一次基于TensorFlow手写数字识别模型的训练
环境:
- tensorflow-estimator==2.7.0
- Python 3.9.7
- jupyter notebook
- mnist数据集
import numpy as np
import pandas as pd
from keras.utils import np_utils
from keras.datasets import mnist
(train_image,train_label), (test_image,test_label) = mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
11493376/11490434 [==============================] - 2s 0us/step
11501568/11490434 [==============================] - 2s 0us/step
进行数据的预处理
#主意当前CNN和MLP对数据的第一步预处理差别,因CNN要进行卷积运算,需保持数组样式,不能同MLP一样转成一维784个元素
train_image_4D = train_image.reshape(60000, 28, 28, 1).astype(float)
test_image_4D = test_image.reshape(10000, 28, 28, 1).astype(float)
#标准化处理
train_image_4D_normalize = train_image_4D / 255
test_image_4D_normalize = test_image_4D / 255
#使用一位有效编码来处理标签
train_label_onehotencoding = np_utils.to_categorical(train_label)
test_label_onehotencoding = np_utils.to_categorical(test_label)
建立CNN卷积神经网络
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Conv2D, MaxPooling2D, Flatten #卷积层,池化层,平坦层
model = Sequential()
添加卷积层1
# filters:滤镜个数 kernel_size:滤镜尺寸
# padding='same'表示不改变图片大小 input_shape:输入图片的尺寸 activation激活函数
model.add(Conv2D(filters=16, kernel_size=(5,5), padding='same', input_shape=(28,28,1), activation='relu'))
添加池化层1
model.add(MaxPooling2D(pool_size = (2,2))) #将28*28的图片缩减一半变为14*14
添加卷积层2
# filters:滤镜个数 kernel_size:滤镜尺寸
# padding='same'表示不改变图片大小 input_shape:输入图片的尺寸 activation激活函数
model.add(Conv2D(filters=36, kernel_size=(5,5), padding='same', activation='relu'))
添加池化层2
model.add(MaxPooling2D(pool_size = (2,2)))
model.add(Dropout(0.25)) #避免过度拟合
添加平坦层
model.add(Flatten())
添加隐藏层
model.add(Dense(units=128, kernel_initializer='normal', activation='relu'))
model.add(Dropout(0.5)) #避免过度拟合
建立隐藏层和输出层之间的关系
model.add(Dense(units=10,kernel_initializer='normal', activation='softmax'))
print(model.summary())
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 16) 416
max_pooling2d (MaxPooling2D (None, 14, 14, 16) 0
)
conv2d_1 (Conv2D) (None, 14, 14, 36) 14436
max_pooling2d_1 (MaxPooling (None, 7, 7, 36) 0
2D)
dropout (Dropout) (None, 7, 7, 36) 0
flatten (Flatten) (None, 1764) 0
dense_1 (Dense) (None, 128) 225920
dropout_1 (Dropout) (None, 128) 0
dense_2 (Dense) (None, 10) 1290
=================================================================
Total params: 242,062
Trainable params: 242,062
Non-trainable params: 0
_________________________________________________________________
None
#配置下训练模型 loss:损失函数 optimizer:优化器,通过优化让训练的结果能够更快的收敛
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
#train_image_4D_normalize :训练数据 train_label_onehotencoding: 训练标签
#validation_split:取出一定比例的数据用于验证 epoch:训练次数 batch_size: 每次训练取出多少数据用于训练
#verbose: 2表示是示训练过程
train_history = model.fit(train_image_4D_normalize, train_label_onehotencoding, validation_split=0.2, epochs=10, batch_size=200, verbose=2)
Epoch 1/10
240/240 - 19s - loss: 0.5127 - accuracy: 0.8396 - val_loss: 0.1068 - val_accuracy: 0.9671 - 19s/epoch - 80ms/step
Epoch 2/10
240/240 - 19s - loss: 0.1492 - accuracy: 0.9556 - val_loss: 0.0668 - val_accuracy: 0.9793 - 19s/epoch - 78ms/step
Epoch 3/10
240/240 - 19s - loss: 0.1062 - accuracy: 0.9682 - val_loss: 0.0577 - val_accuracy: 0.9831 - 19s/epoch - 78ms/step
Epoch 4/10
240/240 - 19s - loss: 0.0875 - accuracy: 0.9739 - val_loss: 0.0491 - val_accuracy: 0.9839 - 19s/epoch - 78ms/step
Epoch 5/10
240/240 - 21s - loss: 0.0747 - accuracy: 0.9772 - val_loss: 0.0432 - val_accuracy: 0.9867 - 21s/epoch - 89ms/step
Epoch 6/10
240/240 - 20s - loss: 0.0642 - accuracy: 0.9803 - val_loss: 0.0441 - val_accuracy: 0.9881 - 20s/epoch - 83ms/step
Epoch 7/10
240/240 - 20s - loss: 0.0583 - accuracy: 0.9822 - val_loss: 0.0375 - val_accuracy: 0.9903 - 20s/epoch - 82ms/step
Epoch 8/10
240/240 - 20s - loss: 0.0521 - accuracy: 0.9843 - val_loss: 0.0366 - val_accuracy: 0.9896 - 20s/epoch - 84ms/step
Epoch 9/10
240/240 - 19s - loss: 0.0475 - accuracy: 0.9855 - val_loss: 0.0342 - val_accuracy: 0.9905 - 19s/epoch - 78ms/step
Epoch 10/10
240/240 - 19s - loss: 0.0429 - accuracy: 0.9868 - val_loss: 0.0364 - val_accuracy: 0.9902 - 19s/epoch - 77ms/step
import matplotlib.pyplot as plt
def show_train_history(history, train, validation):
plt.plot (history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.xlabel('Epoch')
plt.ylabel(train)
plt.legend(['train', 'validation'], loc = 'upper left')
plt.show()
show_train_history(train_history, 'accuracy', 'val_accuracy')
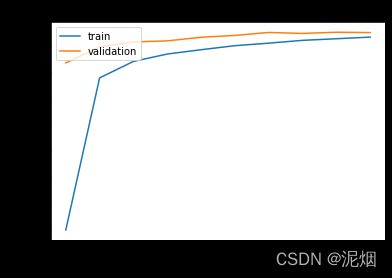
show_train_history(train_history, 'loss', 'val_loss') #损失函数

