统计 | 时间序列学习笔记
统计 | 时间序列学习笔记
- 一、复习
-
- 1、损失函数与最优一步预测
- 2、平方损失函数
- 3、平稳性的定义
- 3、遍历性
- 4、经济模型
-
- CAPM
- HM
- Market Model
- 有效市场假说
- 二、ARMA
-
- 1、基本概念
- 2、AR模型
- 3、MA模型
- 3、ARMA模型
(所有ppt截图,以及部分代码,来自中财黄白老师的ppt)
一、复习
Lecture 1、2
1、损失函数与最优一步预测
- 一个随机过程: Z t ≡ ( Y t , X t ′ ) ′ Z_{t} \equiv\left(Y_{t}, X_{t}^{\prime}\right)^{\prime} Zt≡(Yt,Xt′)′, X t X_{t} Xt是一个向量, Y t Y_{t} Yt是我们感兴趣的变量
- 我们可以利用T期观测: { Z 1 , … , Z t } \left\{Z_{1}, \ldots, Z_{t}\right\} {Z1,…,Zt},来估计模型参数 β ^ t \hat{\beta}_{t} β^t
- 由此得到一步预测: f ( Z t , β ^ t ) f\left(Z_{t}, \hat{\beta}_{t}\right) f(Zt,β^t)令 f t , 1 ≡ f ( Z t , β ^ t ) f_{t, 1} \equiv f\left(Z_{t}, \hat{\beta}_{t}\right) ft,1≡f(Zt,β^t),用 f t , 1 f_{t, 1} ft,1来估计 Y t + 1 Y_{t+1} Yt+1
- 一步预测误差: e t + 1 ≡ Y t + 1 − f t , 1 e_{t+1} \equiv Y_{t+1}-f_{t, 1} et+1≡Yt+1−ft,1
- 一步预测误差的损失函数: c ( e t + 1 ) c\left(e_{t+1}\right) c(et+1),最优预测 f t , 1 ∗ f_{t, 1}^{*} ft,1∗使得损失函数能够达到最小: f t , 1 ∗ = a r g min f t , 1 ∫ − ∞ ∞ c ( y − f t , 1 ) d F t ( y ) f_{t, 1}^{*}=arg\min _{f_{t, 1}} \int_{-\infty}^{\infty} c\left(y-f_{t, 1}\right) d F_{t}(y) ft,1∗=argft,1min∫−∞∞c(y−ft,1)dFt(y)
则最优预测误差: e t + 1 ∗ = Y t + 1 − f t , 1 ∗ e_{t+1}^{*}=Y_{t+1}-f_{t, 1}^{*} et+1∗=Yt+1−ft,1∗ - 求 f t , 1 ∗ f_{t, 1}^{*} ft,1∗的过程:
令偏导数等于0, ∂ ∂ f t , 1 ∫ − ∞ ∞ c ( y − f t , 1 ∗ ) d F t ( y ) = 0 \frac{\partial}{\partial f_{t, 1}} \int_{-\infty}^{\infty} c\left(y-f_{t, 1}^{*}\right) d F_{t}(y)=0 ∂ft,1∂∫−∞∞c(y−ft,1∗)dFt(y)=0 当积分和求导符号互换时, ∫ − ∞ ∞ ∂ ∂ f t , 1 c ( y − f t , 1 ∗ ) d F t ( y ) ≡ E ( ∂ ∂ f t , 1 c ( Y t + 1 − f t , 1 ∗ ) ∣ I t ) ≡ E ( g t + 1 ∣ I t ) = 0 \begin{aligned} &\int_{-\infty}^{\infty} \frac{\partial}{\partial f_{t, 1}} c\left(y-f_{t, 1}^{*}\right) d F_{t}(y) \equiv E\left(\frac{\partial}{\partial f_{t, 1}} c\left(Y_{t+1}-f_{t, 1}^{*}\right) | I_{t}\right)\\ &\equiv E\left(g_{t+1} | I_{t}\right)=0 \end{aligned} ∫−∞∞∂ft,1∂c(y−ft,1∗)dFt(y)≡E(∂ft,1∂c(Yt+1−ft,1∗)∣It)≡E(gt+1∣It)=0 其中, I t = { Z 1 , … , Z t } I_{t}=\left\{Z_{1}, \ldots, Z_{t}\right\} It={Z1,…,Zt}, g t + 1 ≡ ∂ ∂ f t , 1 c ( Y t + 1 − f t , 1 ∗ ) g_{t+1} \equiv \frac{\partial}{\partial f_{t, 1}} c\left(Y_{t+1}-f_{t, 1}^{*}\right) gt+1≡∂ft,1∂c(Yt+1−ft,1∗)
2、平方损失函数
- 平方损失函数: c ( Y t + 1 − f t , 1 ) ≡ ( Y t + 1 − f t , 1 ) 2 c\left(Y_{t+1}-f_{t, 1}\right) \equiv\left(Y_{t+1}-f_{t, 1}\right)^{2} c(Yt+1−ft,1)≡(Yt+1−ft,1)2. 所以 g t + 1 ≡ ∂ ∂ f t , 1 c ( Y t + 1 − f t , 1 ∗ ) = − 2 e t + 1 ∗ g_{t+1} \equiv \frac{\partial}{\partial f_{t, 1}} c\left(Y_{t+1}-f_{t, 1}^{*}\right)=-2 e_{t+1}^{*} gt+1≡∂ft,1∂c(Yt+1−ft,1∗)=−2et+1∗,那么 E ( e t + 1 ∗ ∣ I t ) = 0 E\left(e_{t+1}^{*} | I_{t}\right)=0 E(et+1∗∣It)=0所以, E ( Y t + 1 − f t , 1 ∗ ∣ I t ) = 0 E\left(Y_{t+1}-f_{t, 1}^{*} | I_{t}\right)=0 E(Yt+1−ft,1∗∣It)=0,即 f t , 1 ∗ = E ( Y t + 1 ∣ I t ) f_{t, 1}^{*}=E\left(Y_{t+1} | I_{t}\right) ft,1∗=E(Yt+1∣It)
另外,在check loss下, f t , 1 ∗ = q α ( Y t + 1 ∣ I t ) f_{t, 1}^{*}=q_{\alpha}\left(Y_{t+1} | I_{t}\right) ft,1∗=qα(Yt+1∣It)
3、平稳性的定义
- 严平稳(Strictly stationarity): { X t } \{X_t\} {Xt}为一时间序列, 对 于 任 意 的 m , 对于任意的m, 对于任意的m,\tau , 有 ,有 ,有 F t 1 , t 2 , , . . . , t m ( x 1 , x 2 , . . . , x m ) = F t 1 + τ , t 2 + τ , . . . , t m + τ ( x 1 , x 2 , . . . , x m ) F_{t_1,t_2,,...,tm}(x_1,x_2,...,x_m)=F_{t_1+\tau,t_2+\tau,...,t_m+\tau}(x_1,x_2,...,x_m) Ft1,t2,,...,tm(x1,x2,...,xm)=Ft1+τ,t2+τ,...,tm+τ(x1,x2,...,xm)$联合概率分布相等
- 宽平稳(Covariance stationarity):若时间序列满足 { X t } \{X_t\} {Xt}以下条件,
(1)一阶原点矩存在, E X t = μ EX_t=\mu EXt=μ, μ \mu μ为常数
(2)二阶原点矩存在, E X t 2 < ∞ EX_t^2<\infty EXt2<∞
(3)协方差至于时间间隔有关, γ ( t , s ) = γ ( k , k + s − t ) \gamma(t,s)=\gamma(k,k+s-t) γ(t,s)=γ(k,k+s−t)
则该时间序列是宽平稳的。又称弱平稳或二阶平稳(second-order stationary、wide-sense stationarity、weak stationarity)。
对于一个时间序列 { X t } \{X_t\} {Xt}
(1)均值 μ t \mu_t μt
