2022吴恩达机器学习第2课week2
2022吴恩达机器学习课程学习笔记(第二课第二周)
- 1-1 TensorFlow 实现
- 1-2 模型训练细节
- 2-1 sigmoid 激活函数的替代方案
- 2-2 如何选择激活函数
-
- 如何为输出层选择激活函数
- 如何为隐藏层选择激活函数
- 2-3 为什么模型需要激活函数
- 3-1 多分类问题
- 3-2 Softmax
-
- softmax 回归公式
- softmax 回归代价函数
- 3-3 带有 softmax 输出层的神经网络
-
- 神经网络架构
- 神经网络实现
- 3-4 softmax 的改进实现
-
- 舍入误差
- 逻辑回归的改进实现
- softmax 回归的改进实现
- 3-5 多个输出的分类
- 4-1 高级优化方法
-
- Adam 算法介绍
- Adam 算法实现
- 4-2 其他的网络层类型
1-1 TensorFlow 实现
以手写数字识别为例,说明如何使用 TensorFlow 实现神经网络。
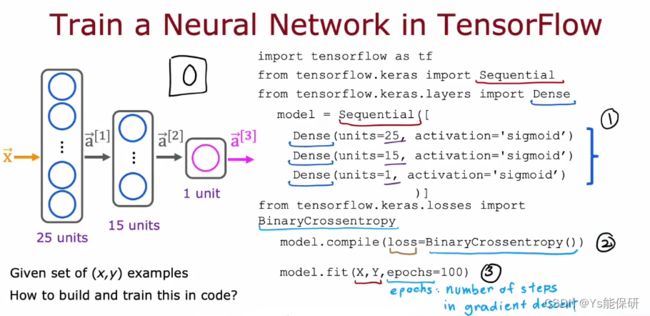
Sequential 函数用于将神经网络的三层顺序串在一起。
compile 函数用于编译模型,需指定损失函数。
fit 函数用于使模型拟合给定的数据集,需指定训练集使用几次(epoch)。
1-2 模型训练细节
模型训练步骤:
- 指定如何在给定输入特征 x 和参数 w 和 b 的情况下计算输出(定义模型)。
- 指定损失函数和代价函数。
- 使用算法特别是指梯度下降算法以最小化代价函数。

