示

Google 根据自注意力机制在《Attention is all you need》中提出了 Transformer 架构。
4.2 运行原理
如下图所示,所有输出 b i b^i bi 都是考虑了所有 a i a^i ai 的

如下图所示, α \alpha α表示 a 1 a^1 a1和 a 4 a^4 a4的关联程度,关联程度越大,在输出中占的权重越大
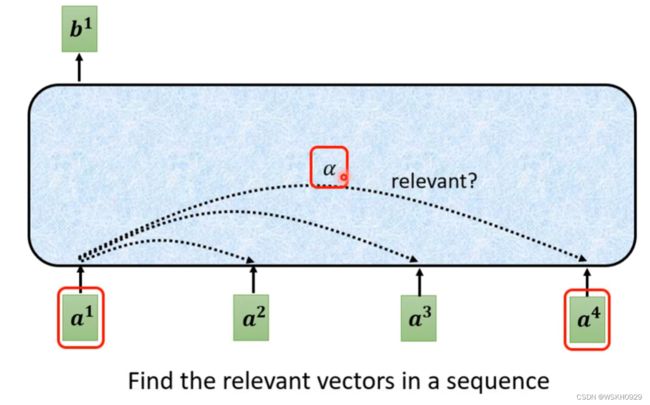
那么如何计算权重呢?
如下图所示,常用的有两种方法。(第一种最常用)
- 第一种方法(Dot-Product):将输入的 a i a^i ai 和 a j a^j aj 通过两个矩阵 W q W^q Wq 和 W k W^k Wk 相乘后得到两个向量 q q q 和 k k k,权重值即为 q q q 和 k k k 的点乘(内积)
- 第二种方法(Additive):计算 q q q 和 k k k 的步骤和第一种方法一样,只是后面是对 q q q 和 k k k 进行相加,然后传入 t a n h tanh tanh 函数后,与一个矩阵 W W W 相乘得到最后的权重值
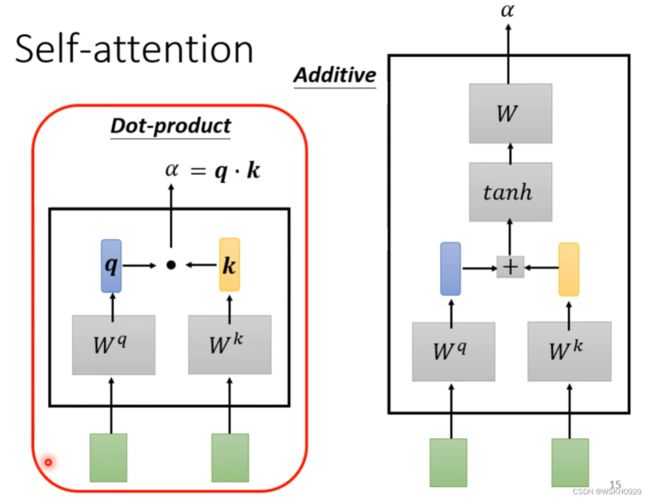
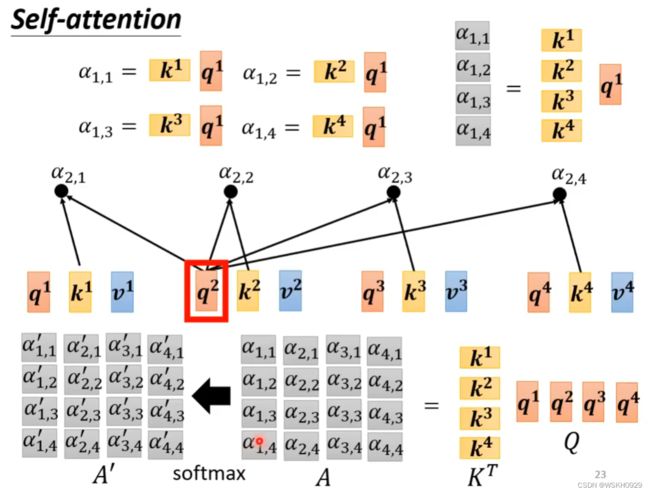
用上面的方法,可以让 a 1 a^1 a1 对包括自身的所有 a i a^i ai 求权重值,如下图所示:其中 α i , j \alpha_{i,j} αi,j 表示 a i a^i ai 和 a j a^j aj 的权重值
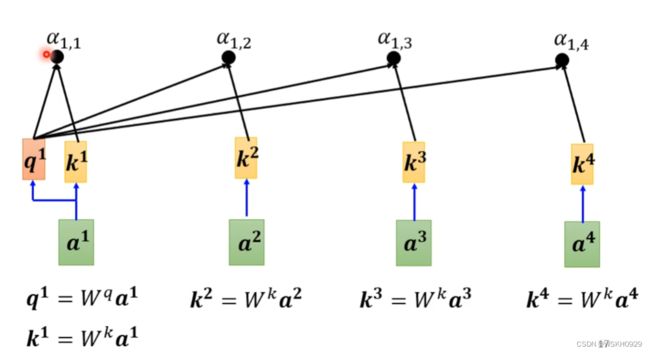
求出所有的 α i , j \alpha_{i,j} αi,j 后,就可以使用SoftMax函数对其进行归一化处理(SoftMax只是最常用,不是非用softmax不可,ReLu当然也可以),得到 α i , j ′ \alpha^{'}_{i,j} αi,j′
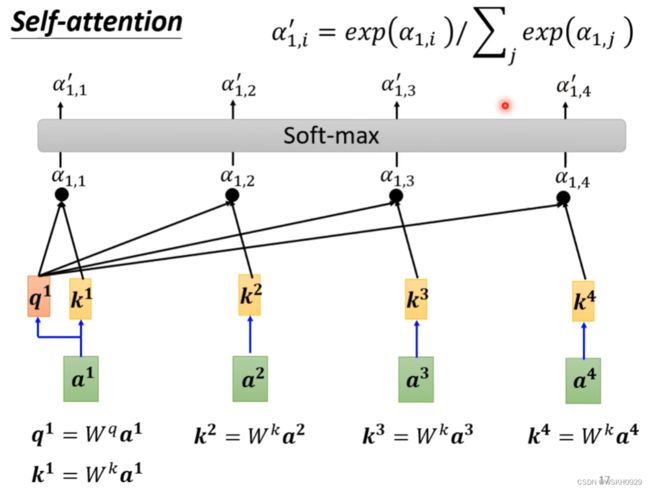
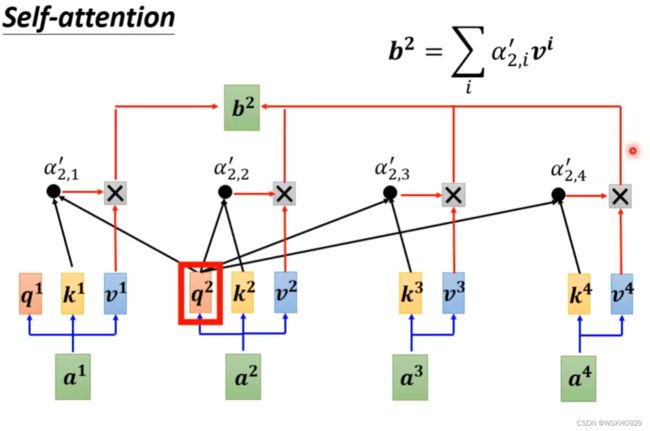
最后,使用 α i , j ′ \alpha^{'}_{i,j} αi,j′ 对每个 v i v^i vi 相乘后再累加,就得到了输出 b i b^i bi