(2)协方差 γ ( t , s ) = c o v ( X t , X s ) = E ( X t − μ t ) ( X s − μ s ) \gamma(t,s)=cov(X_t,X_s)=\mathbb{E}\left(X_{t}-\mu_{t}\right)\left(X_{s}-\mu_{s}\right) γ(t,s)=cov(Xt,Xs)=E(Xt−μt)(Xs−μs)
注:严平稳和宽平稳不能互相推断
虽然严平稳比宽平稳的条件更严格,但二者不能互相推断。
- 严平稳的时间序列不一定是宽平稳的。如:服从柯西分布的严平稳序列,不存在一阶、二阶矩,所以不是宽平稳的。只有二阶矩存在的严平稳序列才是宽平稳的。
- 宽平稳的时间序列也不一定是严平稳的。只有时间序列 { X t } \{X_t\} {Xt}是正态时间序列时,宽平稳才能推出严平稳。
正态时间序列
一个随机时间序列 { X t } \{X_t\} {Xt},若对于任意时间 ( t 1 , . . . , t n ) (t_1,...,t_n) (t1,...,tn), ( x t 1 , . . . , x t n ) (x_{t_1},...,x_{t_n}) (xt1,...,xtn)满足联合正态分布,那么这个时间序列是正态时间序列。
3、遍历性
时间序列可以被研究,需要具有一些性质:遍历性和平稳性
- Ensemble average:
随机过程 { X ( ω i , t ) , t = 1 , … , n } \left\{X\left(\omega_{i}, t\right), t=1, \ldots, n\right\} {X(ωi,t),t=1,…,n}的某一个样本路径 { x 1 ( i ) , x 2 ( i ) , … x n ( i ) } \left\{x_{1}^{(i)}, x_{2}^{(i)}, \ldots x_{n}^{(i)}\right\} {x1(i),x2(i),…xn(i)},即 x t ( i ) = X ( ω i , t ) x_{t}^{(i)}=X\left(\omega_{i}, t\right) xt(i)=X(ωi,t)。均值 μ = E ( X t ) \mu=E(X_t) μ=E(Xt)可以被ensemble averages μ ^ t = k − 1 ∑ i = 1 k X t ( i ) , t = 1 , … , n \hat{\mu}_{t}=k^{-1} \sum_{i=1}^{k} X_{t}^{(i)}, t=1, \dots, n μ^t=k−1∑i=1kXt(i),t=1,…,n所估计
事实上,i只有一个。
人不能同时踏进两条河流。
- time average:实际上,我们只有 { x 1 ( 1 ) , x 2 ( 1 ) , … x n ( 1 ) } \left\{x_{1}^{(1)}, x_{2}^{(1)}, \ldots x_{n}^{(1)}\right\} {x1(1),x2(1),…xn(1)}对于 ω 1 \omega_1 ω1。因为时间序列的平稳性有: μ t = E ( X t ) = μ \mu_t=\mathbb{E}(X_t)=\mu μt=E(Xt)=μ,我们用time average x ˉ n = n − 1 ∑ t = 1 n x t ( 1 ) \bar{x}_{n}=n^{-1} \sum_{t=1}^{n} x_{t}^{(1)} xˉn=n−1∑t=1nxt(1)来估计 μ \mu μ
- 均值的遍历性(ergodicity):如果time average收敛于常数均值, x ˉ n → p μ \bar{x}_{n} \rightarrow^{p} \mu xˉn→pμ,那么我们称该时间序列式均值遍历的。
4、经济模型
CAPM
- 资本资产定价模型(Capital Asset Pricing Model) E ( R p − r f ) = β E ( R m − r f ) \mathbb{E}\left(R_{p}-r_{f}\right)=\beta \mathbb{E}\left(R_{m}-r_{f}\right) E(Rp−rf)=βE(Rm−rf)也可以被写成
