Win10 + RTX3090 安装CUDA11.2 + CUDNN8.1.0
前提
系统重新安装,anaconda3中tensorflow和pytorch已经安装过,主要目的是方便自己以后重新安装CUDA
主机配置
系统:Win10 64bit
CPU:I9-10850K
内存:64G
显卡:GeForce RTX 3090
显卡驱动:
https://www.nvidia.cn/geforce/drivers/
CUDA与驱动版本对照-table2
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
CUDA最新版:
https://developer.nvidia.com/cuda-toolkit
CUDA历史版本:
https://developer.nvidia.com/cuda-toolkit-archive
cuDNN:
https://developer.nvidia.com/rdp/cudnn-archive
安装软件版本:
CUDA:cuda_11.2.2_461.33_win10
cuDNN:cudnn-11.2-windows-x64-v8.1.0.77
cuDNN配置
解压后进cuda将bin、include和lib复制到CUDA的安装目录
CUDA的安装目录在 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2
环境变量
path里面
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\lib\x64
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\libnvvp
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\extras\CUPTI\lib64
环境测试(测试代码后附,或者直接链接下载)
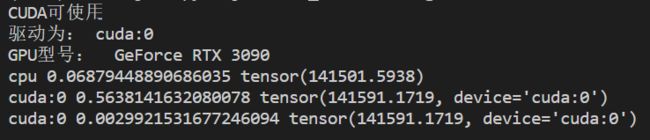
pyTroch:
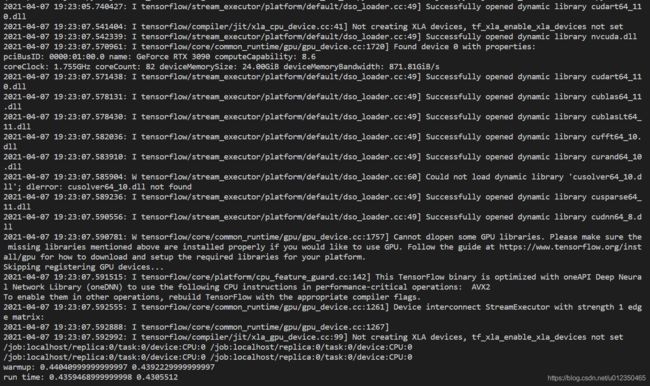
TensorFlow:
测试python代码
pytorch
import torch
import time
flag = torch.cuda.is_available()
if flag:
print("CUDA可使用")
else:
print("CUDA不可用")
ngpu= 1
# Decide which device we want to run on
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
print("驱动为:",device)
print("GPU型号: ",torch.cuda.get_device_name(0))
a = torch.randn(10000, 1000)
b = torch.randn(1000, 2000)
t0 = time.time()
c = torch.matmul(a, b)
t1 = time.time()
print(a.device, t1 - t0, c.norm(2))
device = torch.device('cuda')
a = a.to(device)
b = b.to(device)
t0 = time.time()
c = torch.matmul(a, b)
t2 = time.time()
print(a.device, t2 - t0, c.norm(2))
t0 = time.time()
c = torch.matmul(a, b)
t2 = time.time()
print(a.device, t2 - t0, c.norm(2))
TensorFlow
import tensorflow as tf
import timeit
with tf.device('/cpu:0'):
cpu_a = tf.random.normal([10000, 1000])
cpu_b = tf.random.normal([1000, 2000])
print(cpu_a.device, cpu_b.device)
with tf.device('/gpu:0'):
gpu_a = tf.random.normal([10000, 1000])
gpu_b = tf.random.normal([1000, 2000])
print(gpu_a.device, gpu_b.device)
def cpu_run():
with tf.device('/cpu:0'):
c = tf.matmul(cpu_a, cpu_b)
return c
def gpu_run():
with tf.device('/gpu:0'):
c = tf.matmul(gpu_a, gpu_b)
return c
# warm up
cpu_time = timeit.timeit(cpu_run, number=10)
gpu_time = timeit.timeit(gpu_run, number=10)
print('warmup:', cpu_time, gpu_time)
cpu_time = timeit.timeit(cpu_run, number=10)
gpu_time = timeit.timeit(gpu_run, number=10)
print('run time:', cpu_time, gpu_time)