利用10000项测试数据评估下模型的准确率
scores = model.evaluate(test_image_4D_normalize, test_label_onehotencoding)
print(scores)
313/313 [==============================] - 1s 4ms/step - loss: 0.0260 - accuracy: 0.9911: 0s
[0.02601146325469017, 0.991100013256073]
可以看出,卷积神经网络CNN比多层感知器模型MLP要优秀,不但准确率提升明显,而且过度拟合的问题也被有效抑制了
导出训练模型
model.save('CNN_MNIST_MODEL.h5')
测试所导出的模型
from PIL import Image
import numpy as np
from keras.models import load_model
my_model = load_model('CNN_MNIST_MODEL.h5')
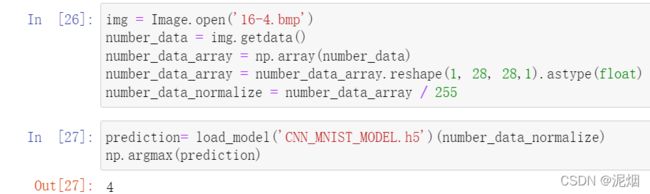
img = Image.open('16-4.bmp')
number_data = img.getdata()
number_data_array = np.array(number_data)
number_data_array = number_data_array.reshape(1, 28, 28,1).astype(float)
number_data_normalize = number_data_array / 255
prediction= load_model('CNN_MNIST_MODEL.h5')(number_data_normalize)
np.argmax(prediction)
4
![]()
![]()

![]()

不足:
- CPU占用太满,GPU利用率极低
- 对于图片格式,大小较为吝啬,有待改进