E ( R p ) = r f + β ( E ( R m ) − r f ) \mathbb{E}\left(R_{p}\right)=r_{f}+\beta\left(\mathbb{E}\left(R_{m}\right)-r_{f}\right) E(Rp)=rf+β(E(Rm)−rf)其中, R p R_p Rp是投资组合的收益率, r f r_f rf是无风险利率, β \beta β是风险系数, R m R_m Rm是市场收益率, E ( R m ) − r f \mathbb{E}_(R_m)-r_f E(Rm)−rf表示风险溢价。
根据最小二乘法,可以得到: β = cov ( R p − r f , R m − r f ) var ( R m − r f ) = σ X Y σ X 2 \beta=\frac{\operatorname{cov}\left(R_{p}-r_{f}, R_{m}-r_{f}\right)}{\operatorname{var}\left(R_{m}-r_{f}\right)}=\frac{\sigma_{X Y}}{\sigma_{X}^{2}} β=var(Rm−rf)cov(Rp−rf,Rm−rf)=σX2σXY
β \beta β与相关系数 ρ = σ X Y σ X σ Y = β σ X σ Y \rho=\frac{\sigma_{X Y}}{\sigma_{X} \sigma_{Y}}=\beta \frac{\sigma_{X}}{\sigma_{Y}} ρ=σXσYσXY=βσYσX有关。 - 意义:
1.任何风险性资产的预期报酬率=无风险利率+资产风险溢酬。
2.资产风险溢酬=风险的价格×风险的数量
3.风险的数量 = β
4.风险的价格 = E ( R m ) − r f E(R_m) − r_f E(Rm)−rf
HM
- 无条件均值模型: E ( R i t ) = μ i \mathbb{E}\left(R_{i t}\right)=\mu_{i} E(Rit)=μi,有时也被称为 HM模型(Historical Mean Model)。对于某一资产i,我们有: R i t = E ( R i t ) + ξ i t = μ i + ξ i t R_{i t}=\mathbb{E}\left(R_{i t}\right)+\xi_{i t}=\mu_{i}+\xi_{i t} Rit=E(Rit)+ξit=μi+ξit E ( ξ i t ) = 0 , Var ( ξ i t ) = σ ξ i 2 \mathbb{E}\left(\xi_{i t}\right)=0, \quad \operatorname{Var}\left(\xi_{i t}\right)=\sigma_{\xi_{i}}^{2} E(ξit)=0,Var(ξit)=σξi2其中, ξ i t \xi_{i t} ξit被称作不正常回报, R i t R_{it} Rit被称为名义收益或额外收益,回归的决定系数 R 2 = 0 R^2=0 R2=0
Market Model
- 条件均值模型: E ( R i t ∣ R m t ) = α i + β i R m t \mathbb{E}\left(R_{i t} | R_{m t}\right)=\alpha_{i}+\beta_{i} R_{m t} E(Rit∣Rmt)=αi+βiRmt。对于某项资产i来讲, R i t = E ( R i t ∣ R m t ) + ε i t = α i + β i R m t + ε i t R_{i t}=\mathbb{E}\left(R_{i t} | R_{m t}\right)+\varepsilon_{i t}=\alpha_{i}+\beta_{i} R_{m t}+\varepsilon_{i t} Rit=E(Rit∣Rmt)+εit=αi+βiRmt+εit E ( ε i t ) = 0 , Var ( ε i t ) = σ ε i 2 \mathbb{E}\left(\varepsilon_{i t}\right)=0, \quad \operatorname{Var}\left(\varepsilon_{i t}\right)=\sigma_{\varepsilon_{i}}^{2} E(εit)=0,Var(εit)=σεi2回归的决定系数为 