下图展示了 b 2 b^2 b2 的计算过程
4.3 QKV
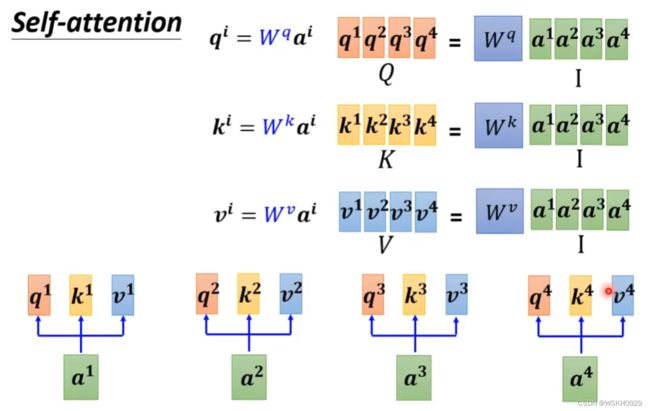

上述过程可总结为:
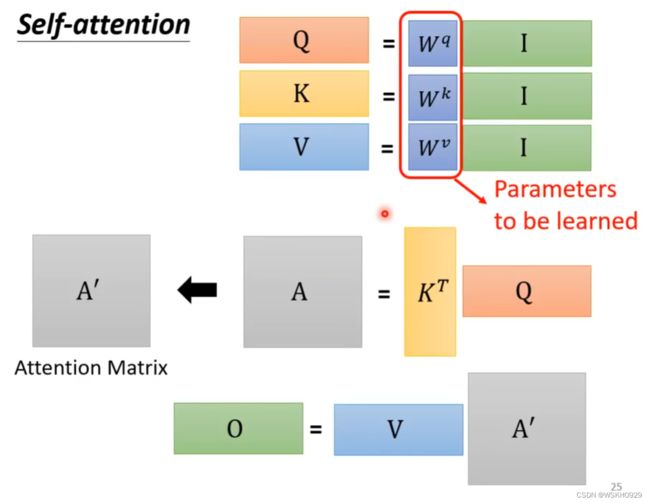
- 输入矩阵 I I I 分别乘以三个 W W W 得到三个矩阵 Q , K , V Q, K, V Q,K,V
- A = Q K T A=Q K^T A=QKT ,经过处理得到注意力矩阵 A ′ = softmax ( Q K T d k ) A^{\prime}=\operatorname{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) A′=softmax(dkQKT)
- 输出 O = A ′ V O=A^{\prime} V O=A′V
即:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V Attention(Q,K,V)=softmax(dkQKT)V
其中, d k \sqrt{d_k} dk 为向量的长度。
其中唯一要训练出的参数就是 W q , W k , W v W^q,W^k,W^v Wq,Wk,Wv
采用矩阵运算的方式可以大大提升计算效率
五、Multi-Head Self-Attention 多头注意力机制
5.1 运算原理

得到两个输出b后,又可以左乘一个可学习参数矩阵,将其变为一个数作为最后输出

5.2 Positional Encoding
对于Self-attention来说,并没有序列中字符位置的信息。例如动词是不太可能出现在句首的,因此可以降低动词在句首的可能性,但是自 注意力机制并没有该能力。因此需要加入 Positional Encoding 的技术来标注每个词汇在句子中的位置信息。
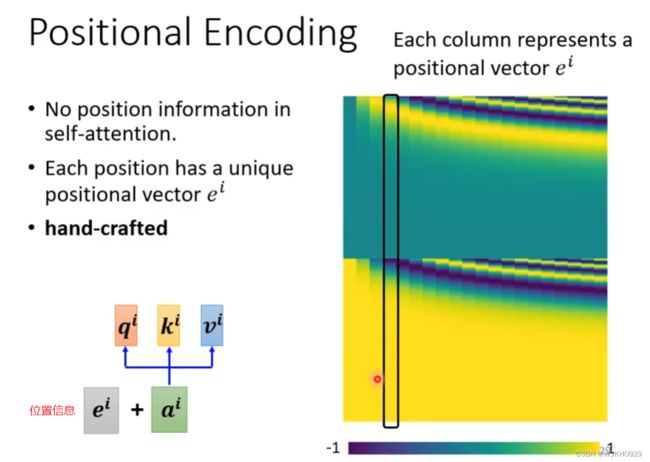
位置信息可以人为指定,也可以让机器自己学习出来。具体可参考下面的论文。
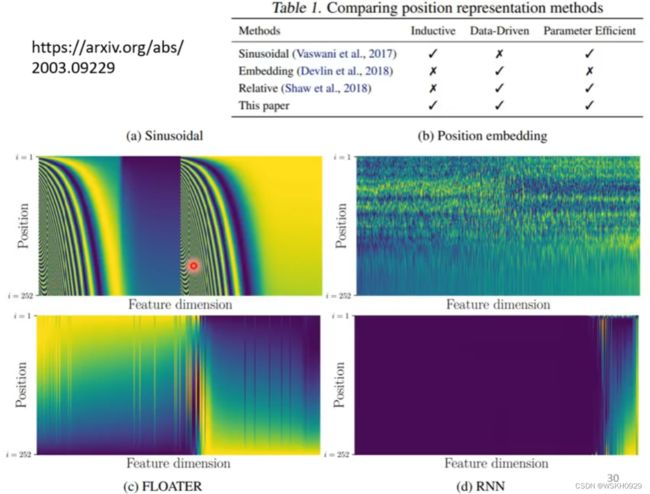
六、其他应用
6.1 语音识别

6.2 图像处理
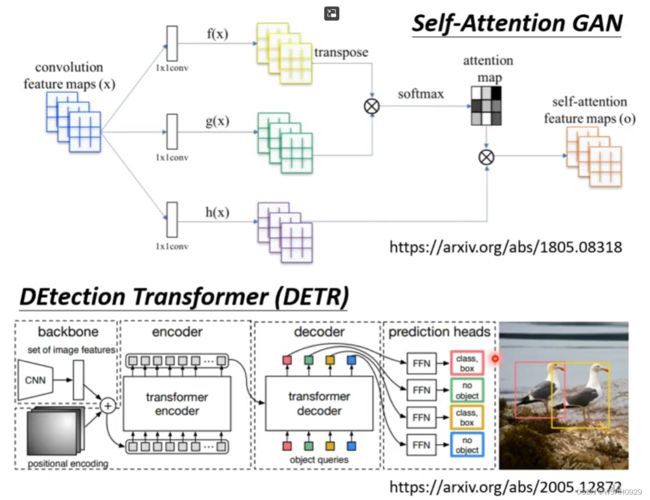