这段代码指定了神经网络的整个架构,其中,每一层的参数是随机初始化的。

这里使用的是和逻辑回归一样的损失函数,也叫二元交叉熵损失函数。
代价函数是神经网络中所有参数的函数,所以 W 和 B 都用大写表示。

如果使用梯度下降来更新参数,那么我们需要对每一层每一单元更新参数,关键就是计算偏导项,而 TensorFlow 是使用一种称为反向传播的算法来计算这些偏导项(在 fit 函数中已经实现)。
2-1 sigmoid 激活函数的替代方案
最常用的激活函数:
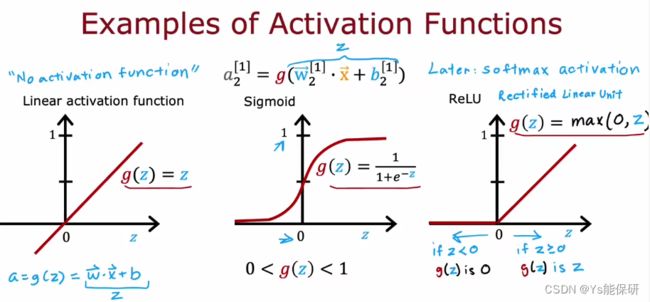
2-2 如何选择激活函数
如何为输出层选择激活函数
为输出层选择激活函数时,取决于预测的标签 y 是什么。
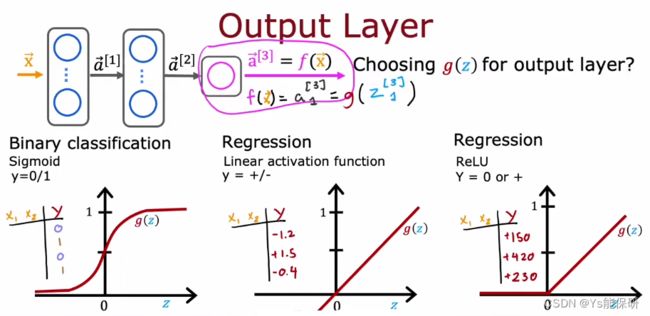
对于二分类问题,选择 sigmoid 激活函数。
对于 y 可以取正值和负值的回归问题,选择线性激活函数。
如果 y只能取非负值的回归问题,选择 ReLu 激活函数。
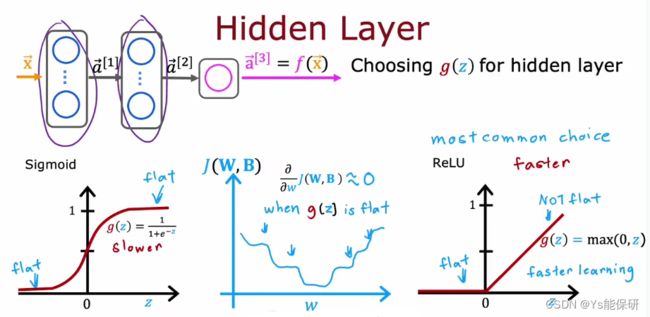
如何为隐藏层选择激活函数
事实证明,ReLU 激活函数是迄今为止神经网络中最常见的选择。
为何使用 ReLU 替代 Sigmoid 呢?
首先,ReLU 的计算速度更快一些;
第二,ReLU 函数仅在图像中的一部分变平,而 sigmoid 函数它在两个地方变平,如果我们使用梯度下降来训练神经网络,当函数有很多平坦的地方时,梯度下降很慢。
虽然梯度下降优化代价函数 J,而不是激活函数,但激活函数是计算的一部分,如果使用 sigmiod,导致在代价函数中的很多地方也是平坦的,梯度很小,减慢了学习的速度。
2-3 为什么模型需要激活函数
如果所有的激活函数都是用线性激活函数,那么神经网络将变得与线性回归模型没什么不同。
简单举个例子证明一下:

也就是说,线性函数的线性函数仍然是线性函数。
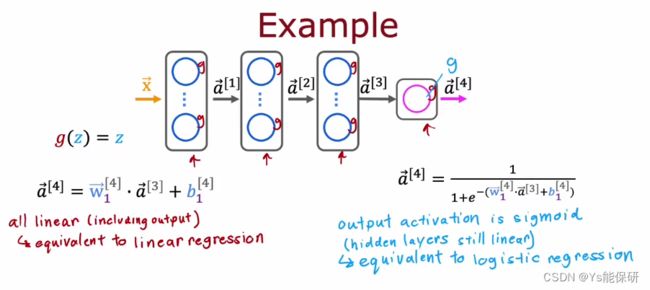
隐藏层都使用线性激活函数,输出层如果是线性激活函数,那么神经网络等同于线性回归模型;输出层如果是 sigmoid 激活函数,那么神经网络等同于逻辑回归模型。
综上,隐藏层不要使用线性激活函数。
3-1 多分类问题
多分类问题:有两个以上可能的输出标签的分类问题。
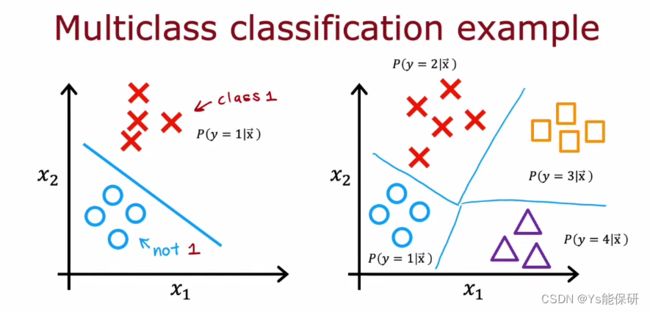
3-2 Softmax
softmax 回归公式