R 2 = 1 − σ ε i 2 σ ξ i 2 R^{2}=1-\frac{\sigma_{\varepsilon_{i}}^{2}}{\sigma_{\xi_{i}}^{2}} R2=1−σξi2σεi2,所以 σ ε i 2 = ( 1 − R 2 ) σ ξ i 2 ≤ σ ξ i 2 \sigma_{\varepsilon_{i}}^{2}=\left(1-R^{2}\right) \sigma_{\xi_{i}}^{2} \leq \sigma_{\xi_{i}}^{2} σεi2=(1−R2)σξi2≤σξi2
setwd("D:/data")
library(fBasics)#时间序列一个重要的包
da = read.table("m-ibm6708.txt",header = T)#读到一个data.frame里
da[1,]
ibm = da$ibm
#Constane Mean Return Model
stdev(ibm)#因变量的标准差
#Market Model
sp = da$sprtn
plot(sp,ibm)
cor(sp,ibm)
marketmodel = lm(ibm~sp)
marketmodel
summary(marketmodel)

相关性
Pearson相关系数不适用描述非线性相关性、不适用于描述分布非正态的随机变量间的相关、对于异常点不具有稳健性。
其他几种相关系数:
1、Spearman’s rank correlation
2、Pseudo correlation
3、Kendall’s τ \tau τ
注:如果X和Y满足联合正态分布,则他们之间的Pearson’s ρ \rho ρ = Spearman’ rank correlation = Pseudo correlation
#Measure of Correlation and Dependence
cor(sp,ibm) #pearson's correlation
cor(sp,ibm,method = "spearman")#Spearman's rank correlation
cor(rank(sp),rank(ibm)) #Spearman's rank correlation
cor(sp,ibm,method = "kendall")#Kendall's tau
#invariance to monotonic nonlinear transformation
cor(exp(sp),exp(ibm)) #not invariant
cor(exp(sp),exp(ibm),method = "spearman")#invaraint
cor(rank(exp(sp)),rank(exp(ibm)))
cor(exp(sp),exp(ibm),method = "kendall")#invaraint
有效市场假说

二、ARMA
1、基本概念
- 均值和方差: μ = E ( r t ) \mu=\mathbb{E}\left(r_{t}\right) μ=E(rt), Var ( r t ) = E [ ( r t − μ ) 2 ] \operatorname{Var}\left(r_{t}\right)=\mathbb{E}\left[\left(r_{t}-\mu\right)^{2}\right] Var(rt)=E[(rt−μ)2]
自协方差: γ l = Cov ( r t , r t − l ) = E ( r t − μ ) ( r t − l − μ ) \gamma_{l}=\operatorname{Cov}\left(r_{t}, r_{t-l}\right)=\mathbb{E}\left(r_{t}-\mu\right)\left(r_{t-l}-\mu\right) γl=Cov(rt,rt−l)=E(rt−μ)(rt−l−μ)