假设一张图片有三个通道,那么每一个位置的三个通道就相当于一个向量,整个图片就是一个向量组,所以可以使用Self-Attention机制

具体应用
6.3 CNN 与 Self-Attention的比较
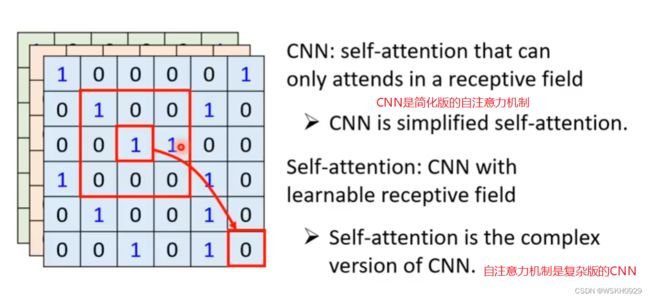
- CNN的做卷积时只考虑卷积核范围内的数据
- Self-Attention考虑全局的信息
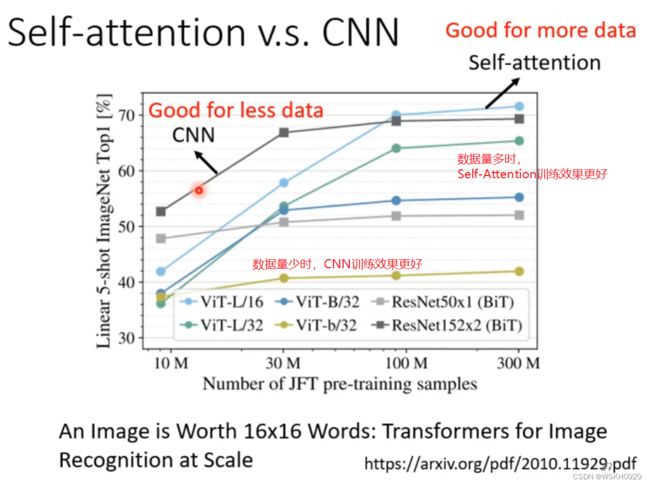
如果用不同的数据量来训练CNN和self-attention,会出现不同的结果。大的模型self-attention如果用于少量数据,容易出现过拟合;而小的模型CNN,在少量数据集上不容易出现过拟合。
6.4 RNN 与 Self-Attention 的比较
- 单向RNN只考虑了一个方向的信息
- Self-Attention(没有加位置信息时)没有考虑位置信息

6.5 Self-Attention 应用于 Graph

自注意力机制的缺点就是计算量非常大,因此如何优化其计算量是未来研究的重点。
七、Pytorch代码实现
7.1 Self-Attention
import math
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, input_dim, dim_q, dim_v):
super(SelfAttention, self).__init__()
# dim_q = dim_k
self.dim_q, self.dim_k, self.dim_v = dim_q, dim_q, dim_v
self.Q = nn.Linear(input_dim, dim_q)
self.K = nn.Linear(input_dim, dim_q)
self.V = nn.Linear(input_dim, dim_v)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
# Q: [batch_size,seq_len,dim_q]
# K: [batch_size,seq_len,dim_k]
# V: [batch_size,seq_len,dim_v]
Q, K, V = self.Q(x), self.K(x), self.V(x)