当 n = 2 时,softmax 回归会简化为逻辑回归。
softmax 回归代价函数
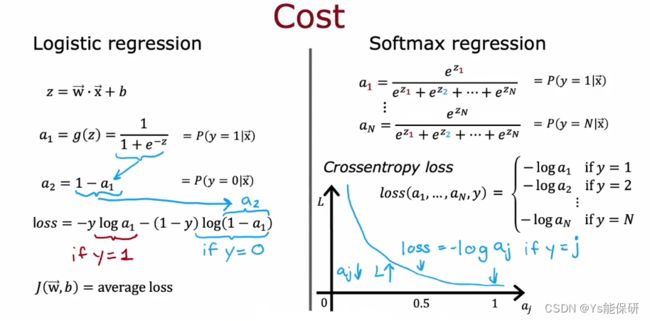
当 y = j 时,aj(模型预测 y-hat = j 的概率)越接近 1,损失越小。
3-3 带有 softmax 输出层的神经网络
神经网络架构
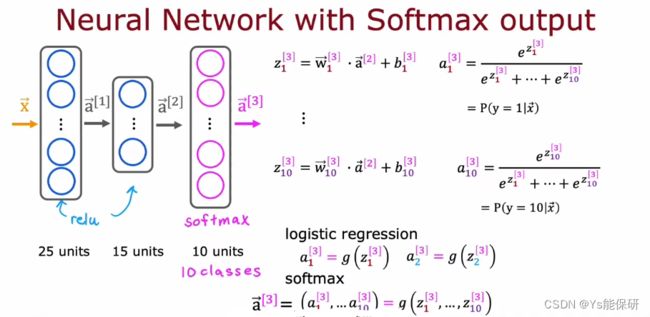
softmax 激活函数与其他激活函数不同的是:
其他激活函数中,aj 只是 zj 的函数;而在 softmax 激活函数中,aj 是 z1 到 zn 的函数。
神经网络实现

这里使用的损失函数是 SparseCategoricalCrossentropy。
categorical 是指我们这是个分类问题(比如手写数字分类问题)。
sparse 是指只能取有限类别中的一种(比如数字只能是 4 或 7,而不可能是 4 和 7)。
上述版本是可工作的,但不是最好的,所以不要使用这个版本!
3-4 softmax 的改进实现
舍入误差
举例说明数值舍入误差:
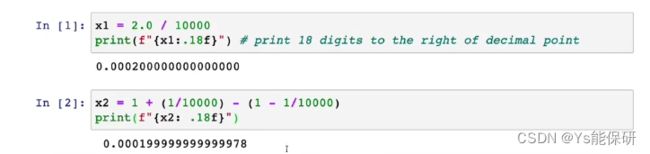
因为计算机只有有限的内存来存储每个数字,在这里称为浮点数,当我们使用不同方式计算 2.0 / 10000 时,结果会有较多较少的舍入误差。
减少数值舍入误差,使其在 TensorFlow 中进行更精确的计算
逻辑回归的改进实现

当我们不计算 a 作为中间项时,而是使用展开的表达式,那么 TensorFlow 可以重新排列这个表达式中的项,并想出一种在数值上更准确的方法来计算这个损失函数。
改进代码的作用是:将输出层的激活函数改成线性激活函数,然后相当于是使用了展开的损失函数,将 z 直接代入损失函数,TensorFlow 可以重新排列这个表达式中的项,使计算变得更准确。
这段代码也有缺点:代码变得不清晰,难以阅读。
对于逻辑回归模型来说,改进前后都可以正常工作,但对于 softmax 回归来说,舍入误差较大,需要使用改进后的版本。
softmax 回归的改进实现

一个值得注意的细节:神经网络输出的不再是概率 a1…a10,而是z1…z10。
所以在预测的时候要改一下:

3-5 多个输出的分类
多分类问题:有两个以上可能的输出标签的分类问题,比如手写数字识别,预测结果是一个类别。
多标签分类问题:每个输入关联了多个标签,比如下图所示,预测结果是一个向量。
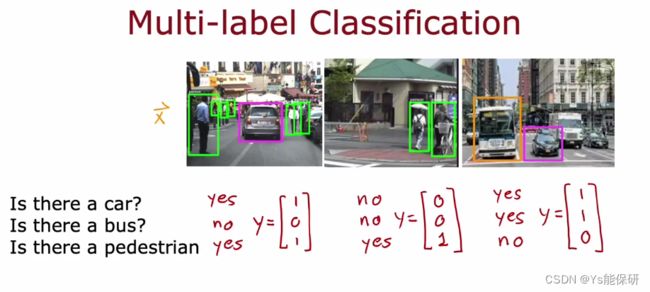
如何使用神经网络解决多标签分类问题?
可以将其视为三个独立的问题,但是不太合理。
也可以训练一个网络同时检测三种物体。
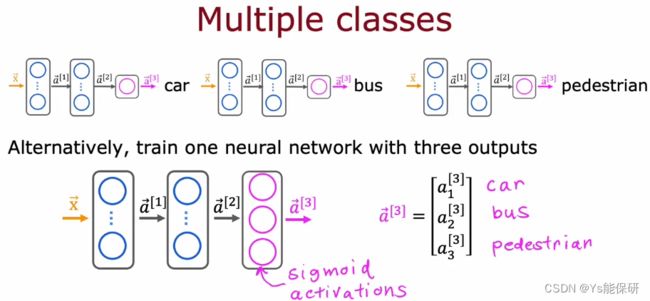
输出层每个单元都使用 sigmoid 激活函数,分别对应是否有小汽车,是否有公共汽车,是否有行人三个二分类问题。
4-1 高级优化方法
Adam 算法介绍
有一种称为 Adam 的算法可以做到自己调整学习率,如果它发现学习率太小(只是朝着相似的方向迈出微小的步伐),则它会让学习率增大;如果它发现学习率太小(来回震荡着迈步),则它会让学习率减小。
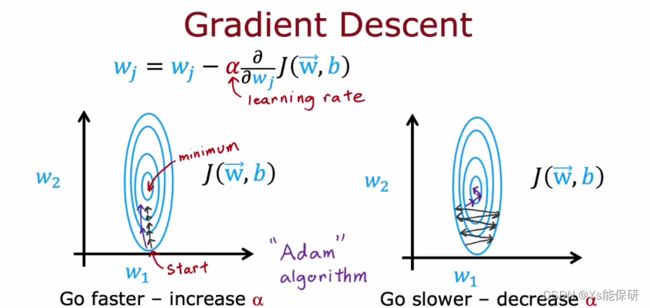
Adam 对每个参数都使用了不同的学习率。
Adam 算法实现

使用 Adam 算法时需要指定初始学习率。
4-2 其他的网络层类型
我们之前使用的的神经网络层,都是密集层类型的,以为他们采取上一层的所有激活值作为自己的输入,这可以构建很强大的学习算法,还有一些其它类型的神经网络层。
全连接层:每个神经元都会以前一层的所有激活作为自己的输入。
卷积层:每个神经元只以前一层的部分激活作为自己的输入。
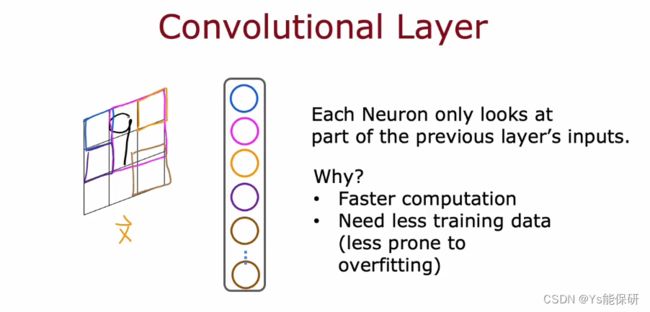
为什么不让神经元看到前一层的所有像素,而只看一部分像素?
首先,加快计算速度。
其次,需要更少的训练数据或者不太容易出现过拟合。
举例说明卷积神经网络是如何工作的——通过心电图查看病人是否患有心脏病。
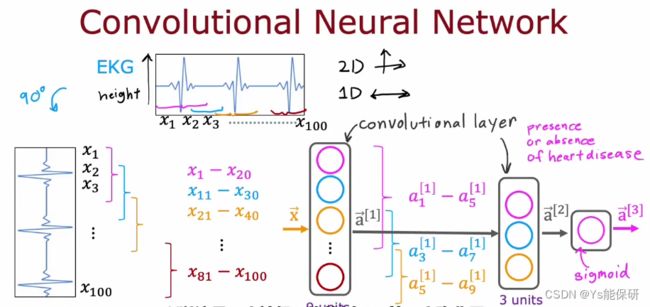
第一个卷积层每一个神经元查看 20 个输入,第二个卷积层每一个神经元查看 5 个输入,第三层是 sigmoid 层。
事实证明,对于卷积层,我们有很多种架构,比如单个神经元应该查看到输入窗口有多大,以及每层应该有多少个神经元。
通过有效地选择这些架构参数,我们可以构建比使用全连接层更有效的新版本神经网络。