自相关系数: ρ l = Cov ( r t , r t − l ) Var ( r t ) = γ l γ 0 \rho_{l}=\frac{\operatorname{Cov}\left(r_{t}, r_{t-l}\right)}{\operatorname{Var}\left(r_{t}\right)}=\frac{\gamma_{l}}{\gamma_{0}} ρl=Var(rt)Cov(rt,rt−l)=γ0γl - 样本均值和样本方差: r ˉ T = 1 T ∑ t = 1 T r t \bar{r}_{T}=\frac{1}{T} \sum_{t=1}^{T} r_{t} rˉT=T1∑t=1Trt, s T 2 = 1 T − 1 ∑ t = 1 T ( r t − r ˉ ) 2 s_{T}^{2}=\frac{1}{T-1} \sum_{t=1}^{T}\left(r_{t}-\bar{r}\right)^{2} sT2=T−11∑t=1T(rt−rˉ)2
样本自相关系数(ACF): ρ ^ l = ∑ t = l + 1 T ( r t − r ˉ T ) ( r t − l − r ˉ T ) ∑ t = 1 T ( r t − r ˉ T ) 2 \hat{\rho}_{l}=\frac{\sum_{t=l+1}^{T}\left(r_{t}-\bar{r}_{T}\right)\left(r_{t-l}-\bar{r}_{T}\right)}{\sum_{t=1}^{T}\left(r_{t}-\bar{r}_{T}\right)^{2}} ρ^l=∑t=1T(rt−rˉT)2∑t=l+1T(rt−rˉT)(rt−l−rˉT)
相关系数是否为0的假设检验:
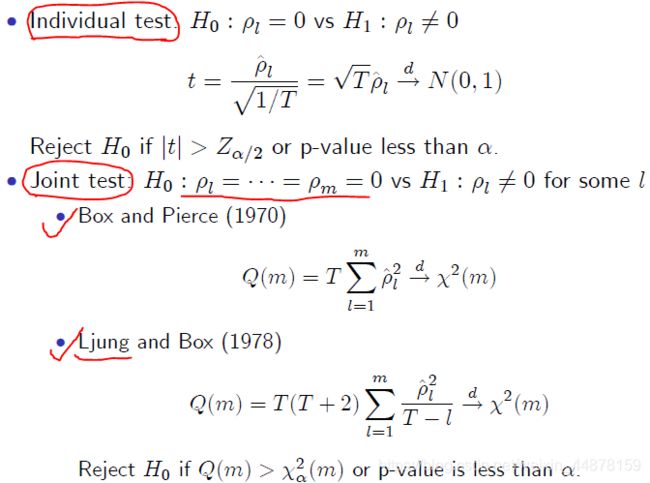
2、AR模型
- AR(1)
模型: r t = ϕ 0 + ϕ 1 r t − 1 + a t r_{t}=\phi_{0}+\phi_{1} r_{t-1}+a_{t} rt=ϕ0+ϕ1rt−1+at或
( 1 − ϕ 1 B ) r t = ϕ 0 + a t \left(1-\phi_{1} B\right) r_{t}=\phi_{0}+a_{t} (1−ϕ1B)rt=ϕ0+at
平稳性条件:当且仅当 ∣ ϕ 1 ∣ < 1 |\phi_{1}|<1 ∣ϕ1∣<1时(充分必要条件),AR(1)平稳
当所有特征根在单位圆外时,AR模型平稳
均值: μ = E ( r t ) = ϕ 0 1 − ϕ 1 \mu=\mathbb{E}\left(r_{t}\right)=\frac{\phi_{0}}{1-\phi_{1}} μ=E(rt)=1−ϕ1ϕ0
(所以得到AR(1)的另一种表达: ( r t − μ ) = ϕ 1 ( r t − 1 − μ ) + a t \left(r_{t}-\mu\right)=\phi_{1}\left(r_{t-1}-\mu\right)+a_{t} (rt−μ)=ϕ1(rt−1−μ)+at)
方差: Var ( r t ) = σ a 2 1 − ϕ 1 2 \operatorname{Var}\left(r_{t}\right)=\frac{\sigma_{a}^{2}}{1-\phi_{1}^{2}} Var(rt)=1−ϕ12σa2
自相关系数: ρ 1 = ϕ 1 , ρ 2 = ϕ 1 2 , … , ρ k = ϕ 1 k \rho_{1}=\phi_{1}, \rho_{2}=\phi_{1}^{2}, \ldots, \rho_{k}=\phi_{1}^{k} ρ1=ϕ1,ρ2=ϕ12,…,ρk=ϕ1k
一步预测: x ^ n ( 1 ) = ϕ 1 x n \hat{x}_{n}(1)=\phi_{1} x_{n} x^n(1)=ϕ1xn
一步预测误差: e n ( 1 ) = x n + 1 − x ^ n ( 1 ) = a n + 1 e_{n}(1)=x_{n+1}-\hat{x}_{n}(1)=a_{n+1} en(1)=xn+1−x^n(1)=an+1
一步预测误差的方差: Var [ e n ( 1 ) ] = Var ( a n + 1 ) = σ a 2 \operatorname{Var}\left[e_{n}(1)\right]=\operatorname{Var}\left(a_{n+1}\right)=\sigma_{a}^{2} Var[en(1)]=Var(an+1)=σa2