print(f'x.shape:{x.shape} , Q.shape:{Q.shape} , K.shape: {K.shape} , V.shape:{V.shape}')
attention = torch.bmm(self.softmax(torch.bmm(Q, K.permute(0, 2, 1)) / math.sqrt(self.dim_k)), V)
return attention
if __name__ == '__main__':
batch_size = 2 # 批量数
input_dim = 5 # 句子中每个单词的向量维度
seq_len = 3 # 句子长度
x = torch.randn(batch_size, seq_len, input_dim)
self_attention = SelfAttention(input_dim, batch_size, batch_size + input_dim)
print(x)
print('=' * 50)
attention = self_attention(x)
print('=' * 50)
print(attention)
输出:
tensor([[[-0.4491, 0.6722, 0.0739, 2.2373, -0.2280],
[-0.5156, -1.0378, 0.4090, -1.1535, -1.1051],
[-1.5552, -1.1806, 0.4696, -0.7460, -1.1878]],
[[-1.9606, 1.3585, -0.2554, -0.3004, -0.6509],
[ 0.2619, -1.5002, 0.2587, 1.0928, -0.2754],
[ 1.2719, 0.9347, -1.2178, 1.4022, -1.9317]]])
==================================================
x.shape:torch.Size([2, 3, 5]) , Q.shape:torch.Size([2, 3, 2]) , K.shape: torch.Size([2, 3, 2]) , V.shape:torch.Size([2, 3, 7])
==================================================