两步预测: x ^ n ( 2 ) = ϕ 1 x ^ n ( 1 ) = ϕ 1 2 x n \hat{x}_{n}(2)=\phi_{1} \hat{x}_{n}(1)=\phi_{1}^{2} x_{n} x^n(2)=ϕ1x^n(1)=ϕ12xn
两步预测误差: e n ( 2 ) = x n + 2 − x ^ n ( 2 ) = a n + 2 + ϕ 1 a n + 1 e_{n}(2)=x_{n+2}-\hat{x}_{n}(2)=a_{n+2}+\phi_{1} a_{n+1} en(2)=xn+2−x^n(2)=an+2+ϕ1an+1
一步预测误差的方差: Var [ e n ( 2 ) ] = ( 1 + ϕ 1 2 ) σ a 2 \operatorname{Var}\left[e_{n}(2)\right]=\left(1+\phi_{1}^{2}\right) \sigma_{a}^{2} Var[en(2)]=(1+ϕ12)σa2
k步预测: x ^ n ( l ) = ϕ 1 l x n \hat{x}_{n}(l)=\phi_{1}^{l} x_{n} x^n(l)=ϕ1lxn
k步预测误差: e n ( l ) = a n + l + ϕ 1 a n + l − 1 + ⋯ + ϕ 1 l − 1 a n + 1 e_{n}(l)=a_{n+l}+\phi_{1} a_{n+l-1}+\cdots+\phi_{1}^{l-1} a_{n+1} en(l)=an+l+ϕ1an+l−1+⋯+ϕ1l−1an+1
k步预测误差的方差: Var [ e n ( l ) ] = ( 1 + ϕ 1 1 + ⋯ + ϕ 1 2 ( l − 1 ) ) σ a 2 \operatorname{Var}\left[e_{n}(l)\right]=\left(1+\phi_{1}^{1}+\cdots+\phi_{1}^{2(l-1)}\right) \sigma_{a}^{2} Var[en(l)]=(1+ϕ11+⋯+ϕ12(l−1))σa2
- AR(2)
模型: r t = ϕ 0 + ϕ 1 r t − 1 + ϕ 2 r t − 2 + a t r_{t}=\phi_{0}+\phi_{1} r_{t-1}+\phi_{2} r_{t-2}+a_{t} rt=ϕ0+ϕ1rt−1+ϕ2rt−2+at也可以写成 ( 1 − ϕ 1 B − ϕ 2 B 2 ) r t = ϕ 0 + a t \left(1-\phi_{1} B-\phi_{2} B^{2}\right) r_{t}=\phi_{0}+a_{t} (1−ϕ1B−ϕ2B2)rt=ϕ0+at
平稳性条件:当特征方程 ( 1 − ϕ 1 z − ϕ 2 z 2 ) = 0 \left(1-\phi_{1} z-\phi_{2} z^{2}\right)=0 (1−ϕ1z−ϕ2z2)=0的所有跟位于单位圆外时,AR(2)平稳
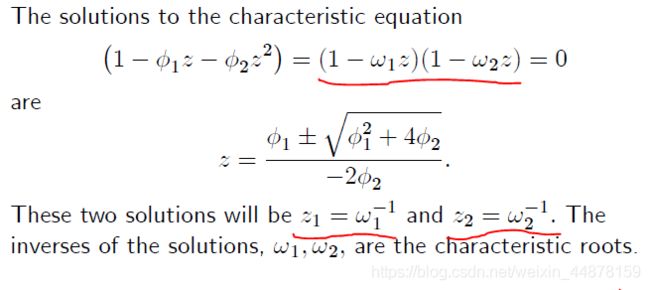
均值: E ( r t ) = ϕ 0 1 − ϕ 1 − ϕ 2 \mathbb{E}\left(r_{t}\right)=\frac{\phi_{0}}{1-\phi_{1}-\phi_{2}} E(rt)=1−ϕ1−ϕ2ϕ0
自相关系数: ρ 0 = 1 \rho_0=1 ρ0=1, ρ 1 = ϕ 1 1 − ϕ 2 \rho_{1}=\frac{\phi_{1}}{1-\phi_{2}} ρ1=1−ϕ2ϕ1, ρ l = ϕ 1 ρ l − 1 + ϕ 2 ρ l − 2 \rho_l=\phi_1\rho_{l-1}+\phi_2\rho_{l-2} ρl=ϕ1ρl−1+ϕ2ρl−2 (for l>2)
3、MA模型
- MA(1)
== 模型==: r t = μ + a t − θ a t − 1 r_{t}=\mu+a_{t}-\theta a_{t-1} rt=μ+at−θat−1
平稳性:MA模型总是平稳的
可逆性: ∣ θ ∣ < 1 |\theta|<1 ∣θ∣<1
均值: E ( r t ) = μ \mathbb{E}\left(r_{t}\right)=\mu E(rt)=μ
方差: Var ( r t ) = ( 1 + θ 2 ) σ a 2 = γ 0 \operatorname{Var}\left(r_{t}\right)=\left(1+\theta^{2}\right) \sigma_{a}^{2}=\gamma_{0} Var(rt)=(1+θ2)σa2=γ0
自协方差: γ 1 = Cov ( r t , r t − 1 ) = − θ σ a 2 \gamma_{1}=\operatorname{Cov}\left(r_{t}, r_{t-1}\right)=-\theta \sigma_{a}^{2} γ1=Cov(rt,rt−1)=−θσa2, γ 2 = Cov ( r t , r t − l ) = 0 \gamma_{2}=\operatorname{Cov}\left(r_{t}, r_{t-l}\right)=0 γ2=Cov(rt,rt−l)=0 for l > 1 l>1 l>1
自相关系数: ρ 1 = γ 1 γ 0 = − θ 1 + θ 2 \rho_{1}=\frac{\gamma_{1}}{\gamma_{0}}=\frac{-\theta}{1+\theta^{2}} ρ1=γ0γ1=1+θ2−θ, ρ l = 0 \rho_l=0 ρl=0 for l > 1 l>1 l>1
注:由自相关系数可以看出,MA模型两步及以上无记忆性
一步预测: r ^ t ( 1 ) = μ − θ a n \hat{r}_{t}(1)=\mu-\theta a_{n} r^t(1)=μ−θan
一步预测误差: e n ( 1 ) = a n + 1 e_{n}(1)=a_{n+1} en(1)=an+1
多步预测: r ^ n ( l ) = μ \hat{r}_{n}(l)=\mu r^n(l)=μ for l > 1 l>1 l>1
多步预测的误差: e n ( l ) = a n + l − θ a n + l − 1 e_{n}(l)=a_{n+l}-\theta a_{n+l-1} en(l)=an+l−θan+l−1
多步预测的误差的方差: ( 1 + θ 2 ) σ a 2 = γ 0 \left(1+\theta^{2}\right) \sigma_{a}^{2}=\gamma_{0} (1+θ2)σa2=γ0
- MA(2)
模型: r t = μ + a t + θ 1 a t − 1 + θ 2 a t − 2 = μ + ( 1 + θ 1 B + θ 2 B 2 ) a t r_{t}=\mu+a_{t}+\theta_{1} a_{t-1}+\theta_{2} a_{t-2}=\mu+\left(1+\theta_{1} B+\theta_{2} B^{2}\right) a_{t} rt=μ+at+θ1at−1+θ2at−2=μ+(1+θ1B+θ2B2)at(R语言)
均值: E ( r t ) = μ E\left(r_{t}\right)=\mu E(rt)=μ
方差: Var ( r t ) = ( 1 + θ 1 2 + θ 2 2 ) σ a 2 = γ 0 \operatorname{Var}\left(r_{t}\right)=\left(1+\theta_{1}^{2}+\theta_{2}^{2}\right) \sigma_{a}^{2}=\gamma_{0} Var(rt)=(1+θ12+θ22)σa2=γ0 Var ( r t ) = ( 1 + θ 1 2 + θ 2 2 ) σ a 2 = γ 0 \operatorname{Var}\left(r_{t}\right)=\left(1+\theta_{1}^{2}+\theta_{2}^{2}\right) \sigma_{a}^{2}=\gamma_{0} Var(rt)=(1+θ12+θ22)σa2=γ0
自相关系数: ρ 2 ≠ 0 , \rho_{2} \neq 0, ρ2=0, but ρ l = 0 \rho_{l}=0 ρl=0 for l > 2 l>2 l>2
多步预测: r ^ n ( l ) = μ \hat{r}_{n}(l)=\mu r^n(l)=μ for l > 2 l>2 l>2
多步预测的方差:Variance of multi-step ahead forecast error is unconditional
variance of r t r_t rt
3、ARMA模型