tensor([[[-0.2963, -0.2623, 0.7339, 0.9425, -0.4123, -0.9852, -0.1668],
[ 0.3173, -0.1366, 0.1946, 0.4260, -0.4735, -0.2990, -0.1717],
[ 0.3296, -0.1388, 0.1891, 0.4204, -0.4767, -0.2839, -0.1747]],
[[-0.3837, 0.2535, 0.6436, 0.3743, -0.6781, -1.2351, -0.3101],
[-0.4371, 0.2849, 0.6881, 0.3698, -0.7420, -1.2496, -0.2881],
[-0.4844, 0.3279, 0.7248, 0.3536, -0.7639, -1.3541, -0.3226]]],
grad_fn=<BmmBackward0>)
7.2 Multi-Head Self-Attention
import math
import torch
import torch.nn as nn
class MultiHeadSelfAttention(nn.Module):
def __init__(self, input_dim, dim_q, dim_v, n_head=1):
super(MultiHeadSelfAttention, self).__init__()
# dim_q = dim_k
self.dim_q, self.dim_k, self.dim_v, self.n_head = dim_q, dim_q, dim_v, n_head
if self.dim_k % n_head != 0:
raise RuntimeError(
f"请将batch_size = {dim_q} , 设置为n_head = {n_head}的整数倍,例如:{n_head * 1}、{n_head * 2}、{n_head * 3}...")
if self.dim_v % n_head != 0:
raise RuntimeError(
f"请将batch_size + input_dim = {dim_v} , 设置为n_head = {n_head}的整数倍,例如:{n_head * 1}、{n_head * 2}、{n_head * 3}...")
self.Q = nn.Linear(input_dim, dim_q)
self.K = nn.Linear(input_dim, dim_q)
self.V = nn.Linear(input_dim, dim_v)
self._norm_fact = 1 / math.sqrt(self.dim_k)
def forward(self, x):
# Q: [n_head,batch_size,seq_len,dim_q]
# K: [n_head,batch_size,seq_len,dim_k]
# V: [n_head,batch_size,seq_len,dim_v]
Q = self.Q(x).reshape(-1, x.shape[0], x.shape[1], self.dim_k // self.n_head)
K = self.K(x).reshape(-1, x.shape[0], x.shape[1], self.dim_k // self.n_head)
V = self.V(x).reshape(-1, x.shape[0], x.shape[1], self.dim_v // self.n_head)
print(f'x.shape:{x.shape} , Q.shape:{Q.shape} , K.shape: {K.shape} , V.shape:{V.shape}')
attention = nn.Softmax(dim=-1)(
torch.matmul(Q, K.permute(0, 1, 3, 2))) # Q * K.T() # batch_size * seq_len * seq_len
attention = torch.matmul(attention, V).reshape(x.shape[0], x.shape[1],
-1) # Q * K.T() * V # batch_size * seq_len * dim_v
return attention
if __name__ == '__main__':
n_head = 2 # 头的数量
batch_size = 4 # 批量数
input_dim = 4 # 句子中每个单词的向量维度
seq_len = 3 # 句子长度
x = torch.randn(batch_size, seq_len, input_dim)
self_attention = MultiHeadSelfAttention(input_dim, batch_size, batch_size + input_dim, n_head=n_head)
print(x)
print('=' * 50)
attention = self_attention(x)
print('=' * 50)
print(attention)
输出:
tensor([[[ 0.8641, -0.4545, -0.3437, -1.3505],
[-1.8631, -0.2410, -0.0692, -0.9518],
[ 0.3442, 1.2714, 1.5605, -1.0755]],
[[-1.1445, -0.9071, -0.2945, -0.9338],
[-0.2961, 0.2670, 0.6485, 0.1274],
[ 0.2757, -0.9526, -0.1947, 1.3630]],
[[-0.6654, 1.8043, 0.7771, -2.0179],
[ 1.9467, -1.1478, 0.2295, -0.5878],
[-1.1283, -0.2811, -1.0215, -0.2777]],
[[ 0.1165, 1.3968, -0.2745, -0.4792],
[ 0.9307, 0.7316, 1.1139, -0.5292],
[-1.1494, 0.4623, -1.3939, -3.0027]]])
==================================================
x.shape:torch.Size([4, 3, 4]) , Q.shape:torch.Size([2, 4, 3, 2]) , K.shape: torch.Size([2, 4, 3, 2]) , V.shape:torch.Size([2, 4, 3, 4])
==================================================
tensor([[[-0.5651, 0.0617, 0.4064, -0.1783, -0.4151, 0.0878, 0.3656,
-0.3224],
[-0.4750, 0.0582, 0.3371, -0.2406, 0.4841, -0.6677, 0.4175,
-0.9181],
[ 0.1175, -0.4277, 0.2538, -0.9493, 0.1103, -0.4356, 0.2730,
-0.9502]],
[[-0.4968, 0.0067, 0.3769, -0.0957, -0.4742, 0.0230, 0.3734,
-0.1573],
[-0.4715, 0.0260, 0.3754, -0.1679, 0.4554, -0.3518, 0.5341,
0.2777],
[ 0.4408, -0.3425, 0.5368, 0.2800, 0.4525, -0.3696, 0.5359,
0.2185]],
[[ 0.0776, -0.4077, -0.1044, -0.8529, 0.5349, -0.6025, -0.1392,
-0.9085],
[-0.3288, -0.2475, -0.0153, -0.9120, -0.1885, 0.1334, 0.6229,
-0.0158],
[-0.1659, 0.1249, 0.5162, -0.0164, -0.1794, 0.1261, 0.5748,
-0.0011]],
[[-0.1911, -0.0506, 0.0524, -0.5707, 0.0190, -0.1300, 0.0619,
-0.6097],
[-0.1689, -0.0501, 0.0528, -0.5536, -0.1215, -0.0887, 0.0580,
-0.7919],
[-0.2557, 0.1489, -0.2454, -1.0483, 0.7787, -0.7513, 0.8527,
-0.6087]]], grad_fn=<ViewBackward>)